之前我們學習了執行緒池ThreadPoolExecutor,它透過對任務佇列和執行緒的有效管理實作了對並行任務的處理。
然而,ThreadPoolExecutor有兩個明顯的缺點: 一是無法對大任務進行拆分,對於某個任務只能由單執行緒執行;二是工作執行緒從佇列中獲取任務時存在競爭情況 。這兩個缺點都會影響任務的執行效率,要知道高並行場景中的每一毫秒都彌足珍貴。
針對這兩個問題,本文即將介紹的 ForkJoinPool 給出了可選的答案。在本文中,我們將首先從分治演算法開始介紹,接著體驗ForkJoinPool中自訂任務的實作,最後再深入到Java中去理解ForkJoinPool的原理和用法。
一、分治演算法與Fork/Join模式
在並行計算中,Fork/Join模式往往用於對大任務的平行計算,它透過遞迴的方式對任務不斷地拆解,再將結果進行合並。如果從其思想上看,Fork/Join並不復雜,其本質是 分治演算法(Divide-and-Conquer) 的套用。
分治演算法的 基本思想是將一個規模為N的問題分解為K個規模較小的子問題,這些子問題相互獨立且與原問題性質相同。求出子問題的解,就可得到原問題的解。 分治演算法的步驟如下:
(1) 分解 :將要解決的問題劃分成若幹規模較小的同類問題;
(2) 求解 :當子問題劃分得足夠小時,用較簡單的方法解決;
(3) 合並 :按原問題的要求,將子問題的解逐層合並構成原問題的解。
在並行計算中,Fork/Join模式往往用於對大任務的平行計算,它透過遞迴的方式對任務不斷地拆解,再將結果進行合並。如果從其思想上看,Fork/Join並不復雜,其本質是 分治演算法(Divide-and-Conquer) 的套用。
分治演算法的 基本思想是將一個規模為N的問題分解為K個規模較小的子問題,這些子問題相互獨立且與原問題性質相同。求出子問題的解,就可得到原問題的解。 分治演算法的步驟如下:
(1) 分解 :將要解決的問題劃分成若幹規模較小的同類問題;
(2) 求解 :當子問題劃分得足夠小時,用較簡單的方法解決;
(3) 合並 :按原問題的要求,將子問題的解逐層合並構成原問題的解。

solve(problem):
if problem is small enough:
// 如果任務足夠小,執行任務
solve problem directly (sequential algorithm)
else:
// 拆分任務
for part in subdivide(problem)
fork subtask to solve(part)
// 合並結果
join all subtasks spawned in previous loop
return combined results
所以,理解Fork/Join模型和ForkJoinPool執行緒池,首先要理解其背後的演算法的目的和思想,因為後文所要詳述的ForkJoinPool不過只是這種演算法的一種的實作和套用。
二、Fork/Join套用場景與體驗
按照 思想->實作->源碼 的思路,在了解了Fork/Join思想之後,我們先透過一個場景手工實作一個RecursiveTask,這樣可以更好地體驗Fork/Join的用法。
場景:給定兩個自然數,計算兩個兩個數之間的總和。比如1~n之間的和:1+2+3+…+n
為了解決這個問題,我們建立了TheKingRecursiveSumTask這個核心類,它繼承於RecursiveTask. RecursiveTask是ForkJoinPool中的一種任務型別,你暫且不必深入了解它,後文會有詳細描述。 TheKingRecursiveSumTask中定義了任務計算的起止範圍(sumBegin和sumEnd)和拆分閾值(threshold),以及核心計算邏輯compute().
public class TheKingRecursiveSumTask extends RecursiveTask<Long> {
private static final AtomicInteger taskCount = new AtomicInteger();
private final int sumBegin;
private final int sumEnd;
/**
* 任務拆分閾值,當任務尺寸大於該值時,進行拆分
*/
private final int threshold;
public TheKingRecursiveSumTask(int sumBegin, int sumEnd, int threshold) {
this.sumBegin = sumBegin;
this.sumEnd = sumEnd;
this.threshold = threshold;
}
@Override
protected Long compute() {
if ((sumEnd - sumBegin) > threshold) {
// 兩個數之間的差值大於閾值,拆分任務
TheKingRecursiveSumTask subTask1 = new TheKingRecursiveSumTask(sumBegin, (sumBegin + sumEnd) / 2, threshold);
TheKingRecursiveSumTask subTask2 = new TheKingRecursiveSumTask((sumBegin + sumEnd) / 2, sumEnd, threshold);
subTask1.fork();
subTask2.fork();
taskCount.incrementAndGet();
return subTask1.join() + subTask2.join();
}
// 直接執行結果
long result = 0L;
for (int i = sumBegin; i < sumEnd; i++) {
result += i;
}
return result;
}
public static AtomicInteger getTaskCount() {
return taskCount;
}
}
在下面的程式碼中,我們設定的計算區間值0~10000000, 當計算的個數超過100時,將對任務進行拆分 ,最大並行數設定為 16 .
public static void main(String[] args) {
int sumBegin = 0, sumEnd = 10000000;
computeByForkJoin(sumBegin, sumEnd);
computeBySingleThread(sumBegin, sumEnd);
}
private static void computeByForkJoin(int sumBegin, int sumEnd) {
ForkJoinPool forkJoinPool = new ForkJoinPool(16);
long forkJoinStartTime = System.nanoTime();
TheKingRecursiveSumTask theKingRecursiveSumTask = new TheKingRecursiveSumTask(sumBegin, sumEnd, 100);
long forkJoinResult = forkJoinPool.invoke(theKingRecursiveSumTask);
System.out.println("======");
System.out.println("ForkJoin任務拆分:" + TheKingRecursiveSumTask.getTaskCount());
System.out.println("ForkJoin計算結果:" + forkJoinResult);
System.out.println("ForkJoin計算耗時:" + (System.nanoTime() - forkJoinStartTime) / 1000000);
}
private static void computeBySingleThread(int sumBegin, int sumEnd) {
long computeResult = 0 L;
long startTime = System.nanoTime();
for (int i = sumBegin; i < sumEnd; i++) {
computeResult += i;
}
System.out.println("======");
System.out.println("單執行緒計算結果:" + computeResult);
System.out.println("單執行緒計算耗時:" + (System.nanoTime() - startTime) / 1000000);
}
執行結果如下:
======
ForkJoin任務拆分:131071
ForkJoin計算結果:49999995000000
ForkJoin計算耗時:207
======
單執行緒計算結果:49999995000000
單執行緒計算耗時:40
Process finished with exit code 0
從計算結果中可以看到,ForkJoinPool總共進行了131071次的任務拆分,最終的計算結果是49999995000000,耗時207毫秒。 不過,細心的你可能已經發現了, ForkJoin的平行計算的耗時竟然比單程程還慢?並且足足慢了近5倍 !先別慌,關於ForkJoin的效能問題,我們會在後文有講解。
三、ForkJoinPool設計與源分碼析
在Java中,ForkJoinPool是Fork/Join模型的實作,於Java7引入並在Java8中廣泛套用。ForkJoinPool允許其他執行緒向它送出任務,並根據設定將這些任務拆分為粒度更細的子任務,這些子任務將由ForkJoinPool內部的工作執行緒來並列執行,並且工作執行緒之間可以竊取彼此之間的任務。
在介面實作和繼承關系上,ForkJoinPool和ThreadPoolExecutor類似,都實作了Executor和ExecutorService介面,並繼承了AbstractExecutorService抽類。而在任務型別上,ForkJoinPool主要有兩種任務型別: RecursiveAction 和 RecursiveTask ,它們繼承於ForkJoinTask. 相關關系如下圖所示:
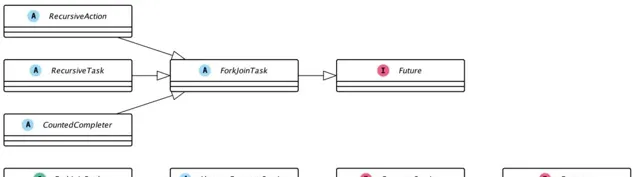
1. 構造ForkJoinPool的幾種不同方式
ForkJoinPool中有四個核心參數,用於控制執行緒池的 並列數 、 工作執行緒的建立 、 例外處理 和 模式指定 等。各參數解釋如下:
int parallelism:指定並列級別(parallelism level)。ForkJoinPool將根據這個設定,決定工作執行緒的數量。如果未設定的話,將使用Runtime.getRuntime().availableProcessors()來設定並列級別;
ForkJoinWorkerThreadFactory factory:ForkJoinPool在建立執行緒時,會透過factory來建立。註意,這裏需要實作的是ForkJoinWorkerThreadFactory,而不是ThreadFactory. 如果你不指定factory,那麽將由預設的DefaultForkJoinWorkerThreadFactory負責執行緒的建立工作;
UncaughtExceptionHandler handler:指定例外處理器,當任務在執行中出錯時,將由設定的處理器處理;
boolean asyncMode:從名字上看,你可能會覺得它是 異步模式 設定,但其實是設定佇列的工作模式:asyncMode ? FIFO_QUEUE : LIFO_QUEUE. 當asyncMode為true時,將使用先進先出佇列,而為false時則使用後進先出的模式。
圍繞上面的四個核心參數,ForkJoinPool提供了三種構造方式,使用時你可以根據需要選擇其中的一種。
(1)方式一:預設無參構造
在該構造方式中,你無需設定任何參數。ForkJoinPool將根據當前處理器數量來設定並列數量,並使用預設的執行緒構造工廠。 不推薦 。
public ForkJoinPool() {
this(Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors()),
defaultForkJoinWorkerThreadFactory, null, false);
}
(2)方式二:透過並列數構造
在該構造方式中,你可以指定並列數量,以更有效地平衡處理器數量和負載。 建議在設定時,並列級別應低於當前處理器的數量 。
public ForkJoinPool(int parallelism) {
this(parallelism, defaultForkJoinWorkerThreadFactory, null, false);
}
(3)方式三:自訂全部參數構造
以上兩種構造方式都是基於這種構造,它允許你配置所有的核心參數。為了更有效地管理ForkJoinPool, 建議你使用這種構造方式 。
public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
boolean asyncMode) {
this(checkParallelism(parallelism),
checkFactory(factory),
handler,
asyncMode ? FIFO_QUEUE : LIFO_QUEUE,
"ForkJoinPool-" + nextPoolId() + "-worker-");
checkPermission();
}
2. 按型別送出不同任務
任務送出 是ForkJoinPool的核心能力之一,在送出任務時你有三種選擇,如下面表格所示:
| 從非fork/join執行緒呼叫 | 從fork/join呼叫 | |
|---|---|---|
| 送出異步執行 | execute(ForkJoinTask) | ForkJoinTask.fork() |
| 等待並獲取結果 | invoke(ForkJoinTask) | ForkJoinTask.invoke() |
| 送出執行獲取Future結果 | submit(ForkJoinTask) | ForkJoinTask.fork() (ForkJoinTasks are Futures) |
(1)第一類核心方法:invoke
invoke型別的方法接受ForkJoinTask型別的任務,並在任務執行結束後,返回泛型結果。如果送出的任務是null,將丟擲空指標異常。
public <T> T invoke(ForkJoinTask<T> task) {
if (task == null)
throw new NullPointerException();
externalPush(task);
return task.join();
}
(2)第二類核心方法:execute
execute型別的方法在送出任務後,不會返回結果。另外要註意的是,ForkJoinPool不僅允許送出ForkJoinTask型別任務,還允許送出 Callable 或 Runnable 任務,因此你可以像使用現有Executors一樣使用ForkJoinPool。
當然,Callable或Runnable型別任務時,將會轉換為ForkJoinTask型別,具體可以檢視任務送出的相關源碼。那麽,這類任務和直接送出ForkJoinTask任務有什麽區別呢?還是有的。 區別在於,由於任務是不可切分的,所以這類任務無法獲得任務拆分這方面的效益,不過仍然可以獲得任務竊取帶來的好處和效能提升 。
public void execute(ForkJoinTask<?> task) {
if (task == null)
throw new NullPointerException();
externalPush(task);
}
public void execute(Runnable task) {
if (task == null)
throw new NullPointerException();
ForkJoinTask<?> job;
if (task instanceof ForkJoinTask<?>) // avoid re-wrap
job = (ForkJoinTask<?>) task;
else
job = new ForkJoinTask.RunnableExecuteAction(task);
externalPush(job);
}
(3)第三類核心方法:submit
submit型別的方法支持三種型別的任務送出:ForkJoinTask型別、Callable型別和Runnable型別。在送出任務後,將返回ForkJoinTask型別的結果。如果送出的任務是null,將丟擲空指標異常,並且當任務不能按計劃執行的話,將丟擲任務拒絕異常。
public < T > ForkJoinTask < T > submit(ForkJoinTask < T > task) {
if (task == null)
throw new NullPointerException();
externalPush(task);
return task;
}
public < T > ForkJoinTask < T > submit(Callable < T > task) {
ForkJoinTask < T > job = new ForkJoinTask.AdaptedCallable < T > (task);
externalPush(job);
return job;
}
public < T > ForkJoinTask < T > submit(Runnable task, T result) {
ForkJoinTask < T > job = new ForkJoinTask.AdaptedRunnable < T > (task, result);
externalPush(job);
return job;
}
public ForkJoinTask < ? > submit(Runnable task) {
if (task == null)
throw new NullPointerException();
ForkJoinTask < ? > job;
if (task instanceof ForkJoinTask < ? > ) // avoid re-wrap
job = (ForkJoinTask < ? > ) task;
else
job = new ForkJoinTask.AdaptedRunnableAction(task);
externalPush(job);
return job;
}
3. ForkJoinTask
ForkJoinTask是ForkJoinPool的核心之一,它是任務的實際載體,定義了任務執行時的具體邏輯和拆分邏輯 ,本文前面的範例程式碼就是透過繼承它實作。作為一個抽象類,ForkJoinTask的行為有點類似於執行緒,但它更為輕量,因為它不維護自己的執行時堆疊或程式計數器等。
在類的設計上,ForkJoinTask繼承了Future介面,所以也可以將其看作是輕量級的Future,它們之間的關系如下圖所示。
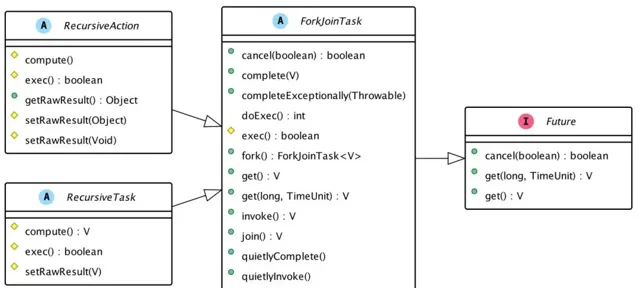
(1)fork與join
fork()/join()是ForkJoinTask甚至是ForkJoinPool的核心方法,承載著主要的任務協調作用,一個用於任務送出,一個用於結果獲取。
fork-送出任務
fork()方法用於向 當前任務所執行的執行緒池 中送出任務,比如上文範例程式碼中的subTask1.fork(). 註意,不同於其他執行緒池的寫法,任務送出由任務自己透過呼叫fork()完成,對此不要感覺詫異,fork()內部會將任務與當前執行緒進行關聯。
從源碼中看,如果當前執行緒是ForkJoinWorkerThread型別,將會放入該執行緒的任務佇列,否則放入common執行緒池的任務佇列中。 關於common執行緒池,後續會有介紹 。
public final ForkJoinTask<V> fork() {
Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
ForkJoinPool.common.externalPush(this);
return this;
}
join-獲取任務執行結果
前面,你已經知道可以透過fork()送出任務。那麽現在,你則可以透過join()方法獲取任務的執行結果。 呼叫join()時,將阻塞當前執行緒直到對應的子任務完成執行並返回結果。從源碼看,join()的核心邏輯由doJoin()負責。doJoin()雖然很短,但可讀性較差,閱讀時稍微忍一下。
public final V join() {
int s;
// 如果呼叫doJoin返回的非NORMAL狀態,將報告異常
if ((s = doJoin() & DONE_MASK) != NORMAL)
reportException(s);
// 正常執行結束,返回原始結果
return getRawResult();
}
private int doJoin() {
int s;
Thread t;
ForkJoinWorkerThread wt;
ForkJoinPool.WorkQueue w;
//如果已完成,返回狀態
return (s = status) < 0 ? s :
//如果未完成且當前執行緒是ForkJoinWorkerThread,則從該執行緒中取出workQueue,並嘗試將當前task取出執行。如果執行的結果是完成,則返回狀態;否則,使用當前執行緒池awaitJoin方法進行等待
((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) ?
(w = (wt = (ForkJoinWorkerThread) t).workQueue).
tryUnpush(this) && (s = doExec()) < 0 ? s :
wt.pool.awaitJoin(w, this, 0 L):
//當前執行緒非ForkJoinWorkerThread,呼叫externalAwaitDone方法等待
externalAwaitDone();
}
final int doExec() {
int s;
boolean completed;
if ((s = status) >= 0) {
try {
completed = exec();
} catch (Throwable rex) {
return setExceptionalCompletion(rex);
}
// 執行完成後,將狀態設定為NORMAL
if (completed)
s = setCompletion(NORMAL);
}
return s;
}
(2)RecursiveAction與RecursiveTask
RecursiveAction:無結果返回
RecursiveAction用於遞迴執行但不需要返回結果的任務,比如下面的排序就是它的典型套用場景。在使用RecursiveAction時,你需要繼承並實作它的核心方法compute().
static class SortTask extends RecursiveAction {
final long[] array;
final int lo, hi;
SortTask(long[] array, int lo, int hi) {
this.array = array;
this.lo = lo;
this.hi = hi;
}
SortTask(long[] array) {
this(array, 0, array.length);
}
// 核心計算方法
protected void compute() {
if (hi - lo < THRESHOLD)
// 直接執行
sortSequentially(lo, hi);
else {
// 拆分任務
int mid = (lo + hi) >>> 1;
invokeAll(new SortTask(array, lo, mid),
new SortTask(array, mid, hi));
merge(lo, mid, hi);
}
}
// implementation details follow:
static final int THRESHOLD = 1000;
void sortSequentially(int lo, int hi) {
Arrays.sort(array, lo, hi);
}
void merge(int lo, int mid, int hi) {
long[] buf = Arrays.copyOfRange(array, lo, mid);
for (int i = 0, j = lo, k = mid; i < buf.length; j++)
array[j] = (k == hi || buf[i] < array[k]) ?
buf[i++] : array[k++];
}
}
RecursiveTask:返回結果
RecursiveTask用於遞迴執行需要返回結果的任務,比如前面範例程式碼中的求和或下面這段求斐波拉契數列求和都是它的典型套用場景。在使用RecursiveTask時,你也需要繼承並實作它的核心方法compute().
class Fibonacci extends RecursiveTask<Integer> {
final int n;
Fibonacci(int n) { this.n = n; }
Integer compute() {
if (n <= 1)
return n;
Fibonacci f1 = new Fibonacci(n - 1);
f1.fork();
Fibonacci f2 = new Fibonacci(n - 2);
return f2.compute() + f1.join();
}
}
(3)ForkJoinTask使用限制
雖然在某些場景下,ForkJoinTask可以透過任務拆解的方式提高執行效率,但是需要註意的是它並非適合所有的場景。 ForkJoinTask在使用時需要謹記一些限制,違背這些限制可能會適得其反甚至引來災難 。
為什麽這麽說呢?
這是因為,ForkJoinTask最適合用於純粹的 計算任務 ,也就是 純函式計算 ,計算過程中的物件都是獨立的,對外部沒有依賴。你可以想象,如果大量的任務或被拆分的子任務之間彼此依賴或對外部存在嚴重阻塞依賴,那將是怎樣的畫面...用千絲萬縷來形容也不為過,外部依賴會帶來 任務執行 和 問題排查 方面的雙重不確定性。
所以,在理想情況下,送出到ForkJoinPool中的任務 應避免執行阻塞I/O ,以免出現不可控的意外情況。當然,這也並非是絕對的,在必要時你也可以定義和使用可阻塞的ForkJoinTask,只不過你需要付出更多的代價和考慮,使用時應當慎之又慎,本文對此不作敘述。
4. 工作佇列與任務竊取
前面已經說到,ForkJoinPool與ThreadPoolExecutor有個很大的不同之處在於,ForkJoinPool存在引入了 任務竊取 設計,它是其效能保證的關鍵之一。
關於任務竊取,簡單來說, 就是允許空閑執行緒從繁忙執行緒的雙端佇列中竊取任務 。預設情況下,工作執行緒從它自己的雙端佇列的 頭部 獲取任務。但是,當自己的任務為空時,執行緒會從其他繁忙執行緒雙端佇列的 尾部 中獲取任務。這種方法,最大限度地減少了執行緒競爭任務的可能性。
ForkJoinPool的大部份操作都發生在 工作竊取佇列(work-stealing queues ) 中,該佇列由內部類WorkQueue實作。其實,這個佇列也不是什麽神奇之物,它是Deques的特殊形式,但僅支持三種操作方式: push 、 pop 和 poll (也稱為竊取)。當然,在ForkJoinPool中,佇列的讀取有著嚴格的約束,push和pop僅能從其所屬執行緒呼叫,而poll則可以從其他執行緒呼叫。換句話說,前兩個方法是留給自己用的,而第三種方法則是為了方便別人來竊取任務用的。 任務竊取的相關過程,可以用下面這幅圖來表示,這幅圖建議你收藏 :

答案當然不會是「 更有意義 」。 這樣做的主要原因是為了提高效能,透過始終選擇最近送出的任務,可以增加資源仍分配在CPU緩存中的機會,這樣CPU處理起來要快一些 。而竊取者之所以從尾部獲取任務, 則是為了降低執行緒之間的競爭可能,畢竟大家都從一個部份拿任務,競爭的可能要大很多 。
此外,這樣的設計還有一種考慮。 由於任務是可分割的,那佇列中較舊的任務最有可能粒度較大,因為它們可能還沒有被分割,而空閑的執行緒則相對更有「精力」來完成這些粒度較大的任務 。
5. ForkJoinPool監控
對於一個復雜框架來說,即時地了解ForkJoinPool的內部狀態是十分必要的。因此,ForkJoinPool提供了一些常用方法。透過這些方法,你可以了解當前的工作執行緒、任務處理等情況。
(1)獲取執行狀態的執行緒總數
public int getRunningThreadCount() {
int rc = 0;
WorkQueue[] ws;
WorkQueue w;
if ((ws = workQueues) != null) {
for (int i = 1; i < ws.length; i += 2) {
if ((w = ws[i]) != null && w.isApparentlyUnblocked())
++rc;
}
}
return rc;
}
(2)獲取活躍執行緒數量
public int getActiveThreadCount() {
int r = (config & SMASK) + (int)(ctl >> AC_SHIFT);
return (r <= 0) ? 0 : r; // suppress momentarily negative values
}
(3)判斷ForkJoinPool是否空閑
public boolean isQuiescent() {
return (config & SMASK) + (int)(ctl >> AC_SHIFT) <= 0;
}
(4)獲取任務竊取數量
public long getStealCount() {
AtomicLong sc = stealCounter;
long count = (sc == null) ? 0 L : sc.get();
WorkQueue[] ws;
WorkQueue w;
if ((ws = workQueues) != null) {
for (int i = 1; i < ws.length; i += 2) {
if ((w = ws[i]) != null)
count += w.nsteals;
}
}
return count;
}
(5)獲取佇列中的任務數量
public long getQueuedTaskCount() {
long count = 0;
WorkQueue[] ws;
WorkQueue w;
if ((ws = workQueues) != null) {
for (int i = 1; i < ws.length; i += 2) {
if ((w = ws[i]) != null)
count += w.queueSize();
}
}
return count;
}
(6)獲取已送出的任務數量
public int getQueuedSubmissionCount() {
int count = 0;
WorkQueue[] ws;
WorkQueue w;
if ((ws = workQueues) != null) {
for (int i = 0; i < ws.length; i += 2) {
if ((w = ws[i]) != null)
count += w.queueSize();
}
}
return count;
}
四、警惕ForkJoinPool#commonPool
在上文中所示的源碼中,你可能已經在多處註意到commonPool的存在。在ForkJoinPool中,commonPool是一個 共享的、靜態的 執行緒池,並且在實際使用時才會進行懶載入, Java8中的CompletableFuture和並列流(Parallel Streams)用的就是它 。不過, 使用CompletableFuture時你可以指定自己的執行緒池,但是並列流在使用時卻不可以,這也是我們要警惕的地方 。
為什麽這麽說呢? ForkJoinPool中的commonPool設計初衷是為了降低執行緒池的重復建立,讓一些任務共用同一個執行緒池,畢竟建立執行緒池和建立執行緒都是昂貴的。然而,凡事都有兩面性,commonPool在某些場景下確實可以達到執行緒池復用的目的,但是, 如果你決定與別人分享自己空間,那麽當你想使用它的時候,它可能不再完全屬於你 。也就是說,當你想用commonPool時,它可能已經其他任務填滿了。
送出到ForkJoinPool中的任務一般有兩類: 計算型別 和 阻塞型別 。考慮一個場景,套用中多處都在使用這個共享執行緒池,有人在某處做了個不當操作,比如往池子裏丟入了阻塞型任務,那麽結果會怎樣?結果當然是, 整個執行緒池都有可能被阻塞 !如此, 整個套用都面臨著被拖垮的風險 。看到這裏,對於Java8中的並列流的使用,你就應該高度警惕了。
那怎麽避免這種情況發生呢?答案是盡量避免使用commonPool,並且在需要執行阻塞任務時,應當建立獨立的執行緒池,和系統的其他部份保持隔離,以免風險擴散。
五、ForkJoinPool效能評估
為了測試ForkJoinPool的效能,我做了一組 簡單的 、 非正式 實驗。實驗分三組進行,為了盡可能讓每組的數據客觀,每組實驗均執行5次,取最後的平均數。
實驗程式碼 :本文第一部份的範例程式碼;
實驗環境 :Mac;
JDK版本 :8;
任務分隔閾值 :100
實驗結果如下方表格所示:
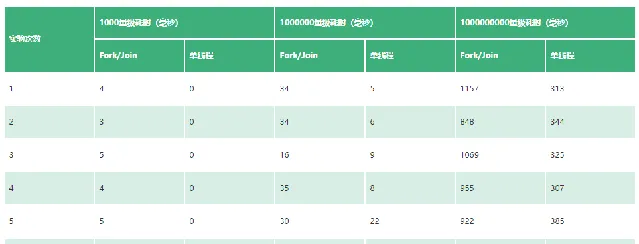
不要驚訝,之所以會出現這個令你匪夷所思的結果, 其原因在於任務拆分的粒度過小 !在上面的測試中,任務拆分閾值僅為100,導致Fork/Join在計算時出現大量的任務拆分動作,也就是任務分的太細,大量的任務拆分和管理也是需要額外成本的。
以0~1000000求和為例,當把閾值從 100 調整為 100000 時,其結果結果如下。可以看到,Fork/Join的優勢就體現出來了。
======
ForkJoin任務拆分:16383
ForkJoin計算結果:499999999500000000
ForkJoin計算耗時:143
======
單執行緒計算結果:499999999500000000
單執行緒計算耗時:410
那麽,問題又來了,哪些因素會影響Fork/Join的效能呢?
根據經驗和實驗, 任務總數 、 單任務執行耗時 以及 並列數 都會影響到效能。所以, 當你使用Fork/Join框架時,你需要謹慎評估這三個指標,最好能透過模擬對比評估,不要憑感覺冒然在生產環境使用 。
小結
以上就是關於ForkJoinPool的全部內容。Fork/Join是一種基於分治演算法的模型,在並行處理計算型任務時有著顯著的優勢。其效率的提升主要得益於兩個方面:
任務切分 :將大的任務分割成更小粒度的小任務,讓更多的執行緒參與執行;
任務竊取 :透過任務竊取,充分地利用空閑執行緒,並減少競爭。
在使用ForkJoinPool時,需要特別註意任務的型別是否為 純函式計算型別 ,也就是這些任務不應該關心狀態或者外界的變化,這樣才是最安全的做法。如果是阻塞型別任務,那麽你需要謹慎評估技術方案。雖然ForkJoinPool也能處理阻塞型別任務,但可能會帶來復雜的管理成本。
而在效能方面,要認識到Fork/Join的效能並不是開箱即來,而是需要你去評估和驗證一些重要指標,透過數據對比得出最佳結論。
此外,ForkJoinPool雖然提供了commonPool,但出於潛在的風險考慮,不推薦使用或謹慎使用。
如喜歡本文,請點選右上角,把文章分享到朋友圈
如有想了解學習的技術點,請留言給若飛安排分享
因公眾號更改推播規則,請點「在看」並加「星標」 第一時間獲取精彩技術分享
·END·
相關閱讀:
來源:網路
版權申明:內容來源網路,僅供學習研究,版權歸原創者所有。如有侵權煩請告知,我們會立即刪除並表示歉意。謝謝!
架構師
我們都是架構師!

關註 架構師(JiaGouX),添加「星標」
獲取每天技術幹貨,一起成為牛逼架構師
技術群請 加若飛: 1321113940 進架構師群
投稿、合作、版權等信箱: [email protected]











