大家好,我是程式設計師魚皮。今天給朋友們還原一個我們團隊真實的開發場景。
開發現場
最近我們編程導航網站要開發
使用者私信
功能,第一期要做的需求很簡單:
能讓兩個使用者之間 1 對 1 單獨發送訊息
使用者能夠檢視到訊息記錄
使用者能夠即時收到訊息通知
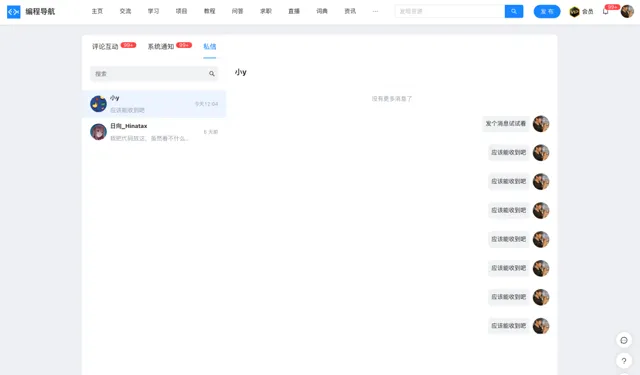
這其實是一個雙向即時通訊的場景,顯然可以使用 WebSocket 技術來實作。
團隊的後端開發小 c 拿到需求後就去調研了,最後打算采用 Spring Boot Starter 快速整合 Websocket 來實作,接受前端某個使用者傳來的訊息後,轉發到接受訊息的使用者的會話,並在資料庫中記錄,便於使用者檢視歷史。
小 c 的程式碼寫得還是不錯的,用了一些設計模式(像策略模式、工廠模式)對程式碼進行了一些抽象封裝。雖然在我看來對目前的需求來說稍微有點過度設計,但開發同學有自己的理由和想法,表示尊重~
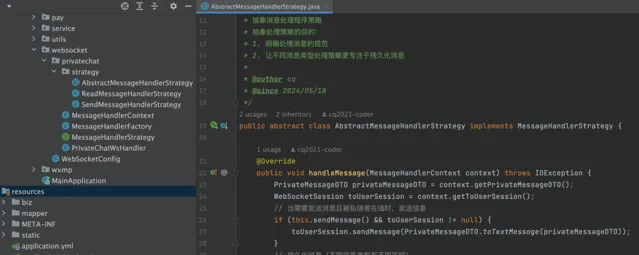
前端同學小 L 也很快完成了開發,並且透過了產品的驗收。
看似這個需求就圓滿地完成了,但直到我閱讀前端同學的程式碼時,才發現了一個 「坑」。
這是前端同學小 L 送出的私信功能程式碼,看到這裏我就已經發現問題了,朋友們能註意到麽?
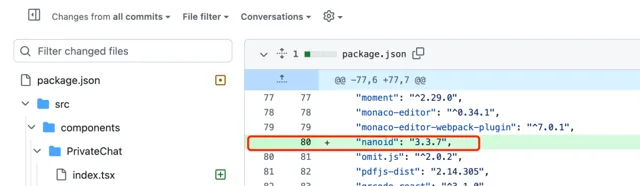
解釋一下,小 L 引入了一個
nanoid
庫,這個庫的作用是生成唯一 id。看到這裏,我本能地感到疑惑:為什麽要引入這個庫?為什麽前端要生成唯一 id?
難道。。。是作為私信訊息的 id?
果不其然,透過這個庫在前端給每個訊息生成了一個唯一 id,然後發送給後端。
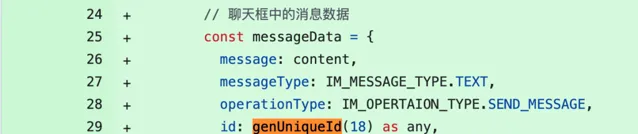
後端開發的同學可能會想:一般情況下不都是後端利用資料庫的自增來生成唯一 id 並返回給前端嘛,怎麽需要讓前端來生成呢?
這裏小 L 的解釋是,在本地建立訊息的時候,需要有一個 id 來追蹤狀態,不會出現訊息沒有 id 的情況。
首先,這麽做的確 能夠滿足需求 ,所以我還是透過了程式碼審查;但嚴格意義上來說,讓前端來生成唯一 id 其實不夠優雅,可能會有一些問題。
前端生成 id 的問題
1)ID 沖突:同時使用系統的前端使用者可能是非常多的,每個使用者都是一個客戶端,多個前端例項可能會生成相同的 ID,導致數據覆蓋或混亂。
2)不夠安全:切記,前端是沒有辦法保證安全性的!因為攻擊者可以篡改或偽造請求中的數據,比如構造一個已存在的 id,導致原本的數據被覆蓋掉,從而破壞數據的一致性。
要做這件事成本非常低,甚至不需要網路攻擊方面的知識,開啟 F12 瀏覽器控制台,重放個請求就行實作:
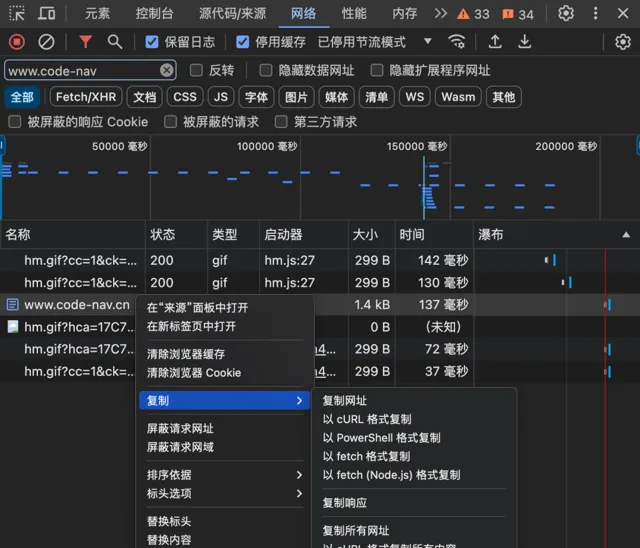
3)時間戳問題:某些生成 id 的演算法是依賴時間戳的,比如當前時間不同,生成的 id 就不同。但是如果前端不同使用者的電腦時間不一致,就可能會生成重復 id 或無效 id。比如使用者 A 電腦是 9 點時生成了 id = 06030901,另一個使用者 B 電腦時間比 A 慢了一個小時,現在是 8 點,等使用者 B 電腦時間為 9 點的時候,可能又生成了重復 id = 06030901,導致數據沖突。這也被稱為 「分布式系統中的全域時鐘問題」。
明確前後端職責
雖然 Nanoid 這個庫不依賴時間戳來生成 id,不會受到裝置時鐘不同步的影響,也不會因為時間戳重復而導致 ID 沖突。根據我查閱的資料,生成大約 10 ^ 9 個 ID 後,重復的可能性大約是 10 ^ -17,幾乎可以忽略不計。但一般情況下,我個人會更建議將業務邏輯統一放到後端實作,這麽做的好處有很多:
後端更容易保證數據的安全性,可以對數據先進行校驗再生成 id
前端盡量避免進行復雜的計算,而是交給後端,可以提升整體的效能
職責分離,前端專註於頁面展示,後端專註於業務,而不是雙方都要維護一套業務邏輯
我舉個典型的例子,比如前端下拉框內要展示一些可選項。由於選項的數量並不多,前端當然可以自己維護這些數據(一般叫做列舉值),但後端也會用到這些列舉值,雙方都寫一套列舉值,就很容易出現不一致的情況。推薦的做法是,讓後端返回列舉值給前端,前端不用重復編寫。
所以一般情況下,對於 id 的生成,建議統一交給後端實作,可以用雪花演算法根據時間戳生成,也可以利用資料庫主鍵生成自增 id 或 UUID,具體需求具體分析吧~
以上就是本期分享,幹飯去了 🍚~ 我們私信功能剛上線,
估計
Bug 不少,歡迎小夥伴們使用和反饋建議,魚皮原創的計畫教程都在編程導航:
https://code-nav.cn
👇🏻 點選下方閱讀原文,獲取魚皮往期編程幹貨。
往期推薦











