Transformer 已經成為了前沿人 AI 技術的代名詞,尤其是在自然語言處理(NLP)這一領域。
那麽,是什麽使得 Transformer 能夠如此高效準確地掌握語言的復雜性呢?
讓我們一起深入探索 Transformer 架構的核心原理。
但在此之前,不妨先看看它的套用場景。 無論是你使用的谷歌轉譯還是 ChatGPT,它們背後的強大功能都離不開 Transformer。
谷歌轉譯:這個被廣泛使用的工具在很大程度上依靠 Transformer 技術,實作了對超過 100 種語言的快速準確轉譯。它能夠考慮到整個句子的上下文,而非僅僅是單個詞語,使得轉譯結果更加自然流暢。
Netflix 推薦系統:Netflix 是如何精準推薦你可能喜歡的電影和電視劇的?答案是透過分析你的觀看歷史和其他使用者的數據,Transformer 能夠辨識出模式和聯系,最終向你推薦個人化的內容。
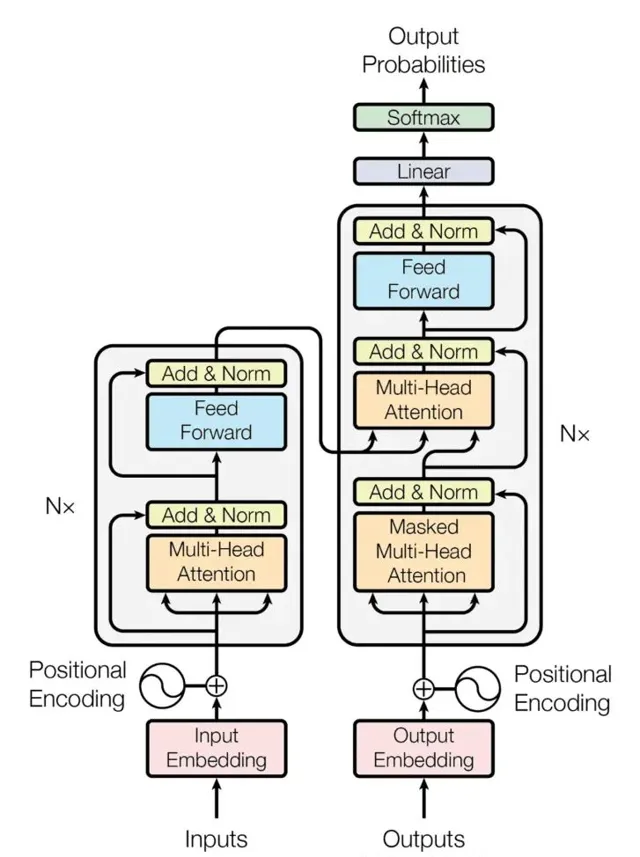
概覽:編解碼器交響
想象一個特殊的工廠,它不是在組裝物理產品,而是在加工處理語言。 這個工廠主要由兩個部份組成:
編碼器(Encoder):它負責提取資訊,透過細致分析輸入文本,理解文本中各個元素的含義,並行現它們之間的隱藏聯系。
解碼器(Decoder):依托編碼器提供的深入洞察,解碼器負責生成所需的輸出,無論是將句子轉譯成另一種語言、生成一個精確的摘要,還是創作一首全新的詩歌。
編碼器:解碼輸入迷宮
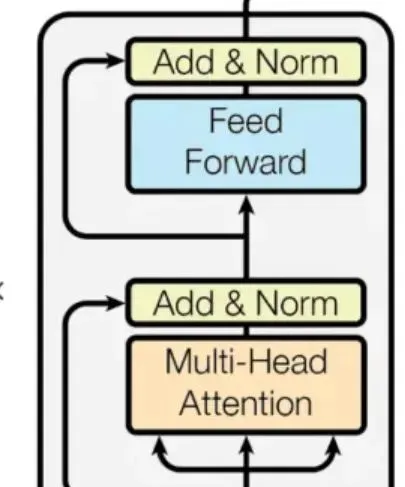
編碼器的旅程從 「輸入嵌入」 開始,此過程中,每個單詞都從文本形態轉換為數值向量,就好像給 每個單詞配上了一個獨一無二的身份證。
以這個例子為例:
輸入文本:例如,「The cat sat on the mat.」
在輸入嵌入層,每個單詞都被轉譯成一個數值向量,就像在一個龐大的字典裏,每個單詞都有一個對應的 「向量地址」。
這些向量不僅捕捉了單詞的含義,還包括:
語意關系(比如,「cat」 和 「pet」 更近,而不是和 「chair」);
句法角色(比如,「cat」 通常作為名詞,「sat」 作為動詞);
句中上下文(比如,這裏的 「mat」 很可能是指地墊)。
向量表示如下:
「The」 -> [0.2, 0.5, -0.1, ...]
「cat」 -> [0.8, -0.3, 0.4, ...]
「sat」 -> [-0.1, 0.7, 0.2, ...]
但編碼器的工作遠不止於此,它還使用了一些關鍵技術來進一步深入。
自註意力機制是其中的革命性創新。想象為對每個單詞開啟一束聚光燈,這束光不僅照亮了該單詞,還揭示了它與句中其他單詞的聯系。這讓編碼器能夠理解文本的全貌 —— 不只是孤立的單詞,還有它們之間的聯系和細微差別。
再次以句子 「The quick brown fox jumps over the lazy dog. 」 為例:
首先,每個單詞都轉換成了一個數值表示,稱為 「詞嵌入」,就像在一個巨大的詞庫地圖上給每個單詞定位。
接下來,自註意力機制為每個單詞生成了三個特殊的向量:「查詢(Query)」(詢問我需要什麽資訊)、「鍵(Key)」(標示我有什麽資訊)和 「值(Value)」(實際的含義和上下文)。
然後,透過比較每個單詞的 「查詢」 向量與其他所有單詞的 「鍵」 向量,自註意力層評估了各個單詞之間的相關性,並計算出註意力得分。這個得分越高,表示兩個單詞之間的聯系越緊密。
最後,自註意力層根據註意力得分加權處理 「值」 向量,這就像根據每個單詞與當前單詞的相關度,取了一個加權平均值。
透過考慮句中其他單詞提供的上下文,自註意力機制為每個單詞建立了一個新的、更豐富的表示。這種表示不僅包含了單詞本身的含義,還有它如何與句中其他單詞關聯和受到影響。
多頭註意力機制(Multi-Head Attention)可以被理解為有多個分析小組,每個小組關註於詞與詞之間聯系的不同層面。這使得編碼器能夠全面捕獲詞義之間的多元關系,從而深化其對語句的理解。
還是以句子:「The quick brown fox jumps over the lazy dog.」為例。
在多頭註意力機制中,不同於只使用一個自我關註機制,我們有多個獨立的 「頭部」(通常是 4 到 8 個)。每個頭部都針對每個詞分別維護一套查詢(Query)、鍵(Key)和值(Value)向量。
這種機制下的註意力是多樣化的:每個頭部根據不同的邏輯計算註意力得分,聚焦於詞間關系的不同方面:
一個頭部可能專註分析語法角色,比如 「fox」 和 「jumps」 之間的關系。
另一個可能關註詞序,比如 「the」 和 「quick」 之間的順序。
還有的頭部可能辨識同義詞或相關概念,例如將 「quick」 和 「fast」 視為相近的詞。
透過結合這些不同頭部的觀點,每個頭部的輸出被匯總,綜合不同的洞察力。
最終,這種綜合的表示形式包含了對句子更加豐富的理解,涵蓋了詞與詞之間的多樣化關系,而不僅僅是單一視角。
位置編碼(Positional Encoding)是為了補充 Transformer 無法直接處理詞序的不足,加入了每個詞在句中位置的資訊。 可以想象成給每個分析員一張地圖,指示他們應該如何按順序審視詞匯。
繼續以句子:「The quick brown fox jumps over the lazy dog.」 為例,來看位置編碼是如何工作的:
首先,每個詞(如 「The」,「quick」 等)都被轉換成一個唯一的數位向量,這就是所謂的單詞嵌入,可以看作是在龐大的詞庫中為每個詞分配的唯一標識。
接著,每個詞的嵌入會和一個基於其在句中位置計算出的額外向量結合。這些位置向量透過正弦和余弦函式生成,能夠反映詞之間的遠近關系。
低頻波動揭示詞之間的長距離關系。
高頻波動則關註緊密相連的詞。
這樣,每個詞的原始向量與其位置向量相加,形成了一個既含有詞義也含有位置資訊的新向量。
即便句子的順序變化,位置向量也能保持詞之間的相對位置關系,使得模型能準確理解詞與詞之間的連線。
前饋網路(FFN,Feed Forward Network)為模型增添了一層非線性處理,使其能夠學習到更為復雜的單詞間關系,這些關系可能單憑註意力機制難以捕捉。
透過前面幾層的分析,你已經深入理解了句中單詞的含義、它們之間的聯系以及它們的位置。現在,FFN 就像是一只偵探用的放大鏡,準備揭示那些不立即顯現的復雜細節。
FFN 透過以下三個關鍵步驟來實作這一目標:
非線性變換 :FFN 透過使用 ReLU 等非線性函式來增加資訊的復雜性,而非直接進行簡單計算。可以想象它為現有資訊施加了一個特殊的濾鏡,揭露了那些簡單運算可能忽視的隱藏模式和聯系。這使得 FFN 能夠把握詞與詞之間更加細膩的關系。
多層次分析 :FFN 不是單一步驟,而是通常由兩層或更多的全連線層組成。每一層都在前一層的基礎上進一步轉換資訊,就像你在不斷放大鏡下審視句子,每一層都揭示出更多細節。
維度變換 :在第一層,FFN 將資訊維度擴充套件(如從 512 維擴到 2048 維),以便分析更多特征並捕捉更復雜的模式。這就像是在更大的畫布上展開資訊進行深入審查。隨後,在最終層將資訊維度縮減回原始大小(比如又回到 512 維),確保與後續層的相容性。
套用到我們的句子上:
想象 FFN 幫助辨識 「quick」 和 「brown」 不僅描述了 「fox」,還透過它們聯合的含義巧妙地與 「fox」 的速度感聯系起來。
或者,它可能深入探究 「jumps」 和 「over」 之間的關系,理解這個動作和空間關系,超越了它們單獨的定義。
重復、最佳化、再重復:自註意力、多頭註意力等層被疊加並多次重復。每一次叠代,編碼器都在精細化其對輸入文本的理解,構建出一個全面的文本表征。
解碼器:編織輸出掛毯
現在,輪到解碼器承擔任務。與編碼器不同的是,解碼器面臨著額外的挑戰:在不預見未來的情況下,逐字生成輸出。為此,它采用了以下策略:
掩蔽自註意力 :類似於編碼器的自註意力機制,但有所調整。解碼器僅關註之前已生成的單詞,確保不會利用到未來的資訊。這就像是一次只寫出一個句子的故事,而不知道故事的結局。
編碼器 - 解碼器註意力 :這一機制允許解碼器參考編碼好的輸入,就像寫作時回頭檢視參考資料一樣。這確保了生成的輸出與原始文本保持一致性和連貫性。
多頭註意力和前饋網路 :與編碼器相同,這些層幫助解碼器深化對文本中上下文和關系的理解。
輸出層 :最終,解碼器將其內部表征逐一轉化為實際的輸出單詞。這就像是最後的裝配線,把所有部件組合起來,形成期望的結果。
超越基本概念
請記住,這只是 Transformer 世界迷人之處的一瞥。 具體的架構會根據任務和數據集的不同而有所變化,包括不同數量的層和配置。
此外,每一層涉及的復雜數學運算超出了本解釋的範圍。
但希望這能讓你基本理解 Transformer 如何工作,以及它們是如何徹底改變自然語言處理(NLP)領域的。
因此,當你下次遇到流暢的機器轉譯或對 AI 驅動的文本生成器的創意贊嘆時,請記住 Transformer 內部編碼器與解碼器之間的精妙互動,它們是如何透過註意力機制和並列處理技術共同織就這場魔法的。
論文連結:https://arxiv.org/abs/1706.03762
原文連結:https://nintyzeros.substack.com/p/how-do-transformer-workdesign-a-multi
T ransformer 是 LLM 背後的硬核技術,研究 T ransformer 技術對研究 LLM 至關重要 ,在 T ransformer 學習過程中,你有什麽問題和心得, 歡迎 進入 AI 大模型實驗室微信群一起交流。
如喜歡本文,請點選右上角,把文章分享到朋友圈
如有想了解學習的技術點,請留言給若飛安排分享
因公眾號更改推播規則,請點「在看」並加「星標」 第一時間獲取精彩技術分享
·END·
相關閱讀:
來源:AI大模型實驗室
版權申明:內容來源網路,僅供學習研究,版權歸原創者所有。如有侵權煩請告知,我們會立即刪除並表示歉意。謝謝!
架構師
我們都是架構師!

關註 架構師(JiaGouX),添加「星標」
獲取每天技術幹貨,一起成為牛逼架構師
技術群請 加若飛: 1321113940 進架構師群
投稿、合作、版權等信箱: [email protected]











