GPT-4o其實也做到了比較流利的即時對話,但是往往這些模型都需要外接一個TTS,就導致對話還是會產生延遲。
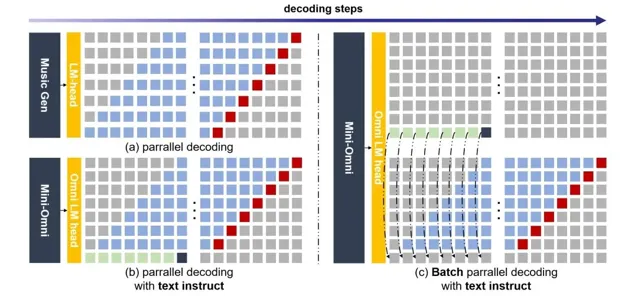
Mini-Omni采用了一種文本指令的語音生成方法,並在推理過程中批次並列進一步提升效能。
所以說Mini-Omni可能是第一個完整意義上的端到端即時語音互動模型。
掃碼加入AI交流群
獲得更多技術支持和交流
(請註明自己的職業)

計畫簡介
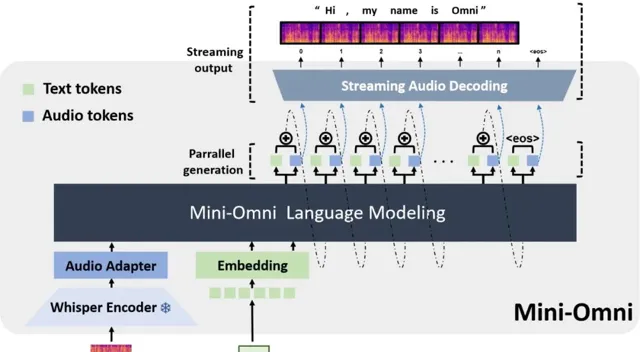
Mini-Omni是一個開源多模態大型語言模型,具備即時對話能力和端到端的語音輸入輸出功能。透過獨特的文本指導並列生成方法,實作了與文本能力一致的語音推理輸出,僅需極少的額外數據和模組。
Mini-Omni還引入了一種「任何模型都能說話」的創新方法,透過最小的訓練和修改,快速地將其他模型的文本處理能力轉換為語音互動能力。
DEMO
只能說,確實快。
這沒有延遲的感覺實在是太爽了!
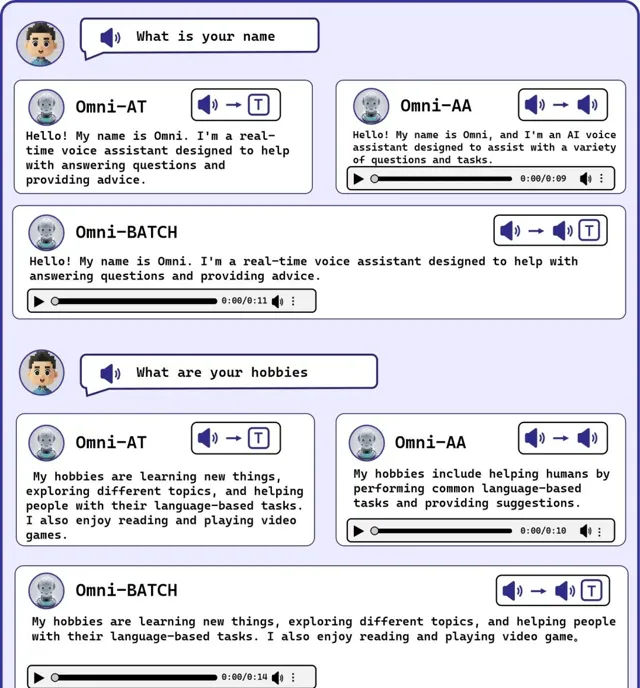
下面圖片是流式輸出的範例
主要特點和貢獻
·端到端的多模態互動能力:
Mini-Omni不僅支持文本輸入輸出,還能處理語音訊號,實作真正的語音到語音的交流,這一點是透過文本指導並列生成技術實作的。
·高效的即時對話能力:
透過創新的並列生成和批次處理並列解碼技術,Mini-Omni能夠在對話中即時響應,顯著減少了延遲,提高了互動的自然流暢性。
·模型和數據效率:
該模型使用的是比較小的0.5B參數規模,但透過高效的訓練和最佳化策略,實作了與大模型相媲美的效能,特別是在資源有限的環境下表現出色。
·"任何模型都能說話"的方法:
這是一種新穎的方法,允許透過最小的訓練和修改,迅速將其他語言模型的文本處理能力擴充套件到語音互動領域。
·專門最佳化的數據集VoiceAssistant-400K:
為了訓練和最佳化語音輸出,Mini-Omni使用了特別開發的VoiceAssistant-400K數據集,該數據集旨在幫助模型在提供語音助手服務時減少生成程式碼符號,增強模型在真實套用中的實用性。
計畫連結
https://github.com/gpt-omni/mini-omni
關註「 開源AI計畫落地 」公眾號
與AI時代更靠近一點
關註「 向量光年 」公眾號
加速全行業向AI轉變
關註「 AGI光年 」公眾號
獲取每日最新資訊











