今天就應某位小夥伴的要求,來講一講Nacos作為服務註冊中心底層的實作原理
不知你是否跟我一樣,在使用Nacos時有以下幾點疑問:
臨時例項和永久例項是什麽?有什麽區別?
服務例項是如何註冊到伺服端的?
服務例項和伺服端之間是如何保活的?
服務訂閱是如何實作的?
集群間數據是如何同步的?CP還是AP?
Nacos的數據模型是什麽樣的?
...
本文就透過探討上述問題來探秘Nacos服務註冊中心核心的底層實作原理。
雖然Nacos最新版本已經到了2.x版本,但是為了照顧那些還在用1.x版本的同學,所以本文我會同時去講1.x版本和2.x版本的實作
觀前提醒,本文又又又是一篇超長的幹貨,非常適合一鍵三連~~
臨時例項和永久例項
臨時例項和永久例項在Nacos中是一個 非常非常重要 的概念
之所以說它重要,主要是因為我在讀源碼的時候發現,臨時例項和永久例項在底層的許多實作機制是完全不同的
臨時例項
臨時例項在註冊到註冊中心之後僅僅只保存在伺服端內部一個緩存中,不會持久化到磁盤
這個伺服端內部的緩存在註冊中心屆一般被稱為 服務登錄檔
當服務例項出現異常或者下線之後,就會把這個服務例項從服務登錄檔中剔除
永久例項
永久服務例項不僅僅會存在服務登錄檔中,同時也會被持久化到磁盤檔中
當服務例項出現異常或者下線,Nacos只會將服務例項的健康狀態設定為不健康,並不會對將其從服務登錄檔中剔除
所以這個服務例項的資訊你還是可以從註冊中心看到,只不過處於不健康狀態
這是就是兩者最最最基本的區別
當然除了上述最基本的區別之外,兩者還有很多其它的區別,接下來本文還會提到
這裏你可能會有一個疑問
為什麽Nacos要將服務例項分為臨時例項和永久例項?
主要還是因為套用場景不同
臨時例項 就比較適合於業務服務,服務下線之後可以不需要在註冊中心中檢視到
永久例項 就比較適合需要運維的服務,這種服務幾乎是永久存在的,比如說MySQL、Redis等等
MySQL、Redis等服務例項可以透過SDK手動註冊
對於這些服務,我們需要一直看到服務例項的狀態,即使出現異常,也需要能夠檢視時實的狀態
所以從這可以看出Nacos跟你印象中的註冊中心不太一樣,他不僅僅可以註冊平時業務中的例項,還可以註冊像MySQL、Redis這個服務例項的資訊到註冊中心
在SpringCloud環境底下,一般其實都是業務服務,所以預設註冊服務例項都是臨時例項
當然如果你想改成永久例項,可以透過下面這個配置項來完成
spring
cloud:
nacos:
discovery:
#ephemeral單詞是臨時的意思,設定成false,就是永久例項了
ephemeral:false
這裏還有一個小細節
在1.x版本中,一個服務中可以既有臨時例項也有永久例項,服務例項是永久還是臨時是由服務例項本身決定的
但是2.x版本中,一個服務中的所有例項要麽都是臨時的要麽都是永久的,是由服務決定的,而不是具體的服務例項
所以在2.x可以說是 臨時服務 和 永久服務

為什麽2.x把臨時還是永久的內容由例項本身決定改成了由服務決定?
其實很簡單,你想想,假設對一個MySQL服務來說,它的每個服務例項肯定都是永久的,不會出現一些是永久的,一些是臨時的情況吧
所以臨時還是永久的內容由服務本身決定其實就更加合理了
服務註冊
作為一個服務註冊中心,服務註冊肯定是一個非常重要的功能
所謂的服務註冊,就是透過註冊中心提供的客戶端SDK(或者是控制台)將服務本身的一些元資訊,比如ip、埠等資訊發送到註冊中心伺服端
伺服端在接收到服務之後,會將服務的資訊保存到前面提到的服務登錄檔中
1、1.x版本的實作
在Nacos在1.x版本的時候,服務註冊是透過Http介面實作的
程式碼如下
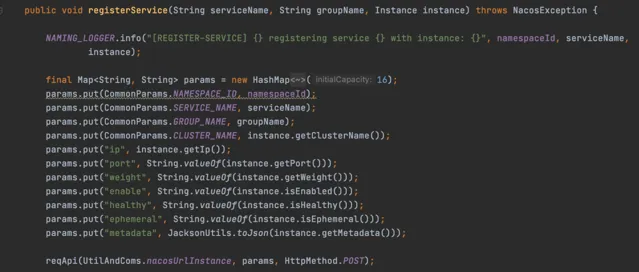
整個邏輯比較簡單,因為Nacos伺服端本身就是用SpringBoot寫的
但是在2.x版本的實作就比較復雜了
2、2.x版本的實作
2.1、通訊協定的改變
2.x版本相比於1.x版本最主要的升級就是客戶端和伺服端通訊協定的改變,由1.x版本的Http改成了2.x版本gRPC
gRPC是谷歌公司開發的一個高效能、開源和通用的RPC框架,Java版本的實作底層也是基於Netty來的
之所以改成了gRPC,主要是因為Http請求會頻繁建立和銷毀連線,白白浪費資源
所以在2.x版本之後,為了提升效能,就將通訊協定改成了gRPC
根據官網顯示,整體的效果還是很明顯,相比於1.x版本,註冊效能總體提升至少2倍
雖然通訊方式改成了gRPC,但是2.x版本伺服端依然保留了Http註冊的介面,所以用1.x的Nacos SDK依然可以註冊到2.x版本的伺服端
2.2、具體的實作
Nacos客戶端在啟動的時候,會透過gRPC跟伺服端建立長連線
這個連線會一直存在,之後客戶端與伺服端所有的通訊都是基於這個長連線來的
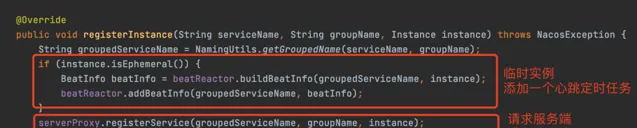
當客戶端發起註冊的時候,就會透過這個長連線,將服務例項的資訊發送給伺服端
伺服端拿到服務例項,跟1.x一樣,也會存到服務登錄檔
除了註冊之外, 當註冊的是臨時例項時 ,2.x還會將服務例項資訊儲存到客戶端中的一個緩存中,供Redo操作
所謂的Redo操作,其實就是一個補償機制,本質是個定時任務,預設每3s執行一次
這個定時任務作用是,當客戶端與伺服端重新建立連線時(因為一些異常原因導致連線斷開)
那麽之前註冊的服務例項肯定還要繼續註冊伺服端(斷開連線服務例項就會被剔除服務登錄檔)
所以這個Redo操作一個很重要的作用就是重連之後的重新註冊的作用
除了註冊之外,比如服務訂閱之類的操作也需要Redo操作,當連線重新建立,之前客戶端的操作都需要Redo一下
小總結
1.x版本是透過Http協定來進行服務註冊的
2.x由於客戶端與伺服端的通訊改成了gRPC長連線,所以改成透過gRPC長連線來註冊
2.x比1.x多個Redo操作,當註冊的服務例項是臨時例項是,出現網路異常,連線重新建立之後,客戶端需要將服務註冊、服務訂閱之類的操作進行重做
這裏你可能會有個疑問
既然2.x有Redo機制保證客戶端與伺服端通訊正常之後重新註冊,那麽1.x有類似的這種Redo機制麽?
當然也會有,接下往下看。
心跳機制
心跳機制,也可以被稱為 保活機制 ,它的作用就是服務例項告訴註冊中心我這個服務例項還活著
在正常情況下,服務關閉了,那麽服務會主動向Nacos伺服端發送一個服務下線的請求
Nacos伺服端在接收到請求之後,會將這個服務例項從服務登錄檔中剔除
但是對於異常情況下,比如出現網路問題,可能導致這個註冊的服務例項無法提供服務,處於不可用狀態,也就是不健康
而此時在沒有任何機制的情況下,伺服端是無法知道這個服務處於不可用狀態
所以為了避免這種情況,一些註冊中心,就比如Nacos、Eureka,就會用心跳機制來判斷這個服務例項是否能正常
在Nacos中,心跳機制僅僅是針對臨時例項來說的,臨時例項需要靠心跳機制來保活
心跳機制在1.x和2.x版本的實作也是不一樣的
1.x心跳實作
在1.x中,心跳機制實作是透過客戶端和伺服端各存在的一個定時任務來完成的
在服務註冊時,發現是臨時例項,客戶端會開啟一個5s執行一次的定時任務
這個定時任務會構建一個Http請求,攜帶這個服務例項的資訊,然後發送到伺服端
在Nacos伺服端也會開啟一個定時任務,預設也是5s執行一次,去檢查這些服務例項最後一次心跳的時間,也就是客戶端最後一次發送Http請求的時間
當最後一次心跳時間超過15s,但沒有超過30s,會把這服務例項標記成不健康
當最後一次心跳超過30s,直接把服務從服務登錄檔中剔除
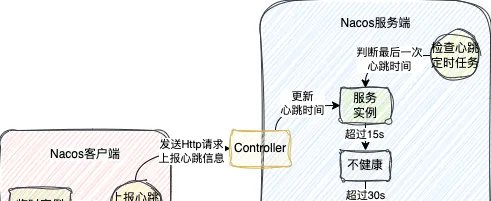
這就是1.x版本的心跳機制,本質就是兩個定時任務
其實1.x的這個心跳還有一個作用,就是跟上一節說的gRPC時Redo操作的作用是一樣的
服務在處理心跳的時候,發現心跳攜帶這個服務例項的資訊在登錄檔中沒有,此時就會添加到服務登錄檔
所以心跳也有Redo的類似效果
2.x心跳實作
在2.x版本之後,由於通訊協定改成了gRPC,客戶端與伺服端保持長連線,所以2.x版本之後它是利用這個gRPC長連線本身的心跳來保活
一旦這個連線斷開,伺服端就會認為這個連線註冊的服務例項不可用,之後就會將這個服務例項從服務登錄檔中提出剔除
除了連線本身的心跳之外,Nacos還有伺服端的一個主動檢測機制
Nacos伺服端也會啟動一個定時任務,預設每隔3s執行一次
這個任務會去檢查超過20s沒有發送請求數據的連線
一旦發現有連線已經超過20s沒發送請求,那麽就會向這個連線對應的客戶端發送一個請求
如果請求不通或者響應失敗,此時伺服端也會認為與客戶端的這個連線異常,從而將這個客戶端註冊的服務例項從服務登錄檔中剔除
所以對於2.x版本,主要是兩種機制來進行保活:
連線本身的心跳機制,斷開就直接剔除服務例項
Nacos主動檢查機制,伺服端會對20s沒有發送數據的連線進行檢查,出現異常時也會主動斷開連線,剔除服務例項
小總結
心跳機制僅僅針對臨時例項而言
1.x心跳機制是透過客戶端和伺服端兩個定時任務來完成的,客戶端定時上報心跳資訊,伺服端定時檢查心跳時間,超過15s標記不健康,超過30s直接剔除
1.x心跳機制還有類似2.x的Redo作用,伺服端發現心跳的服務資訊不存在會,會將服務資訊添加到登錄檔,相當於重新註冊了
2.x是基於gRPC長連線本身的心跳機制和伺服端的定時檢查機制來的,出現異常直接剔除
健康檢查
前面說了,心跳機制僅僅是臨時例項用來保護的機制
而對於永久例項來說,一般來說無法主動上報心跳
就比如說MySQL例項,肯定是不會主動上報心跳到Nacos的,所以這就導致無法透過心跳機制來保活
所以針對永久例項的情況,Nacos透過一種叫 健康檢查 的機制去判斷服務例項是否活著
健康檢查跟心跳機制剛好相反,心跳機制是服務例項向伺服端發送請求
而所謂的健康檢查就是伺服端 主動 向服務例項發送請求,去探測服務例項是否活著
健康檢查機制在1.x和2.x的實作機制是一樣的
Nacos伺服端在會去建立一個健康檢查任務,這個任務每次執行時間間隔會在2000~7000毫秒之間
當任務觸發的時候,會根據設定的健康檢查的方式執行不同的邏輯,目前主要有以下三種方式:
TCP
HTTP
MySQL
TCP 的方式就是根據服務例項的ip和埠去判斷是否能連線成功,如果連線成功,就認為健康,反之就任務不健康
HTTP 的方式就是向服務例項的ip和埠發送一個Http請求,請求路徑是需要設定的,如果能正常請求,說明例項健康,反之就不健康
MySQL 的方式是一種特殊的檢查方式,他可以執行下面這條Sql來判斷資料庫是不是主庫
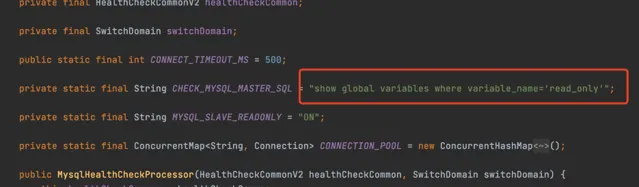
預設情況下,都是透過TCP的方式來探測服務例項是否還活著
服務發現
所謂的服務發現就是指當有服務例項註冊成功之後,其它服務可以發現這些服務例項
Nacos提供了兩種發現方式:
主動查詢
服務訂閱
主動查詢 就是指客戶端主動向伺服端查詢需要關註的服務例項,也就是拉(pull)的模式
服務訂閱 就是指客戶端向伺服端發送一個訂閱服務的請求,當被訂閱的服務有資訊變動就會主動將服務例項的資訊推播給訂閱的客戶端,本質就是推(push)模式
在我們平時使用時,一般來說都是選擇使用訂閱的方式,這樣一旦有服務例項數據的變動,客戶端能夠第一時間感知
並且Nacos在整合SpringCloud的時候,預設就是使用訂閱的方式
對於這兩種服務發現方式,1.x和2.x版本實作也是不一樣
服務查詢其實兩者實作都很簡單
1.x整體就是發送Http請求去查詢服務例項,2.x只不過是將Http請求換成了gRPC的請求
伺服端對於查詢的處理過程都是一樣的,從服務登錄檔中查出符合查詢條件的服務例項進行返回
不過對於服務訂閱,兩者的機制就稍微復雜一點
在Nacos客戶端,不論是1.x還是2.x都是透過SDK中的
NamingService#subscribe
方法來發起訂閱的
當有服務例項數據變動的時,客戶端就會回呼
EventListener
,就可以拿到最新的服務例項數據了
雖然1.x還是2.x都是同樣的方法,但是具體的實作邏輯是不一樣的
1.x服務訂閱實作
在1.x版本的時候,服務訂閱的處理邏輯大致會有以下三步:
第一步,客戶端在啟動的時候,會去構建一個叫PushReceiver的類
這個類會去建立一個UDP Socket,埠是隨機的
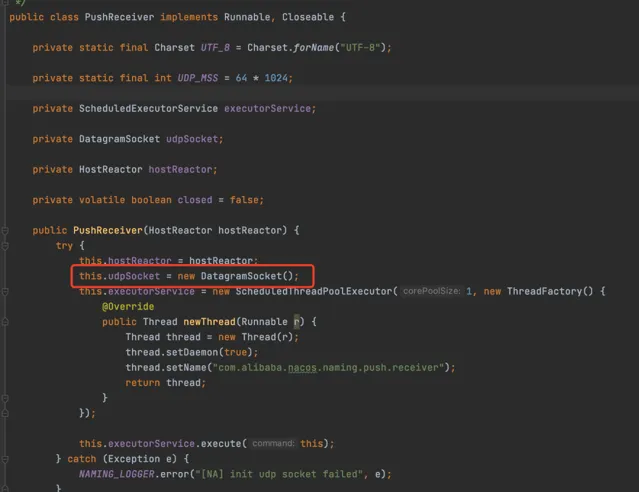
其實透過名字就可以知道這個類的作用,就是透過UDP的方式接收伺服端推播的數據的
第二步,呼叫
NamingService#subscribe
來發起訂閱時,會先去伺服端查詢需要訂閱服務的所有例項資訊
之後會將所有服務例項數據存到客戶端的一個 內部緩存中
並且在查詢的時候,會將這個UDP Socket的埠作為一個參數傳到伺服端
伺服端接收到這個UDP埠後,後續就透過這個埠給客戶端推播服務例項數據
第三步,會為這次訂閱開啟一個不定時執行的任務
之所以不定時,是因為這個當執行異常的時候,下次執行的時間間隔就會變長,但是最多不超過60s,正常是10s,這個10s是查詢服務例項是伺服端返回的
這個任務會去從伺服端查詢訂閱的服務例項資訊,然後更新內部緩存
這裏你可能會有個疑問
既然有了服務變動推播的功能,為什麽還要定時去查詢更新服務例項資訊呢?
其實很簡單,那就是因為UDP通訊不穩定導致的
雖然有Push,但是由於UDP通訊自身的不確定性,有可能會導致客戶端接收變動資訊失敗
所以這裏就加了一個定時任務,彌補這種可能性,屬於一個兜底的方案。
這就是1.x版本的服務訂閱的實作
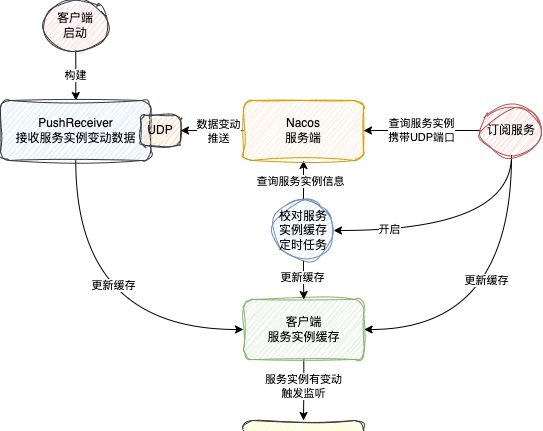
2.x服務訂閱的實作
講完1.x的版本實作,接下來就講一講2.x版本的實作
由於2.x版本換成了gRPC長連線的方式,所以2.x版本服務數據變更推播已經完全拋棄了1.x的UDP做法
當有服務例項變動的時候,伺服端直接透過這個長連線將服務資訊發送給客戶端
客戶端拿到最新服務例項數據之後的處理方式就跟1.x是一樣了
除了處理方式一樣,2.x也繼承了1.x的其他的東西
比如客戶端依然會有服務例項的緩存
定時對比機制也保留了,只不過這個定時對比的機制預設是關閉狀態
之所以預設關閉,主要還是因為長連線還是比較穩定的原因
當客戶端出現異常,接收不到請求,那麽伺服端會直接跟客戶端斷開連線
當恢復正常,由於有Redo操作,所以還是能拿到最新的例項資訊的
所以2.x版本的服務訂閱功能的實作大致如下圖所示
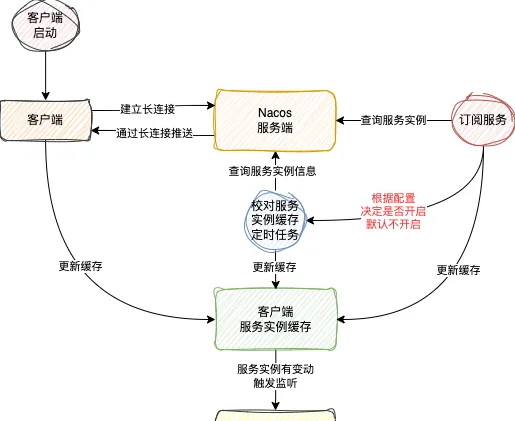
這裏還有個細節需要註意
在1.x版本的時候,任何服務都是可以被訂閱的
但是在2.x版本中,只支持訂閱臨時服務,對於永久服務,已經不支持訂閱了
小總結
服務查詢1.x是透過Http請求;2.x透過gRPC請求
服務訂閱1.x是透過UDP來推播的;2.x就基於gRPC長連線來實作的
1.x和2.x客戶端都有服務例項的緩存,也有定時對比機制,只不過1.x會自動開啟;2.x提供了一個開個,可以手動選擇是否開啟,預設不開啟
數據一致性
由於Nacos是支持集群模式的,所以一定會涉及到分布式系統中不可避免的數據一致性問題
1、服務例項的責任機制
再說數據一致性問題之前,先來討論一下服務例項的責任機制
什麽是服務例項的責任機制?
比如上面提到的服務註冊、心跳管理、監控檢查機制,當只有一個Nacos服務時,那麽自然而言這個服務會去檢查所有的服務例項的心跳時間,執行所有服務例項的健康檢查任務
但是當出現Nacos服務出現集群時,為了平衡各Nacos服務的壓力,Nacos會根據一定的規則讓每個Nacos服務只管理一部份服務例項的
當然每個Nacos服務的登錄檔還是全部的服務例項數據
這個管理機制我給他起了一個名字,就叫做責任機制,因為我在1.x和2.x都提到了
responsible
這個單詞
本質就是Nacos服務對哪些服務例項負有心跳監測,健康檢查的責任。
2、CAP定理和BASE理論
談到數據一致性問題,一定離不開兩個著名分布式理論
CAP定理
BASE理論
CAP定理中,三個字母分別代表這些含義:
C,Consistency單詞的縮寫,代表一致性,指分布式系統中各個節點的數據保持強一致,也就是每個時刻都必須一樣,不一樣整個系統就不能對外提供服務
A,Availability單詞的縮寫,代表可用性,指整個分布式系統保持對外可用,即使從每個節點獲取的數據可能都不一樣,只要能獲取到就行
P,Partition tolerance單詞的縮寫,代表分區容錯性。
所謂的CAP定理,就是指在一個分布式系統中,CAP這三個指標,最多同時只能滿足其中的兩個,不可能三個都同時滿足
為什麽三者不能同時滿足?
對於一個分布式系統,網路分區是一定需要滿足的
而所謂分區指的是系統中的服務部署在不同的網路區域中
比如,同一套系統可能同時在北京和上海都有部署,那麽他們就處於不同的網路分區,就可能出現無法互相存取的情況
當然,你也可以把所有的服務都放在一個網路分區,但是當網路出現故障時,整個系統都無法對外提供服務,那這還有什麽意義呢?
所以分布式系統一定需要滿足分區容錯性,把系統部署在不同的區域網路中
此時只剩下了一致性和可用性,它們為什麽不能同時滿足?
其實答案很簡單,就因為可能出現網路分區導致的通訊失敗。
比如說,現在出現了網路分區的問題,上圖中的A網路區域和B網路區域無法相互存取
此時假設往上圖中的A網路區域發送請求,將服務中的一個值 i 內容設定成 1
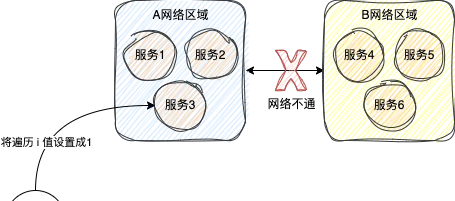
如果保證可用性 ,此時由於A和B網路不通,此時只有A中的服務修改成功,B無法修改成功,此時數據AB區域數據就不一致性,也就沒有保證數據一致性
如果保證一致性 ,此時由於A和B網路不通,所以此時A也不能修改成功,必須修改失敗,否則就會導致AB數據不一致
雖然A沒修改成功,保證了數據一致性,AB還是之前相同的數據,但是此時整個系統已經沒有寫可用性了,無法成功寫數據了。
所以從上面分析可以看出,在有分區容錯性的前提下,可用性和一致性是無法同時保證的。
雖然無法同時一致性和可用性,但是能不能換種思路來思考一下這個問題
首先我們可以先保證系統的可用性,也就是先讓系統能夠寫數據,將A區域服務中的i修改成1
之後當AB區域之間網路恢復之後,將A區域的i值復制給B區域,這樣就能夠保證AB區域間的數據最終是一致的了
這不就皆大歡喜了麽
這種思路其實就是BASE理論的核心要點,優先保證可用性,數據最終達成一致性。
BASE理論主要是包括以下三點:
基本可用(Basically Available):系統出現故障還是能夠對外提供服務,不至於直接無法用了
軟狀態(Soft State):允許各個節點的數據不一致
最終一致性,(Eventually Consistent):雖然允許各個節點的數據不一致,但是在一定時間之後,各個節點的數據最終需要一致的
BASE理論其實就是妥協之後的產物。
3、Nacos的AP和CP
Nacos其實目前是同時支持AP和CP的
具體使用AP還是CP得取決於Nacos內部的具體功能,並不是有的文章說的可以透過一個配置自由切換。
就以服務註冊舉例來說,對於臨時例項來說,Nacos會優先保證可用性,也就是AP
對於永久例項,Nacos會優先保證數據的一致性,也就是CP
接下來我們就來講一講Nacos的CP和AP的實作原理
3.1、Nacos的AP實作
對於AP來說,Nacos使用的是阿裏自研的Distro協定
在這個協定中,每個伺服端節點是一個平等的狀態,每個伺服端節點正常情況下數據是一樣的,每個伺服端節點都可以接收來自客戶端的讀寫請求
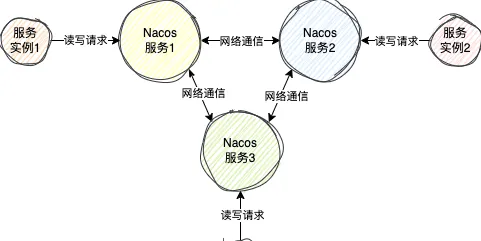
當某個節點剛啟動時,他會向集群中的某個節點發送請求,拉取所有的服務例項數據到自己的服務登錄檔中
這樣其它客戶端就可以從這個服務節點中獲取到服務例項數據了
當某個伺服端節點接收到註冊 臨時服務例項 的請求,不僅僅會將這個服務例項存到自身的服務登錄檔,同時也會向其它所有服務節點發送請求,將這個服務數據同步到其它所有節點
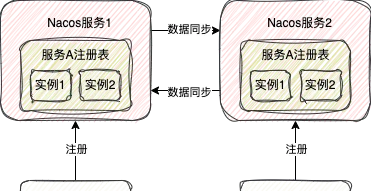
所以此時從任意一個節點都是可以獲取到所有的服務例項數據的。
即使數據同步的過程發生異常,服務例項也成功註冊到一個Nacos服務中,對外部而言,整個Nacos集群是可用的,也就達到了AP的效果
同時為了滿足BASE理論,Nacos也有下面兩種機制保證最終節點間數據最終是一致的:
失敗重試機制
定時對比機制
失敗重試機制 是指當數據同步給其它節點失敗時,會每隔3s重試一次,直到成功
定時對比機制 就是指,每個Nacos服務節點會定時向所有的其它服務節點發送一些認證的請求
這個請求會告訴每個服務節點 自己負責的服務例項 的對應的版本號,這個版本號隨著服務例項的變動就會變動
如果其它服務節點的數據的版本號跟自己的對不上,那就說明其它服務節點的數據不是最新的
此時這個Nacos服務節點就會將自己負責的服務例項數據發給不是最新數據的節點,這樣就保證了每個節點的數據是一樣的了。
3.2、Nacos的CP實作
Nacos的CP實作是基於Raft演算法來實作的
在1.x版本早期,Nacos是自己手動實作Raft演算法
在2.x版本,Nacos移除了手動實作Raft演算法,轉而擁抱基於螞蟻開源的JRaft框架
在Raft演算法,每個節點主要有三個狀態
Leader,負責所有的讀寫請求,一個集群只有一個
Follower,從節點,主要是負責復制Leader的數據,保證數據的一致性
Candidate,候選節點,最終會變成Leader或者Follower
集群啟動時都是節點Follower,經過一段時間會轉換成Candidate狀態,再經過一系列復雜的選擇演算法,選出一個Leader

這個選舉演算法比較復雜,完全值得另寫一篇文章,這裏就不細說了。不過立個flag,如果本篇文章點贊量超過28個,我連夜爆肝,再來一篇。
當有寫請求時,如果請求的節點不是Leader節點時,會將請求轉給Leader節點,由Leader節點處理寫請求
比如,有個客戶端連到的上圖中的
Nacos服務2
節點,之後向
Nacos服務2
註冊服務
Nacos服務2
接收到請求之後,會判斷自己是不是Leader節點,發現自己不是
此時
Nacos服務2
就會向Leader節點發送請求,Leader節點接收到請求之後,會處理服務註冊的過程
為什麽說Raft是保證CP的呢?
主要是因為Raft在處理寫的時候有一個判斷過程
首先,Leader在處理寫請求時,不會直接數據套用到自己的系統,而是先向所有的Follower發送請求,讓他們先處理這個請求
當超過半數的Follower成功處理了這個寫請求之後,Leader才會寫數據,並返回給客戶端請求處理成功
如果超過一定時間未收到超過半數處理成功Follower的訊號,此時Leader認為這次寫數據是失敗的,就不會處理寫請求,直接返回給客戶端請求失敗
所以,一旦發生故障,導致接收不到半數的Follower寫成功的響應,整個集群就直接寫失敗,這就很符合CP的概念了。
不過這裏還有一個小細節需要註意
Nacos在處理查詢服務例項的請求直接時,並不會將請求轉發給Leader節點處理,而是直接查當前Nacos服務例項的登錄檔
這其實就會引發一個問題
如果客戶端查詢的Follower節點沒有及時處理Leader同步過來的寫請求(過半響應的節點中不包括這個節點),此時在這個Follower其實是查不到最新的數據的,這就會導致數據的不一致
所以說,雖然Raft協定規定要求從Leader節點查最新的數據,但是Nacos至少在讀服務例項數據時並沒有遵守這個協定
當然對於其它的一些數據的讀寫請求有的還是遵守了這個協定。
JRaft對於讀請求其實是做了很多最佳化的,其實從Follower節點透過一定的機制也是能夠保證讀到最新的數據
數據模型
在Nacos中,一個服務的確定是由三部份資訊確定
名稱空間(Namespace):多租戶隔離用的,預設是
public
分組(Group):這個其實可以用來做環境隔離,服務註冊時可以指定服務的分組,比如是測試環境或者是開發環境,預設是
DEFAULT_GROUP
服務名(ServiceName):這個就不用多說了
透過上面三者就可以確定同一個服務了
在服務註冊和訂閱的時候,必須要指定上述三部份資訊,如果不指定,Nacos就會提供預設的資訊
不過,在Nacos中,在服務裏面其實還是有一個集群的概念
在服務註冊的時候,可以指定這個服務例項在哪個集體的集群中,預設是在
DEFAULT
集群下
在SpringCloud環境底下可以透過如下配置去設定
spring
cloud:
nacos:
discovery:
cluster-name:sanyoujavaCluster
在服務訂閱的時候,可以指定訂閱哪些集群下的服務例項
當然,也可以不指定,如果不指定話,預設就是訂閱這個服務下的所有集群的服務例項
我們日常使用中可以將部署在相同區域的服務劃分為同一個集群,比如杭州屬於一個集群,上海屬於一個集群
這樣服務呼叫的時候,就可以優先使用同一個地區的服務了,比跨區域呼叫速度更快。
總結
到這,終終終於總算是講完了Nacos作為註冊中心核心的實作原理
這篇文章從最開始的翻源碼、查資料到最終完成,前前後後也肝了大半個月的時間,橫跨了2023和2024,碼了上萬字
不知道你讀完整篇文章是否有所收貨
不過有一點可以確定的是,能夠看到這裏的那一定都是真愛粉了
2024年到了,這裏也祝大家身體健康,升職加薪,今年我也會繼續輸出硬核幹貨文章
好了,本文就講到這裏,如果覺得本篇對你有點幫助,歡迎點贊、在看、收藏、轉發分享給其他需要的人,你的支持就是我更新的最大動力,感謝感謝!
如此裁員+AI浪潮下,作為程式設計師的你,還沒用過ChatGPT4o嗎?還沒用過Copilot嗎?
國內直接使用ChatGPT4o:
谷歌瀏覽器直接使用:https://www.nezhasoft.cn
無需魔法,同時支持手機、電腦
個人獨享
ChatGPT4o mini永久免費
支持Copilot、DALLE AI繪畫、上傳檔等
長按辨識下方二維碼,備註ai,發給你
回復gpt,獲取ChatGPT4o直接使用地址
點選閱讀原文,國內直接使用ChatGpt4o











