點選上方 「 Linux開源社群 」,選擇「 設為星標 」
優質文章,及時送達
轉自:Linux開發架構之路
DMA
直接記憶體存取(Direct Memory Access)
什麽是DMA?
在進行數據傳輸的時候,數據搬運的工作全部交給 DMA 控制器,而 CPU 不再參與,可以去幹別的事情。
傳統I/O
在沒有 DMA 技術前,全程數據拷貝都需要CPU來做,嚴重消耗CPU。

利用DMA的IO
利用DMA之後:
4次數據拷貝,其中DMA和CPU分別拷貝2次(CPU的時間多寶貴啊)
2次系統呼叫導致的 4 次 使用者態與內核態的 上下文切換
DMA 控制器進行數據傳輸的過程:
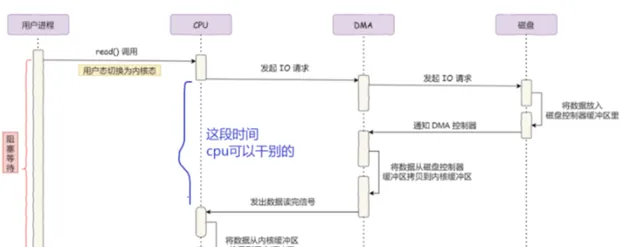
使用者行程呼叫 read 方法,向作業系統發出 I/O 請求,請求讀取數據到自己的使用者緩沖區中,行程進入阻塞狀態,使用者態切換至內核態;
作業系統收到請求後,進一步將 I/O 請求發送 DMA,然後讓 CPU 可以執行其他任務;
DMA 進一步將 I/O 請求發送給磁盤;
磁盤收到 DMA 的 I/O 請求,把數據從磁盤讀取到磁盤控制器的緩沖區中,當磁盤控制器的緩沖區被讀滿後,向 DMA 發起中斷訊號,告知自己緩沖區已滿;
DMA 收到磁盤的訊號,將磁盤控制器緩沖區中的數據拷貝到內核緩沖區中,此時不占用 CPU,CPU 可以執行其他任務;
當 DMA 讀取了足夠多的數據,就會發送中斷訊號給 CPU;
CPU 收到 DMA 的訊號,知道數據已經準備好,於是將數據從內核拷貝到使用者空間,系統呼叫返回, 內核態切換至使用者態 ;
利用DMA的IO完整流程圖:

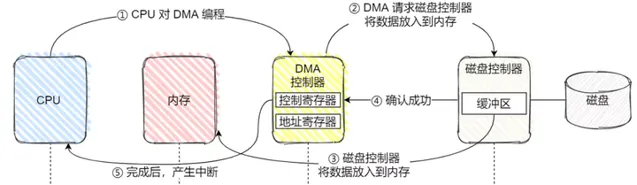
1、CPU 需對 DMA 控制器下發指令,告訴它想讀取多少數據,讀完的數據放在記憶體;
2、接下來,DMA 控制器會向磁盤控制器發出指令,通知它從磁盤讀數據到其內部的緩沖區中,
3、接著磁盤控制器將緩沖區的數據傳輸到記憶體;
4、數據拷貝成功之後,磁盤控制器在匯流排上發出一個確認成功的訊號到 DMA 控制器;
5、DMA 控制器收到訊號後,DMA 控制器透過中斷通知 CPU 指令完成,CPU 就可以直接取記憶體裏面現成的數據了;
可以看到,僅僅在傳送開始和結束時需要 CPU 幹預,其他任務交由DMA處理。
因為發生了read+write兩次系統呼叫,所以一共發生了 4 次使用者態與內核態的上下文切換
上下文切換的成本並不小,一次切換需要耗時幾十納秒到幾微秒
還發生了 4 次數據拷貝,其中兩次是 CPU參與的拷貝。
如何最佳化?
減少 「使用者態與內核態的上下文切換」和「數據拷貝」 的次數。
1、如何減少「使用者態與內核態的 上下文切換 」的次數呢?
讀取磁盤數據的時候,之所以要發生上下文切換,是因為 使用者空間沒有許可權操作磁盤或網卡 ,這些操作裝置的過程只能 交由OS內核 來完成。所以需要系統呼叫進行上下文切換,切換到內核態。
所以,減少上下文切換到次數的辦法就是:
減少系統呼叫的次數
2、如何減少 「數據拷貝」 的次數?
從內核的讀緩沖區-----使用者的緩沖區裏----- socket 的緩沖區裏 ,這個過程是沒有必要的。
因為檔傳輸的套用場景中,在 使用者空間 我們並不會對數據「再加工」,所以數據實際上 可以不用搬運到使用者空間 ,因此使用者的緩沖區是沒有必要存在的。
零拷貝
零拷貝技術實作的方式通常有 2 種:
mmap(記憶體對映) + write
sendfile
mmap + write
在前面我們知道,read() 系統呼叫的過程中會把內核緩沖區的數據拷貝到使用者的緩沖區裏,於是為了減少這一步開銷,我們可以用 mmap() 替換 read() 系統呼叫函式。
mmap系統呼叫函式會直接把內核緩沖區裏的數據共享到使用者空間,這樣,作業系統內核與使用者空間就不需要再進行任何的數據拷貝操作。
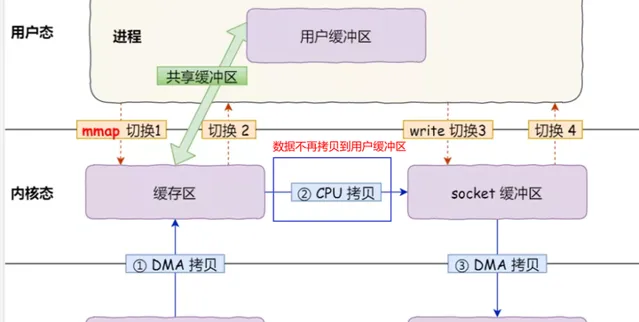
具體過程如下:
套用行程呼叫了 mmap 後,DMA 會把磁盤的數據拷貝到內核的緩沖區裏。接著, 套用行程跟作業系統 內核 「共享」 這個緩沖區;
套用行程再呼叫 write ,作業系統直接將 內核緩沖區 的數據拷貝到 socket 緩沖區中,這一切都發生在內核態,由 CPU 來搬運數據;
最後,把內核的 socket 緩沖區裏的數據,拷貝到網卡的緩沖區裏,這個過程是由 DMA 搬運的。
效能如何?
可以減少一次數據拷貝的過程。
但這還不是最理想的零拷貝,因為 把內核緩沖區的數據拷貝到 socket 緩沖區裏 的工作仍然需要透過 CPU 完成,
而且 仍然需要 4 次上下文切換,因為系統呼叫還是 2 次。
mmap詳解
是什麽?
mmap是一種實作記憶體對映檔的方法。
即:將一個檔對映到使用者行程的地址空間,實作檔磁盤地址和行程虛擬地址空間中一段虛擬地址的一一對映關系。
實作這樣的對映關系後,行程就可以采用指標的方式讀寫操作這一段記憶體,而系統會自動回寫臟頁面到對應的檔磁盤上,即完成了對檔的操作,又不必再呼叫read,write等系統呼叫函式。
相應地,內核空間對這段區域的修改也直接反映到使用者空間,從而可以實作不同使用者行程間的檔共享。
mmap記憶體對映的實作過程,總的來說可以分為三個階段:
1、行程啟動對映過程,並在 虛擬地址空間 中為對映 建立虛擬對映區域
2、呼叫 mmap 實作 檔的實體位址和行程虛擬地址 的一一對映關系
註:前兩個階段僅在於建立虛擬區間並完成地址對映,還沒有將任何檔數據拷貝至主記憶體。真正的檔讀取是當行程發起讀或寫操作時開始。
3、行程發起對這片對映空間的存取,引發 缺頁 中斷 ,實作檔到內核緩沖區的拷貝
行程的讀或寫操作存取虛擬地址空間這一段對映地址,透過查詢頁表,發現這一段地址並不在物理頁面上。因為目前只建立了地址對映,真正的硬碟數據還沒有拷貝到記憶體中,因此引發缺頁異常。
缺頁異常進行一系列判斷,確定無非法操作後,內核發起請求調頁過程。
調頁完成後。行程即可對這片內核緩沖區進行讀寫操作,如果寫操作改變了其內容,一定時間後系統會自動回寫臟頁面到對應磁盤地址,也即完成了寫入到檔的過程。
mmap的功能:
1、上面已經分析了,mmap最大的功能就是 減少了數據的拷貝次數
2、提供了 行程間共享記憶體及相互通訊 的方式。
不管是父子行程還是無親緣關系的行程,都可以將自身使用者空間對映到同一個檔。從而透過各自對對映區域的改動,達到行程間通訊和行程間共享的目的。
同時,如果行程A和行程B都對映了區域C,當A第一次讀取C時透過缺頁從磁盤復制檔頁到記憶體中;但當B再讀C的相同頁面時,雖然也會產生缺頁異常,但是不再需要從磁盤中復制檔過來,而可直接使用已經保存在記憶體中的檔數據。
3、可用於實作高效的大規模數據傳輸。
記憶體空間不足,是制約大數據操作的一個方面,解決方案往往是借助硬碟空間協助操作,補充記憶體的不足。但是進一步會造成大量的檔I/O操作,極大影響效率。這個問題可以透過mmap對映很好的解決。換句話說,但凡是需要用磁盤空間代替記憶體的時候,mmap都可以發揮其功效。
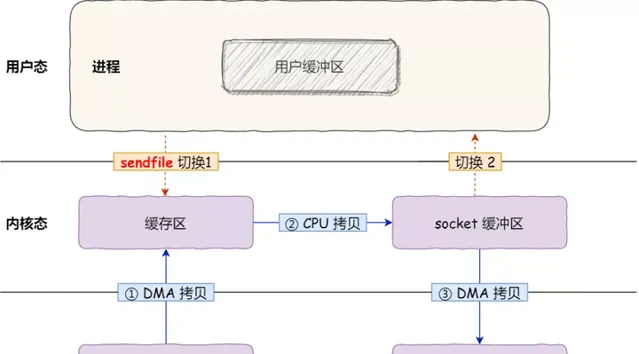
sendfile
3次數據拷貝,其中CPU拷貝一次 1次系統呼叫 2 次使用者態與內核態的上下文切換
在 Linux 內核版本 2.1 中,提供了一個 專門發送檔 的系統呼叫函式 sendfile 。
首先,它可以替代前面的 read() 和 write() 這兩個系統呼叫,這樣就 可以減少一次系統呼叫 ,也就 減少了 2 次上下文切換的開銷 。微信搜尋公眾號:架構師指南,回復:架構師 領取資料 。
其次,該系統呼叫,可以直接把內核緩沖區裏的數據拷貝到 socket 緩沖區裏,不再拷貝到使用者態,這樣就 減少了一次數據拷貝 ,
現在一共只有 2 次上下文切換,和 3 次數據拷貝。如下圖:
但是這 還不是真正的零拷貝技術 。
真正的零拷貝
1次系統呼叫
2 次使用者態與內核態的上下文切換
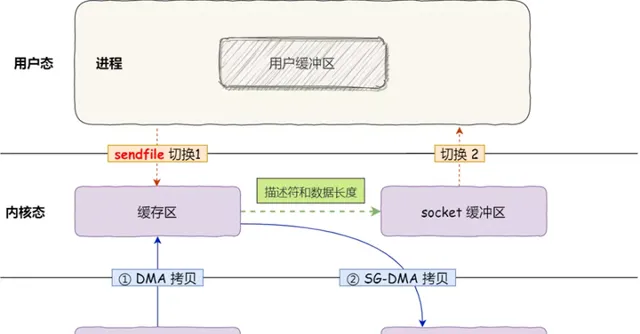
從 Linux 內核 2.4 版本開始起, sendfile() 系統呼叫 的過程發生了點變化,具體過程如下:
透過 DMA 將 磁盤 上的數據拷貝到 內核緩沖區 裏;
只將 緩沖區描述符和數據長度 傳到 socket 緩沖區,而 內核緩存中的數據 則透過 網卡的 SG-DMA 控制器 直接拷貝到 網卡的緩沖區 裏,這樣就減少了一次數據拷貝;
所以,這個過程之中,只進行了 2 次數據拷貝,如下圖:
效能如何?
全程沒有透過 CPU 來搬運數據,所有的數據都是透過 DMA 來進行傳輸的。
只需要 2 次上下文切換和2次數據拷貝,就可以完成檔的傳輸,
所以,總體來看,零拷貝技術可以把檔傳輸的效能 提高至少一倍 以上。
kafka和Nginx都使用了零拷貝技術
為什麽需要內核緩存區?
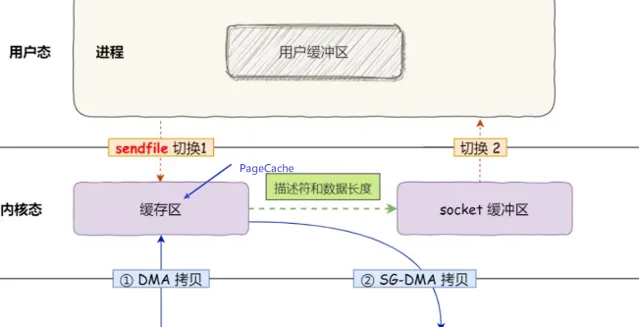
現在回過頭再來看,為什麽不直接將磁盤數據拷貝到網卡,而要在中間加一個 內核緩存區 呢?——核心原因是 磁盤讀寫太慢了
內核緩存區做了什麽?
緩存最近被存取的數據;
預讀功能;
內核的 I/O 排程演算法 會緩存盡可能多的 I/O 請求在 內核緩存區中,最後 「合並」 成一個更大的 I/O 請求再發給磁盤,這樣做是為了減少磁盤的尋址操作;
1、緩存最近被存取的數據
最近存取過的數據接下來很可能還會被存取,所以利用PageCache 緩存最近被存取的數據,讀磁盤數據的時候,優先在 PageCache 找,如果數據存在則可以直接返回;如果沒有,則從磁盤中讀取,然後緩存在 PageCache 中。當PageCache的空間不足時,淘汰最久未被存取的緩存。
2、預讀功能
利用 空間局部性 原理,假設 read 方法每次只會讀 32 KB 的字節,雖然 read 剛開始只會讀 0 ~ 32 KB 的字節,但內核會把其後面的 32~64 KB 也讀取到 PageCache,這樣後面讀取 32~64 KB 的成本就很低,如果在 32~64 KB 淘汰出 PageCache 前,行程讀取到它了,收益就非常大。
這兩個做法都在於解決 讀寫磁盤相比讀寫記憶體的速度慢太多了 這一痛點, 大大提高了讀寫磁盤的效能。
所以零拷貝使用 內核緩存區技術進一步提升效能。
但是由於 內核緩存區不適合傳輸大檔 ,所以零拷貝不適合傳輸大檔 因為每當使用者存取這些大檔的時候,內核就會把它們載入 內核緩存區中,於是 內核緩存區空間很快被這些大檔占滿。 其他「熱點」的小檔可能就無法充分使用到 內核緩存區 ,於是這樣磁盤讀寫的效能就會下降了;
所以,內核緩存區中的大檔數據,不但沒有享受到緩存帶來的好處,卻還耗費 DMA 多拷貝到 內核緩存區一次;
那針對大檔的傳輸,我們應該使用什麽方式呢?
大檔傳輸:異步IO+直接IO
回顧最初的例子,當呼叫 read 方法讀取檔時,行程實際上會阻塞在 read 方法呼叫,因為要等待磁盤數據的返回,如下圖:
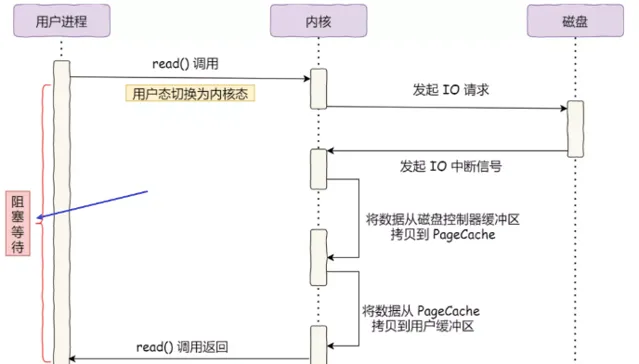
對於阻塞的問題,可以用 異步 I/O 來解決,它的工作方式如下圖:
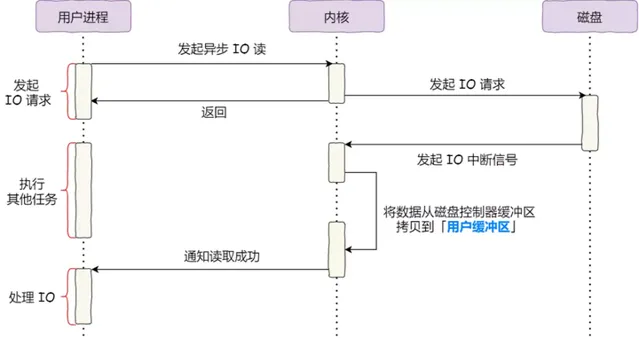
可以發現, 異步 I/O 並沒有涉及到 內核緩存區 。
繞開 內核緩存區的 I/O 叫 直接 I/O ,使用 內核緩存區的 I/O 則叫 緩存 I/O 。通常,對於磁盤, 異步 I/O 只支持直接 I/O 。
所以,針對大檔的傳輸的方式,應該使用 異步 I/O + 直接 I/O 來替代零拷貝技術。
總結
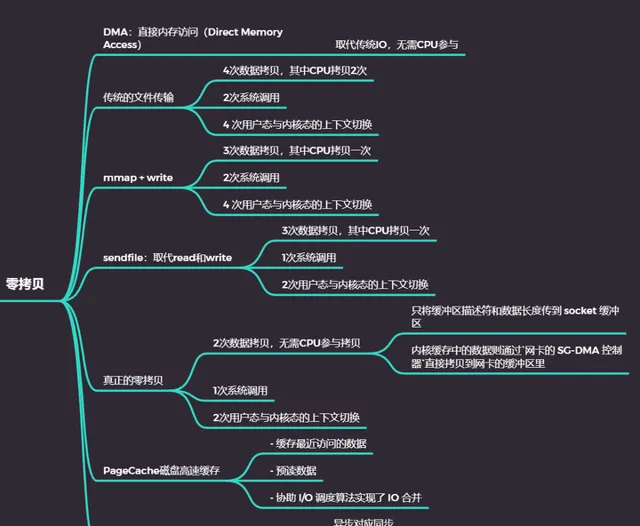
DMA和傳統IO
早期 I/O 操作,記憶體與磁盤的數據傳輸的工作都是由 CPU 完成的,而此時 CPU 不能執行其他任務,會特別浪費 CPU 資源。
於是,為了解決這一問題,DMA 技術就出現了,實際數據傳輸工作由 DMA 控制器來完成,CPU 不需要參與數據傳輸的工作。
零拷貝
傳統 IO 的工作方式,從 硬碟 讀取數據,然後再透過 網卡 向外發送,需要進行 4次上下文切換,和 4 次數據拷貝,更糟糕的是其中兩次都是CPU完成的。
為了提高 檔傳輸 的效能,於是就出現了 零拷貝技術 ,只有 一個sendfile系統呼叫 導致的 2 次使用者態與內核態的上下文切換 ,只進行了 2 次數據拷貝(磁盤——pageCache——網卡) ,全程沒有透過 CPU 來搬運數據,所有的數據都是透過 DMA 來進行傳輸的。
需要註意的是 ,零拷貝技術中,數據沒有進入使用者緩沖區,所以 使用者行程 無法對檔內容作進一步的加工的,比如 壓縮數據再發送 。
內核緩存區
零拷貝技術是基於 內核緩存區的,內核緩存區具有
緩存最近存取的數據
預讀數據
協助 I/O 排程演算法 實作了 IO 合並
提升了存取緩存數據的效能,解決了磁盤IO慢的問題,進一步提升了零拷貝的效能。
大檔傳輸
當傳輸大檔時,不能使用零拷貝,因為可能由於 內核緩存區 被大檔占據,而導致其他的 「熱點」小檔 無法利用到 內核緩存區,並且大檔的緩存命中率不高,這時就需要使用 「異步 IO + 直接 IO 」 的方式。
-End-
讀到這裏說明你喜歡本公眾號的文章,歡迎 置頂(標星)本公眾號 Linux技術迷,這樣就可以第一時間獲取推播了~
在本公眾號,後台回復:Linux,領取2T學習資料 !
推薦閱讀
1.
2.
3.
4.