👉 目錄
1 前言
2 騰訊新聞業務介紹
3 新聞推薦架構升級的背景
4 新聞推薦架構升級的目標和演進路線
5 架構升級的關鍵路徑
6 系統防劣化
7 總結
程式設計師最大的幸福是看到自己的程式碼跑在千萬人的裝置上,程式設計師最大的不幸是去維護千萬人裝置背後的老程式碼。騰訊新聞,是一個有著十多年歷史、海量使用者規模的經典業務,其背後的系統走過了門戶時代,走到了推薦演算法時代。
隨著時間的推演,老舊架構面臨著那些經典的問題:可用性差,服務不穩定;擴充套件性差,開發周期長,叠代效率低;200 多個程式碼倉庫,300 多萬行程式碼,程式語言、協定混用……
疊加上推薦演算法的時代命題,如何對騰訊新聞的推薦架構做升級成了業務進一步發展的內在要求。本文從業務場景介紹入手,詳細介紹了騰訊新聞推薦架構升級過程中的目標設定,架構設計和實踐過程,值得仔細品閱,轉發點贊收藏一鍵三連。
01
前言
我們先來簡單回顧下騰訊新聞的發展歷程,騰訊新聞源於03年成立的入口網站騰訊網,成立之初,抓住了中國互聯網崛起的東風,位列四大門戶(搜狐、新浪、網易)之一;2010年伴隨著智慧型手機的普及,也抓住了行動網際網路普及的浪潮,第一批推出了騰訊新聞的客戶端,經過了一系列互動和內容的創新,於2014年移動端的使用者數更是達到了峰值的 DAU2.5億,位列資訊類 APP 第一位,一度也達到了套用總榜的第一,這是截止到當時唯一觸達榜首的資訊類 APP ,由於這些傲人的成績,騰訊新聞在2015年強勢拿到了騰訊集團的「名品堂」,該獎項授予那些曾經影響到騰訊集團發展歷程的裏程碑式的套用,應該算是騰訊新聞最高光的時刻,時至今日騰訊深圳總部大樓上高懸的還是騰訊新聞的 logo:

萬事萬物的發展,基本都要遵循生命周期的規律,一個互聯網產品也會遵循一定的發展曲線,經歷了2015年的高光時刻,自身業務邏輯的膨脹以及外部環境的變化,騰訊新聞也迎來了生命周期上的陣痛期,業務形式和技術架構都要求擁抱變化。
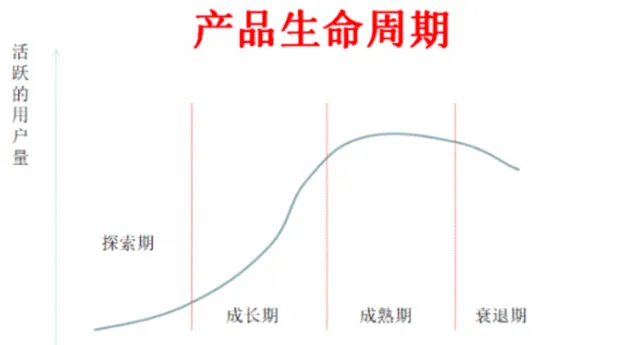
02
騰訊新聞業務介紹
2.1 發展階段
談到騰訊新聞的業務,我的理解裏面大致將他劃分為三個階段:
第一個階段:我把它稱之為以類目為索引的櫥窗式內容陳列階段,這也是所有入口網站的內容組織形式,就像一個大的「內容超市」,你會看到各類內容,按照一個大的分類體系(按照顆粒度不同少則幾十大則幾百上千)來組織內容然後呈現給使用者:
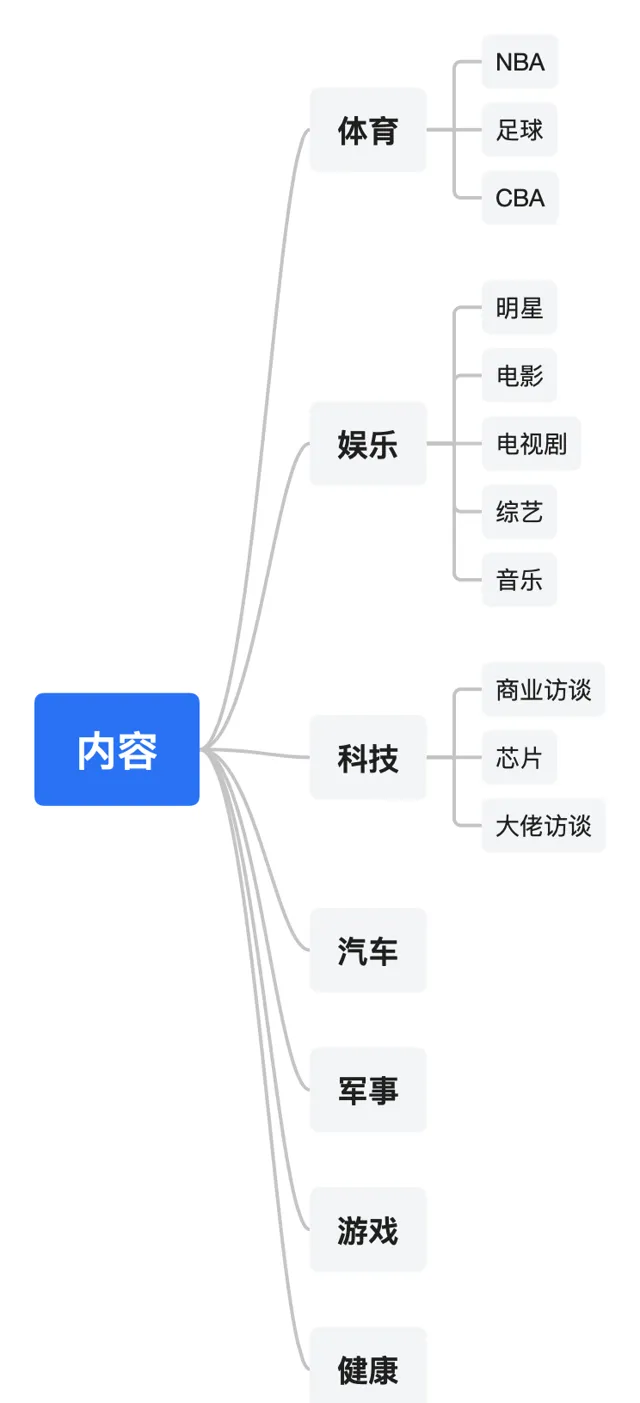
分類體系示意
這個階段的持續時間,我們對應到騰訊新聞發展的歷史行程之中,大概是在2003-2020年,但是我認為這個階段在2015年之前是比較成功的,2015年之後就有所變化,為什麽會這麽說,我個人感覺這跟互聯網內容生產的模式息息相關,在2015年之前互聯網的內容生態呈現如下的特點:
內容創作門檻較高,內容的供給主要存在於專業化的團隊、因而內容的多樣性比較差,集中度比較高,原因是內容創作機構也自然而然的按照品類進行了衍生,各大機構傾向於在自己擅長的品類裏面深耕。
內容消費的渠道比較多元,紙媒、電視、PC(各個媒體的官網),消費呈現出很強的地域性特點,但是內容消費的品類比較單一,大家的消費主要集中在熱點內容上,當然這跟內容的生產效率是有直接相關性的。
因而各家門戶之間比拼的更多的是營運的功力,如何能夠更快的覆蓋熱點,能夠提供獨家內容的消費渠道。騰訊新聞在內容營運方面是符合這個時代的特點的(「打造精品,自我變革」),同時發力移動端也比較早,因而在這個階段獲得了快速的發展。
第二個階段:我把他稱之為個人化引擎驅動的瀑布流階段;這個階段的開始源於個性推薦資訊類 App 的盛行,從時間節點上看,我覺得應該在2015年左右,但是騰訊新聞真正將個人化分發能力作為一個重點發力的時間點大概在2020年。這個階段的主要特點是:
隨著智慧型手機功能的增強和網路資費的下降,內容消費的渠道逐步收縮到了移動端,使用者的消費呈現出多元化;
內容創作的門檻下降,資訊幾何倍數增加,訊息觸達使用者的效率大幅提升,但是使用者獲取有效資訊的效率下降;
由於資訊量陡增,原有新聞擅長的精細化營運的模式,受到了極大的沖擊,所以在2016-2020這個時間段,新的內容生產模式跟新聞原有的營運方式以及組織架構產生了摩擦,應該算是一個陣痛期,陸續湧現出了一些問題:
熱點無法第一時間觸達使用者,相比於早年可預期的熱點營運,由於消費渠道和流量的集中,很多熱點的爆發呈現出了很強的隨機性,很容易透過微博等關系引擎引爆,原有的人工營運的模式無法第一時間跟進並且做出差異化。
由於營運偏向於客製化,後端系統架構過於分散,缺乏復用性,需求叠代的效率受到了嚴重的制約。
場景分立的系統導致了整體的可用性壓力比較大。
整個機器的營運成本也比較高。
從2021年開始,雖然當時業務上還存在一些搖擺,但是從架構上我們確立了以推薦引擎驅動的分發模式,因而也正式開啟了長達2年的系統架構升級之路。
2.2 業務分類
雖然整個騰訊新聞裏面場景眾多,從細分來看超過了400個場景,但是從底層本邏輯來看,我們可以將所有場景總結為兩大類:
個人化推薦的場景:
該類場景的特點是:所有系統的請求由使用者主動觸發,由於使用者的作息和使用手機的習慣存在差異,因而請求數量存在周期性規律,同時由於所有請求由使用者主動行為觸發,因而活躍使用者占比較高。同時,為了提升使用者的消費行為,我們也會傾向於使用更加復雜的模型,同時由於熱點事件的熱點事件影響大,業務場景多,策略的復雜度高,整個系統以消費深度和留存作為主要的最佳化目標。
個人化推播的場景:
該類場景的特點是:請求透過系統觸發,覆蓋的使用者量級極大,不活躍使用者占比高超過正常水平,計算密集度高 QPS 超過數十萬,需要兼顧時效性和個人化,以拉活和拉新為主要目標。
03
新聞推薦架構升級的背景
在展開架構升級的過程之前,我們先來思考兩個核心的問題:
1、當我們的產品處於一個高頻、多變的叠代之中的時候,我們如何才能保持我們系統架構的生命力?
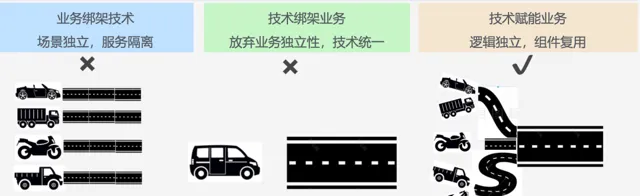
常見的架構設計問題
各個場景的產運是路上行駛的各種規格的車輛,我們的系統就是一條條的公路,優秀的架構升級不是要大家不開私家車改坐公交車(放棄業務邏輯獨立的系統統一),也不是給每輛私家車修建一條專屬道路(業務主導系統建設,成本高昂,養護不易),而是建設一條公共的高速公路(邏輯復用),合理架設橋梁,安置訊號燈(控制收口),讓各類車輛,往來穿梭,並 行不悖(高並行)。
2、判斷一個系統架構好壞的評價標準是什麽?

可用性:主要是指一個系統在滿足功能要求的前提下,在一定時間內正常執行的程度,我們可以用如下的公式來定義:
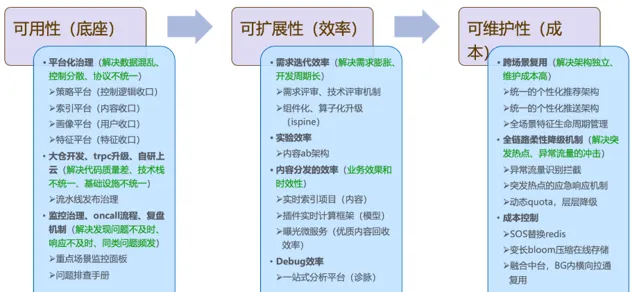
可用性是衡量一個系統健康度的最基礎的指標,可用性存在問題,其他指標也就無從談起。
可延伸性:主要是指系統處理增加的負載、使用者數量、數據量或復雜業務邏輯的能力,一個擴充套件性好的系統架構,在套用上述問題的時候,不需要進行頻繁的重構或者替換。可延伸性是系統架構能夠長期有效執行並滿足未來需求的關鍵衡量指標。良好的擴充套件性設計使得系統能夠在不犧牲效能和穩定性的前提下,適應不斷變化的業務叠代需求。
可運維性:主要是指系統在執行過程中的營運成本、以及進行維護、升級以及 bug 修復的難易程度,通常包含幾個方面的要求:整個系統的可解釋性、可測試性、文件完整度、配置化程度、自動化、容錯性以及可監控性等。
了解了前面提到的兩個核心問題,我們帶著這兩個核心問題,來觀測升級前的騰訊新聞整體的架構:
老的架構示意
我們可以看到騰訊新聞是一個叠代非常頻繁的業務產品,同時原有的架構延續了入口網站時代:水平分層,場景自治的設計理念,該設計在早期以營運為主體的階段,給了產品和營運團隊極大的靈活性,但是到了當下個人化引擎驅動的時代,就暴露了很多的問題,我們從上面提到評價系統架構的三個標準層面去看,可以看到以下的問題:
可用差,事故頻發:可用性不足99%,21年線級別的事故超過 xx 次。
可延伸性差,開發周期長,叠代效率低:一個需求聯動前後端多個模組,數十位開發, 拉大群,開大會,一開2、3小時,聯調效率低,開發周期超過一個月。
成本高昂:推薦架構成本超過了 xxw/m,線全年機器營運成本接近 x 個億。
問題排查效率低,實驗效率低,系統的可解釋性差:定位一個系統問題,橫跨多個工具, 占用各個環節研發人力,實驗叠代周期長,很多需求不經驗證直接上線。
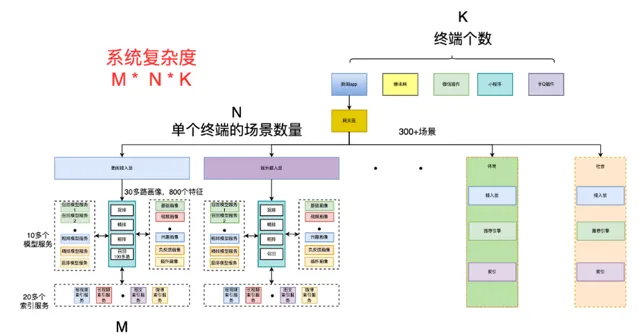
為什麽老的架構適合個人化驅動的業務訴求,個人化引擎由於引入了模型打分,為了使得系統能夠快速的逼近當下的最優解,往往叠代速度會更加的迅速,鏈路也相對會更長;同時,新聞是一個發展超過了20年的老業務,在發展過程中累積了相當的歷史債務,主要體現在如下方面:
場景多,策略多,服務多:400+場景,1000+策略,2000多個物理服務(包含儲存引擎),場景之間復用程度低,基礎設施不統一。
倉庫多,程式碼多,語言多,協定多,程式碼品質差,釋出流程不規範:200多個程式碼倉庫, 300多萬行程式碼,php,c++,golang,java,python 混用,brpc,http,grpc 協定混用, 單測覆蓋率極低,不足10%,分支開發,隨意打包映像釋出線上環境。
內容種類多,時效多,特征多,使用混亂:小視訊、短視訊、長視訊、問答、專題、事 件、微博、cp 等10多種分發介質,幾十種分發時效,內容側特征1000多個,畫像側特征 1000多個,特征生產鏈路私搭亂建,特征儲存零星分布,各類 redis 數百個。
工具龐雜,九龍治水,控制不收口:各類營運工具,幾十個營運工具幹預線上分發邏輯。
監控缺失,告警缺失:沒有一個端到端的監控頁面,主端的核心二級頻道缺少監控和告警,靠產運人工發現系統問題反饋。
04
新聞推薦架構升級的目標和演進路線
4.1 目標
有了前面的鋪墊,我們可以用一句話,來概括我們架構升級的目標:在保證業務邏輯獨立性的前提下,實作架構的復用,提升系統架構的健壯性(保證使用者體驗)、可延伸性(提升叠代效率)、可運維性(降低維護成本)。
這裏面有個非常核心的前提,「保證業務邏輯的獨立性 」 ,為什麽這個前提很重要,因為我們從歷史經驗來看,很多公司技術路線演進過程中,是犧牲掉了部份業務邏輯獨立性換來的。比如,早些年業界提出了「大中台,小前台」的中台架構理念,但是隨著時間推演,業務蓬勃發展下,業務邏輯獨立性的訴求逐步增加,中台逐步成為了限制業務獨立發展的枷鎖,這也就不難理解最近,業界又開始拆中台的風潮了。
於我個人而言,我不反對建設一個技術中台,但是這裏面有個很重要的原則,就是我們要來定義什麽樣的元件適合成為一個中台,以及業務和中台的關系如何界定。譬如說:數據資產管理、容器平台、機器學習平台這些作為中台,基本是可以達成共識的。但是長在這些公共元件之上的推薦引擎部份,能不能拿了作為中台,很多公司在這些方面有不同的看法,我個人認為要結合業務的發展階段來看。如果一個業務早期,需要快速驗證業務模型,快速試錯,當然接入一個統一的引擎中台,無疑是最快速、成本最低的做法;同樣業務如果處於生命周期的中後段,處在一個維穩狀態,沒有太多的叠代前提下,也比較適合中台這種集中式托管的方式。但是如果這個業務正處在一個快速發展的上升期、以及平台期亟需尋找第二增長曲線的階段的時候,捆綁在中台,無疑對於業務的叠代效率就會產生制約。這個階段中台的角色作為一個孵化器往往是比較合適的,給業務提供一些基礎的元件,同時類似開源社群的方式,允許業務自己維護自己的程式碼版本。
4.2 路徑
有了上面的認識之後,我們如何來推進我們的架構升級?我們先要做什麽,後要做什麽?
這裏面我想提一個可能在推薦系統架構設計裏面不太常被人提及的概念」領域驅動設計(Domain-Driven Design, DDD)」。
領域驅動設計(Domain-Driven Design,簡稱 DDD)是一種軟體開發方法論,它專註於建立一個以業務領域為核心的軟體模型。DDD 由 Eric Evans 在2004年提出,其核心思想是透過領域模型來定義業務和套用邊界,確保業務模型與程式碼模型的一致性。DDD 的目標是幫助開發人員更好地理解和建模業務領域,將業務領域的知識和邏輯融入到軟體設計中,從而提高軟體的品質和可維護性。
為什麽這裏要提這個概念,因為我們在實際工作中發現,很多系統設計是缺乏底層理論支撐的,只是為了解決單點的問題。這樣隨著業務叠代,日積月累,必然導致積重難返。我們架構設計首先需要理解底層的業務邏輯,這跟 DDD 的理念不謀而合,因為 DDD 的第一步就是領域建模。
領域模型是 DDD 的核心,它描述了業務領域中的概念、實體、關系和業務流程。透過領域模型,我們可以將業務領域的知識轉化為電腦可理解的語言,實作業務邏輯與技術實作的統一。
所以我們系統重構的首要問題,是面向數據要素建模。
數據基礎決定上層架構,歷史債務治理,首要進行數據治理,數據收斂帶動架構統一 推薦系統裏面最核心的數據要素是什麽: 使用者、內容、特征、策略。
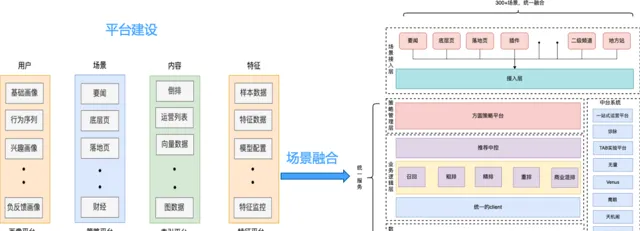
數據收斂帶動架構融合
我們希望圍繞推薦系統內部的四個核心要素,進行統一的平台化治理,將數據要素的讀寫進行統一的收口,然後在此基礎上,按照推薦的漏鬥進行一個微服務改造,提升系統整體復用性和擴充套件性,具體的執行路徑如下圖式:
演進路線
05
架構升級的關鍵路徑
平台建設
為了實作整個底層數據模型的統一,我們花了接近2年的時間,進行了底層數據平台的建設,並推播了多個場景對底層數據依賴的統一,下面我們找兩個有代表 性的平台進行一個簡單的展開,在建設這些平台過程中遇到的問題以及核心的思考。
5.1 索引平台
問題與挑戰
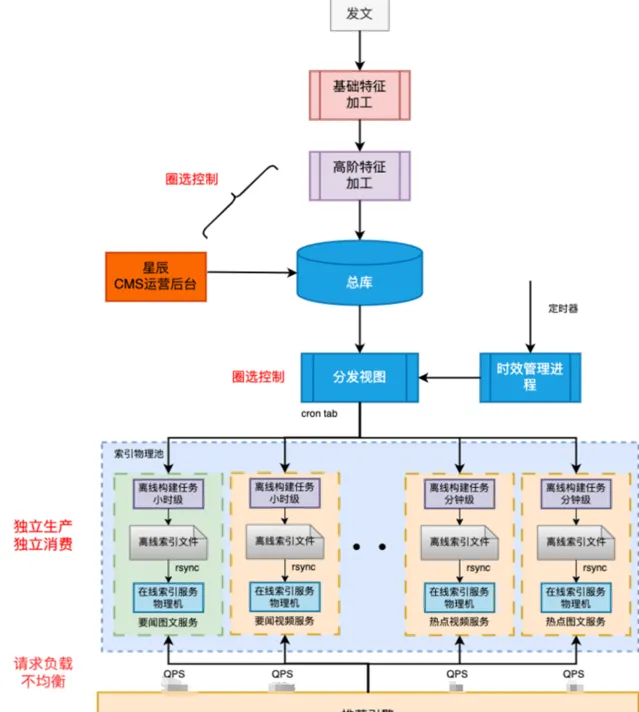
XX平台架構
老的新聞索引服務,沒有所謂平台的抽象。基本都都是按照分發場景對於內容池的要求(內容的品質、時效、安全等級、內容的分類),進行的離線加工,並且推播到線上的物理機進行線上存取的,主要存在以下的問題:
時效性不足:倒排打分更新和文章入池受限於定時任務的間隔,延遲短則十幾分鐘,長則數個小時。
擴充套件性不足:受限於單個物理機的記憶體,無法橫向擴容。
成本高:由於各個物理池,讀寫負載差異很大,導致分割的小集群利用率偏低。
可用性差:采用 crontab 的任務排程,rsync 離線檔傳輸來更新,釋出效率低,數百個物理池,運維難度大,監控無法面面俱到,可用性不足99%。
問題排查效率低:10多種介質,300多個場景,幾十種時效(短則數小時長則2年種類繁多),沒有易用的排查手段,基本靠人工,刀耕火種,很多問題得不到解答。
新的架構設計
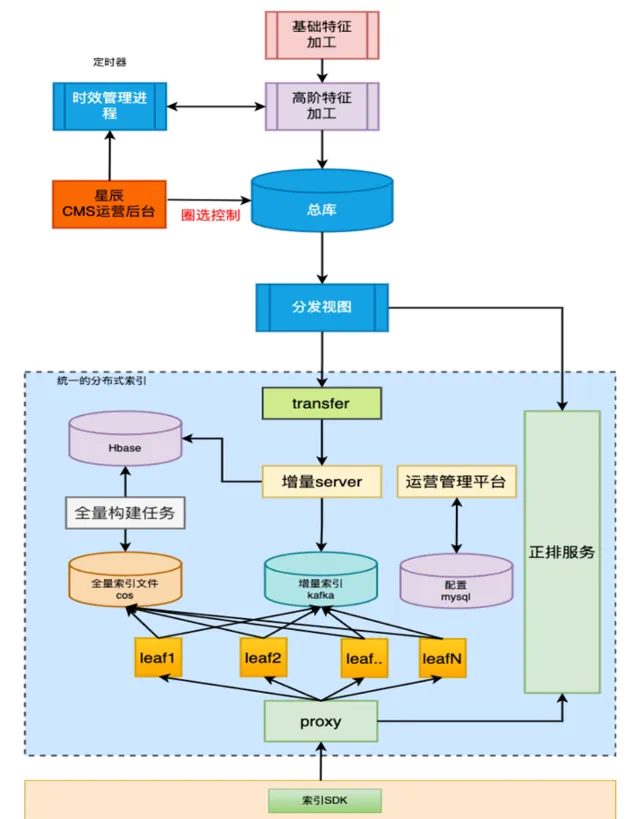
新的索引架構
新架構的設計要點:
時效性提升: 批次處理升級為流式更新。
擴充套件性提升:采用主從分片的方式,提升橫向的擴充套件性。
成本控制和可用性:統一的集群服務,資源共享,統一監控。
新架構的技術挑戰:
數據一致性問題:流式更新過程中丟訊息帶來的數據偏移問題。
效能問題:高強度讀寫並行的情況下,如何保證延遲的穩定。
叠代效率問題:統一分布式索引的架構下,如何同時滿足不同業務場景的實驗訴求。
應對措施
一致性問題:
參考大數據處理的常用的一致性架構 Lambda 架構,流批一體進行定期的校準。
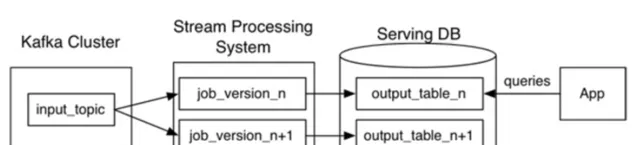
Lambda 架構

Kappa 架構
效能問題:
采用了全記憶體的方式,支持多執行緒進行讀寫請求,同時結合業務特點進行了客製化的調優,比如:分片的方式、底層的數據結構。
1、數據結構的選型:
首先是底層數據結構的選型問題,我們如何確定底層的數據結構,需要結合新聞的推薦的場景特點:
更新頻繁,動態特征秒級更新。
索引有序,拉鏈獨立打分。
範圍查詢頻繁。
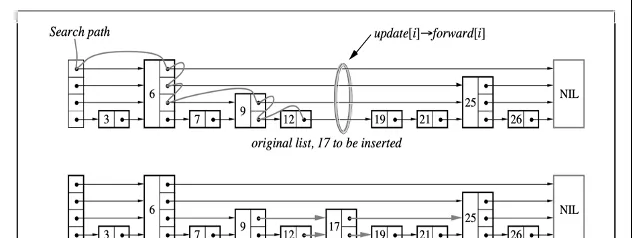
選型的對比:

選型的原則:增、刪、改、查效率穩定,簡單可依賴。
2、拉鏈構建方式的最佳化:
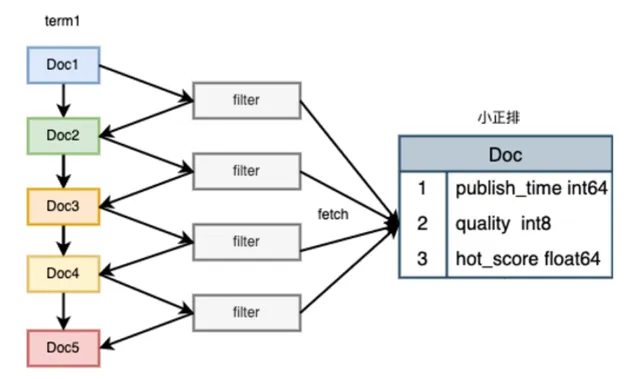
單鏈
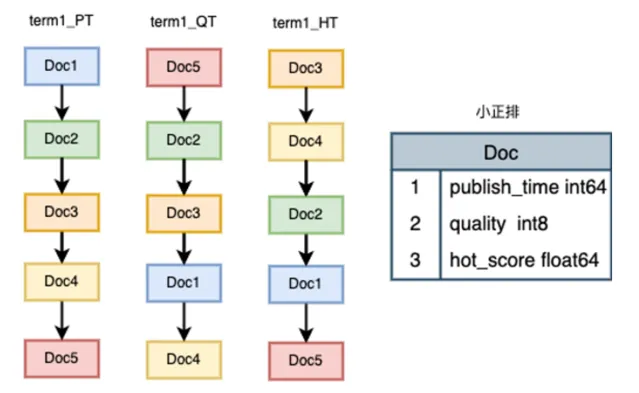
多鏈
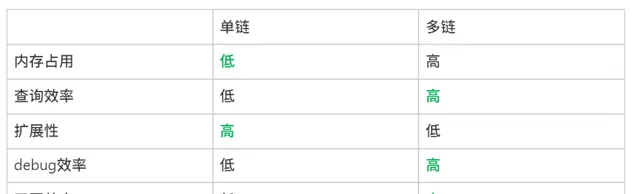
對比

拉鏈長度跟效能的關系
最終我們選擇多鏈作為我們底層的倒排構建方式:跨場景內容量級差異大,要聞 xxw,二級頻道 xxx 萬,線上穩定性優先,盡可能減少 pv 查詢級別的復雜度,每天 xx 億 pv,透過配置管理減少拉鏈無序擴張。
3、分片方式的最佳化:
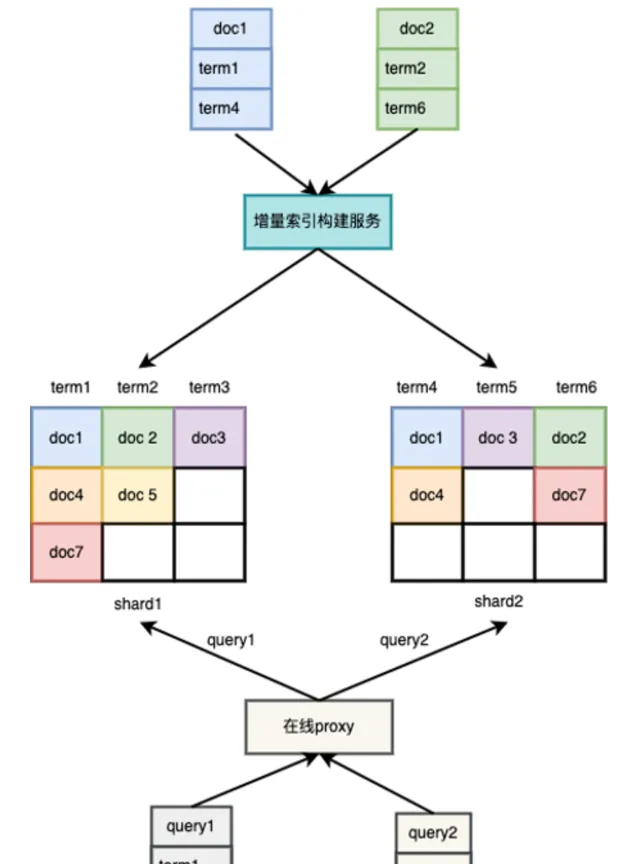
term Hash 方式
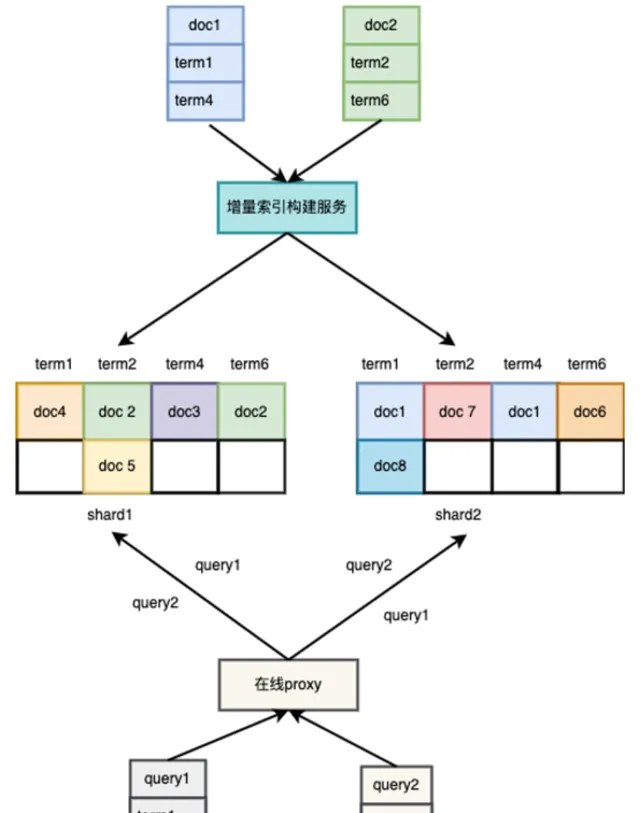
doc 哈希
考慮索引服務本身對於效能和穩定性的極致要求,我們最終還是選擇了doc哈希的方式。
4、分片數量的問題:
另外一個核心的問題:分片數量是不是越多越好?答案顯然是否定?分片的多少對於一個系統效能的影響也是非常大的。
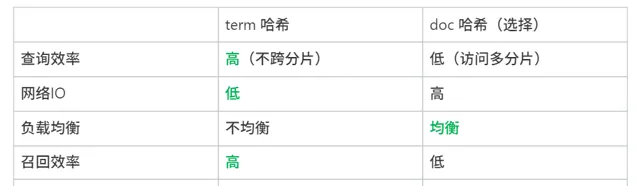
分片多:並列度高,單次請求效率高,追增量快;代理扇出大。
分片少:代理扇出小,召回效率高;並列度低,容量小,追增量慢。
分片數量
5、整個線上架構分層:
當新聞推動精品資訊戰略,內容池由千萬縮減到百萬,單分片可以承載整個索引數據的時候,三層架構是否還具有良好的效能?
6、效能最佳化的收益:
線上 cpu 核數由 xxx 核下降至 xxx 核,節省了62%
線上記憶體由 xxT 下降至了 xxT,節省了30%
集群的平均耗時由 xms 下降至 xms,節省了61%
億次 pv 的呼叫成本 xx 元,下降至 xx 元,節省了63%
場景賦能:
認知:任何技術的出現都是為了解決業務的問題,技術的最佳化必須貼合業務場景,面優於線優於點,路線正確優於細節正確。
1、個人化推薦場景:
傳統的召回索引架構
場景業務特點:
召回型別多樣(倒排、模型、協同、生態等),服務眾多。
業務召回占比高,業務邏輯多變,實驗頻次高。
存取的波動性強,受熱點事件影響大。
場景統一控制規則多,例如:場景統一時效,品質等級等。
傳統架構的問題:
效能差。
召回效率低。
控制不收口,叠代效率低。
新的召回索引體系
最佳化成果:
中控模組的網路扇出,下降了20%
召回模組的整體的cpu利用率下降了10%
倒排類召回的召回效率提升了30%
修改場景過濾規則上線效率由天級減少到分鐘級。
2、個人化推播的場景
老的推播場景架構
半線上推拉結合的架構,拉活占騰訊新聞 DAU 的 xx%
周期性計算,計算密集度高,資源敏感,吞吐相對可控。
可分發集合小,保持在 xxw 量級之間。
時效性跟使用者微信活躍時間相關,直接影響拉活效果。
老的架構問題:
時效性差,小時級更新。
可維護差,多個加工任務。
成本高,多個 redis。
新的架構
最佳化成果:
新文章入庫時效從小時級到分鐘級,提升了90%
24小時內曝光文章占比提升了 xx%,每天拉活使用者 uv 增加 xxw+
索引整體成本,下降了40%
叠代效率問題:
在談叠代效率問題,之前我們回頭思考下,老架構發生的緣由是什麽?答案顯而易見,獨立物理池的方式,給了營運對內容池幹預的最大的靈活性,而且相互之間不影響。
獨立池
營運對內容的掌控力強、實驗靈活。
鏈路復用性差、成本高、服務運維難度大。
內容時效差,入庫延遲小時級、天級。
完全去池化
服務運維難度大幅下降,成本下降顯著,節省90%
營運無法感知內容變化,規則上線耦合開發人力。
pv 級別的查詢過濾運算,線上成本高,影響服務穩定性。
邏輯池+統一索引架構
最佳化成果:
供給和分發解耦,營運所見即所得。
內容實驗效率,周級別提升至天級,最佳化了80%
索引需求開發效率提升,策略修改分鐘級生效。
線上索引過濾效能提升,節省 cpu12%
5.2 特征平台
特征品質直接決定了推薦效果的上限,特征服務是推薦系統最核心的基礎服務。
老的特征鏈路
問題與挑戰
叠代效率低,抽取邏輯沒有統一規範,上線新的特征,需要修改多個模組,需要3天以上的開發周期。
特征不一致,依賴的後設資料在時間上有差異,各個模組自己維護的抽取邏輯,存在不一致。
特征缺乏管理,由於抽取邏輯的分散,特征上線較為隨意,同時使用上溯源困難,特征只增不減,線上特征超過2000+。
可用性差,上線新的特征需要頻繁重新開機,線上服務,程式碼異常容易引發穩定性問題;離線樣本鏈路缺乏管理,特征生產時常斷流。
成本高,采用了抽取後落盤的方式,跨模型,跨模組實驗無法復用,線上精排階段需要抽取大量的實驗特征,cpu 核數超過 xxw 核,成本超過 xxxw。
新的架構設計
新的架構全景
核心能力:
特征生命周期管理
模型配置管理
特征進退場管理
特征監控
特征溯源
特征實驗
高效特征服務
算子化
通用抽取庫
模型打分元件(TF 和無量)
特征上報
明文樣本流
樣本生成
通用離線抽取框架 FM
解決的核心問題:
叠代效率問題。
原有的特征鏈路
存在的問題:
原始數據(畫像、正排、使用者行為)生產和使用不收口。
沒有統一的線上特征服務框架,各模組各自為戰。
缺乏通用的算子化和配置化抽象,開發耗時高。
沒有明確的研發流程指引。
簡化後的鏈路
設計要點(工程保證效率,演算法關註效果):
借力打力,模組化治理。
內容側特征生產和使用收口至正排服務。
使用者側特征收口至畫像平台。
使用者行為收口至大同。
提供多場景的特征服務框架,滿足不同場景的特征服務訴求。
整合了ispine框架支持業務和抽取流程算子化、配置化。
依托平台,制定統一的研發流程規範,簡化演算法上線流程,涉及線上服務的部份由工程統一治理,保證品質和效率。
這裏面有個非常關鍵的模組,線上特征服務,它的效率直接影響到了整個特征叠代的效率,我們充分對比了業務主流的解決方案:
場景賦能:
認知:特征服務套用場景廣泛,為了保證多場景架構的通用性,需要結合場景進行架構抽象、規範化治理。
我們結合前面抽象出來的兩類新聞的核心場景,抽象出來了兩套通用的架構解決方案:
個人化推薦場景的通用架構
雙塔&&個人化推播場景的通用架構
最佳化成果:
主端、手 Q 外掛程式、微信外掛程式模型特征開發效率由之前周級別縮短至0.5天以內,提升了90%了;配置化管理,一次配置離線上同時生效;數據和抽取邏輯解耦,避免演算法工程同時操作線上程式碼,提升了線上服務穩定性至99.99%。
特征一致性問題
歸因分析:為了提升叠代效率,采用了明文樣本的特征保存方式,來達成數據和抽取邏輯解耦,同時引入了不一致的問題,體現在:
抽取邏輯的不一致,離線上抽取邏輯以及線上各個模組抽取邏輯分散維護,產生的不一致問題。
後設資料有差異,預估時刻和樣本生成階段原始數據不一致。
分散的特征抽取架構
抽取邏輯的一致性解決方案:
中心化治理的抽取架構
後設資料的一致性保證
後設資料一致的架構
使用者特征一致性:線上特征服務采用了 TraceID 級別的緩存,緩存使用者側畫像和 context 內的動態行為資訊。
內容特征一致性:中心化的 Item 級別的緩存,透過 Item+timestamp 來進行內容級別的緩存。
路由一致性:線上透過一致性 hash 回呼的方式,來進行 featureDump。
最佳化成果:
達成了特征的完全一致性,整個樣本拼接率 xx%提升至了94%,多個核心場景的業務指標提升顯著。
效能最佳化
影響效能的關鍵環節:
核心抽取庫的效能,直接影響了離線上抽取的效能。
特征抽取流程最佳化,大量模型實驗,模型之間特征重合度,高達90%以上,避免重復抽取是影響效能的關鍵。
網路最佳化,如何減少明文現場帶來的網路開銷,是效能最佳化的關鍵。
歸因分析:
特征眾多,以精排模型為例特征數量 xx 個,一次排序600-1000篇文章,37.5w-50w 次的計算。
數據結構不合理,智慧指標大量的參照計數,記憶體物件包含動態型別,記憶體構造析構頻繁,一次精排呼叫至少進行了 37.5w 次。
存在大量的重復計算,在特征服務內部計算會分 batch,每個 batch 裏面 User 側的特征存在重復計算的問題。
存在冗余計算的問題,抽取配置是模型特征的超集。
解決思路:
線上關鍵路徑最佳化
樣本流動通路最佳化
解決方案:
特征眾多的問題:建立完善的特征評估和進退場機制,及時下線無用特征,提升線上抽取效率。
冗余和重復計算問題:打通新聞特征平台和無量之間的模型配置,避免無效的特征抽取;最佳化計算流程,一次請求分 batch,user 側特征只抽取一次。
減少動態記憶體申請和釋放:采用記憶體池實作物件的復用;特征使用 POD 型別,可以字節復制(memset,memcopy) ,記憶體對齊,計算友好;使用原始指標替換智慧指標。
采用中心化緩存的方式,儲存重的特征現場,同時透過請求回呼的方式避免冗余數據寫入,來實作網路資源的最佳化。
按照場景設定 namespace,namespace 內部共享樣本抽取流程,一次抽取多模型使用。
最佳化成果:
特征抽取庫的效能提升了一倍,抽取階段耗時下降了50%。
CPU利用率相對下降39%,最佳化了 xx 核。
精排打分出口 avg 下降 xxms,節省了23%,推薦引擎的出口耗時 avg 下降了 xxms,p99.9耗時下降了 xxms。
5.3 推薦系統的可解釋建設-Debug 平台
這裏為什麽把 debug 平台作為一個獨立的模組單獨出來講,在我看來很多公司忽視了推薦可解釋性平台建設的重要性,大家過分的依賴於數據本身的表現而忽略了背後的邏輯,從而導致了一個現象:就是往往我們做的每一個實驗都是正向的但是累積一段時間下來,整體大盤指標反而沒有任何進展。這跟當下的推薦最佳化過分依賴 ab 實驗平台,忽略了可解性建設有直接的關系,很多方向的探索大家都處在「知其然,不知其所以然 」 的狀態。
推薦系統的可解釋性困局
可解釋性的兩層含義:
對於終端使用者的可解釋性(簡單,易懂,高度抽象)
對於系統參與者的可解釋性 (詳細,全面,直擊要害)
由於推薦系統的參與者眾多,內容、使用者量級巨大,架構復雜,因而構建一個可解釋的系統面臨了極大的挑戰。
可解釋性困局
新聞是一個營運和個人化並重的資訊流產品,內容供給和推薦涉及的環節眾多,橫跨多個團隊 新聞延續了之前騰訊網的架構,上百個場景獨立部署,幾百個程式碼倉庫,程式碼不能主幹開發,數據采集和上報各自為戰,數據缺失嚴重。
原有的 Debug 工具各個模組自建,面向模組自身,而非面向業務場景,導致工具龐雜,上下遊無法串聯。
數據的即時性不夠,關鍵消費數據的更新只能做到 T+1,且維度單一。
針對推薦側有狀態的模組例如(分布式索引、畫像、曝光),缺乏有效的 Debug 手段和工具。關鍵數據的呈現采用原始 KV 的方式,可讀性差,易用性低。
針對開發人員缺少必要的模擬請求、結果分析的工具。
增長(Push、外掛程式)、主端推薦,存在重復建設的問題。
由於推薦系統的復雜性,成為了產品、營運和技術之間的鴻溝,問題發現往往在產品和營運側,問題的定位往往在技術側,問題排查占用了非常多的研發人力。
新聞 Debug 平台的設計目標
設計一套全新的數據采集協定和數據采集架構,提升數據的準確性和時效性。
面向業務場景設計 Debug 鏈路,而非面向模組,打通上下遊。
深入理解平台使用者訴求,結合業務場景最佳化體驗,提升易用性。
合理設計離線上架構,降低對於業務系統的影響,最佳化儲存效率節省成本。
工具收斂,一站式定位問題。
透過平台的建設,發現新聞推薦系統的問題,推動新聞推薦架構升級。
在解決好新聞自己問題的同時,抽象出通用的推薦引擎白盒化能力反哺BG內的其他類似場景,推動整個平台演進至 BG 乃至行業內領先的水平。
平台全景
架構全景
平台能力
核心鏈路設計
數據流轉架構
30天內任意內容,秒級可查,可追溯,線上消費核心指標分鐘級更新。
3小時後,線上任一使用者 Trace,分鐘級回撈,即時可查。
負反饋資訊即時采集,自動抽樣,一站式分析。
5.4 端到端的穩定性建設
新聞的業務特點:時效性強、熱點突發多,導致 QPS 波動大,對系統穩定性沖擊大。
穩定性治理的措施:
異常請求辨識,閘道器限流。
完善的降級流程和操作手冊。
方便的人工介入能力,一鍵生效。
各階段柔性降級,層層兜底。
針對可預見熱點的快速擴容機制。
完善的監控和告警機制建設,第一時間發現問題,解決問題。
聯動123平台,解決基礎設施穩定性問題,例如:容器負載不均,網路擁堵、單節點異常等。
自動容災的架構設計
06
系統防劣化
原則:制定並且遵循標準、規範和最佳實踐,構建防腐層避免新的技術債務的累積。
程式碼規範:
大倉的開發模式,統一程式碼標準:單側覆蓋率大於70%,圈復雜度小於5,程式碼重復率小於8%。
統一協定規範,采用 BG 的 trpc-cpp 協定,替換原有的 brpc、http 等。
釋出流程規範:
所有線上服務釋出均接入藍盾流水線,執行嚴格的單測、diff 流程。
二進制灰度能力建設,建立了金絲雀釋出機制,保證端到端的穩定性。
策略灰度能力,基於方圓策略平台建設了策略灰度能力,避免錯誤配置引起全線崩潰。
問題排查流程規範:
打通伽利略監控到 oncall 平台的通路,自動提單,故障 MTTR<60分鐘。
針對重點場景建設了監控大盤並制定了相應的問題排查手冊。
透過企微建立了 slo 長效的跟蹤機制,及時發現及時響應。
需求開發流程規範:
所有的需求開發均接入 Tapd 需求管理平台,透過 Tedi 平台進行叠代效率的監控,及時發現問題,保證叠代效率。
建立規範的需求價值衡量機制,避免無效需求對於系統架構的侵蝕。
引入技術評審機制,避免垃圾設計對於存量系統的影響。
07
總結
新聞的架構最佳化,從21年開始一直持續到現在,系統從不足99%的可用性提升至了99.99%,整體成本下降了60%,取得了一些成果。同時,系統的最佳化之路又永遠都沒有終點,因為業務總是在向前的,新的問題不斷湧現,我的認知也隨著解決問題不斷提升,「路漫漫其修遠兮,吾將上下而求索 」 ,以此共勉。
-End-
原創作者|董道祥











