背景
Twitter每日需即時處理高達4000億的事件,並生成PB級的數據。這些數據主要來源於分布式資料庫、Kafka以及Twitter事件匯流排等多種事件源。
接下來,我們將深入探討Twitter在事件處理方面的演變,具體包括以下方面:
回顧Twitter過去的事件處理方式及其存在的問題
分析促使Twitter進行架構遷移的業務需求和客戶影響
詳細介紹新架構的設計與實施
對比新舊架構的效能差異
在處理事件方面,Twitter依賴一系列內部工具,例如:
Scalding用於批次處理
Heron是串流媒體引擎
TimeSeriesAggregator(TSAR)用於批次處理和即時處理
為了更好地理解這些工具的作用,我們先簡要介紹它們:
1.Scalding
Scalding是一個Scala庫,能夠輕松定義Hadoop MapReduce作業。Scalding透過Cascading(一個Java庫),抽象出對底層Hadoop細節的處理,並提供了與Scala的緊密整合,使得MapReduce作業的開發更為高效。
2.Heron
Apache Heron是Twitter開發的流處理引擎,旨在處理大規模數據(PB級)、提升開發效率並簡化偵錯過程。
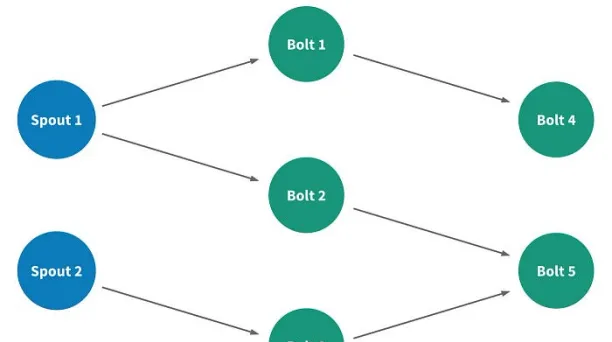
在Heron中,流處理套用被稱為拓撲,它是由表示數據計算元素的節點、表示元素之間流動數據流的邊為基礎構建的有向無環圖。
有兩種型別的節點:
Spouts: 它們連線到資料來源並將數據註入流中
Bolts: 它們處理傳入的數據並行出數據
3.TimeSeriesAggregator
Twitter 的數據工程團隊面臨著每天批次即時處理數十億個事件的挑戰。TSAR是一個強大的、可延伸的即時事件時間序列聚合框架,主要負責監控參與度,如聚合推文的互動數據,並按多種維度(如裝置、參與型別等)進行細分。
讓我們從宏觀角度來認識Twitter的運作方式。Twitter的所有功能均由微服務(其中包括遍布全球的10萬多個例項)支持。微服務負責生成事件,這些事件會被發送到Meta基於開源計畫構建的事件聚合層,經過事件聚合層的處理,被分組、聚合,並儲存在HDFS中。隨後,這些事件數據經過進一步處理、格式轉換和重新壓縮,形成良好的數據集。
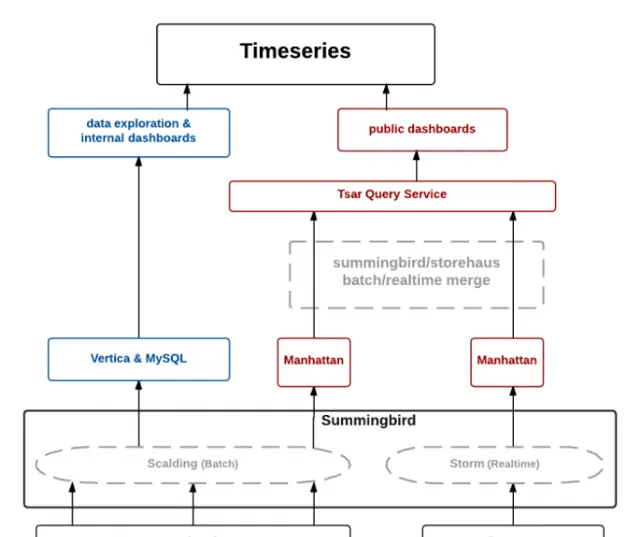
舊架構
Twitter的舊架構基於lambda架構,包括批次處理層、速度層和服務層。 批次處理層主要處理客戶端生成的日誌,經過事件處理後儲存在Hadoop分布式檔案系統(HDFS)上。Twitter還構建了一系列擴充套件管道,用於預處理原始日誌,並將其匯入Summingbird平台作為離線資料來源。速度層則負責處理Kafka主題(topic)中的即時元件源。
數據處理完畢後,批次處理數據儲存在Manhattan分布式系統中,而即時數據則被緩存於Twitter自有的分布式緩存Nighthawk中。TSAR系統(例如查詢緩存和資料庫的TSAR查詢服務)是服務層的構成部份之一。
Twitter在三個不同的數據中心部署了即時管道和查詢服務。為了降低批次處理計算成本,Twitter選擇在一個數據中心執行批次處理管道,並將數據復制到其他兩個數據中心。
那麽,為何 即時數據會選 擇儲存在緩存中而非資料庫中 呢?
舊架構的挑戰
舊架構面臨的挑戰不容忽視。讓我們透過一個具體案例來理解:
設想FIFA世界杯這樣的大型賽事期間,推文源開始向推文拓撲發送大量事件。若解析推文的Bolts無法及時處理這些事件, 拓撲內部將出現背壓 。系統長時間處於背壓情況時,Heron Bolts會積累Spout lag,此系統延遲較高。Twitter觀察到,當這種情況發生時,拓撲滯後往往需要很長時間才能下降。
過去,團隊透過重新開機Heron容器以恢復流處理來解決這一問題。但這種做法可能導致事件遺失,進而導致緩存中聚合計數不準確。
Twitter有多個繁重的計算管道,以處理PB級的數據。管道每小時執行一次,將數據同步至Manhattan資料庫。若同步作業超時而下一個作業已開始,可能導致系統背壓增加,甚至數據遺失。
TSAR查詢服務整合了Manhattan資料庫與緩存服務,向客戶端提供數據支持。由於即時數據可能會遺失,TSAR查詢服務提供給客戶的指標也可能失真。
是什麽促使Twitter解決這些問題呢?以下是可能的因素:
Twitter的 廣告服務 是其主要的收入模式之一,效能下降將直接影響其商業模式。
Twitter提供各種 數據產品服務 來檢索有關印象和參與度指標的資訊,數據不準確將影響這些服務。
另外,批次處理作業導致從事件建立到可用存在 數小時的時延 ,這意味著客戶執行的數據分析或其他操作將不會擁有最新數據,可能會滯後幾個小時。
所以,如果想要根據使用者生成的事件更新使用者的時間線,或者根據使用者與Twitter系統的互動方式對使用者行為進行分析,客戶都需要等待批次處理完成。
新架構
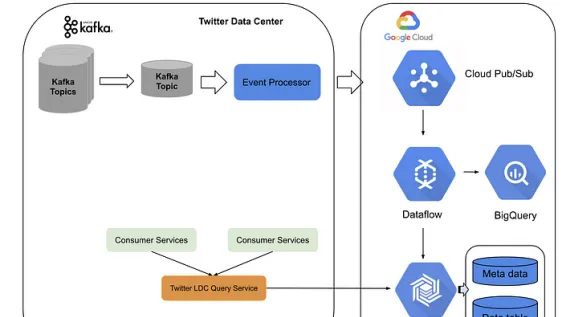
新架構建立於Twitter數據中心服務和Google Cloud平台之上。Twitter建立了一個事件處理管道,將Kafka主題轉換為pub子主題,並將其發送至Google Cloud。在Google Cloud上,流數據流作業執行即時聚合,並將數據存入BigTable。
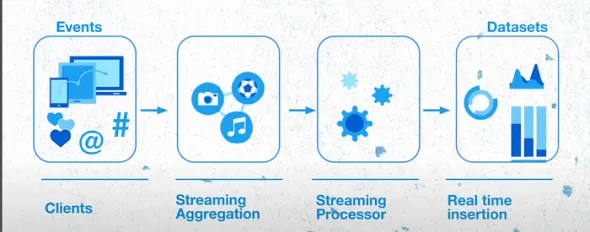
服務層方面,Twitter采用了一個LDC查詢服務(前端位於Twitter數據中心,後端位於BigTable及Bigquery)。整個系統能夠以低延遲(約10毫秒)的狀態流式處理每秒數百萬事件,並在高流量期間輕松擴充套件。
新架構不僅降低了批次處理管道的建設成本,還實作了即時聚合的高精度和穩定的低延遲。此外,Twitter無需在多個數據中心維護不同的即時事件聚合。
效能比較
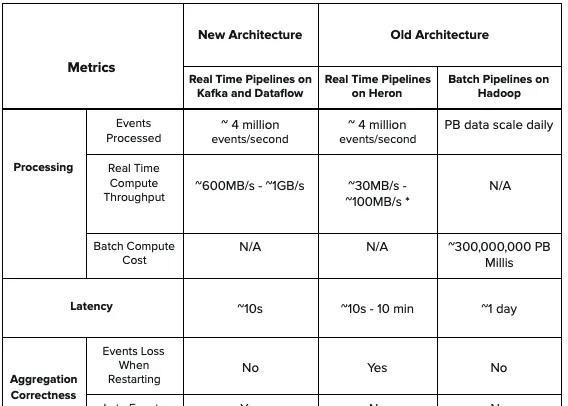
與舊架構中的Heron拓撲相比,新架構提供了更低的延遲和更高的吞吐量,同時還能處理後期事件計數,以保證在即時聚合時不再遺失事件。此外,相較舊架構,新架構中沒有批次處理元件,簡化了設計並降低了計算成本。
總結
透過將基於 TSAR 構建的舊架構遷移到 Twitter 數據中心和谷歌雲平台上的混合架構,Twitter能夠即時處理數十億個事件,並實作低延遲、高準確性、高穩定性、架構簡單化,同時降低工程師的營運成本。
> > > >
參考資料
Log Events @ Twitter: Challenges of Handling Billions of Events per Minute | Lohit Vijayarenu
https://youtu.be/EXMt_t_uWGE
Processing billions of events in real time at Twitter
https://blog.x.com/engineering/en_us/topics/infrastructure/2021/processing-billions-of-events-in-real-time-at-twitter-#below
作者丨Mayank Sharma 編譯丨onehunnit
來源丨medium.com/@mayank.sharma2796/how-twitter-improved-the-processing-of-400-billion-events-621b3456c9dc
*本文為dbaplus社群編譯整理,如需轉載請取得授權並標明出處! 歡迎廣大技術人員投稿,投稿信箱:[email protected]
活動推薦
2024 XCOPS智慧運維管理人年會·廣州站將於5月24日舉辦 ,深究大模型、AI Agent等新興技術如何落地於運維領域,賦能企業智慧運維水平提升,構建全面運維自治能力! 碼上報名,享早鳥優惠。












