點選上方 "
Python人工智慧技術
"
關註,
星標或者置頂
22點24分準時推播,第一時間送達
後台回復「
大禮包
」,送你特別福利
編輯:樂樂 | 來自:網路
上一篇:
大家好,我是Python人工智慧技術
Pandas 展示
請看下表:

它描述了一個線上商店的不同產品線,共有四種不同的產品。與前面的例子不同,它可以用NumPy陣列或Pandas DataFrame表示。但讓我們看一下它的一些常見操作。
1. 排序
使用Pandas按列排序更具可讀性,如下所示:
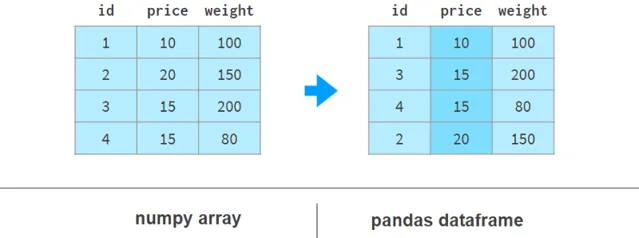
這裏argsort(a[:,1])計算使a的第二列按升序排序的排列,然後a[…]相應地對a的行重新排序。Pandas可以一步完成。
2.按多列排序
如果我們需要使用weight列來對價格列進行排序,情況會變得更糟。這裏有幾個例子來說明我們的觀點:
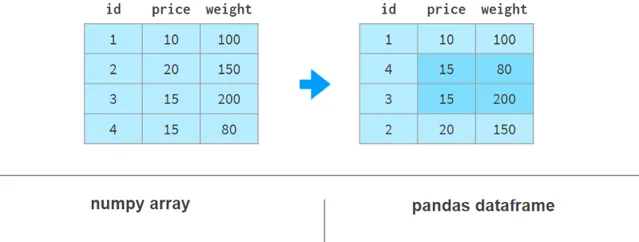
在NumPy中,我們先按重量排序,然後再按價格排序。穩定排序演算法保證第一次排序的結果不會在第二次排序期間遺失。NumPy還有其他實作方法,但沒有一種方法像Pandas那樣簡單優雅。
3. 添加一列
使用Pandas添加列在語法和架構上要好得多。下面的例子展示了如何操作:
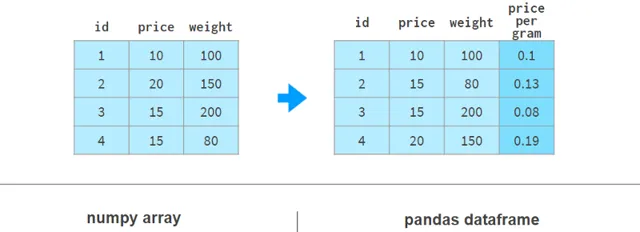
Pandas不需要像NumPy那樣為整個陣列重新分配記憶體;它只是添加了對新列的參照,並更新了列名的` registry `。
4. 快速元素搜尋
在NumPy陣列中,即使你尋找的是第一個元素,你仍然需要與陣列大小成正比的時間來尋找它。使用Pandas,你可以索引你期望被查詢最多的列,並將搜尋時間減少到一個常量。

index列有以下限制。
它需要記憶體和時間來構建。
它是唯讀的(需要在每次追加或刪除操作後重新構建)。
這些值不需要是唯一的,但是只有當元素是唯一的時候加速才會發生。
它需要預熱:第一次查詢比NumPy稍慢,但後續查詢明顯快得多。
5. 按列連線(join)
如果你想從另一張表中獲取基於同一列的資訊,NumPy幾乎沒有任何幫助。Pandas更好,特別是對於1:n的關系。
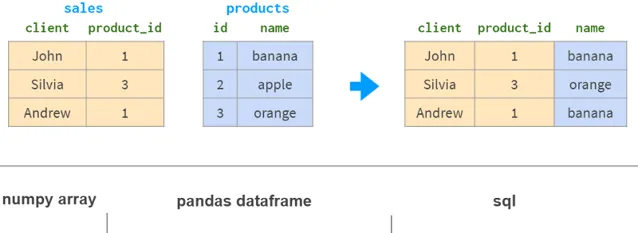
Pandas join具有所有熟悉的「內」、「左」、「右」和「全外部」連線模式。
按列分組
數據分析中的另一個常見操作是按列分組。例如,要獲得每種產品的總銷量,你可以這樣做:
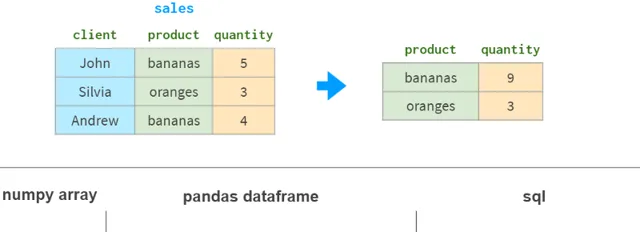
除了sum之外,Pandas還支持各種聚合函式:mean、max、min、count等。
7. 數據透視表
Pandas最強大的功能之一是「樞軸」表。這有點像將多維空間投影到二維平面上。
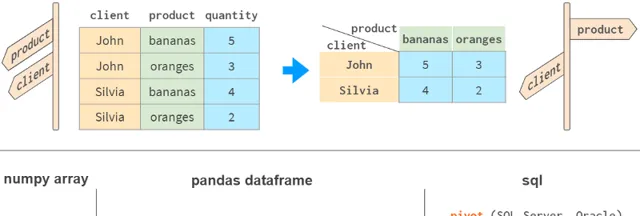
雖然用NumPy當然可以實作它,但這個功能沒有開箱即用,盡管它存在於所有主要的關聯式資料庫和電子試算表應用程式(Excel,WPS)中。
Pandas用df.pivot_table將分組和旋轉結合在一個工具中。
簡而言之,NumPy和Pandas的兩個主要區別如下:
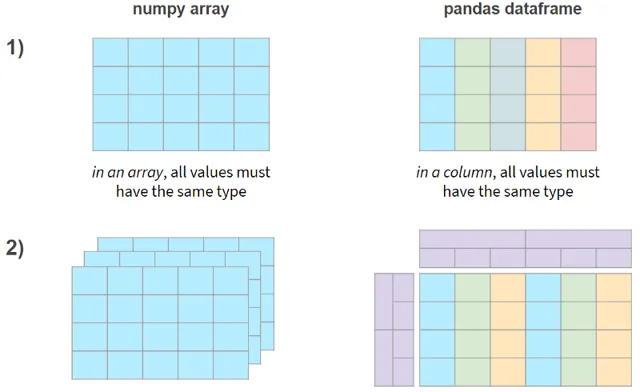
現在,讓我們看看這些功能是否以效能損失為代價。
Pandas速度
我在Pandas的典型工作負載上對NumPy和Pandas進行了基準測試:5-100列,10³- 10⁸行,整數和浮點數。下面是1行和1億行的結果:
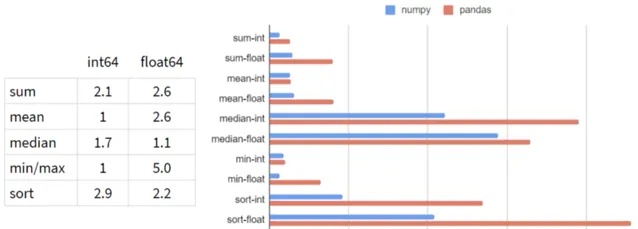
看起來在每一次操作中,Pandas都比NumPy慢!
當列數增延長,情況不會改變(可以預見)。至於行數,依賴關系(在對數尺度下)如下所示:

對於小陣列(少於100行),Pandas似乎比NumPy慢30倍,對於大陣列(超過100萬行)則慢3倍。
怎麽可能呢?也許是時候送出一個功能請求,建議Pandas透過df.column.values.sum()重新實作df.column.sum()了?這裏的values內容提供了存取底層NumPy陣列的方法,效能提升了3 ~ 30倍。
答案是否定的。Pandas在這些基本操作方面非常緩慢,因為它正確地處理了缺失值。Pandas需要NaNs (not-a-number)來實作所有這些類似資料庫的機制,比如分組和旋轉,而且這在現實世界中是很常見的。在Pandas中,我們做了大量工作來統一所有支持的數據型別對NaN的使用。根據定義(在CPU級別上強制執行),nan+anything會得到nan。所以
>>> np.sum([1, np.nan, 2])
nan
但是
>>> pd.Series([1, np.nan, 2]).sum()
3.0
一個公平的比較是使用np.nansum代替np.sum,用np.nanmean而不是np.mean等等。突然間……
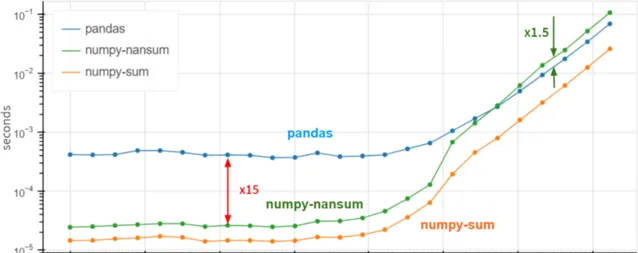
對於超過100萬個元素的陣列,Pandas的速度是NumPy的1.5倍。對於較小的陣列,它仍然比NumPy慢15倍,但通常情況下,無論操作在0.5 ms還是0.05 ms內完成都沒有太大關系——無論如何它都是快速的。
最重要的是,如果您100%確定列中沒有缺失值,則使用df.column.values.sum()而不是df.column.sum()可以獲得x3-x30的效能提升。在存在缺失值的情況下,Pandas的速度相當不錯,甚至在巨大的陣列(超過10個同質元素)方面優於NumPy。
第二部份. Series 和 Index
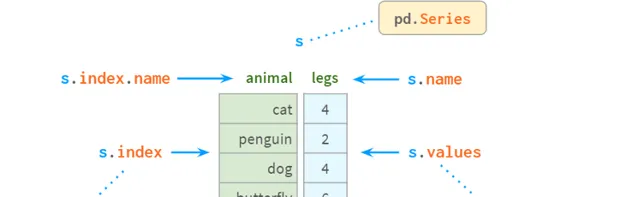
Series是NumPy中的一維陣列,是表示其列的DataFrame的基本組成部份。盡管與DataFrame相比,它的實際重要性正在降低(你可以在不知道Series是什麽的情況下完美地解決許多實際問題),但如果不首先學習Series和Index,你可能很難理解DataFrame是如何工作的。
在內部,Series將值儲存在普通的NumPy vector中。因此,它繼承了它的優點(緊湊的記憶體布局、快速的隨機存取)和缺點(型別同質、緩慢的刪除和插入)。最重要的是,Series允許使用類似於字典的結構index透過label存取它的值。標簽可以是任何型別(通常是字串和時間戳)。它們不必是唯一的,但唯一性是提高尋找速度所必需的,許多操作都假定唯一性。

如你所見,現在每個元素都可以透過兩種替代方式尋址:透過` label `(=使用索引)和透過` position `(=不使用索引):
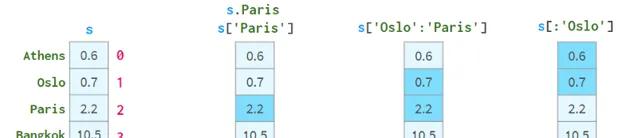
按「位置」尋址有時被稱為「位置索引」,這只是增加了混淆。
一對方括弧是不夠的。特別是:
S[2:3]不是解決元素2最方便的方式
如果名稱恰好是整數,s[1:3]就會產生歧義。它可能意味著名稱1到3包含或位置索引1到3不包含。
為了解決這些問題,Pandas還有兩種「風格」的方括弧,你可以在下面看到:

.loc總是使用標號,並且包含間隔的兩端。
.iloc總是使用「位置索引」並排除右端。
使用方括弧而不是圓括弧的目的是為了存取Python的切片約定:你可以使用單個或雙冒號,其含義是熟悉的start:stop:step。像往常一樣,缺少開始(結束)意味著從序列的開始(到結束)。step參數允許使用s.iloc[::2]參照偶數行,並使用s['Paris':'Oslo':-1]以相反的順序獲取元素。
它們還支持布爾索引(使用布爾陣列進行索引),如下圖所示:

你可以在下圖中看到它們如何支持` fancy indexing `(用整數陣列進行索引):

Series最糟糕的地方在於它的視覺表現:出於某種原因,它沒有一個很好的富文本外觀,所以與DataFrame相比,它感覺像是二等公民:

我對這個Series做了修補程式,讓它看起來更好,如下所示:
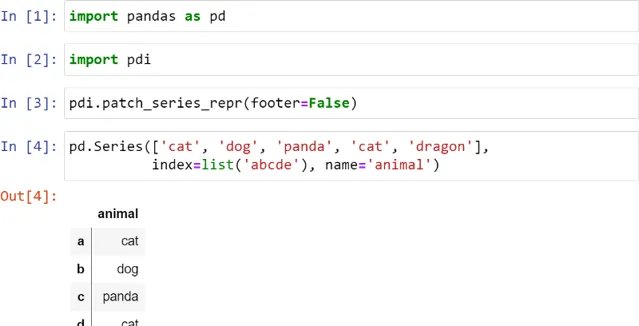
垂直線表示這是一個Series,而不是一個DataFrame。Footer在這裏被禁用了,但它可以用於顯示dtype,特別是分類型別。
您還可以使用pdi.sidebyside(obj1, obj2,…)並排顯示多個Series或dataframe:
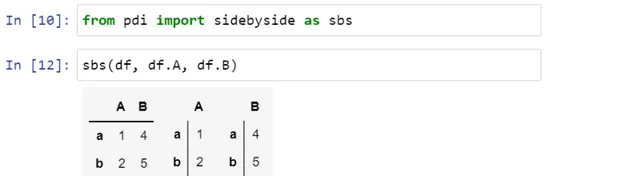
pdi(代表pandas illustrated)是github上的一個開源庫,具有本文所需的這個和其他功能。要使用它,就要寫
pip install pandas-illustrated
索引(Index)
負責透過標簽獲取元素的物件稱為index。它非常快:無論你有5行還是50億行,你都可以在常量時間內獲取一行數據。
指數是一個真正的多型生物。預設情況下,當建立一個沒有索引的序列(或DataFrame)時,它會初始化為一個惰性物件,類似於Python的range()。和range一樣,幾乎不使用任何記憶體,並且與位置索引無法區分。讓我們用下面的程式碼建立一個包含一百萬個元素的序列:
>>> s = pd.Series(np.zeros(10**6))
>>> s.index
RangeIndex(start=0, stop=1000000, step=1)
>>> s.index.memory_usage() # in bytes
128# the same as for Series([0.])
現在,如果我們刪除一個元素,索引隱式地轉換為類似於dict的結構,如下所示:
>>>s.drop(1,inplace=True)
>>>s.index
Int64Index([0,2,3,4,5,6,7,
...
999993,999994,999995,999996,999997,999998,999999],
dtype='int64',length=999999)
>>>s.index.memory_usage()
7999992
該結構消耗8Mb記憶體!為了擺脫它,回到輕量級的類range結構,添加如下程式碼:
>>> s.reset_index(drop=True, inplace=True)
>>> s.index
RangeIndex(start=0, stop=999999, step=1)
>>> s.index.memory_usage()
128
如果你不熟悉Pandas,你可能想知道為什麽Pandas自己沒有做到這一點?好吧,對於非數位標簽,有一點很明顯:為什麽(以及如何)Pandas在刪除一行後,會重新標記所有後續的行?對於數值型標簽,答案就有點復雜了。
首先,正如我們已經看到的,Pandas允許您純粹按位置參照行,因此,如果您想在刪除第3行之後定位第5行,則可以無需重新索引(這就是iloc的作用)。
其次,保留原始標簽是一種與過去時刻保持聯系的方法,就像「保存遊戲」按鈕一樣。假設您有一個100x1000000的大表,需要尋找一些數據。你正在一個接一個地進行幾次查詢,每次都縮小了搜尋範圍,但只檢視了一小部份列,因為同時檢視數百個欄位是不切實際的。現在您已經找到感興趣的行,您希望在原始表中檢視有關它們的所有資訊。數位索引可以幫助您立即獲得它,而無需任何額外的努力。
一般來說,在索引中保持值的唯一性是一個好主意。例如,在索引中存在重復值時,尋找速度不會得到提升。Pandas不像關系型資料庫那樣有「唯一約束」(該功能仍然是實驗性的),但它有檢查索引中的值是否唯一的函式,並以各種方式消除重復。
有時,一列不足以唯一標識一行。例如,同一個名字的城市有時會碰巧出現在不同的國家,甚至是同一個國家的不同地區。所以(城市,州)是一個比城市更好的標識一個地方的候選者。在資料庫中,這被稱為「復合主鍵」。在Pandas中,它被稱為多索引(參見下面的第4部份),索引中的每一列都被稱為「級別」。
索引的另一個重要特性是不可變。與DataFrame中的普通列不同,你不能就地更改它。索引中的任何更改都涉及從舊索引中獲取數據,修改它,並將新數據作為新索引重新附加。通常情況下,它是透明的,這就是為什麽不能直接寫df.City.name = ' city ',而必須寫一個不那麽明顯的df.rename(columns={' A ': ' A '}, inplace=True)
Index有一個名稱(在MultiIndex的情況下,每個級別都有一個名稱)。不幸的是,這個名稱在Pandas中沒有得到充分使用。一旦你在索引中包含了這一列,就不能再使用df了。不再使用列名表示法,並且必須恢復為可讀性較差的df。指數還是更通用的df。loc對於多索引,情況更糟。一個明顯的例外是df。Merge -你可以透過名稱指定要合並的列,無論它是否在索引中。
同樣的索引機制用於標記dataframe的行和列,以及序列。
按值尋找元素
Series內部由一個NumPy陣列和一個類似陣列的結構index組成,如下所示:
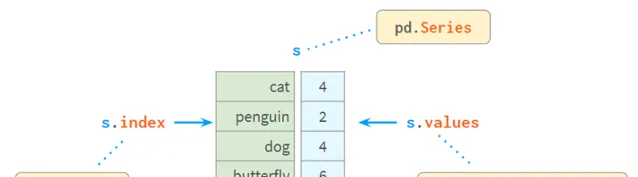
Index提供了一種透過標簽尋找值的方便方法。那麽如何透過值尋找標簽呢?
s.index[s.tolist().find(x)] # fasterforlen(s) < 1000
s.index[np.where(s.values==x)[0][0]] # fasterforlen(s) > 1000
我編寫了find()和findall()兩個簡單的封裝器,它們執行速度快(因為它們會根據序列的大小自動選擇實際的命令),而且使用起來更方便。程式碼如下所示:
>>> import pdi
>>> pdi.find(s, 2)
'penguin'
>>> pdi.findall(s, 4)
Index(['cat', 'dog'], dtype='object')
缺失值
Pandas開發人員特別關註缺失值。通常,你透過向read_csv提供一個標誌來接收一個帶有NaNs的dataframe。否則,可以在建構函式或設定運算子中使用None(盡管不同數據型別的實作略有不同,但它仍然有效)。這張圖片有助於解釋這個概念:
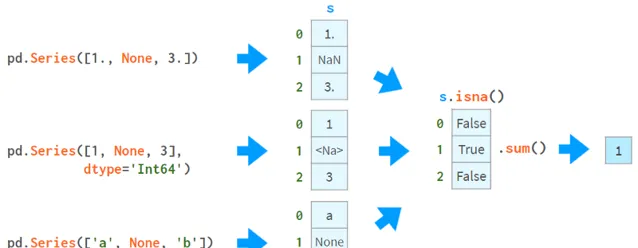
你可以使用NaNs做的第一件事是了解你是否有NaNs。從上圖可以看出,isna()生成了一個布爾陣列,而.sum()給出了缺失值的總數。
現在你知道了它們的存在,你可以選擇用常量值填充它們或透過插值來一次性刪除它們,如下所示:

另一方面,你可以繼續使用它們。大多數Pandas函式會很高興地忽略缺失值,如下圖所示:

更高級的函式(median、rank、quantile等)也可以做到這一點。
算術運算與索引對齊:
如果索引中存在非唯一值,則結果不一致。不要對索引不唯一的序列使用算術運算。
比較
比較有缺失值的陣列可能會比較棘手。下面是一個例子:
>>> np.all(pd.Series([1., None, 3.]) ==
pd.Series([1., None, 3.]))
False
>>> np.all(pd.Series([1, None, 3], dtype='Int64') ==
pd.Series([1, None, 3], dtype='Int64'))
True
>>> np.all(pd.Series(['a', None, 'c']) ==
pd.Series(['a', None, 'c']))
False
為了正確地比較nan,需要用陣列中一定沒有的元素替換nan。例如,使用-1或∞:
>>> np.all(s1.fillna(np.inf) == s2.fillna(np.inf)) # works for all dtypes
True
或者,更好的做法是使用NumPy或Pandas的標準比較函式:
>>> s = pd.Series([1., None, 3.])
>>> np.array_equal(s.values, s.values, equal_nan=True)
True
>>> len(s.compare(s)) == 0
True
這裏,compare函式返回一個差異列表(實際上是一個DataFrame), array_equal則直接返回一個布爾值。
當比較混合型別的 DataFrames 時,NumPy比較失敗(issue #19205),而Pandas工作得很好。如下所示:
>>> df = pd.DataFrame({'a': [1., None, 3.], 'b': ['x', None, 'z']})
>>> np.array_equal(df.values, df.values, equal_nan=True)
TypeError
<...>
>>> len(df.compare(df)) == 0
True
追加、插入、刪除
雖然Series物件被認為是size不可變的,但它可以在原地追加、插入和刪除元素,但所有這些操作都是:
慢,因為它們需要為整個物件重新分配記憶體和更新索引。
非常不方便。
下面是插入值的一種方式和刪除值的兩種方式:
第二種刪除值的方法(透過drop)比較慢,並且在索引中存在非唯一值時可能會導致復雜的錯誤。
Pandas有df.insert方法,但它只能將列(而不是行)插入到dataframe中(並且對series不起作用)。
添加和插入的另一種方法是使用iloc對DataFrame進行切片,套用必要的轉換,然後使用concat將其放回。我實作了一個名為insert的函式,可以自動執行這個過程:
註意(就像在df.insert中一樣)插入位置由位置0<=i<=len(s)指定,而不是索引中元素的標簽。如下所示:
要按元素的名稱插入,可以合並pdi。用pdi尋找。插入,如下所示:
請註意,unlikedf.insert、pdi.insert返回一個副本,而不是原地修改Series/DataFrame
統計數據
Pandas提供了全方位的統計函式。它們可以讓您了解百萬元素序列或DataFrame中的內容,而無需手動捲動數據。
所有Pandas統計函式都會忽略NaNs,如下所示:
註意,Pandas std給出的結果與NumPy std不同,如下所示:
>>> pd.Series([1, 2]).std()
0.7071067811865476
>>> pd.Series([1, 2]).values.std()
0.5
這是因為NumPy std預設使用N作為分母,而Pandas std預設使用N-1作為分母。兩個std都有一個名為ddof (` delta degrees of freedom `)的參數,NumPy預設為0,Pandas預設為1,這可以使結果一致。N-1是你通常想要的值(在均值未知的情況下估計樣本的偏差)。這裏有一篇維基百科的文章詳細介紹了貝茲的修正。
由於序列中的每個元素都可以透過標簽或位置索引存取,因此argmin (argmax)有一個姐妹函式idxmin (idxmax),如下圖所示:
下面是Pandas的自描述統計函式供參考:
std:樣本標準差
var,無偏變異數
sem,均值的無偏標準誤差
quantile分位數,樣本分位數(s.quantile(0.5)≈s.median())
oode是出現頻率最高的值
預設為Nlargest和nsmallest,按出現順序排列
diff,第一個離散差分
cumsum 和 cumprod、cumulative sum和product
cummin和cummax,累積最小值和最大值
以及一些更專業的統計函式:
pct_change,當前元素與前一個元素之間的變化百分比
skew偏態,無偏態(三階矩)
kurt或kurtosis,無偏峰度(四階矩)
cov、corr和autocorr、共變異數、相關和自相關
rolling捲動視窗、加權視窗和指數加權視窗
重復數據
在檢測和處理重復數據時需要特別小心,如下圖所示:
drop_duplicates和duplication可以保留最後一次出現的副本,而不是第一次出現的副本。
請註意,s.a uint()比np快。唯一性(O(N) vs O(NlogN)),它會保留順序,而不會返回排序結果。獨特的。
缺失值被視為普通值,有時可能會導致令人驚訝的結果。
如果你想排除nan,需要顯式地這樣做。在這個例子中,是s.l opdropna().is_unique == True。
還有一類單調函式,它們的名字是自描述的:
s.is_monotonic_increasing ()
s.is_monotonic_decreasing ()
s._strict_monotonic_increasing ()
s._string_monotonic_decreasing ()
s.is_monotonic()。這是意料之外的,出於某種原因,這是s.is_monotonic_increasing()。它只對單調遞減序列返回False。
分組
在數據處理中,一個常見的操作是計算一些統計量,不是針對整個數據集,而是針對其中的某些組。第一步是透過提供將一系列(或一個dataframe)分解為組的標準來定義一個「智慧物件」。這個`智慧物件`沒有立即的表示,但可以像Series一樣查詢它,以獲得每個組的某個內容,如下圖所示:
在這個例子中,我們根據數值除以10的整數部份將序列分成三組。對於每個組,我們請求每個組中元素的和、元素的數量以及平均值。
除了這些聚合函式,您還可以根據特定元素在組中的位置或相對值存取它們。如下所示:
你也可以使用g.ag (['min', 'max'])一次呼叫計算多個函式,或者使用g.c describe()一次顯示一堆統計函式。
如果這些還不夠,你還可以透過自己的Python函式傳遞數據。它可以是:
一個函式f,它接受一個組x(一個Series物件)並生成一個值(例如sum())與g.eapply (f)一起使用。
一個函式f,它接受一個組x(一個Series物件),並與g.transform(f)生成一個大小與x相同的Series物件(例如cumsum())。
在上面的例子中,輸入數據是有序的。groupby不需要這樣做。實際上,如果分組中的元素不是連續儲存的,它也同樣有效,因此它更接近於collections.defaultdict,而不是itertools.groupby。它總是返回一個沒有重復項的索引。
與defaultdict和關聯式資料庫GROUP BY子句不同,Pandas groupby按組名對結果進行排序。可以用sort=False來禁用它。
免責聲明:實際上,g.apply(f)比上面描述的更通用:
如果f(x)返回與x大小相同的序列,它可以模擬transform
如果f(x)返回一系列不同大小或不同的dataframe,則會得到一個具有相應多索引的序列。
但文件警告說,這些使用方法可能比相應的transform和agg方法慢,所以要小心。
第三部份. DataFrames
Pandas的主要數據結構是DataFrame。它將一個二維陣列與它的行和列的標簽捆綁在一起。它由一系列物件組成(具有共享索引),每個物件表示一列,可能具有不同的dtype。
讀寫CSV檔
構造DataFrame的一種常用方法是讀取csv(逗號分隔值)檔,如下圖所示:
pd.read_csv()函式是一個完全自動化且可瘋狂客製的工具。如果你只想學習Pandas的一件事,那就學習使用read_csv——它會有報酬的:)。
下面是一個解析非標準的.csv檔的例子:
以及一些簡要描述:
因為CSV沒有嚴格的規範,所以有時需要一些試錯才能正確地閱讀它。read_csv最酷的地方在於它會自動檢測很多東西:
列名和型別
布爾值的表示
缺失值的表示等。
與其他自動化一樣,你最好確保它做了正確的事情。如果在 Jupyter 單元中簡單地編寫df的結果碰巧太長(或太不完整),您可以嘗試以下操作:
df.head(5)或df[:5]顯示前5行
df.dtypes返回列的型別
df.shape返回行數和列數
Df.info()匯總所有相關資訊
將一列或幾列設定為索引是一個好主意。下圖展示了這個過程:
Index在Pandas中有很多用途:
算術運算按索引對齊
它使按該列進行的尋找更快,等等。
所有這些都是以較高的記憶體消耗和不太明顯的語法為代價的。
構建DataFrame
另一種選擇是從記憶體中已經儲存的數據中構建一個dataframe。它的建構函式非常全能,可以轉換(或包裝)任何型別的數據:
在第一種情況下,在沒有行標簽的情況下,Pandas用連續的整數標記行。在第二種情況下,它對行和列都進行了相同的操作。為Pandas提供列的名稱總是一個好主意,而不是整數標簽(使用columns參數),有時也可以提供行(使用index參數,盡管rows聽起來可能更直觀)。這張圖片會有幫助:
不幸的是,無法在DataFrame建構函式中為索引列設定名稱,所以唯一的選擇是手動指定,例如,df.index.name = '城市名稱'
下一種方法是使用NumPy向量組成的字典或二維NumPy陣列構造一個DataFrame:
請註意,在第二種情況下,人口數量的值被轉換為浮點數。實際上,它在之前的構建NumPy陣列時就發生過。這裏需要註意的另一件事是,從2D NumPy陣列構建dataframe預設是檢視。這意味著改變原始陣列中的值會改變dataframe,反之亦然。另外,它節省了記憶體。
第一種情況(NumPy向量組成的字典)也可以啟用這種模式,設定copy=False即可。不過,它非常脆弱。簡單的操作就可以把它變成副本而不需要通知。
另外兩個(不太有用的)建立DataFrame的選項是:
從一個dict列表(其中每個dict表示一行,其鍵是列名,其值是相應的單元格值)
來自由Series組成的dict(其中每個Series表示一列;預設情況下,可以讓它返回一個copy=False的檢視)。
如果你「動態」註冊流數據,最好的選擇是使用列表的dict或列表的列表,因為Python會透明地在列表末尾預分配空間,以便快速追加。NumPy陣列和Pandas dataframes都不能做到這一點。另一種可能性(如果你事先知道行數)是用DataFrame(np.zeros)之類的東西手動預分配記憶體。
DataFrames的基本操作
DataFrame最好的地方(在我看來)是你可以:
輕鬆存取其列,如d.area返回列值(或者df[' Area ']——適用於包含空格的列名)
將列作為自變量進行操作,例如使用afterdf. population /= 10**6人口以百萬計儲存,下面的命令根據現有列中的值建立一個名為` density `的新列。更多資訊見下圖:
註意,建立新列時,即使列名中不包含空格,也必須使用方括弧。
此外,你可以對不同dataframe中的列使用算術操作,只要它們的行具有有意義的標簽,如下所示:
索引DataFrames
正如我們在本系列中已經看到的,普通的方括弧不足以滿足索引的所有需求。你不能透過名稱存取行,不能透過位置索引存取不相交的行,你甚至不能參照單個單元格,因為df['x', 'y']是為多索引保留的!
為了滿足這些需求,dataframes,就像series一樣,有兩種可選的索引模式:按標簽索引的loc和按位置索引的iloc。
在Pandas中,參照多行/多列是一個副本,而不是檢視。但它是一種特殊的復制,允許賦值作為一個整體:
df.loc[‘a’]=10 works (一行作為一個整體是一個可寫的)
df.loc[‘a’][‘A’]=10 works (元素存取傳播到原始df)
df.loc[‘a’:’b’] = 10 works (assigning to a subar將整個作品賦值給一個子陣列)
df.loc[‘a’:’b’][‘A’] = 10 doesn’t (對其元素賦值不會).
在最後一種情況下,該值只會被設定在切片的副本上,而不會反映在原始df上(會相應地顯示一個警告)。
根據不同的背景,有不同的解決方案:
你想要改變原始的df。然後使用df。loc[' a': ' b ', ' a'] = 10
你故意建立了一個副本,然後想要處理這個副本:df1 = df.loc[' a ': ' b '];df1[' A ']=10 # SettingWithCopy warning要在這種情況下消除警告,請使其成為一個真正的副本:df1 = df.loc[' A ': ' b '].copy();df1 [A] = 10
Pandas還支持一種方便的NumPy語法來進行布爾索引。
當使用多個條件時,必須將它們括起來,如下所示:
當你期望返回一個值時,需要特別註意。
因為可能有多行匹配條件,所以loc返回一個序列。要從中得到純量值,你可以使用:
float(s)或更通用的s.e item(),除非序列中只有一個值,否則都會引發ValueError
S.iloc[0],僅在沒有找到時引發異常;此外,它是唯一支持賦值的函式:df[…].Iloc[0] = 100,但當你想修改所有匹配時,肯定不需要它:df[…]= 100。
或者,你可以使用基於字串的查詢:
df.query (' name = =「Vienna」)
df.query('population>1e6 and area<1000')它們更短,適合多索引,並且邏輯操作符優先於比較操作符(=需要更少的括弧),但它們只能按行過濾,並且不能透過它們修改Dataframe。
幾個第三方庫允許你使用SQL語法直接查詢dataframe ( duckdb ),或者透過將dataframe復制到SQLite並將結果包裝回Pandas objects (pandasql)來間接查詢dataframe。不出所料,直接法更快。
DataFrame算術
你可以對dataframes、series和它們的組合套用普通操作,如加、減、乘、除、求模、冪等。
所有的算術運算都是根據行標簽和列標簽對齊的:
在dataframe和Series之間的混合操作中,Series(天知道為什麽)表現得(和廣播)像一個行向量,並相應地對齊:
可能是為了與列表和一維NumPy向量保持一致(它們不按標簽對齊,並被認為是一個簡單的二維NumPy陣列的DataFrame):
因此,在不太幸運(也是最常見的!)的情況下,將一個dataframe除以列向量序列,你必須使用方法而不是操作符,如下所示:
由於這個有問題的決定,每當你需要在dataframe和列式序列之間執行混合操作時,你必須在文件中尋找它(或記住它):
結合DataFrames
Pandas有三個函式,concat、merge和join,它們做同樣的事情:將來自多個dataframe的資訊合並為一個。但是每個工具的實作方式都略有不同,因為它們是為不同的用例量身客製的。
垂直疊加
這可能是將兩個或多個dataframe合並為一個的最簡單方法:您獲取第一個dataframe中的行,並將第二個dataframe中的行追加到底部。為了使其工作,這兩個dataframe需要(大致)具有相同的列。這類似於NumPy中的vstack,正如你在影像中所看到的:
索引中有重復的值是不好的。你可能會遇到各種各樣的問題(參見下面的` drop `範例)。即使你不關心索引,也要盡量避免出現重復的值:
要麽使用reset_index=True參數
呼叫df.reset_index(drop=True)將行從0重新索引到len(df)-1,
使用keys參數可以解決MultiIndex的二義性(見下文)。
如果dataframe的列不能完美匹配(不同的順序在這裏不計算在內),Pandas可以取列的交集(預設值kind='inner ')或插入nan來標記缺失值(kind='outer'):
水平疊加
concat也可以執行「水平」堆疊(類似於NumPy中的hstack):
join比concat更可配置:特別是,它有五種連線模式,而concat只有兩種。詳情請參閱下面的「1:1關系連線」部份。
基於多指數的數據疊加
如果行標簽和列標簽一致,concat可以執行與垂直堆疊類似的多索引(就像NumPy中的dstack):
如果行和/或列部份重疊,Pandas將相應地對齊名稱,這很可能不是你想要的。下面的圖表可以幫助你將這個過程視覺化:
一般來說,如果標簽重疊,這意味著dataframe在某種程度上彼此相關,實體之間的關系最好使用關聯式資料庫的術語來描述。
1:1 連線的關系
當同一組物件的資訊儲存在幾個不同的DataFrame中時,你希望將它們合並為一個DataFrame。
如果要合並的列不在索引中,則使用merge。
它所做的第一件事是丟棄索引中的任何內容。然後執行聯結操作。最後,將結果從0重新編號為n-1。
如果列已經在索引中,則可以使用join(這只是merge的別名,將left_index或right_index設定為True,並設定不同的預設值)。
從這個簡化的例子中可以看出(參見上面的全外連線),與關系型資料庫相比,Pandas對行順序的處理相當輕松。左外聯結和右外聯結比內外聯結更容易預測(至少在需要合並的列中有重復值之前是這樣)。因此,如果你想保證行順序,就必須顯式地對結果進行排序。
1:n 連線的關系
這是資料庫設計中使用最廣泛的關系,表A中的一行(例如「State」)可以與表B中的幾行(例如城市)相關聯,但表B中的每一行只能與表A中的一行相關聯(即一個城市只能處於一種狀態,但一個狀態由多個城市組成)。
就像1:1關系一樣,在Pandas中連線一對1:n相關的表,你有兩種選擇。如果要合並的列或者不在索引中,並且可以丟棄碰巧在兩張表的索引中都存在的列,則使用merge。下面的例子會有所幫助:
正如我們已經看到的,merge對行順序的處理沒有Postgres嚴格:所有聲明的語句,保留的鍵順序只適用於left_index=True和/或right_index=True(這就是join的別名),並且只在要合並的列中沒有重復值的情況下。這就是為什麽join有一個sort參數。
現在,如果要合並的列已經在右側DataFrame的索引中,可以使用join(或者merge with right_index=True,這是完全相同的事情):
這次Pandas保留了左DataFrame的索引值和行順序。
註意:註意,如果第二個表有重復的索引值,你最終將在結果中得到重復的索引值,即使左表索引是唯一的!
有時,合並的dataframe具有同名的列。merge和join都有解決二義性的方法,但語法略有不同(預設情況下merge會用` _x `, ` _y `來解決,而join會丟擲異常),如下圖所示:
總結:
合並非索引列上的連線,連線要求列被索引
merge丟棄左DataFrame的索引,join保留它
預設情況下,merge執行行內結,join執行左外聯結
合並不保持行順序
Join可以保留它們(有一些限制)
join是合並的別名,left_index=True和/或right_index=True
多個連線
如上所述,當對兩個dataframe(如df.join(df1))執行join時,它充當了合並的別名。但是join也有一個` multiple join `模式,它只是concat(axis=1)的別名。
與普通模式相比,該模式有一些限制:
它沒有提供解析重復列的方法
它只適用於1:1關系(索引到索引連線)。
因此,多個1:n關系應該一個接一個地連線。倉庫` panda -illustrated `也提供了一個輔助方法,如下所示:
pdi.join是Join的一個簡單包裝器,它接受on、how和字尾參數,以便您可以在一個命令中進行多個聯結。與原始的關聯操作一樣,關聯的是屬於第一個DataFrame的列,其他DataFrame根據它們的索引進行關聯操作。
插入和刪除
由於DataFrame是列的集合,因此將這些操作套用到行上比套用到列上更容易。例如,插入一列總是在原地完成,而插入一行總是會生成一個新的DataFrame,如下所示:
刪除列通常不用擔心,除了del df['D']和del df。D則沒有(Python級別的限制)。
使用drop刪除行非常慢,如果原始標簽不是唯一的,可能會導致復雜的bug。下圖將幫助解釋這個概念:
一種解決方案是使用ignore_index=True,它告訴concat在連線後重設行名稱:
在這種情況下,將name列設定為索引將有所幫助。但對於更復雜的濾波器,它不會。
另一種快速、通用、甚至可以處理重復行名的解決方案是索引而不是刪除。為了避免顯式地否定條件,我寫了一個(只有一行程式碼的)自動化程式。
分組
這個操作已經在Series部份詳細描述過了。但是DataFrame的groupby在此基礎上有一些特定的技巧。
首先,你可以使用一個名稱來指定要分組的列,如下圖所示:
如果沒有as_index=False, Pandas將進行分組的列指定為索引。如果這不是我們想要的,可以使用reset_index()或指定as_index=False。
通常,數據框中的列比你想在結果中看到的多。預設情況下,Pandas會對所有遠端可求和的東西進行求和,因此你需要縮小選擇範圍,如下所示:
註意,當對單個列求和時,你將得到一個Series而不是DataFrame。如果出於某種原因,你想要一個DataFrame,你可以:
使用雙括弧:df.groupby('product')[['quantity']].sum()
顯式轉換:df.groupby('product')['quantity'].sum().to_frame()
切換到數值索引也會建立一個DataFrame:
df.groupby('product', as_index=False)['quantity'].sum()
df.groupby('product')['quantity'].sum().reset_index()
但是,盡管外觀不尋常,Series的行為就像DataFrames一樣,所以可能對pdi.patch_series_repr()進行「整容」就足夠了。
顯然,不同的列在分組時表現不同。例如,對數量求和完全沒問題,但對價格求和就沒有意義了。使用。agg可以為不同的列指定不同的聚合函式,如下圖所示:
或者,你可以為一列建立多個聚合函式:
或者,為了避免繁瑣的列重新命名,你可以這樣做:
有時,預定義的函式不足以產生所需的結果。例如,在平均價格時使用權重會更好。你可以為此提供一個自訂函式。與Series不同的是,該函式可以存取組中的多個列(它以子dataframe作為參數),如下所示:
不幸的是,你不能把預定義的聚合和幾個列級的自訂函式結合在一起,比如上面的那個,因為agg只接受單列級的使用者函式。單列範圍的使用者函式唯一可以存取的是索引,這在某些情況下很方便。例如,那天香蕉以5折的價格出售,如下圖所示:
為了從自訂函式中存取group by列的值,它事先已經包含在索引中。
通常,客製最少的函式可以獲得最好的效能。為了提高速度:
透過g.apply()實作多列範圍的自訂函式
透過g.agg()實作單列範圍的自訂函式(支持使用Cython或Numba進行加速)
預定義函式(Pandas或NumPy函式物件,或其字串名稱)。
預定義函式(Pandas或NumPy函式物件,或其字串名稱)。
數據透視表(pivot table)是一種有用的工具,通常與分組一起使用,從不同的角度檢視數據。
旋轉和`反旋轉`
假設你有一個變量a,它依賴於兩個參數i和j。有兩種等價的方法將它表示為一個表:
當數據是「密集的」(當有很少的0元素)時,` short `格式更合適,而當數據是「稀疏的」(大多數元素為0,可以從表中省略)時,` long `格式更好。當有兩個以上的參數時,情況會變得更加復雜。
當然,應該有一種簡單的方法來轉換這些格式。Pandas為此提供了一個簡單方便的解決方案:數據透視表。
作為一個不那麽抽象的例子,考慮下表中的銷售數據。有兩個客戶購買了兩種產品的指定數量最初,這個數據是短格式的。`要將其轉換為`長格式`,請使用df.pivot:
該命令丟棄了與操作無關的任何資訊(索引、價格),並將來自三個請求列的資訊轉換為長格式,將客戶名稱放入結果的索引中,將產品名稱放入列中,將銷售數量放入DataFrame的` body `中。
至於相反的操作,你可以使用stack。它將索引和列合並到MultiIndex中:
另一種選擇是使用melt:
註意,melt以不同的方式對結果行進行排序。
Pivot 遺失了結果的` body `的名稱資訊,因此無論是stack還是melt,我們都必須提醒pandas ` quantity `列的名稱。
在上面的例子中,所有的值都存在,但這不是必須的:
分組值然後旋轉結果的做法是如此常見,以至於groupby和pivot被捆綁在一個專用的函式(以及相應的DataFrame方法)數據透視表中:
如果沒有columns參數,它的行為與groupby類似
當沒有重復的行進行分組時,它的工作原理與pivot類似
否則,它會進行分組和旋轉
aggfunc參數控制哪一個聚合函式應該用於分組行(預設為均值)。
為了方便,pivot_table可以計算小計和合計:
一旦建立,pivot表就變成了一個普通的DataFrame,因此可以使用前面描述的標準方法查詢它。
當使用多索引時,透視表特別方便。我們已經見過很多Pandas函式返回多索引DataFrame的例子。讓我們仔細看看。
第四部份. MultiIndex
對於從未聽說過Pandas的人來說,多索引(MultiIndex)最直接的用法是使用第二個索引列作為第一個索引列的補充,以唯一地標識每行。例如,為了消除來自不同州的城市的歧義,州的名字通常附加在城市的名字後面。例如,在美國大約有40個springfield(在關系型資料庫中,它被稱為復合主鍵)。
你可以在從CSV解析DataFrame後指定要包含在索引中的列,也可以立即作為read_csv的參數。
您還可以使用append=True將現有級別添加到多重索引,如下圖所示:
另一個更典型的用例是表示多維。當你有一組具有特定內容的物件或者隨著時間的推移而演變的物件時。例如:
社會學調查的結果
` Titanic `數據集
歷史天氣觀測
錦標賽排名的年表。
這也被稱為「面板數據」,Pandas就是以此命名的。
讓我們添加這樣一個維度:
現在我們有了一個四維空間,如下所示:
年形成一個(幾乎連續的)維度
城市名稱沿第二條排列
第三個州的名字
特定的城市內容(「人口」、「密度」、「面積」等)在第四個維度上起到了「刻度線」的作用。
下圖說明了這個概念:
為了給對應列的尺寸名稱留出空間,Pandas將整個標題向上移動:
分組
關於多重索引需要註意的第一件事是,它並不按照它可能出現的情況對任何內容進行分組。在內部,它只是一個扁平的標簽序列,如下所示:
你可以透過對行標簽進行排序來獲得相同的groupby效果:
你甚至可以透過設定相應的Pandas選項來完全禁用視覺分組
:pd.options.display.multi_sparse=False。
型別轉換
Pandas(以及Python本身)區分數位和字串,因此在無法自動檢測數據型別時,通常最好將數位轉換為字串:
pdi.set_level(df.columns, 0, pdi.get_level(df.columns, 0).astype('int'))
如果你喜歡冒險,可以使用標準工具做同樣的事情:
df.columns = df.columns.set_levels(df.columns.levels[0].astype(int), level=0)
但為了正確使用它們,你需要理解什麽是` levels `和` codes `,而pdi允許你使用多索引,就像使用普通的列表或NumPy陣列一樣。
如果你真的想知道,` levels `和` codes `是特定級別的常規標簽列表被分解成的東西,以加速像pivot、join等操作:
pdi.get_level(df, 0) == Int64Index([2010, 2010, 2020, 2020])
df.columns.levels[0] == Int64Index([2010, 2020])
df.columns.codes[0] == Int64Index([0, 1, 0, 1])
使用多重索引構建一個Dataframe
除了從CSV檔讀取和從現有列構建外,還有一些方法可以建立多重索引。它們不太常用——主要用於測試和偵錯。
由於歷史原因,使用Panda自己的多索引表示的最直觀的方法不起作用。
這裏的` Levels `和` codes `(現在)被認為是不應該暴露給終端使用者的實作細節,但我們已經擁有了我們所擁有的。
可能最簡單的構建多重索引的方法如下:
這樣做的缺點是必須在單獨的一行中指定級別的名稱。有幾種可選的建構函式將名稱和標簽捆綁在一起。
當關卡形成規則結構時,您可以指定關鍵元素,並讓Pandas自動交織它們,如下所示:
上面列出的所有方法也適用於列。例如:
使用多重索引進行索引
透過多重索引存取DataFrame的好處是,您可以輕松地使用熟悉的語法一次參照所有級別(可能省略內部級別)。
列——透過普通的方括弧
行和單元格——使用.loc[]
現在,如果你想選擇奧勒岡州的所有城市,或者只留下包含人口的列,該怎麽辦?Python語法在這裏有兩個限制。
1. 沒有辦法區分df['a', 'b']和df[('a', 'b')]——它是以同樣的方式處理的,所以你不能只寫df[:, ' Oregon ']。否則,Pandas將永遠不知道你指的是列Oregon還是第二級行Oregon
2. Python只允許在方括弧內使用冒號,而不允許在圓括弧內使用冒號,所以你不能寫df.loc[(:, 'Oregon'),:]
在技術方面,這並不難安排。我給DataFrame打了猴修補程式,添加了這樣的功能,你可以在這裏看到:
這種語法唯一的缺點是,當你使用兩個索引器時,它返回一個副本,所以你不能寫df.mi[:, ' Oregon ']。Co [' population '] = 10。有許多可選的索引器,其中一些允許這樣的賦值,但它們都有自己的特點:
1. 您可以將內層與外層交換,並使用括弧。
因此,df[:, 'population']可以用df.swaplevel(axis=1)['population']實作。
這感覺很hacky,不方便超過兩層。
2. 你可以使用xs方法:df.xs (' population ', level=1, axis=1)。
它給人的感覺不夠python化,尤其是在選擇多個關卡時。這種方法無法同時過濾行和列,因此名稱xs(代表「橫截面」)背後的原因並不完全清楚。它不能用於設定值。
3.可以為pd建立別名。idx=pd.IndexSlice;df.loc [:, idx[:, ' population ']]
這更符合python風格,但要存取元素,必須使用別名,這有點麻煩(沒有別名的程式碼太長了)。您可以同時選擇行和列。可寫的。
4. 你可以學習如何使用slice代替冒號。如果你知道a[3:10:2] == a[slice(3,10,2)],那麽你可能也會理解下面的程式碼:df.loc[:, (slice(None), ' population ')],但它幾乎無法讀懂。您可以同時選擇行和列。可寫的。
作為底線,Pandas有多種使用括弧使用多重索引存取DataFrame元素的方法,但沒有一種方法足夠方便,因此他們不得不采用另一種索引語法:
5. 一個用於.query方法的迷你語言:df.query(' state=="Oregon" or city=="Portland" ')。
它方便快捷,但缺乏IDE的支持(沒有自動補全,沒有語法高亮等),而且它只過濾行,而不是列。這意味著你不能在不轉置DataFrame的情況下用它實作df[:, ' population '](除非所有列的型別都相同,否則會遺失型別)。Non-writable。
疊加與拆分
Pandas沒有針對列的set_index。向列中添加層次的一種常見方法是將現有的層次從索引中「解棧」:
Pandas的棧與NumPy的棧有很大不同。讓我們看看文件中對命名約定的說明:
「該函式的命名類似於重新組織的書籍集合,從水平位置並排(dataframe的列)到垂直堆疊(在dataframe的索引中)。」
「在上面」的部份聽起來並不能讓我信服,但至少這個解釋有助於記住誰把東西朝哪個方向移動。順便說一下,Series有unstack,但沒有stack,因為它已經「堆疊」了。由於是一維的,Series在不同情況下可以作為行向量或列向量,但通常被認為是列向量(例如dataframe列)。
例如:
您還可以透過名稱或位置索引指定要堆疊/解堆疊的級別。在這個例子中,df.stack()、df.stack(1)和df.stack(' year ')與df1.unstack()、df1.unstack(2)和df1.unstack(' year ')產生相同的結果。目的地總是在「最後一層之後」,並且不可配置。如果需要將級別放在其他地方,可以使用df.swaplevel().sort_index()或pdi。swap_level (df = True)
列必須不包含重復的值才能堆疊(在反堆疊時,索引也是如此):
如何防止疊加/分解排序
stack和unstack都有一個壞習慣,會不可預測地按字典順序排序結果索引。這有時可能令人惱火,但這是在有大量缺失值時給出可預測結果的唯一方法。
考慮下面的例子。你希望一周中的天數以何種順序出現在右邊的表中?
你可以推測,如果John的星期一在John的星期五的左邊,那麽就是' Mon ' < ' Fri ',類似地,Silvia的' Fri ' < ' Sun ',因此結果應該是' Mon ' < ' Fri ' < ' Sun '。這是合法的,但是如果剩余的列順序不同,比如' Mon ' < ' frii '和' Tue ' < ' frii ',該怎麽辦?或者' Mon ' < ' friday '和' Wed ' < ' Sat ' ?
好吧,一周沒有那麽多天,Pandas可以根據先驗知識推斷出順序。但是,人類還沒有得出一個決定性的結論,那就是星期天應該作為一周的結束還是開始。Pandas應該預設使用哪種順序?閱讀區域設定?那麽不那麽瑣碎的順序呢,比如美國的州的順序?
在這種情況下,Pandas所做的只是簡單地按字母順序排序,如下所示:
雖然這是一個合理的預設,但感覺上仍然是錯誤的。應該有一個解決方案!有一個。它被稱為CategoricalIndex。即使缺少一些標簽,它也會記住順序。它最近已經順利整合到Pandas工具鏈中。它唯一缺少的是基礎設施。它很難建立;它是脆弱的(在某些操作中會退回到物件),但它是完全可用的,並且pdi庫有一些幫助程式可以陡峭地提高學習曲線。
例如,要告訴Pandas釘選儲存產品的簡單索引的順序(如果你決定將一周中的天數解棧回列,則不可避免地會排序),你需要編寫像df這樣可怕的程式碼。index = pd.CategoricalIndex(df. index)df指數。指數排序= True)。它更適合多索引。
pdi庫有一個輔助函式locked(以及一個預設為inplace=True的別名lock),透過將某個多索引級別提升到CategoricalIndex來釘選該級別的順序:
等級名稱旁邊的勾選標記表示等級被釘選。它可以使用pdi.vis(df)手動視覺化,也可以使用pdi.vis_patch()對DataFrame HTML輸出進行monkey修補程式自動視覺化。套用修補程式後,在Jupyter單元中簡單地寫` df `將顯示釘選順序的所有級別的復選標記。
Lock和locked在簡單的情況下自動工作(如客戶端名稱),但在更復雜的情況下(如缺少日期的星期幾)需要使用者提示。
在級別切換到CategoricalIndex之後,它會在sort_index、stack、unstack、pivot、pivot_table等操作中保持原來的順序。
不過,它很脆弱。即使像df[' new_col '] = 1這樣簡單的操作也會破壞它。使用pdi.insert (df。columns, 0, ' new_col ', 1)用CategoricalIndex正確處理級別。
操作級別
除了前面提到的方法之外,還有一些其他的方法:
pdi.get_level(obj, level_id)返回透過數位或名稱參照的特定級別,可用於DataFrames, Series和MultiIndex
pdi.set_level(obj, level_id, labels)用給定的陣列(list, NumPy array, Series, Index等)替換關卡的標簽
pdi.insert_level (obj, pos, labels, name)使用給定的值添加一個層級(必要時適當廣播)
pdi.drop_level(obj, level_id)從多重索引中刪除指定的級別
pdi.swap_levels (obj, src=-2, dst=-1)交換兩個級別(預設是兩個最內層的級別)
pdi.move_level (obj, src, dst)將特定級別src移動到指定位置dst
除了上述參數外,本節中的所有函式還有以下參數:
axis=None其中None對於DataFrame表示「列」,對於Series表示「索引」
sort=False,可選在操作之後對相應的多索引進行排序
inplace=False,可選地原地執行操作(不能用於單個索引,因為它是不可變的)。
上面的所有操作都是從傳統意義上理解「級別」這個詞的(級別的標簽數量與數據框中的列數量相同),隱藏了索引的機制。標簽和索引。來自終端使用者的程式碼。
在極少數情況下,當移動和交換單獨的關卡不夠時,您可以使用純Pandas呼叫:df一次性重新排序所有關卡。columns = df.columns.reorder_levels([' M ', ' L ', ' K '])其中[' M ', ' L ', ' K ']是層的期望順序。
通常,使用get_level和set_level對標簽進行必要的修復就足夠了,但如果你想一次對多索引的所有級別套用轉換,Pandas有一個(命名不明確)函式rename接受一個dict或一個函式:
至於重新命名級別,它們的名稱儲存在.names欄位中。該欄位不支持直接賦值(為什麽不?):df.index.names[1] = ' x ' # TypeError,但可以作為一個整體替換:
當你只需要重新命名一個特定的級別時,語法如下:
將多索引轉換為平面索引並恢復它
正如我們在上面看到的,便捷的查詢方法只解決了處理行中的多索引的復雜性。盡管有這麽多的輔助函式,但當某些Pandas函式返回列中的多索引時,對初學者來說會有一個震驚的效果。因此,pdi庫具有以下內容:
join_levels(obj, sep=’_’, name=None) 將所有多索引級別連線到一個索引
split_level(obj, sep=’_’, names=None)將索引拆分回多索引
它們都有可選的axis和inplace參數。
排序MultiIndex
由於多索引由多個級別組成,因此排序比單索引更做作。這仍然可以使用sort_index方法完成,但可以使用以下參數進行進一步微調。
要對列級別進行排序,指定axis=1。
讀寫多索引dataframe到磁盤
Pandas可以以完全自動化的方式將具有多重索引的DataFrame寫入CSV檔:df.to_csv('df.csv ')。但是在讀取這樣的檔時,Pandas無法自動解析多重索引,需要使用者的一些提示。例如,要讀取具有三層高列和四層寬索引的DataFrame,你需要指定pd.read_csv('df.csv', header=[0,1,2], index_col=[0,1,2,3])。
這意味著前三行包含有關列的資訊,後續每一行的前四個欄位包含索引級別(如果列的級別不止一個,你不能再透過名稱來參照行級別,只能透過編號)。
手動解讀多索引中的層數是不方便的,所以更好的主意是在將DataFrame保存到CSV之前,stack()所有列頭層,並在讀取後將它們解stack()。
如果你需要「置之不理」的解決方案,可能需要研究二進制格式,例如Python的pickle格式:
直接呼叫:df.to_pickle('df.pkl'), pd.read_pickle('df.pkl')
使用storemagic在Jupyter %store df然後%store -r df(儲存在$
HOME/.ipython/profile_default/db/autorestore)
Python的pickle小巧而快速,但只能在Python中存取。如果您需要與其他生態系互操作,請檢視更標準的格式,如Excel格式(在讀取MultiIndex時需要與read_csv相同的提示)。程式碼如下:
!pipinstallopenpyxl
df.to_excel('df3.xlsx')
df.to_pd.read_excel('df3.xlsx', header=[0,1,2], index_col=[0,1,2,3])
或者檢視其他選項(參見文件)。
MultiIndex算術
當使用多索引數據框時,與普通數據框適用相同的規則(見上文)。但是處理細胞的一個子集有它自己的一些特性。
使用者可以透過外部的多索引級別更新部份列,如下所示:
如果想保持原始數據不變,可以使用df1 = df.assign(population=df.population*10)。
你也可以用density=df.population/df.area輕松獲得人口密度。
但不幸的是,你不能用df.assign將結果賦值給原始的dataframe。
一種方法是將列索引的所有不相關級別堆疊到行索引中,執行必要的計算,然後將它們解堆疊回去(使用pdi)。鎖以保持列的原始順序)。
或者,你也可以使用pdi.assign:
pdi.assign是釘選順序感知的,所以如果你給它一個(多個)釘選級別的dataframe,它不會解鎖它們或後續的棧/解棧/等。操作將保持原始的列和行順序。
總而言之,Pandas是分析和處理數據的好工具。希望這篇文章能幫助你理解「如何」和「為什麽」解決典型問題,並欣賞Pandas庫的真正價值和美麗。
為了跟上AI時代我幹了一件事兒,我建立了一個知識星球社群:ChartGPT與副業。想帶著大家一起探索 ChatGPT和新的AI時代 。
有很多小夥伴搞不定ChatGPT帳號,於是我們決定,凡是這三天之內加入ChatPGT的小夥伴,我們直接送一個正常可用的永久ChatGPT獨立帳戶。
不光是增長速度最快,我們的星球品質也絕對經得起考驗,短短一個月時間,我們的課程團隊釋出了 8個專欄、18個副業計畫 :
簡單說下這個星球能給大家提供什麽:
1、不斷分享如何使用ChatGPT來完成各種任務,讓你更高效地使用ChatGPT,以及副業思考、變現思路、創業案例、落地案例分享。
2、分享ChatGPT的使用方法、最新資訊、商業價值。
3、探討未來關於ChatGPT的機遇,共同成長。
4、幫助大家解決ChatGPT遇到的問題。
5、 提供一整年的售後服務,一起搞副業
星球福利:
1、加入星球4天後,就送ChatGPT獨立帳號。
2、邀請你加入ChatGPT會員交流群。
3、贈送一份完整的ChatGPT手冊和66個ChatGPT副業賺錢手冊。
其它福利還在籌劃中... 不過,我給你大家保證,加入星球後,收獲的價值會遠遠大於今天加入的門票費用 !
本星球第一期原價 399 ,目前屬於試營運,早鳥價 169 ,每超過50人漲價10元,星球馬上要來一波大的漲價,如果你還在猶豫,可能最後就要以 更高價格加入了 。。
早就是優勢。建議大家盡早以便宜的價格加入!
歡迎有需要的同學試試,如果本文對您有幫助,也請幫忙點個 贊 + 在看 啦!❤️
在 還有更多優質計畫系統學習資源,歡迎分享給其他同學吧!
你還有什
麽想要補充的嗎?
免責聲明:本文內容來源於網路,文章版權歸原作者所有,意在傳播相關技術知識&行業趨勢,供大家學習交流,若涉及作品版權問題,請聯系刪除或授權事宜。
技術君個人微信
添加技術君個人微信即送一份驚喜大禮包
→ 技術資料共享
→ 技術交流社群
--END--
往日熱文:
Python程式設計師深度學習的「四大名著」:
這四本書著實很不錯!我們都知道現在機器學習、深度學習的資料太多了,面對海量資源,往往陷入到「無從下手」的困惑出境。而且並非所有的書籍都是優質資源,浪費大量的時間是得不償失的。給大家推薦這幾本好書並做簡單介紹。
獲得方式:
1.掃碼關註本公眾號
2.後台回復關鍵詞:名著
▲長按掃描關註,回復名著即可獲取











