點選上方 "
Python人工智慧技術
"
關註,
星標或者置頂
22點24分準時推播,第一時間送達
後台回復「
大禮包
」,送你特別福利
編輯:樂樂 | 來自: 七天小碼哥
上一篇:
正文
大家好,我是Python人工智慧技術
想要快速學習爬蟲,最值得學習的語言一定是Python,Python套用場景比較多,比如: Web快速開發、爬蟲、自動化運維等等, 可以做簡單網站、自動發帖指令碼、收發信件指令碼、簡單驗證碼辨識指令碼。

爬蟲在開發過程中也有很多復用的過程,今天就總結一下必備的8大技巧,以後也能省時省力,高效完成任務。
1 基本抓取網頁
get方法
import urllib2
url = "http://www.baidu.com"
response = urllib2.urlopen(url)
print response.read()
post方法
import urllib
import urllib2
url = "http://abcde.com"
form = {'name':'abc','password':'1234'}
form_data = urllib.urlencode(form)
request = urllib2.Request(url,form_data)
response = urllib2.urlopen(request)
print response.read()
2 使用代理IP
在開發爬蟲過程中經常會遇到 IP被封掉 的情況,這時就需要用到代理IP;在urllib2包中有ProxyHandler類,透過此類可以設定 代理存取網頁 ,如下程式碼片段:
import urllib2
proxy = urllib2.ProxyHandler({'http': '127.0.0.1:8087'})
opener = urllib2.build_opener(proxy)
urllib2.install_opener(opener)
response = urllib2.urlopen('http://www.baidu.com')
print response.read()
3 Cookies處理
cookies是某些網站為了
辨別使用者身份
、進行session跟蹤而儲存在使用者本地終端上的數據(通常經過加密),python提供了cookielib模組用於處理cookies,cookielib模組的主要作用是提供可儲存cookie的物件,以便於與urllib2模組配合使用來存取Internet資源。
程式碼片段:
import urllib2, cookielib
cookie_support= urllib2.HTTPCookieProcessor(cookielib.CookieJar())
opener = urllib2.build_opener(cookie_support)
urllib2.install_opener(opener)
content = urllib2.urlopen('http://XXXX').read()
關鍵在於CookieJar(),它用於管理HTTP cookie值、儲存HTTP請求生成的cookie、向傳出的HTTP請求添加cookie的物件。整個cookie都儲存在記憶體中,對CookieJar例項進行垃圾回收後cookie也將遺失,所有過程都不需要單獨去操作。
手動添加cookie:
cookie = "PHPSESSID=91rurfqm2329bopnosfu4fvmu7; kmsign=55d2c12c9b1e3; KMUID=b6Ejc1XSwPq9o756AxnBAg="
request.add_header("Cookie", cookie)
4 偽裝成瀏覽器
某些網站反感爬蟲的到訪,於是對爬蟲一律拒絕請求。所以用urllib2直接存取網站經常會出現
HTTP Error 403: Forbidden
的情況。
對有些 header 要特別留意,Server 端會針對這些 header 做檢查:
User-Agent 有些 Server 或 Proxy 會檢查該值,用來判斷是否是瀏覽器發起的 Request
Content-Type 在使用 REST 介面時,Server 會檢查該值,用來確定 HTTP Body 中的內容該怎樣解析
這時可以透過修改http包中的header來實作,程式碼片段如下:
import urllib2
headers = {
'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'
}
request = urllib2.Request(
url = 'http://my.oschina.net/jhao104/blog?catalog=3463517',
headers = headers
)
print urllib2.urlopen(request).read()
5 頁面解析
對於頁面解析最強大的當然是 正規表式 ,這個對於不同網站不同的使用者都不一樣,就不用過多的說明其次就是 解析庫 了,常用的有兩個lxml和BeautifulSoup對於這兩個庫,我的評價是,都是HTML/XML的處理庫,Beautifulsoup純python實作,效率低,但是 功能實用 ,比如能用透過結果搜尋獲得某個HTML節點的源碼;lxml C語言編碼,高效,支持Xpath。
6 驗證碼的處理
對於一些簡單的驗證碼,可以進行簡單的辨識。本人也只進行過一些簡單的驗證碼辨識。但是有些反人類的驗證碼,比如12306,可以透過打碼平台進行人工打碼,當然這是要付費的。
7 gzip壓縮
有沒有遇到過某些網頁,不論怎麽轉碼都是一團亂碼。哈哈,那說明你還不知道
許多web服務具有發送壓縮數據的能力
,這可以將網路路線上傳輸的大量數據
消減 60%****以上
。這尤其適用於XML web 服務,因為 XML 數據 的壓縮率可以很高。
但是一般伺服器不會為你發送壓縮數據,除非你告訴伺服器你可以處理壓縮數據。
於是需要這樣修改程式碼:
import urllib2, httplib
request = urllib2.Request('http://xxxx.com')
request.add_header('Accept-encoding', 'gzip')
opener = urllib2.build_opener()
f = opener.open(request)
這是關鍵:建立Request物件,添加一個 Accept-encoding 頭資訊告訴伺服器你能接受 gzip 壓縮數據。
然後就是解壓縮數據:
import StringIO
import gzip
compresseddata = f.read()
compressedstream = StringIO.StringIO(compresseddata)
gzipper = gzip.GzipFile(fileobj=compressedstream)
print gzipper.read()
8 多執行緒並行抓取
單執行緒太慢的話,就需要多執行緒了,這裏給個簡單的執行緒池樣版 這個程式只是簡單地打印了1-10,但是可以看出是並行的。
雖然說Python的多執行緒很雞肋,但是對於爬蟲這種網路頻繁型,還是能一定程度提高效率的。
from threading import Thread
from Queue import Queue
from time import sleep
# q是任務佇列
#NUM是並行執行緒總數
#JOBS是有多少任務
q = Queue()
NUM = 2
JOBS = 10
#具體的處理常式,負責處理單個任務
defdo_somthing_using(arguments):
print arguments
#這個是工作行程,負責不斷從佇列取數據並處理
defworking():
whileTrue:
arguments = q.get()
do_somthing_using(arguments)
sleep(1)
q.task_done()
#fork NUM個執行緒等待佇列
for i in range(NUM):
t = Thread(target=working)
t.setDaemon(True)
t.start()
#把JOBS排入佇列
for i in range(JOBS):
q.put(i)
#等待所有JOBS完成
q.join()
為了跟上AI時代我幹了一件事兒,我建立了一個知識星球社群:ChartGPT與副業。想帶著大家一起探索 ChatGPT和新的AI時代 。
有很多小夥伴搞不定ChatGPT帳號,於是我們決定,凡是這三天之內加入ChatPGT的小夥伴,我們直接送一個正常可用的永久ChatGPT獨立帳戶。
不光是增長速度最快,我們的星球品質也絕對經得起考驗,短短一個月時間,我們的課程團隊釋出了 8個專欄、18個副業計畫 :
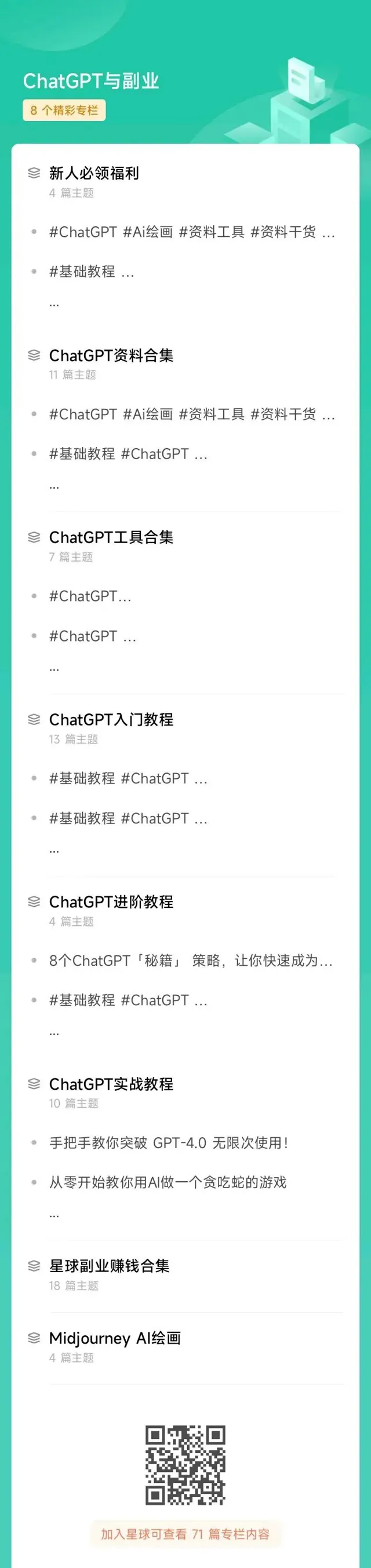
簡單說下這個星球能給大家提供什麽:
1、不斷分享如何使用ChatGPT來完成各種任務,讓你更高效地使用ChatGPT,以及副業思考、變現思路、創業案例、落地案例分享。
2、分享ChatGPT的使用方法、最新資訊、商業價值。
3、探討未來關於ChatGPT的機遇,共同成長。
4、幫助大家解決ChatGPT遇到的問題。
5、 提供一整年的售後服務,一起搞副業
星球福利:
1、加入星球4天後,就送ChatGPT獨立帳號。
2、邀請你加入ChatGPT會員交流群。
3、贈送一份完整的ChatGPT手冊和66個ChatGPT副業賺錢手冊。
其它福利還在籌劃中... 不過,我給你大家保證,加入星球後,收獲的價值會遠遠大於今天加入的門票費用 !
本星球第一期原價 399 ,目前屬於試營運,早鳥價 169 ,每超過50人漲價10元,星球馬上要來一波大的漲價,如果你還在猶豫,可能最後就要以 更高價格加入了 。。
早就是優勢。建議大家盡早以便宜的價格加入!


歡迎有需要的同學試試,如果本文對您有幫助,也請幫忙點個 贊 + 在看 啦!❤️
在 還有更多優質計畫系統學習資源,歡迎分享給其他同學吧!
你還有什
麽想要補充的嗎?
免責聲明:本文內容來源於網路,文章版權歸原作者所有,意在傳播相關技術知識&行業趨勢,供大家學習交流,若涉及作品版權問題,請聯系刪除或授權事宜。
技術君個人微信
添加技術君個人微信即送一份驚喜大禮包
→ 技術資料共享
→ 技術交流社群

--END--
往日熱文:
Python程式設計師深度學習的「四大名著」:

這四本書著實很不錯!我們都知道現在機器學習、深度學習的資料太多了,面對海量資源,往往陷入到「無從下手」的困惑出境。而且並非所有的書籍都是優質資源,浪費大量的時間是得不償失的。給大家推薦這幾本好書並做簡單介紹。
獲得方式:
1.掃碼關註本公眾號
2.後台回復關鍵詞:名著
▲長按掃描關註,回復名著即可獲取











