連結:https://mp.weixin.qq.com/s/Rey0gSnnj-zoAEwE6J-Gjw
Linux系統的效能是指作業系統完成任務的有效性、穩定性和響應速度。Linux系統管理員可能經常會遇到系統不穩定、響應速度慢等問題,例如在Linux上搭建了一個web服務,經常出現網頁無法開啟、開啟速度慢等現象,而遇到這些問題,就有人會抱怨Linux系統不好,其實這些都是表面現象。
作業系統完成一個任務時,與系統自身設定、網路拓樸結構、路由裝置、路由策略、接入裝置、物理路線等多個方面都密切相關,任何一個環節出現問題,都會影響整個系統的效能。 因此當Linux套用出現問題時,應當從應用程式、作業系統、伺服器硬體、網路環境等方面綜合排查,定位問題出現在哪個部份,然後集中解決。
隨著容器時代的普及和AI技術的顛覆,面對越來越復雜的業務和架構,再加上企業的降本增效已提上了日程,因此對Linux的高效能、可靠性提出了更高的要求,Linux效能最佳化成為運維人員的必備的核心技能。
例如,主機CPU使用率過高報警,登入Linux上去top完之後,卻不知道怎麽進一步定位,到底是系統CPU資源太少,還是應用程式導致的問題?這些Linux效能問題一直困擾著我們,哪怕工作多年的資深工程師也不例外。
1、影響Linux系統效能的因素一般有哪些?
@zhaoxiaoyong081
平安科技
資深工程師:
Linux系統的效能受多個因素的影響。以下是一些常見的影響Linux系統效能的因素:
CPU負載:CPU的利用率和負載水平對系統效能有直接影響。高CPU負載可能導致行程響應變慢、延遲增加和系統變得不穩定。
記憶體使用:記憶體是系統執行的關鍵資源。當系統記憶體不足時,可能會導致行程被終止、交換分區使用過多以及系統效能下降。
磁盤I/O:磁盤I/O效能是影響系統響應時間和吞吐量的重要因素。高磁盤I/O負載可能導致延遲增加、響應變慢和系統效能下降。
網路負載:網路流量的增加和網路延遲會對系統效能產生影響。高網路負載可能導致網路延遲增加、響應變慢和系統資源競爭。
行程排程:Linux系統使用行程排程器來管理和分配CPU資源。排程演算法的選擇和配置會影響行程的優先級和執行順序,從而影響系統的響應能力和負載均衡。
檔案系統效能:檔案系統的選擇和配置對磁盤I/O效能有影響。不同的檔案系統可能在效能方面有所差異,適當的檔案系統選項和調整可以改善系統效能。
內核參數:Linux內核有許多可調整的參數,可以影響系統的效能和行為。例如,TCP/IP參數、記憶體管理參數、檔案系統緩存等。適當的內核參數調整可以改善系統的效能和資源利用率。
資源限制和配額:在多使用者環境中,資源限制和配額的設定可以控制每個使用者或行程可使用的資源量。適當的資源管理可以避免某些行程耗盡系統資源而導致效能問題。
這些因素之間相互關聯,對系統效能產生綜合影響。為了最佳化Linux系統效能,需要綜合考慮並適當調整這些因素,以滿足特定的需求和使用情況。
2、工作中有沒有快速排除故障的辦法?
@zhaoxiaoyong081 平安科技 資深工程師:
1.CPU 效能分析
利用 top、vmstat、pidstat、strace 以及 perf 等幾個最常見的工具,獲取 CPU 效能指標後,再結合行程與 CPU 的工作原理,就可以迅速定位出 CPU 效能瓶頸的來源。
比如說,當你收到系統的使用者 CPU 使用率過高告警時,從監控系統中直接查詢到,導致 CPU 使用率過高的行程;然後再登入到行程所在的 Linux 伺服器中,分析該行程的行為。你可以使用 strace,檢視行程的系統呼叫匯總;也可以使用 perf 等工具,找出行程的熱點函式;甚至還可以使用動態追蹤的方法,來觀察行程的當前執行過程,直到確定瓶頸的根源。
2.記憶體效能分析
可以透過 free 和 vmstat 輸出的效能指標,確認記憶體瓶頸;然後,再根據記憶體問題的型別,進一步分析記憶體的使用、分配、泄漏以及緩存等,最後找出問題的來源。
比如說,當你收到記憶體不足的告警時,首先可以從監控系統中。找出占用記憶體最多的幾個行程。然後,再根據這些行程的記憶體占用歷史,觀察是否存在記憶體泄漏問題。確定出最可疑的行程後,再登入到行程所在的 Linux 伺服器中,分析該行程的記憶體空間或者記憶體分配,最後弄清楚行程為什麽會占用大量記憶體。
3.磁盤和檔案系統 I/O 效能分析
當你使用 iostat ,發現磁盤 I/O 存在效能瓶頸(比如 I/O 使用率過高、響應時間過長或者等待佇列長度突然增大等)後,可以再透過 pidstat、 vmstat 等,確認 I/O 的來源。接著,再根據來源的不同,進一步分析檔案系統和磁盤的使用率、緩存以及行程的 I/O 等,從而揪出 I/O 問題的真兇。
比如說,當你發現某塊磁盤的 I/O 使用率為 100% 時,首先可以從監控系統中,找出 I/O 最多的行程。然後,再登入到行程所在的 Linux 伺服器中,借助 strace、lsof、perf 等工具,分析該行程的 I/O 行為。最後,再結合應用程式的原理,找出大量 I/O 的原因。
4.網路效能分析
而要分析網路的效能,要從這幾個協定層入手,透過使用率、飽和度以及錯誤數這幾類效能指標,觀察是否存在效能問題。比如 :
在鏈路層,可以從網路介面的吞吐量、丟包、錯誤以及軟中斷和網路功能解除安裝等角度分析;
在網路層,可以從路由、分片、疊加網路等角度進行分析;
在傳輸層,可以從 TCP、UDP 的協定原理出發,從連線數、吞吐量、延遲、重傳等角度進行分析;
比如,當你收到網路不通的告警時,就可以從監控系統中,尋找各個協定層的丟包指標,確認丟包所在的協定層。然後,從監控系統的數據中,確認網路頻寬、緩沖區、連線跟蹤數等軟硬體,是否存在效能瓶頸。最後,再登入到發生問題的 Linux 伺服器中,借助 netstat、tcpdump、bcc 等工具,分析網路的收發數據,並且結合內核中的網路選項以及 TCP 等網路協定的原理,找出問題的來源。
3、Linux環境下,怎麽排查os中系統負載過高的原因瓶頸?
@zhaoxiaoyong081 平安科技 資深工程師:
在Linux環境下排查系統負載過高的原因和瓶頸,可以采取以下步驟:
使用top或htop命令觀察系統整體負載情況。檢視load average的值,分別表示系統在1分鐘、5分鐘和15分鐘內的平均負載。如果負載值超過CPU核心數量的70-80%,表示系統負載過高。
使用top或htop命令檢視CPU占用率。觀察哪些行程占用了大量的CPU資源。如果有某個行程持續高CPU占用,可能是引起負載過高的原因之一。
使用free命令檢視系統記憶體使用情況。觀察記憶體的使用量和剩余量。如果記憶體使用量接近或超過實體記憶體容量,可能導致系統開始使用交換空間(swap),進而影響系統效能。
使用iotop命令檢視磁盤I/O使用情況。觀察磁盤讀寫速率和占用率。如果磁盤I/O負載過高,可能導致系統響應變慢。
使用netstat命令或類似工具檢視網路連線情況。觀察是否存在大量的網路連線或網路流量。如果網路連線過多或網路流量過大,可能影響系統的效能。
檢查日誌檔。檢視系統日誌檔(如/var/log/messages、/var/log/syslog)以及應用程式日誌,尋找任何異常或錯誤資訊,可能有助於確定導致負載過高的問題。
使用perf或strace等工具進行行程級別的效能分析。這些工具可以幫助你跟蹤行程的系統呼叫、函式呼叫和效能瓶頸,進一步確定導致負載過高的具體原因。
檢查系統的配置和參數設定。審查相關的配置檔(如/etc/sysctl.conf、/etc/security/limits.conf)和參數設定,確保系統的設定與實際需求相匹配,並進行適當的調整。
綜合上述步驟,可以幫助你定位系統負載過高的原因和瓶頸,並進一步采取相應的措施來最佳化系統效能。
4、Linux怎麽找出占用負載top5的行程及主要瓶頸在哪個資源(CPU or 內容 or 磁盤 IO)?
@zhaoxiaoyong081 平安科技 資深工程師:
CPU 使用排名
ps aux --sort=-%cpu | head -n 5
記憶體 使用排名
ps aux --sort=-%mem | head -n 6
IO 使用排名
iotop -oP
@zwz99999 dcits 系統工程師:
檢視最占用 CPU 的 10 個行程
#ps aux|grep -v USER|sort +2|tail -n 10
檢視最占用記憶體的 10 個行程
#ps aux|grep -v USER|sort +3|tail -n 10
io
iostat 1 10看哪個磁盤busy高
5、Linux的記憶體計算不準如何解決?
@Acdante
HZTYYJ
技術總監:
free是執行時間的瞬時計數,/proc/memory記憶體是即時變化的。
而且free會把緩存和緩沖區記憶體都計入使用記憶體,所以會導致看到的可用記憶體少很多。
準確值的話,建議結合多種監控指標和命令手段去持續觀測記憶體情況。
如:htop 、 nmon 、 syssta、top等,可以結合運維軟體和平台,而非站在某個時間點,最好是有一定時間的效能數據積累,從整體趨勢和具體問題點位去分析。
記憶體只是一個資源指標,使用記憶體的呼叫才是問題根源。
@zhaoxiaoyong081 平安科技 資深工程師:
在一些情況下,透過ps或top命令檢視的記憶體使用累計值與free命令或/proc/meminfo檔中的記憶體統計值之間可能存在較大差異。這可以由以下原因導致:
緩存和緩沖區:Linux系統使用緩存和緩沖區來提高檔案系統效能。這些緩存和緩沖區占用的記憶體會被標記為"cached"(緩存)和"buffers"(緩沖區)型別。然而,這些記憶體並不一定是實際被行程使用的記憶體,而是被內核保留用於提高IO效能。因此,ps或top命令顯示的記憶體使用累計值可能包括了這些緩存和緩沖區,而free命令或/proc/meminfo中的統計值通常不包括它們。
共享記憶體:共享記憶體是一種特殊的記憶體區域,多個行程可以存取和共享它。ps或top命令顯示的記憶體使用累計值可能會包括共享記憶體的大小,而free命令或/proc/meminfo中的統計值通常不會將其計算在內。
記憶體回收:Linux系統具有記憶體回收機制,可以在需要時回收未使用的記憶體。這意味著一些行程釋放的記憶體可能不會立即反映在ps或top命令顯示的記憶體使用累計值中。相比之下,free命令或/proc/meminfo中的統計值通常更及時地反映實際的記憶體使用情況。
綜上所述,ps或top命令顯示的記憶體使用累計值和free命令或/proc/meminfo中的記憶體統計值之間的差異通常是由於緩存和緩沖區、共享記憶體以及記憶體回收等因素造成的。如果你需要更準確地了解行程實際使用的記憶體,建議參考free命令或/proc/meminfo中的統計值,並結合其他工具和方法進行綜合分析
@wenwen123 計畫經理:
在Linux中,可能會出現記憶體計算不準確的情況,導致ps、top命令中的記憶體使用累計值與free命令或/proc/meminfo中的記憶體統計值之間存在較大差異。這種差異可能由以下原因導致:
共享記憶體:共享記憶體是多個行程之間共享的一塊記憶體區域,用於行程間通訊。共享記憶體不會被ps、top等工具計算在記憶體使用量中,因為它們只統計行程的私有記憶體使用量。因此,如果行程使用了大量的共享記憶體,它的記憶體使用量在工具中顯示的數值可能較低。
緩存和緩沖區:Linux系統會將一部份記憶體用於緩存和緩沖區,以提高檔案系統和IO操作的效能。這些緩存和緩沖區的記憶體在ps、top等工具中被視為可回收的,因此它們通常不計入行程的記憶體使用量中。但是,在free命令或/proc/meminfo中,這些緩存和緩沖區的記憶體會被納入統計。
記憶體回收機制:Linux內核具有記憶體回收機制,根據需要自動回收和分配記憶體。這可能導致在ps、top等工具顯示的記憶體使用量和free命令或/proc/meminfo中的統計值之間存在差異。這種差異通常是正常的,並且Linux會動態管理記憶體以滿足系統的需求。
針對記憶體計算不準確的問題,關註共享記憶體是合理的。共享記憶體的使用可能對行程的記憶體使用量造成影響,但不會被ps、top等工具計算在記憶體使用量中。如果需要更準確地了解行程的記憶體使用情況,可以使用專門的工具,如pmap、smem等,這些工具可以提供更詳細和準確的記憶體統計資訊。
需要註意的是,Linux記憶體計算的準確性也取決於內核版本、系統設定和使用的工具等因素。在排查記憶體計算不準確的問題時,建議使用多個工具進行對比,並結合具體場景和需求進行分析和判斷。
6、 Swap現在的套用場景還有哪些?
@zhaoxiaoyong081 平安科技 資深工程師:
雖然現代電腦的記憶體容量越來越大,但交換分區(swap)仍然在某些場景下具有重要的套用。以下是一些使用交換分區的常見場景:
記憶體不足:交換分區作為記憶體不足時的後備機制,用於將不經常使用或暫時不需要的記憶體頁面轉移到磁盤上。當實體記憶體(RAM)不足以容納所有活動行程和數據時,交換分區可以提供額外的虛擬記憶體空間,以避免系統發生記憶體耗盡錯誤(Out of Memory)。
休眠/睡眠模式:交換分區在某些作業系統中用於支持休眠(hibernation)或睡眠(suspend)模式。當電腦進入休眠或睡眠狀態時,系統的記憶體狀態會被保存到交換分區中,以便在喚醒時恢復到先前的狀態。
虛擬化環境:在虛擬化環境中,交換分區可以用於虛擬機器的記憶體管理。當宿主機的實體記憶體不足時,虛擬機器的記憶體頁面可以被交換到宿主機的交換分區,以提供額外的記憶體空間。
記憶體回收和頁面置換:交換分區可以用於記憶體回收和頁面置換演算法。當作業系統需要釋放實體記憶體以滿足更緊急的需求時,它可以將不活動的記憶體頁面置換到交換分區中,以便將實體記憶體分配給更重要的任務或行程。
盡管交換分區在上述場景中發揮作用,但需要註意的是,過度依賴交換分區可能會導致效能下降。頻繁的交換操作可能會增加I/O負載,並導致響應時間延遲。因此,在現代系統中,通常建議合理配置實體記憶體,以盡量減少對交換分區的依賴,並保持足夠的記憶體可用性。
7、在Linux tcp方面有什麽調優經驗或案例?
@zhanxuechao 數位研究院 咨詢專家:
centos7-os-init.sh




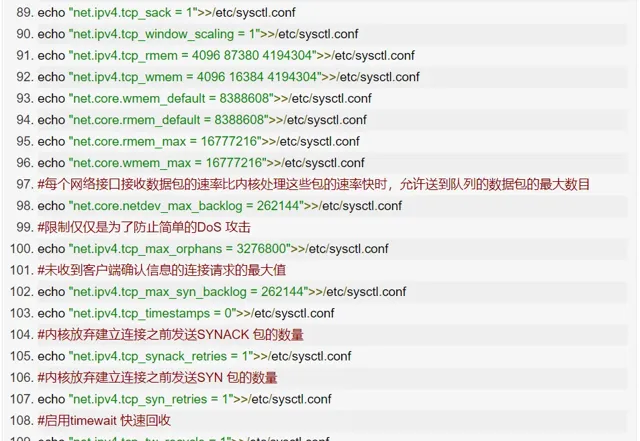



@zhaoxiaoyong081 平安科技 資深工程師:
TCP 最佳化,分三類情況詳細說明:
第一類,在請求數比較大的場景下,你可能會看到大量處於 TIME_WAIT 狀態的連線,它們會占用大量記憶體和埠資源。這時,我們可以最佳化與 TIME_WAIT 狀態相關的內核選項,比如采取下面幾種措施。
增大處於 TIME_WAIT 狀態的連線數量 net.ipv4.tcp_max_tw_buckets ,並增大連線跟蹤表的大小 net.netfilter.nf_conntrack_max。
減小 net.ipv4.tcp_fin_timeout 和 net.netfilter.nf_conntrack_tcp_timeout_time_wait ,讓系統盡快釋放它們所占用的資源。
開啟埠復用 net.ipv4.tcp_tw_reuse。這樣,被 TIME_WAIT 狀態占用的埠,還能用到新建的連線中。
增大本地埠的範圍 net.ipv4.ip_local_port_range 。這樣就可以支持更多連線,提高整體的並行能力。
增加最大檔描述符的數量。你可以使用 fs.nr_open 和 fs.file-max ,分別增大行程和系統的最大檔描述符數;或在應用程式的 systemd 配置檔中,配置 LimitNOFILE ,設定應用程式的最大檔描述符數。
第二類,為了緩解 SYN FLOOD 等,利用 TCP 協定特點進行攻擊而引發的效能問題,你可以考慮最佳化與 SYN 狀態相關的內核選項,比如采取下面幾種措施。
增大 TCP 半連線的最大數量 net.ipv4.tcp_max_syn_backlog ,或者開啟 TCP SYN Cookies net.ipv4.tcp_syncookies ,來繞開半連線數量限制的問題(註意,這兩個選項不可同時使用)。
減少 SYN_RECV 狀態的連線重傳 SYN+ACK 包的次數 net.ipv4.tcp_synack_retries。
第三類,在長連線的場景中,通常使用 Keepalive 來檢測 TCP 連線的狀態,以便對端連線斷開後,可以自動回收。但是,系統預設的 Keepalive 探測間隔和重試次數,一般都無法滿足應用程式的效能要求。所以,這時候你需要最佳化與 Keepalive 相關的內核選項,比如:
縮短最後一次封包到 Keepalive 探測包的間隔時間 net.ipv4.tcp_keepalive_time;
縮短發送 Keepalive 探測包的間隔時間 net.ipv4.tcp_keepalive_intvl;
減少 Keepalive 探測失敗後,一直到通知應用程式前的重試次數 net.ipv4.tcp_keepalive_probes。
總結
企業linux 效能最佳化從來不是一件容易的事,對於運維工程師來說是繞不過去的坎,這也是運維知識體系中最底層並且最難的一部份。想要學習好效能分析和最佳化,需要建立整體系統效能的全域觀,需要理解CPU、記憶體、磁盤、網路的原理,掌握需要收集哪些監控的指標,以及熟練使用各種工具來分析和追蹤以及定位問題。
<END>
點這裏👇關註我,記得標星呀~
感謝你的分享,點贊,在看三連











