導語 透過例項來深入理解 C++ 物件的記憶體布局,包括基礎數據類、帶方法的類、私有成員、靜態成員、類繼承等。透過 GDB 檢視物件的記憶體布局,探討成員變量、成員方法、虛擬函式表等在記憶體中的儲存位置和實作細節, 本篇文章試著從實際的例子出發,幫助大家對 C++ 類成員變量和函式在記憶體布局有個直觀的理解。
一、簡單物件記憶體分布
首先以一個最簡單的 Basic 類為例,來看看只含有基本數據型別的物件是怎麽分配記憶體的。
#include <iostream>using namespace std; class Basic {public: int a; double b;};int main() { Basic temp; temp.a = 10; return 0;}
編譯執行後,可以用 GDB 來檢視物件的記憶體分布。如下圖:

物件 temp 的起始地址是
0x7fffffffe3b0
,這是整個物件在記憶體中的位置。成員變量a的地址也是
0x7fffffffe3b0
,
表明int a是物件temp中的第一個成員,位於物件的起始位置。成員變量b的型別為double,其地址是
0x7fffffffe3b8
(a的地址+8),記憶體布局如下圖:

這裏 int型別在當前平台上占用4個字節(可以用sizeof(int)驗證),而這裏double成員的起始地址與int成員的起始地址之間相差8個字節,說明在a之後存在 記憶體對齊填充 (具體取決於編譯器的實作細節和平台的對齊要求)。記憶體對齊要求數據的起始地址在某個特定大小(比如 4、8)的倍數上,這樣可以 最佳化硬體和作業系統存取記憶體的效率 。這是因為許多處理器 存取對齊的記憶體地址比存取非對齊地址更快 。
另外在不進行記憶體對齊的情況下,較大的數據結構可能會跨越多個緩存行或記憶體頁邊界,這會導致額外的緩存行或頁的載入,降低記憶體存取效率。不過大多時候我們不需要手動管理記憶體對齊,編譯器和作業系統會自動處理這些問題。
二、帶方法的物件記憶體分布
帶有方法的類又是什麽樣呢?接著上面的例子,在類中增加一個方法 setB,用來設定其中成員 b 的值。
#include <iostream> class Basic {public: int a; double b; void setB(double value) { b = value; // 直接存取成員變量b }};int main() { Basic temp; temp.a = 10; temp.setB(3.14); return 0;}
用 GDB 打印 temp 物件以及成員變量的地址,發現記憶體布局和前面不帶方法的完全一樣。整個物件 size 依然是 16,a 和 b 的記憶體地址分布也是一致的。那麽 新增加的成員方法儲存在什麽位置? 成員方法中又是 如何拿到成員變量的地址呢?
成員方法記憶體布局
可以在 GDB 裏面打印下成員方法的地址,如下圖所示:
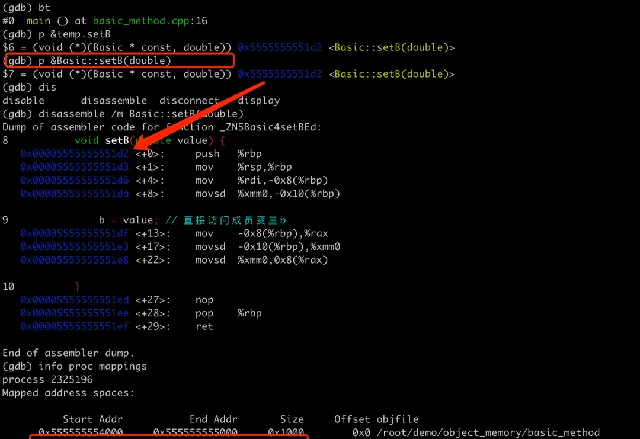
回憶下 Linux 中行程的記憶體布局,其中
文本段(也叫程式碼段)是儲存程式執行程式碼的記憶體區域
,通常是唯讀的,以防止程式在執行時意外或惡意修改其執行程式碼。這裏 setB 方法地址
0x5555555551d2
就是位於程式的文本段內,可以在 GDB 中用
info target
驗證一下:
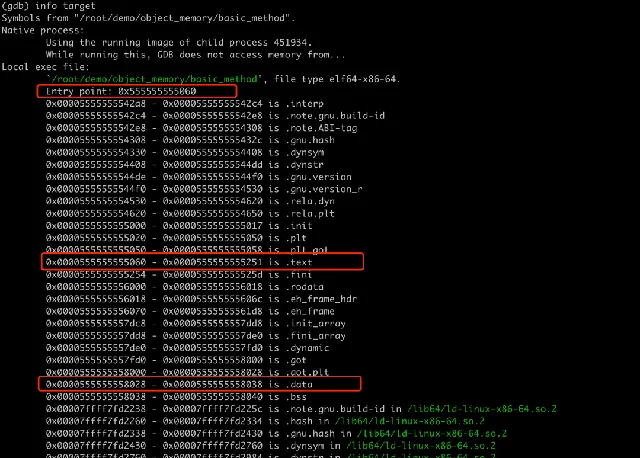
其中 .text 段的地址範圍是
0x0000555555555060 - 0x0000555555555251
,setB 剛好在這個範圍內。至此前面第一個問題有了答案,成員方法儲存在行程的文本段,添加
成員方法不會改變類例項物件的記憶體布局大小,它們也不占用物件例項的記憶體空間。
成員變量尋址
那麽成員方法中又是如何拿到成員變量的地址呢?在解決這個疑問前,先來仔細看下 setB 的函式原型
(void (*)(Basic * const, double))
,這裏函式的第一個參數是
Basic*
指標,而在程式碼中的呼叫是這樣:
temp.setB(3.14)
。這種用法其實是一種語法糖,
編譯器在呼叫成員函式時自動將當前物件的地址作為this指標傳遞給了函式的
。
(gdb) p &Basic::setB(double)$7 = (void (*)(Basic * const, double)) 0x5555555551d2 <Basic::setB(double)>
這裏參數傳遞了物件的地址,但是在函式裏面是怎麽拿到成員變量 b 的地址呢? 我們在呼叫 setB 的地方打斷點,執行到斷點後,用 step 進入到函式,然後檢視相應寄存器的值和組譯程式碼。整個過程如下圖:
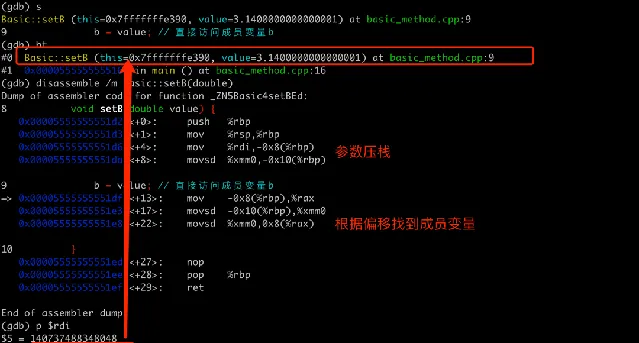
這裏的組譯程式碼 展示了如何透過 this指標和偏移量存取b 。可以分為兩部份,第一部份是處理 this 指標和參數,第二部份是找到成員 b 的記憶體位置然後進行賦值。
參數傳遞部份
。這裏
mov %rdi,-0x8(%rbp)
將 this 指標(透過rdi寄存器傳入)保存到棧上。將 double 型別的參數value 透過xmm0寄存器傳入保存到棧上。這是 x86_64 機器下 GCC 編譯器的傳參規定,我們可以透過打印
$rdi
保存的地址來驗證確實是 temp 物件的開始地址。
物件賦值部份
。
mov -0x8(%rbp),%rax
將this指標從棧上載入到 rax 寄存器中。類似的,
movsd -0x10(%rbp),%xmm0
將參數value從棧上重新載入到xmm0寄存器中。
movsd %xmm0,0x8(%rax)
將value寫入到this物件的 b 成員。這裏
0x8(%rax)
表示rax(即this指標)
加上8字節的偏移,這個偏移正是成員變量b在Basic物件中的位置
。
這個偏移是什麽時候,怎麽算出來的呢?其實成員變量的地址相對於物件地址是固定的,物件的地址加上成員變量在物件內的偏移量就是成員變量的實際地址。 編譯器在編譯時,基於類別定義中成員變量的聲明順序和編譯器的記憶體布局規則,計算每個成員變量相對於物件起始地址的偏移量。 然後在執行時,透過基地址(即物件的地址)加上偏移量,就能夠計算出每個成員變量的準確地址。這個過程對於程式設計師來說是透明的,由編譯器和執行時系統自動處理。
函式呼叫約定與最佳化
上面的組譯程式碼中,setB 的兩個參數,都是從寄存器先放到棧上,接著又從棧上放到寄存器進行操作, 為什麽要移來移去多此一舉呢 ?要回答這個問題,需要先了解函式的呼叫約定和寄存器使用。在x86_64架構的系統呼叫約定中,前幾個整數或指標參數通常透過寄存器(如rdi, rsi, rdx, 等)傳遞,而浮點參數透過 xmm0 到 xmm7 寄存器傳遞。這種約定目的是為了 提高函式呼叫的效率 ,因為使用寄存器傳遞參數比使用棧更快。
而將寄存器上的參數又移動到棧上,是為了 保證寄存器中的值不被覆蓋 。因為寄存器是有限的資源,在函式中可能會被多次用於不同的目的。將值保存到棧上可以讓函式內部自由地使用寄存器,而不必擔心覆蓋呼叫者的數據。
接著又將
-0x8(%rbp)
放到 rax 寄存器,然後再透過
movsd %xmm0,0x8(%rax)
寫入成員變量b的值,為啥不直接從
xmm0
寄存器寫到基於rbp的偏移地址呢?這是因為 x86_64 的指令集和其操作模式通常支持使用
寄存器間接尋址方式存取數據
。使用
rax
等通用寄存器作為中間步驟,是一種更通用和相容的方法。
當然上面編譯過程 沒有開啟編譯最佳化 ,所以編譯器采用了直接但效率不高的程式碼生成策略,包括將參數和局部變量頻繁地在棧與寄存器間移動。 而編譯器的最佳化策略可能會影響參數的處理方式 。如果我們開啟編譯最佳化,如下:
$ g++ basic_method.cpp -o basic_method_O2 -O2 -g -std=c++11
生成的 main 函式組譯部份如下:
(gdb) disassemble /m main=> 0x0000555555555060 <+0>: xor %eax,%eax 0x0000555555555062 <+2>: ret 0x0000555555555063: data16 nopw %cs:0x0(%rax,%rax,1) 0x000055555555506e: xchg %ax,%ax
在
O2
最佳化級別下,編譯器認定main函式中的所有操作(包括建立Basic物件和對其成員變量的賦值操作)對程式的最終結果沒有影響,因此它們都被最佳化掉了。這是編譯器的
「死程式碼消除」
,直接移除那些不影響程式輸出的程式碼部份。
三、特殊成員記憶體分布
上面的成員都是 public 的,如果是 private(私有) 變量,私有方法呢?另外,靜態成員變量或者靜態成員方法,在記憶體中又是怎麽布局呢?
私有成員
先來看私有成員,接著上面的例子,增加私有成員變量和方法。整體程式碼如下:
#include <iostream> class Basic {public: int a; double b; void setB(double value) { b = value; // 直接存取成員變量b secret(b); }private: int c; double d; void secret(int temp) { d = temp + c; }};int main() { Basic temp; temp.a = 10; temp.setB(3.14); return 0;}
編譯之後,透過 GDB,可以打印出所有成員變量的地址,發現這裏 私有變量的記憶體布局並沒有什麽特殊地方,也是依次順序儲存在物件 中。私有的方法也沒有特殊地方,一樣儲存在文本段。整體布局如下如:
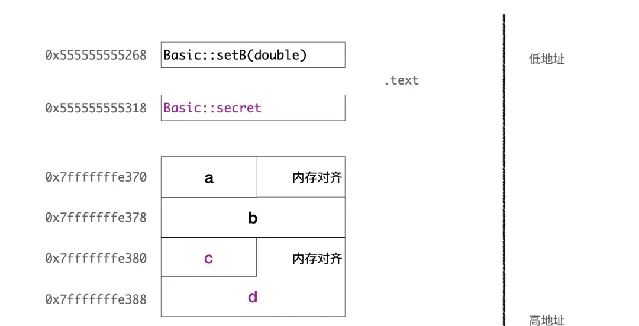
那麽 private 怎麽進行可見性控制的呢? 首先編譯期肯定是有保護的,這個很容易驗證,我們無法直接存取 temp.c ,或者呼叫 secret 方法,因為直接會編譯出錯。
那麽 執行期是否有保護呢? 我們來驗證下。前面已經驗證 private 成員變量也是根據偏移來找到記憶體位置的,我們可以在程式碼中直接根據偏移找到記憶體位置並更改裏面的值。
int* pC = reinterpret_cast<int*>(reinterpret_cast<char*>(&temp) + 16);*pC = 12; // 直接修改c的值
這裏修改後,可以增加一個show方法打印所有成員的值,發現這裏temp.c 確實被改為了 12。可見 成員變量在執行期並沒有做限制,知道地址就可以繞過編譯器的限制進行讀寫了。 那麽私有的方法呢?
私有方法和普通成員方法一樣儲存在文本段,我們拿到其地址後,可以透過這個地址呼叫嗎?這裏需要一些騷操作,我們 在類別定義中添加額外的介面來暴露私有成員方法的地址 ,然後透過成員函式指標來呼叫私有成員函式。整體程式碼如下 :
class Basic {...public: // 暴露私有成員方法的地址 static void (Basic::*getSecretPtr())(int) { return &Basic::secret; }...}int main() { // ... void (Basic::*funcPtr)(int) = Basic::getSecretPtr(); // 呼叫私有成員函式 (temp.*funcPtr)(10); // ...}
上面程式碼正常執行,你可以透過 print 打印呼叫前後成員變量的值來驗證。看來對於成員函式來說,只是編譯期不讓直接呼叫,執行期並沒有保護,我們可以繞過編譯限制在物件外部呼叫。
當然實際開發中, 千萬不要直接透過地址偏移來存取私有成員變量 ,也不要透過各種騷操作來存取私有成員方法,這樣不僅破壞了類的封裝性,而且是不安全的。
靜態成員
每個熟悉 c++ 類靜態成員的人都知道,靜態成員變量在類的所有例項之間共享, 不管你建立了多少個類的物件,靜態成員變量只有一份數據 。靜態成員變量的生命周期從它們被定義的時刻開始,直到程式結束。靜態成員方法不依賴於類的任何例項來執行,主要用在工廠方法、單例模式的例項獲取方法、或其他與類的特定例項無關的工具函式。
下面以一個具體的例子,來看看靜態成員變量和靜態成員方法的記憶體布局以及實作特點。繼續接著前面程式碼例子,這裏省略掉其他無關程式碼了。
#include <iostream> class Basic {// ...public: static float alias; static void show() { std::cout << alias << std::endl; }};float Basic::alias = 0.233;int main() { // ... temp.show(); return 0;}
簡單的打印 temp 和 alias 地址,發現兩者之間差異挺大。temp 地址是
0x7fffffffe380
,Basic::alias 是
0x555555558048
,用
info target
可以看到 alias 在程式的
.data
記憶體空間範圍
0x0000555555558038 - 0x000055555555804c
內。進一步驗證了下,
.data
段用於儲存已初始化的全域變量和靜態變量,註意這裏需要是非零初始值。
對於沒有初始化,或者初始化為零的全域變量或者靜態變量,是儲存在
.bss
段內的。這個也很好驗證,把上面 alias 的值設為0,重新檢視記憶體位置,就能看到確實在
.bss
段內了。對於全域變量或者靜態變量,
為啥需要分為這兩個段來儲存,而不是合並為一個段來儲存呢
?
這裏主要是考慮到
二進制檔磁盤空間大小以及載入效率
。在磁盤上,
.data
占用實際的磁盤空間,因為它
需要儲存具體的初始值數據
。
.bss
段不占用實際的儲存空間,只需要在程式載入時由作業系統分配並清零相應的記憶體即可,這樣可以減少可執行檔的大小。在程式啟動時,作業系統可以快速地為
.bss
段分配記憶體並將其初始化為零,而無需從磁盤讀取大量的零值數據,可以提高程式的載入速度。這裏詳細的解釋也可以參考 Why is the .bss segment required?。
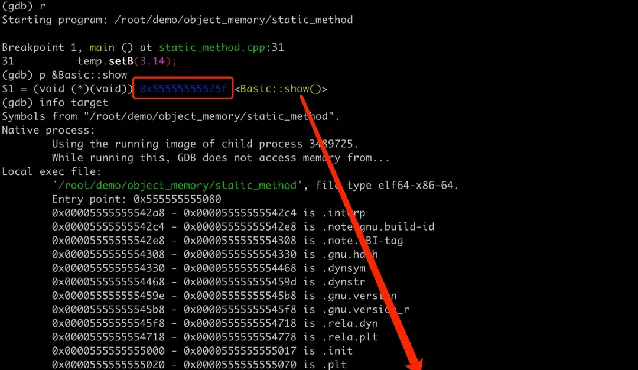
靜態方法又是怎麽實作呢?我們先輸出記憶體地址,發現在
.text
程式碼段,這點和其他成員方法是一樣的。不過和成員方法不同的是,第一個參數並不是 this 指標了。在實作上它與普通的全域函式類似,主要區別在於它們的作用域是限定在其所屬的類中。
四、類繼承的記憶體布局
當然,既然是在聊物件導向的類,那就少不了繼承了。我們還是從具體例子來看看,在繼承情況下,類的記憶體布局情況。
不帶虛擬函式的繼承
先來看看不帶虛擬函式的繼承,範例程式碼如下:
#include <iostream> class Basic {public: int a; double b; void setB(double value) { b = value; // 直接存取成員變量b }}; class Derived : public Basic {public: int c; void setC(int value) { c = value; // 直接存取成員變量c }};int main() { Derived temp; temp.a = 10; temp.setB(3.14); temp.c = 1; temp.setC(2); return 0;}
編譯執行後,用 GDB 打印成員變量的記憶體分布,發現
Derived
類的物件在記憶體中的布局首先包含其基礎類別
Basic
的所有成員變量,緊接著是 Derived 類自己的成員變量。整體布局如下圖:

其實 C++ 標準並沒有規定在繼承中,基礎類別和衍生類別的成員變量之間的排列順序,編譯器可以自由發揮的。但是大部份編譯器在實作中,都是基礎類別的成員變量在衍生類別的成員變量之前,為什麽這麽做呢?因為這樣實作, 使物件模型變得更簡單和直觀。不論是基礎類別還是衍生類別,物件的記憶體布局都是連續的,簡化了物件建立、復制和銷毀等操作的實作。 我們透過衍生類別物件存取基礎類別成員與直接使用基礎類別物件存取時完全一致,一個衍生類別物件的前半部份就是一個完整的基礎類別物件。
對於成員函式(包括普通函式和靜態函式),它們不占用物件例項的記憶體空間。不論是基礎類別的成員函式還是衍生類別的成員函式,它們都儲存在程式的程式碼段中(.text段)。
帶有虛擬函式的繼承
帶有虛擬函式的繼承,稍微有點復雜了。在前面繼承例子基礎上,增加一個虛擬函式,然後在 main 中用多型的方式呼叫。
#include <iostream> class Basic {public: int a; double b; virtual void printInfo() { std::cout << "Basic: a = " << a << ", b = " << b << std::endl; } virtual void printB() { std::cout << "Basic in B" << std::endl; } void setB(double value) { b = value; // 直接存取成員變量b }}; class Derived : public Basic {public: int c; void printInfo() override { std::cout << "Derived: a = " << a << ", b = " << b << ", c = " << c << std::endl; } void setC(int value) { c = value; // 直接存取成員變量c }};int main() { Derived derivedObj; derivedObj.a = 10; derivedObj.setB(3.14); derivedObj.c = 1; derivedObj.setC(2); Basic* ptr = &derivedObj; // 基礎類別指標指向衍生類別物件 ptr->printInfo(); // 多型呼叫 ptr->printB(); // 呼叫 Basic basicObj; basicObj.a = 10; basicObj.setB(3.14); Basic* anotherPtr = &basicObj; anotherPtr->printInfo(); anotherPtr->printB(); return 0;}
上面程式碼中,
Basic* ptr = &derivedObj;
這一行用一個基礎類別指標指向衍生類別物件,當透過基礎類別指標呼叫虛擬函式
ptr->printInfo();
時,將在執行時解析為
Derived::printInfo()
方法,這是就是執行時多型。對於
ptr->printB();
呼叫,由於衍生類別中沒有定義
printB()
方法,所以會呼叫基礎類別的
printB()
方法。
那麽在有虛擬函式繼承的情況下,物件的記憶體布局是什麽樣?虛擬函式的多型呼叫又是怎麽實作的呢?實踐出真知,我們可以透過 GDB 來檢視物件的記憶體布局,在此基礎上可以驗證虛擬函式表指標,虛擬函式表以及多型呼叫的實作細節。這裏先看下 Derived 類物件的記憶體布局,如下圖:
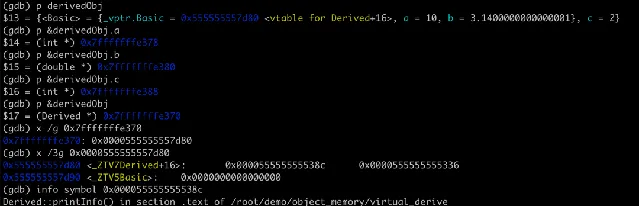
可以看到衍生類別物件的開始部份(地址
0x7fffffffe370
處)有一個 8 字節的虛擬函式表指標 vptr(指標地址
0x555555557d80
),這個指標指向一個虛擬函式表(vtable),虛擬函式表中儲存了虛擬函式的地址,一共有兩個地址
0x55555555538c
和
0x555555555336
,分別對應
Derived
類中的兩個虛擬函式
printInfo
和
printB
。基礎類別的情況類似,下面畫一個圖來描述更清晰些:
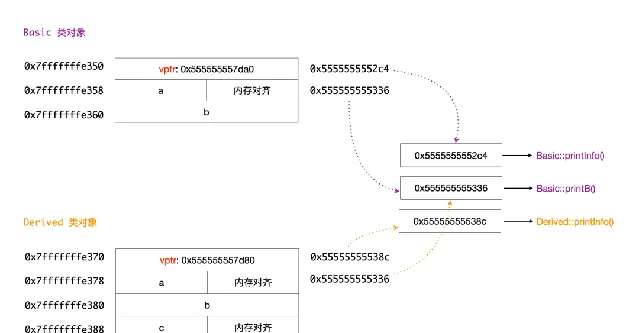
現在搞清楚了虛擬函式在類物件中的記憶體布局。在編譯器實作中, 虛擬函式表指標是每個物件例項的一部份,占用物件例項的記憶體空間。 對於一個例項物件, 透過其地址就能找到對應的虛擬函式表,然後透過虛擬函式表找到具體的虛擬函式地址,實作多型呼叫 。那麽為什麽 必須透過參照或者指標才能實作多型呼叫 呢?看下面 3 個呼叫,最後一個沒法多型呼叫。
Basic& ref = derivedObj; Basic* ptr = &derivedObj;Basic dup = derivedObj; // 沒法實作多型呼叫
我們用 GDB 來看下這三種物件的記憶體布局,如下圖:
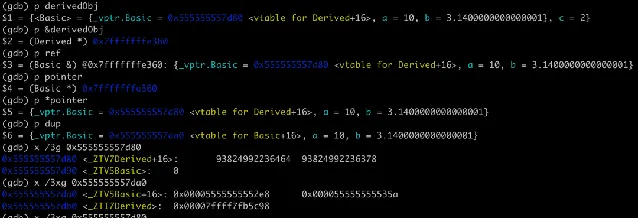
指標和參照在編譯器底層沒有區別,ref 和 ptr 的地址一樣,就是原來衍生類別 derivedObj 的地址
0x7fffffffe360
,裏面的虛擬函式表指標指向衍生類別的虛擬函式表,所以可以呼叫到衍生類別的 printInfo。而這裏的 dup 是透過拷貝建構函式生成的,編譯器執行了隱式型別轉換,從衍生類別截斷了基礎類別部份,生成了一個基礎類別物件。dup 中的虛擬函式表指標指向的是基礎類別的虛擬函式表,所以呼叫的是基礎類別的 printInfo。
從上面 dup 虛擬函式表指標的輸出也可以看到,虛擬函式表不用每個例項一份, 所有物件例項共享同一個虛擬函式表即可 。虛擬函式表是每個多型類一份,由編譯器在編譯時建立。
當然,這裏是 Mac 平台下 Clang 編譯器對於多型的實作。C++ 標準本身沒有規定多型的實作細節,沒有說一定要有虛擬函式表(vtable)和虛擬函式表指標(vptr)來實作。這是因為C++標準關註的是行為和語意,確保我們使用多型特性時能夠得到正確的行為,但它不規定底層的記憶體布局或具體的實作機制,這些細節通常由編譯器的實作來決定。
不同編譯器的實作也可能不一樣,許多編譯器為了存取效率, 將虛擬函式表指標放在物件記憶體布局的開始位置 。這樣,虛擬函式的呼叫可以快速定位到虛擬函式表,然後找到對應的函式指標。如果類有多重繼承,情況可能更復雜,某些編譯器可能會采取不同的策略來安排虛擬函式表指標的位置,或者一個物件可能有多個虛擬函式表指標。
五、地址空間布局隨機化
前面的例子中,如果用 GDB 多次運行程式,物件的 虛擬記憶體地址每次都一樣 ,這是為什麽呢?
我們知道現代作業系統中,每個執行的程式都使用 虛擬記憶體地址空間 ,透過作業系統的記憶體管理單元(MMU)對映到實體記憶體的。虛擬記憶體有很多優勢,包括 提高安全性、允許更靈活的記憶體管理等 。為了防止 緩沖區溢位攻擊 等安全漏洞,作業系統還會在每次程式啟動時 隨機化行程的地址空間布局 ,這就是地址空間布局隨機化(ASLR, Address Space Layout Randomization )。
在 Linux 作業系統上,可以透過
cat /proc/sys/kernel/randomize_va_space
檢視當前系統的 ASLR 是否啟用,基本上預設都是開啟狀態(值為 2),如果是 0,則是禁用狀態。
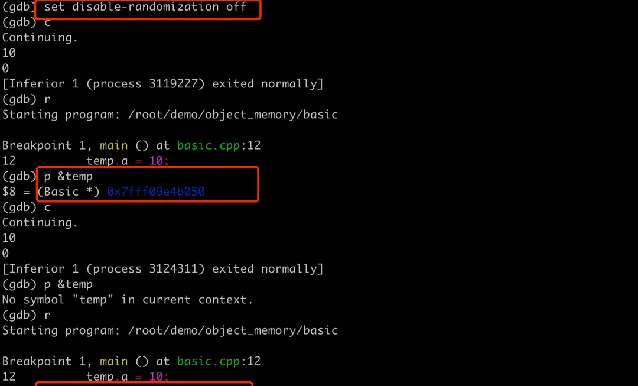
前面使用 GDB 進行偵錯時,之所以觀察到記憶體地址是固定不變的,這是因為 GDB 預設禁用了ASLR,以便於偵錯過程中更容易重現問題。可以在使用 GDB 時啟用 ASLR,從而讓偵錯環境更貼近實際執行環境。啟動 GDB 後,可以透過下面命令開啟地址空間的隨機化。
(gdb) set disable-randomization off
之後再多次執行,這裏的地址就會變化了。
六、總結
C++ 的物件模型是一個復雜的話題,涉及到類的記憶體布局、成員變量和成員函式的存取、繼承、多型等多個方面。本文從實際例子出發,幫助大家對 C++ 物件的記憶體布局有了一個直觀的認識。
簡單總結下本文的核心結論:
物件的記憶體布局是連續的,成員變量按照聲明的順序儲存在物件中,編譯器會根據類別定義計算每個成員變量相對於物件起始地址的偏移量。
成員方法儲存在行程的文本段,不占用物件例項的記憶體空間,透過 this 指標和偏移量存取成員變量。
私有成員變量和方法在執行期並沒有保護,可以透過地址偏移繞過編譯器的限制進行讀寫,但是不推薦這樣做。
靜態成員變量和靜態成員方法儲存在程式的數據段和程式碼段,不占用物件例項的記憶體空間。
繼承類的記憶體布局,編譯器一般會把基礎類別的成員變量放在衍生類別的成員變量之前,使物件模型變得更簡單和直觀。
帶有虛擬函式的繼承,物件的記憶體布局中包含虛擬函式表指標,多型呼叫透過虛擬函式表實作。虛擬函式實作比較復雜,這裏只考慮簡單的單繼承。
地址空間布局隨機化(ASLR)是現代作業系統的安全特性,可以有效防止緩沖區溢位攻擊等安全漏洞。GDB 預設禁用 ASLR,可以透過
set disable-randomization off命令開啟地址空間的隨機化。
當然本文也只是一個入門級的介紹,更深入的內容可以參考【深度探索 C++物件模型:Inside the C++ Object Model】這本書。
掃碼添加 「
鵝廠架構師小客服
」 ,加入【
鵝廠架構師圈
】,與技術愛好者、技術關註者分享交流,共同進步成長,歡迎大家!↓↓↓

關於我們
技術分享:關註微信公眾號 【鵝廠架構師】












