什麽是數據服務化
大數據開發的主要流程分為數據整合、數據開發、數據生產和數據回流四個階段。
數據整合打通了業務系統數據進入大數據環境的通道,通常包含周期性匯入離線表、即時采集並清洗匯入離線表和即時寫入對應資料來源三種方式,當前滴滴內部同步中心平台已經提供了MySQL、Oracle、MongoDB、Publiclog等多種資料來源的數據采集能力;
數據開發/生產,使用者可以構建即時、離線兩種資料倉儲,並基於SQL、Native、Shell等多種任務方式下的數據建模;
數據回流透過將離線數據匯入OLAP、RDBMS等,以提升存取效能,下遊服務直接存取該資料來源進行數據分析、數據視覺化。
滴滴內部的數據夢工廠,就是提供一站式數據開發、生產的解決方案,核心關註的是數據開發、生產環節中的效率、安全和穩定性。
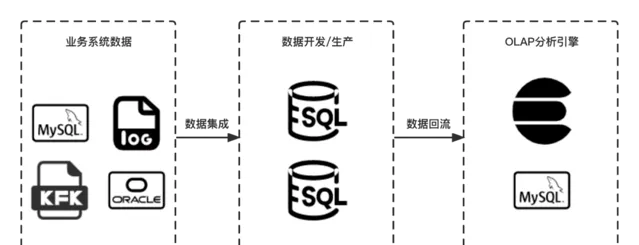
數據開發流程
為了體系地將數據交付使用者,我們構建的是一站式的數據消費平台,包含了數易、數據智慧問答機器人、異動分析等通用數據消費產品,和橫向沈澱的內容產品北極星、集團展廳。一站式消費平台需要透過查詢結構化、標準化的數據來提供視覺化、分析能力。
從數據消費產品的技術架構中,對查詢效能有一定要求,會根據查詢的方式回流到合適的多維分析儲存引擎,最為常見的是MySQL、ClickHouse、Druid和StarRocks。因此,對多維分析儲存引擎的查詢收口、擴充套件計算能力擴充套件、效能最佳化實施和查詢穩定性保障等,對於消費類數據產品來說都是公共、通用能力。
此外,對於其他個人化數據產品、營運平台、B端/C端產品來說,都是亟需的數據存取能力。這也是數據中台建設,對於數據存取能力統一化的核心問題:數據服務化能力。
對於該項能力建設,我們也不是一蹴而就的,主要分為三個階段。
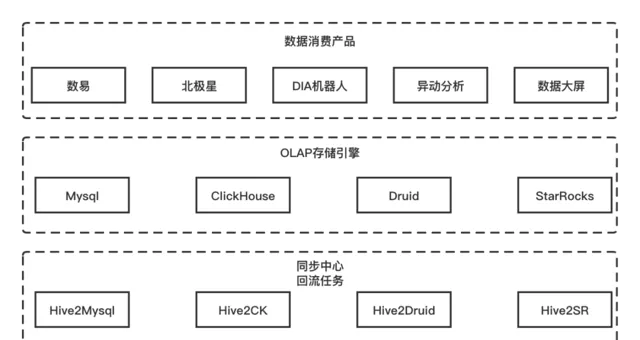
數據消費產品技術架構示意
階段一:建設同步中心數據回流能力
2019年滴滴發起了數據體系2.0建設,作為核心產出的數據夢工廠,其第一階段目標是建設一站式的數據開發、生產平台,關鍵節點以同步中心的一站式建設完畢為裏程碑。
同步中心透過自動化流程的建設,結束了透過提工單的方式,來人工構建資料來源間同步任務的歷史,其核心產出是數據進入Hive鏈路的自主管理能力建設。另外,我們新建了Hive回流到MySQL、ClickHouse、Druid、Hbase和ES鏈路,使得數據回流完成平台化建設。

基於數據回流實作的數據服務化能力,使得服務分、北極星和數易等相關場景得以系統化覆蓋。核心解決了業務直接存取大數據環境的效能問題,以數易為例,透過數據回流到ClickHouse,使數據查詢效能P90從5s下降到2s以內,這樣的效能提升使數易的使用者體驗有質的提升。這個階段的數據產品的基本架構,尤其是查詢側,類似於下圖所示,都抽象出來了數據回流和取數邏輯兩個模組。
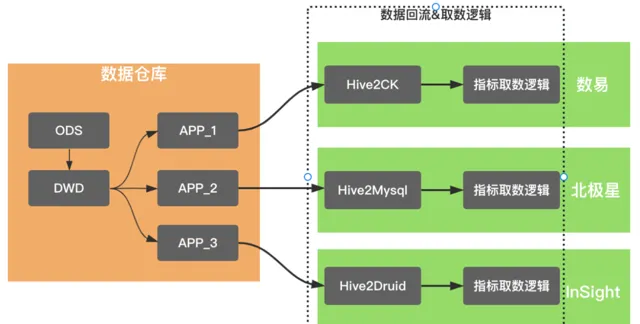
數據回流實作數據匯出到多維分析儲存引擎,並沈澱有任務的管理和運維能力,這些數據產品均深度打通了數據夢工廠,基於數據夢工廠強大的離線任務運維能力保障數據的產出。
取數邏輯維護著具體的查詢邏輯,除了北極星,其他兩款產品均衍生出了基於查詢抽象的中介軟體,例如InSight的QE(QueryEngine)、數易的查詢中心。數據回流和取數邏輯,是數據產品的核心能力,也是建設成本極高的模組。 所以,這個階段,類似於數據智慧問答機器人、數據門戶、復雜表格等產品,采用了基於數易數據集的查詢、加速能力,以快速驗證產品。
階段二:建設數鏈平台,統一數據服務化
階段一提供了數據回流線上儲存能力,提升了相關系統呼叫效能,為數據產品發展做出了階段性貢獻。隨著業務發展,數據表數量提升,取數邏輯隔離沈澱在不同系統問題凸顯出來,管理成本不斷提升。
為了提升取數效能,除了加速到多維分析儲存引擎之外,還需要對數據進行高度聚合,構建數據量較少的APP層。APP層表和業務需求有著強相關性,因此,需求的變化常常導致需要變更APP表支持業務。階段一中,取數邏輯場景散落在不同的系統內部,APP表變更將是比較大的工作量,包含了不同看板的資料來源切換,看板品質的再次驗收,過程十分繁雜。
數據回流和取數邏輯在不同的數據產品內進行重復建設,也增加了數據產品構建的效率。為了提升效率,內部產品基本都依賴數易數據集進行建設,例如數據智慧問答機器人、復雜表格。
但這不是最優的解決方案,問題主要體現在:
基於數易數據集,加速、限流、隔離等措施建設都非常復雜、龐雜。尤其,數易數據集加速方式分成一級的SQL任務加速、二級ClickHouse加速,形式固化。
數易的查詢都是基於MPP建設,對於相對高的並行查詢、點查很難支撐。
運維保障能力較弱,加速任務都由平台代持,使用者感知較弱,且無法運維。
數易數據集是數易的強依賴,剝離建設服務化能力難度較大,當時對於數易來說也不是第一優先級考慮的事情。
綜上所述,構建一個統一的數據服務化平台,有著較強的業務收益。從2021年初開始,數鏈平台應運而生,其基本思路在於對加速鏈路、查詢邏輯進行統一管理,並提供統一、完備的查詢閘道器。
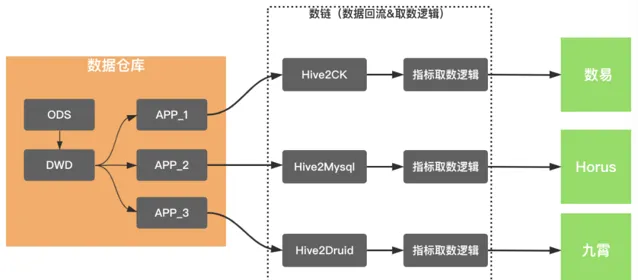
數鏈的基本能力在於:
多樣化的資料來源: 支持ES、MySQL、ClickHouse、Hbase、Druid等資料來源的存取;
多場景的數據存取:
支持key/value鍵值對的高並行查詢、支持復雜的多維分析和支持數據下載能力;
統一的接入標準:
統一的存取閘道器、統一數據存取協定、統一的數據運維和統一的API管理能力;
數據安全管控:
支持對敏感數據存取的審計,數據下載外發管控能力。
數鏈平台構建之後,數據API構建時間從天級別下降到分鐘級別,實作了白屏化API建設能力。當前,數鏈的API數量已經超過4000,周活API數量也超過了1600,服務了200多個套用,覆蓋了所有的業務線,達成既定建設目標。
階段三:建設數鏈標準指標服務化
透過階段二的平台建設,收益的數據產品主要是監控、看板、門戶、營運系統和安全相關系統。這些系統主要看中數鏈構建API的效率,API業務邏輯的管理能力和API的運維能力。但是,數易、北極星等早期建設,有相關能力閉環的產品,很難找到接入數鏈的突破口,或者說收益很難看到。
當前,大數據中指標交付,長期透過Hive表和沈澱在指標管理工具的指標描述來交付,也就是說,數倉會提供給業務方一張Hive表,和描述性的取值邏輯。業務方透過Hive表構建看板、臨時取數時,需要反復校驗取數邏輯,效率比較低下。同時,同一個指標常常在北極星、數易等產品展示,最為尷尬的是常常出現數值的不一致,也就是指標消費的一致性問題凸顯。
指標管理工具是根據指標管理方法論,構建的指標、維度後設資料管理系統。為了錄入指標、維度,數據團隊花費非常大的成本。指標管理工具僅僅提供指標錄入和檢索能力,指標規範性建設只能依賴於自上而下的管理,無法有效自運轉。對於指標一致性,只能是確保指標來自一個來源,並且交付方式不能是Hive表,而是指標本身,指標需要提供直接消費能力。
第二階段服務化建設的困境,北極星、數易指標消費的二義性問題,以及指標管理工具的本身困局,標準指標服務化建設應運而生。基本思路如圖所示,一個是指標管理工具提供模型管理,把指標和物理表進行關聯,另外,就是數鏈提供統一的消費閘道器,讓數易、北極星等數據產品打通這個消費渠道。
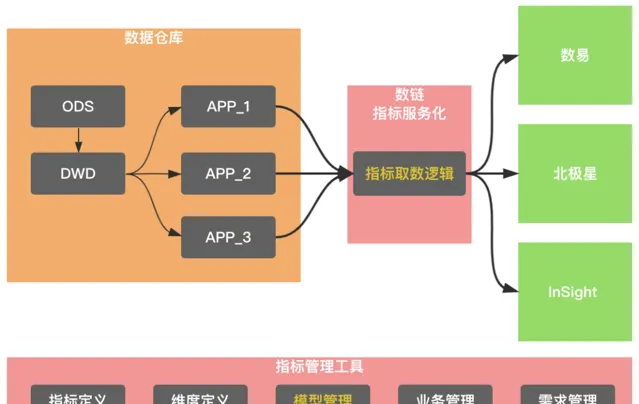
標準指標服務化建設,後設資料管理需要擴充套件指標、維度的表達能力,並透過邏輯模型去關聯指標、維度和具體物理表的具體欄位。為了簡化下遊消費邏輯,標準指標服務化需要提供一定的自動化取數邏輯能力。通常一個指標會在不同的物理表中實作,透過不同物理表間指標實作的一致性校驗,有效避免指標的二義性。
1.後設資料管理
標準指標服務化最為關鍵的後設資料:指標、維度和邏輯模型。下面依次進行介紹。
1)指標
指標管理方法論主要介紹為了提升指標表達語意能力,引入的計算指標和復合指標。衍生指標是指物理表(Hive/Starrocks/ClickHouse)開發後可以直接對外服務的指標,也就是一定物化在物理表上對應欄位的指標。計算指標是根據已註冊衍生指標計算生成的指標,可以不物化到物理表上對應欄位的指標,當前計算方式只支持加減乘除四則運算。
例如,應答後取消率=應答後取消訂單量/當日應答訂單量。復合指標是指已註冊衍生復合維度生成的指標,可以不物化到物理表上對應欄位的指標,例如,「網花出GMV」是根據指標「含openapi含掃碼付GMV」,復合維度「訂單聚合業務線」,維值為「網+出+花」生成的。如下圖所示,復合指標和計算指標可以相互巢狀,當前復合指標在巢狀鏈中最多只能出現一次。

2)緯度
緯度型別,當前構建了四種:
維表維度: 獨立的維表,維表會有唯一主鍵,以及其他內容資訊。維表維度可以構建數倉的星形模型。如果還有存在外來鍵,則可以構建多層維表依賴的雪花模型。例如,城市維表維度 whole_dw.dim_city。
列舉維度: key/value 鍵值對,鍵值對集中管理。例如:性別維度,對應的鍵值對男(M)/女(F)。
退化維度: 維度邏輯無法集中管理,在不同物理表有著不同的實作,但表示的是同一個維度。例如,北極星的業務線維度,不同板塊下的業務線id轉換到北極星的業務線id有著不一樣的轉換邏輯,需要在具體實作中確定。
衍生維度: 與退化維度不一樣的情況,維度邏輯可以集中化管理,該邏輯是一段處理程式碼。
3)邏輯模型
邏輯模型在不同地方有不同的解讀,指標管理工具中的邏輯模型是指標、維度和物理表繫結的載體。邏輯模型可以繫結衍生指標、計算指標、復合指標三種指標,也可以繫結維表維度、列舉維度、衍生維度和退化維度四種維度。繫結到邏輯模型的指標、維度,可以直接繫結到物理表的欄位,也可以繫結到根據物理表欄位構建的計算欄位。
計算指標、復合指標還能根據計算邏輯或者復合邏輯,非物化的繫結。邏輯模型可以繫結多個指標、多個維度,反過來,一個指標、維度可以繫結到多個邏輯模型中。更通俗的說,一個指標的多種實作方式,是透過邏輯模型指定的。
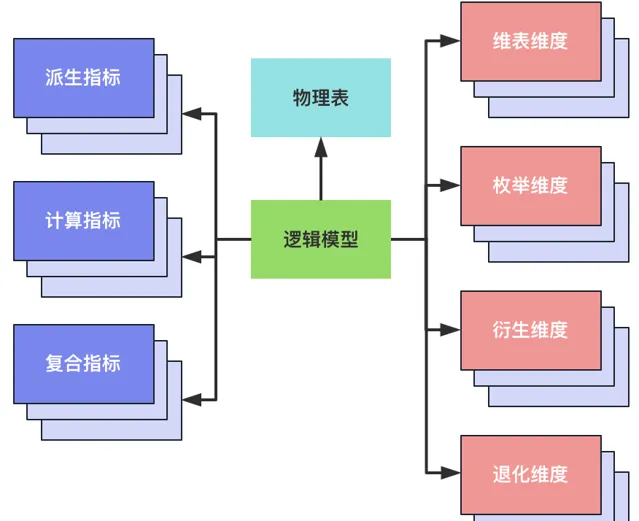
邏輯模型在指定物理表的時候,還對物理表的儲存引擎、物理表的數據布局、數倉層級進行了指定。當前數鏈支持Hive、SR、ClickHouse三種儲存引擎;數據布局支持一般APP表、Cube表和GroupingSets表;數倉層級支持APP、DM、DWS和DWD。
2.取數邏輯自動化
數鏈建設標準指標服務化中,取數邏輯自動化,一方面能實作集中管理(Single Source of Truth),另一方面也是提效過程。取數邏輯自動化,在標準指標服務化中主要體現在:
支持透過指標、維度取數 ,使用者只需要提供所需要的指標和維度,透過取數介面獲取數據。上面邏輯模型中提到,指標與邏輯模型是一對多關系。自動化的取數邏輯,會根據所需的指標、維度、分區範圍,以及效能最佳的取數方式去選擇合適的邏輯模型。需要重點指出的是,當計算指標依賴的衍生指標只能透過不同的模型獲取時,該取數過程支持透過聯邦查詢完成。
支持多種數據布局的表 ,當前已經支持一般APP表、Cube表和GroupingSets表。在取數中,已經遮蔽了不同數據布局的取數邏輯,使用者無需關心原先表的數據布局方式。
支持多樣的數倉建模模型 ,數倉建模規範產出中,可以是單例、星形和雪花模型。雪花和星形模型,自動化取數邏輯已經可以透過自動關聯所需的維表,實作維表維度中的不同維度內容上卷等復雜的取數邏輯。
支持日、周、月、季粒度的上卷 ,在之前不同時間粒度的數據,只能透過開發不同的表實作。在查詢效能有保障的情況下,現在可以實作時間粒度的上卷能力。

3.一致性校驗
除了透過取數邏輯自動化實作取數提效之外,指標一致性也是數鏈建設標準指標服務化的核心出發點。指標一致性,一方面是透過統一的消費介面,另一方面,則是根據指標的實際現狀,進行被動和自動的校驗。
被動指標校驗,由使用者在平台配置所需要的進行校驗的指標,如下圖所示,像「最近一天全集團GMV」一樣,可能在多個邏輯模型中實作。因此,校驗邏輯是在幾個邏輯模型產出後,進行一次周期性的校驗。還有一種情況則是,「最近一天全集團GMV」,可以透過「最近一天網約車GMV」+「最近一天兩輪車GMV」+「最近一天貨運GMV」實作。因此,如下圖所示,檢驗邏輯可以是左側的邏輯模型_1和右側的邏輯模型_1‘、邏輯模型_2’、邏輯模型_3‘產出後,進行一次周期性的校驗。
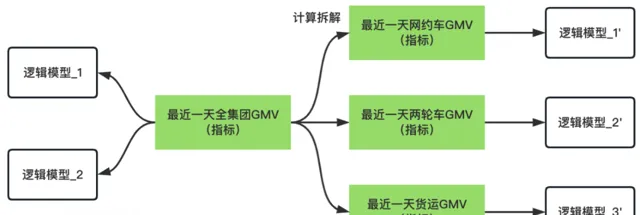
自動指標檢驗,檢驗的邏輯跟被動指標校驗的區別在於,模型拆解方式由系統自動生成,另外,可以進行校驗的指標也由系統篩選出來。
4.接入&查詢流程
當下接入數鏈標準指標服務化的服務有北極星、數易和InSight,這三個產品也是滴滴最核心的數據產品。標準指標服務化在打通這三個產品的時候,都具備不同的挑戰,具體會在其他同學分享的文章進行詳述。這裏只簡單介紹下數據產品接入、查詢的基本流程。
通常流程中,數據BP將會根據指標管理工具依次錄入指標、維度,數據開發同學依據不同的數據架構方式構建數倉,並建立邏輯模型,和指標、維度進行關聯繫結。管理好的後設資料,會被即時同步到數鏈。
數易、北極星、InSight透過後設資料介面,對報表、看板進行構建。發起數據查詢時,請求將發送到數鏈,並經過模型篩選、最佳化,生成最終的執行SQL,查詢的數據再返回數據產品側。

數據服務體系整體架構
數鏈平台旨在打造一站式規範、高效、穩定和安全的數據服務化平台。當前服務的業務場景主要分為本地數據服務化、離線數據服務化、特征服務化和標準指標服務化。數鏈平台分為閘道器層和引擎層。閘道器實作的是統一的入口,並提供了鑒權、限流、緩存、路由、監控等能力。引擎層將實作場景分成了key/value鍵值對場景、多維分析場景和標準指標服務化場景。
key/value鍵值對場景主要服務特征服務化,即牛盾、地圖特征等業務場景。多維分析場景,主要服務於本地數據服務化和離線數據服務化,即Horus、九霄等業務場景。key/value鍵值對場景、多維分析場景是階段二的核心能力,標準指標服務化場景則是階段三的核心能力。
為了支撐多樣、復雜的數據查詢訴求,我們還建設了統一的查詢中介軟體:DiQuery。DiQuery依托於MPP的強大查詢能力,構建了統一的查詢能力,服務於數鏈、數易等數據產品。DiQuery除了支持單表查詢能力之外,還支持了聯邦查詢、LOD復雜函式查詢能力。DiQuery支持同環比、四周均值等擴充套件函式,並支持在此基礎上的上卷能力。

總結與展望
滴滴數據服務體系的發展,經歷了原始的數據回流任務方式、統一數據服務化平台建設、標準指標服務化建設,一步步在建設更好的數據服務體系。標準指標服務化建設,是今年的重頭戲,在數倉研發、產品和平台研發的鼎力協作中高速發展。
現在的數據服務體系,解耦了數據生產和數據消費的關系。接下來,需要推進數據生產的標準化,進一步解決指標一致性問題,提升數倉建設效率,並透過指標視角提升數據品質等等。標準指標服務化,將是一場一步步推進的數據平台重要演化,並在業界已經慢慢拉開帷幕。
作者丨江國薦
來源丨公眾號:滴滴技術(ID:didi_tech)
dbaplus社群歡迎廣大技術人員投稿,投稿信箱: [email protected]












