經過社群開發者們幾個月的開發與貢獻,現正式釋出昇思MindSpore2.3.RC1版本,透過多維混合並列以及確定性CKPT來實作超大集群的高效能訓練,支持大模型訓推一體架構,大模型開發訓練推理更簡、更穩、更高效,並在訓推一體框架的基礎上透過多樣的大模型推理最佳化技術,進一步降低大模型推理成本;透過使能kernel by kernel排程執行,進一步提升靜態圖偵錯調優能力;持續升級昇思MindSpore TransFormers大模型套件和昇思MindSpore One生成式套件,全流程開箱即用,一周即可完成大模型全流程的開發、驗證;創新AI+科學計算(科學智慧)範式,孵化科學領域基礎大模型;下面就帶大家詳細了解下昇思MindSpore2.3.RC1版本的關鍵特性。
1.
大模型訓練:細粒度多副本並列,有效提升計算通訊並行度,顯著提升大模型訓練效能
大模型訓練下,為了降低視訊記憶體開銷,廣泛的使用算子級並列技術,其中引入了大量的模型並列的通訊,極大地影響了大模型的訓練效率。模型並列的通訊,從網路的結構上來看,其處於正反向計算過程中,阻塞正反向計算,無法與正反向的計算進行互相掩蓋。為了解決模型並列通訊的掩蓋問題,昇思MindSpore提出了多副本並列技術。
在舊版本的昇思 MindSpore 上,透過將網路從數據開始進行拆分,如下圖所示,在單張卡內,透過 Slice 算子將 Batch 維度進行拆分,進而產生多個分支,這多個分支的計算與通訊互相之間沒有依賴,存在並行的空間,透過執行序排程演算法,控制多個分支的計算與通訊進行並行。
隨著網路規模的增大,受限於視訊記憶體限制,當一張卡內的BatchSize僅支持為1時,上述對整網進行Batch拆分的方案不再可行。因此,考慮到模型並列通訊的位置,昇思MindSpore2.3.RC1版本將TransFormer模型中的AttentionProjection層以及FFN層進行拆分,產生多個分支,透過執行序排程演算法控制細粒度的多分支的並列,其中拆分從AttentionProjection開始,到下一個Layer的QKV計算前結束。
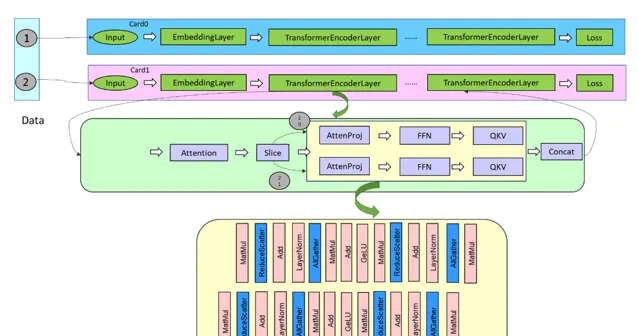
上圖描述了序列並列場景下的細粒度多副本拆分與掩蓋基本思路,拆分為兩個副本,在正向可以達成 50%+ 的通訊掩蓋;而在反向,結合計算梯度的分支的計算與 TP 通訊的掩蓋,可達成 90% 的通訊的掩蓋。當前細粒度多副本並列僅在昇思 MindSpore TransFormers 的 LLAMA 網路進行了實作,需要對模型結構進行手動改造為多個副本。後續版本昇思 MindSpore 將整合自動拆分副本的邏輯,達成更易用的細粒度多副本並列。
參考連結:https://www.mindspore.cn/tutorials/experts/zh-CN/master/parallel/multiple_copy.html
2.
大模型推理全棧升級
大模型大規模商用之後,推理消耗的算力規模將十分龐大,相應地帶來高昂的成本,商業閉環依賴推理規模突破。在降低大模型推理的成本的同時,要兼顧模型精度和計算時延,不能影響使用者的體驗。昇思MindSpore 2.3.RC1版本,從最上層推理服務到模型指令碼最佳化到推理引擎LLM Serving,為使用者提供端到端的高效推理解決方案。
2.1 訓推一體:大模型訓/推統一指令碼,大幅簡化部署流程,提高效率
模型指令碼預設使能了增量推理、FlashAttention/PagedAttention等推理加速技術,避免了模型匯出、切分、推理指令碼開發等一系列工作,訓練到推理加速平滑遷移,部署周期下降到天級。
2.2 極致效能:持續提升融合大算子、並列推理、模型小型化的關鍵能力
融合大算子: 新增10+業界最新的推理融合大算子介面,模型開發人員可以快速使能推理融合算子實作加速。
並列推理: 訓練推理並列策略介面一致,提供訓練並列到推理並列ckpt重切分介面,支持動態shape模型切分。
模型壓縮: 昇思MindSpore金箍棒升級到2.0版本,提供了針對大模型的業界SOTA以及華為諾亞自研的量化、減枝等演算法,實作千億大模型10倍+壓縮。
以上技術均可泛化的套用於 TransFormer 結構的大模型中,經過驗證,在盤古、 Llama 2 的 8 卡模型推理中,首 token 時延做到百 ms 級,平均 token 時延小於 50ms ,保持業界領先水平。
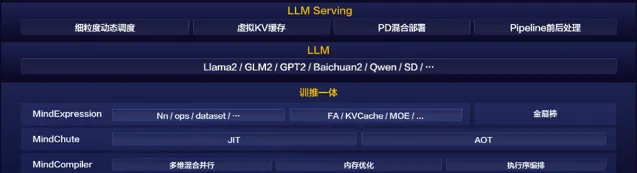
2.3 服務化高吞吐
透過連續批排程、Prefill/Decoding混合部署等手段,盡可能的消除掉冗余計算,確保算力不閑置,實作大模型推理吞吐提升2倍+。
參考連結:
https://www.mindspore.cn/lite/docs/zh-CN/r2.3.0rc1/use/cloud_infer/runtime_distributed_python.html
3.
靜態圖最佳化:支持O(n)多級編譯,使能kernel by kernel排程執行,提升靜態圖偵錯調優能力
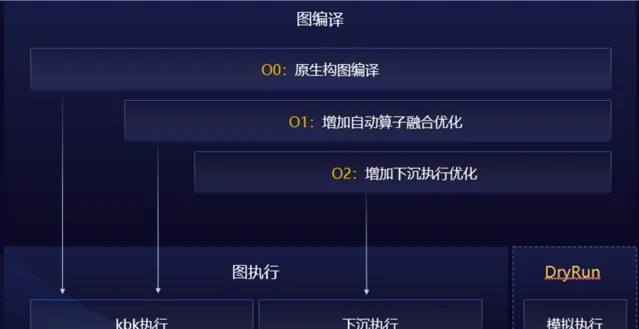
整圖下沈執行效能最優,但大模型的規模和參數量發展得更為龐大,整圖下沈執行方式在整圖編譯過程中耗時較長,一個千億級別的大模型的編譯時間為 30 分鐘 -60 分鐘,偵錯調優效率低下。為解決上述問題,昇思 MindSpore2.3.RC1 版本中,提供了多級編譯技術, O0 原生構圖不最佳化、 O1 增加自動算子融合最佳化、 O2 整圖下沈執行最佳化。
在 O0 的編譯選項下,透過原生圖編譯和 kernel by kernel ( KBK )的執行技術,可以將編譯時間提升到 15 分鐘以內,同時我們在新版本中還開發了 DryRun 技術,使用者可以直接在離線的情況進行記憶體瓶頸分析和並列策略調優,結合這兩大技術可以使得大模型偵錯效率倍增。
在 O0 這種編譯條件下,我們使能了 SOMAS/LazyInline/ 控制流 Inline 來提升記憶體復用率,使能了多流並列 / 流水異步排程,可以提升執行效能;在 O1 這種編譯條件下,透過使能算子融合技術, KBK 執行模式下可以有更好的執行效能。
參考連結:
https://www.mindspore.cn/docs/zh-CN/r2.3.0rc1/api_python/mindspore/mindspore.JitConfig.html?highlight=jitconfig
4.
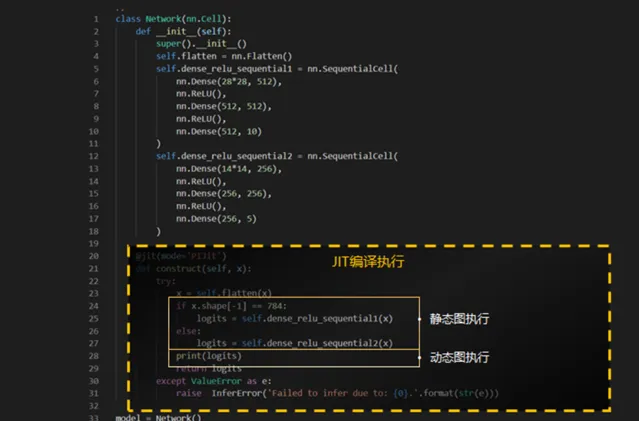
JIT兼具易用性和效能,動靜統一,提供靈活高效開發
昇思 MindSpore 支持圖模式(靜態圖)和 PyNative 模式(動態圖)兩種執行方法。動態圖易於偵錯,開發靈活,易用性好;靜態圖語法支持有限,但執行效能好。 JIT 兼顧效能和易用性,透過對 Python 字節碼進行分析 & 調整、執行流進行圖捕獲 & 圖最佳化,支持入圖的 Python 程式碼做靜態圖方式執行,不支持的進行子圖切分以動態圖方式執行,自動地做到動靜統一,實作方法如下圖所示 。
參考連結:
https://www.mindspore.cn/docs/zh-CN/r2.3/design/dynamic_graph_and_static_graph.html#动态图转静态图技术
5.
MindSpore Elec:新增大地電磁智慧反演模型
MindSpore Elec 電磁仿真套件升級至 0.3 版本,聯合清華大學李懋坤教授團隊、華為先進計算與儲存實驗室共同打造了基於昇思 MindSpore 的大地電磁( Magnetotelluric , MT )智慧反演模型。該模型透過變分自編碼器( VAE )靈活嵌入了多物理先驗知識,達到了業界 SOTA 。 該成果已被國際頂級勘探地球物理期刊【 Geophysics 】收錄,同時也在昇思人工智慧框架峰會 2024 上釋出亮相。
( 1 )基礎 MT 反演:反演區域水平長度為 10km ,深度為 1km 。下圖 1 中目標電阻率分布(第一列)與傳統大地電磁反演(第二列)、大地電磁智慧反演(第三列),可以看出大地電磁智慧反演相比傳統反演精度顯著提升(前者殘留誤差為 0.0056 和 0.0054 ;後者為 0.023 和 0.024 ) ;下圖 2 中,大地電磁智慧反演效能也優於傳統反演方法(前者收斂步數為 4 和 4 ;後者為 6 和 4 )。
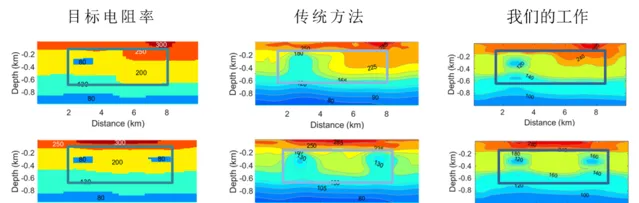
圖1 大地電磁反演精度對比

( 2 )南部非洲 MT 反演:大地電磁智慧反演模型也在南部非洲開源數據集( SAMTEX )上做了驗證。該反演區域位於南部非洲西海岸附近,長度約為 750km ,深度選定為 80km 。該測區顯著特征為在水平方向 100km 至 400km 之間,深度 20km 以淺的區域存在的高導結構 。由於低頻電磁波在導體結構中的衰減, MT 方法對高導結構下部區域的敏感度很低 , 因此無先驗知識約束的傳統 MT 反演難以準確重建高導地層的下邊界位置。大地電磁智慧反演對高導地層的下邊界重建較為清晰準確,較好地將地層厚度的先驗知識融入了反演。
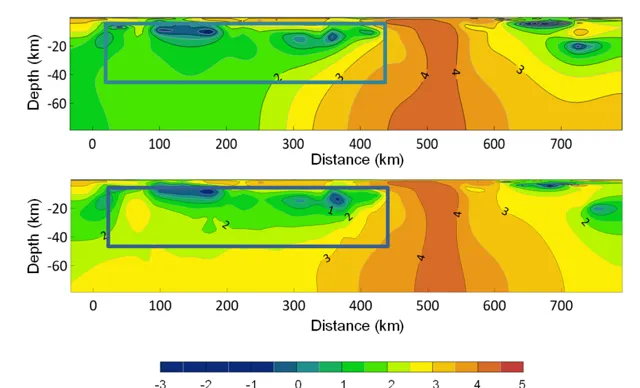
參考連結: https://gitee.com/mindspore/mindscience/tree/master/MindElec












