更多內容請參考「 」,從硬體特點分析如何進行效能調優,同時還介紹了計畫中效能調優的思路和常用 效能采集工具。 「 」 和「 」。
鯤鵬處理器為核心的華為TaiShan伺服器在國產伺服器中可以說是名列前茅的。不僅僅是其高效的處理效能,還有針對鯤鵬處理器進行深度最佳化的原生套用以及不斷壯大的共建鯤鵬社群。下面以鯤鵬處理器的軟硬體效能最佳化為例,深入理解更為底層的技術方案。
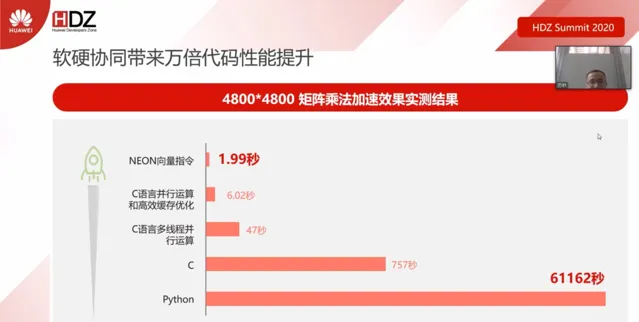
以一個4800*4800矩陣乘法為例闡述效能調優的重要性
為了實作4800*4800的矩陣乘法,我們有多種方式,例如可以使用python實作,可以使用C語言實作,進一步地,還可以使用C語言中的多執行緒並列運算來實作。當然,不同方式實作的方法在計算效能上也是不一樣的。使用python這樣的解釋性語言,其大概需要耗費61162秒;使用C語言大概需要耗費757秒;而將原始矩陣進行拆分,使用C語言的平行計算,則可以將計算時間縮短到47秒。如果單從實作方式上來看的話,這個47秒相較於61162秒已經是縮短了1300多倍了,但是如果我們在硬體設施層面進行有針對地最佳化,我們會發現另一個世界。在將C語言平行計算與高效緩存最佳化結合之後,該計算時間可節省至6.02秒。而如果使用鯤鵬的NEON向量指令進行計算最佳化,可縮短至1.99秒,這就是鯤鵬的極致效能最佳化。
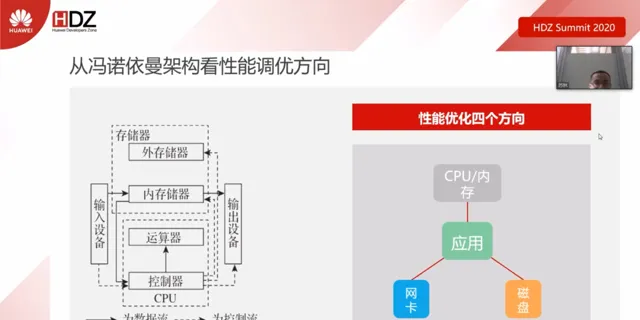
從馮諾依曼架構看效能調優
在馮諾依曼架構下,電腦可以抽象為記憶體、控制器、輸入以及輸出裝置。記憶體分為記憶體和外部記憶體,程式在未執行時儲存在外部記憶體中,而在執行時則是載入到記憶體中進行各種運算和處理。簡單地,我們可以將電腦調優抽象為四個部份,分別為:CPU/記憶體、網卡、磁盤、套用。
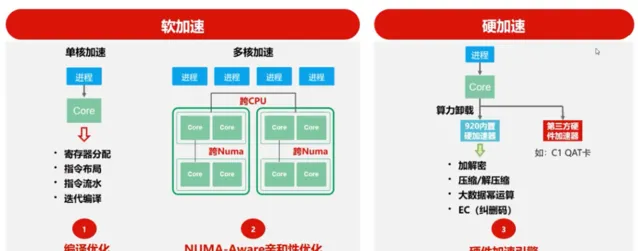
基於鯤鵬處理器的軟硬加速能力概覽
鯤鵬處理器可針對套用實作軟加速和硬加速。其中,軟加速包括單核加速和多核加速;硬加速則包括芯片級別的加速引擎。

從編譯器和JDK的最佳化看鯤鵬的單核軟加速能力
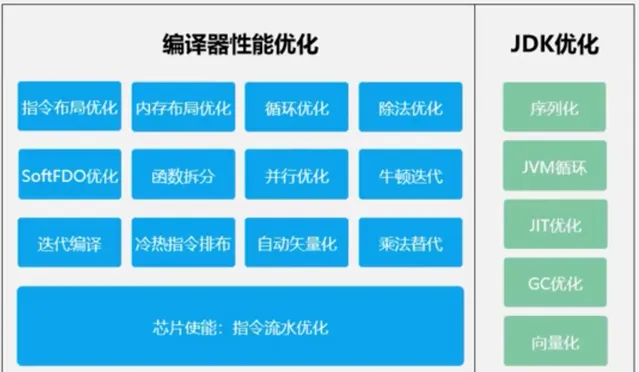
當前市面上常見的CPU架構是多流水線架構,其CPU指令是並行執行的。在這種情況下,某兩條執行流水線存在相互依賴關系,那麽一條流水線出現阻塞,另一條流水線則也有可能出現阻塞。針對上述問題,華為編譯器進行了多種最佳化,其中包括:
指令布局最佳化:拆分函式程式碼,按照冷熱指令重新排序,提升指令Cache命中率
記憶體布局最佳化:按照記憶體數據存取頻度,組合熱數據區域,提升數據Cache命中率
迴圈最佳化:分析迴圈叠代間數據訪存依賴關系,對無依賴的迴圈並列到多核執行,無依賴的數據自動向量化計算,加速程式執行。
對於Java開發者來說,JDK是再熟悉不過了。華為針對鯤鵬伺服器推出的畢昇JDK也進行了如下最佳化:
JIT編譯最佳化,GC記憶體回收管理最佳化提升記憶體管理效能
JVM迴圈、向量化、序列化技術,提升程式執行效能
基於NUMA的多核效能最佳化
2006年之後,CPU開始邁進多核的時代,剛開始的時候核數還比較少,采用的是SMP(對稱多處理器)架構。在第一代CPU架構下,多核心可在系統層面做均衡排程,也就是多個核心都可以存取所有記憶體區域,具體如下圖所示:
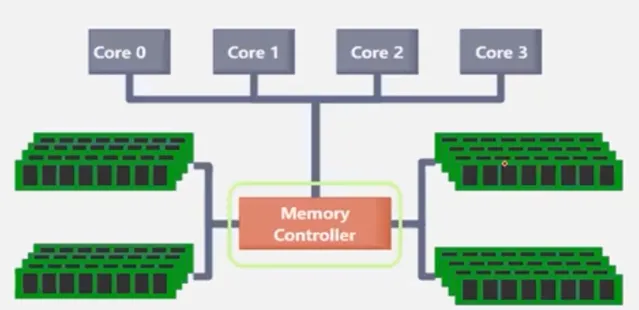
由上圖我們也發現了一個問題,CPU核心在存取記憶體區域時,都是透過單一的記憶體控制器去做的控制。顯然,當核心數多了之後,單一控制器必然制約CPU的效能。
那麽針對上述問題,NUMA架構便應運而生,其架構如下圖所示:
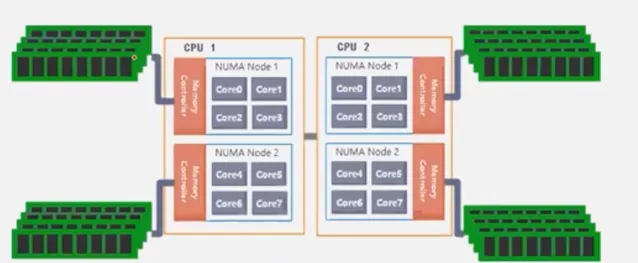
在NUMA架構下,將多核分為不同的NUMA節點,各個節點有自己的記憶體控制器。CPU核心透過NUMA節點內的記憶體控制器存取屬於該節點的記憶體區域,當然也可以透過匯流排存取其他NUMA節點的記憶體區域。在這種情況下,隨著核數增多,記憶體控制器也隨之增多,從而很好解決記憶體存取瓶頸問題。
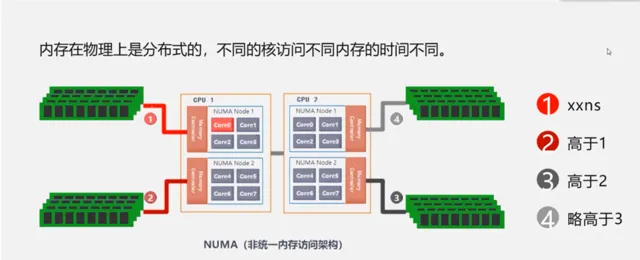
然而,從上圖我們也會發現NUMA架構的一個問題,由於記憶體在物理上是分布式的,不同的核心存取不同記憶體的時間是不同的。如果核心存取的是最近的記憶體,那麽其效率必然是最高的,如下圖所示,Core0存取記憶體區域1的成本是低於記憶體區域2、3、4的。
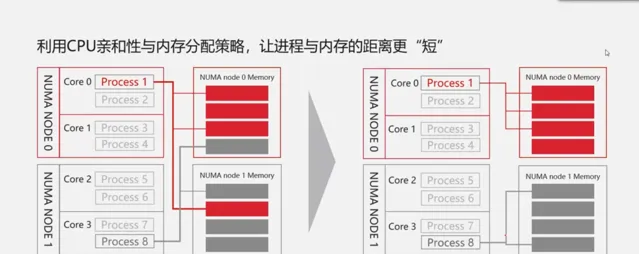
當然,鯤鵬處理器也完成了記憶體存取最短路徑的方法。利用NUMA-Aware親和性資源規劃實作行程與記憶體之間的距離更短,具體如圖所示。
以Nginx為例展示NUMA的最佳化效果
NGINX 是用於 Web 服務、反向代理、緩存、負載平衡、媒體流等的開源軟體。它最初是為實作最高效能和穩定性而設計的 Web 伺服器。除了 HTTP 伺服器功能,NGINX 還可以用作電子信件(IMAP、POP3 和 SMTP)的代理伺服器以及 HTTP、TCP 和 UDP 伺服器的反向代理和負載平衡器。
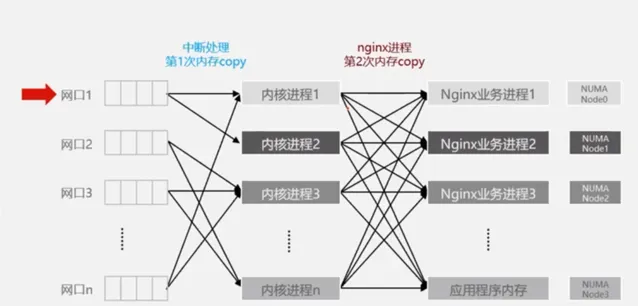
從數據傳輸角度來說,數據到達業務行程中需要進行兩次拷貝,第一次是透過網口拷貝到內核行程,第二次是將內核行程中的的數據再拷貝的業務行程中,由上圖可見,兩階段的數據拷貝是離散的。而在NUMA最佳化情況下,可將網口、內核行程以及Nginx業務行程進行繫結。經實驗驗證,經過最佳化的Nginx端到端的時延可以有15%左右的提升。
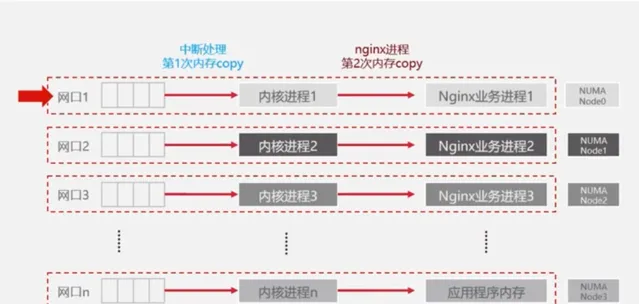
具體來說,可透過如下三種方式實作NUMA綁核配置方法:
使用系統工具numactl設定:numactl -C 0-15 process name -C: Core scope
在程式碼中呼叫親和性設定參數:int sched_setaffinity(pid_t pid, size_t cpusetsize, cpu_set_t*mask)
多數開源軟體中提供了配置介面:nginx中可在其配置檔nginx.conf中調整worker_cpu_affinity參數
基於鯤鵬技術優勢構建加速庫
除了上述描述的軟加速能力之外,鯤鵬還提供了硬加速能力,針對基礎加速、壓縮加速、加解密加速、多媒體加速四類業務提供了9大加速庫,典型場景達到了10%-100#的效能提升,具體如下圖所示。

以OpenSSL和壓縮演算法為例介紹加速庫實作原理
如下圖所示,當Web呼叫OpenSSL時,在不修改程式碼的情況下,透過路徑2載入硬體加速庫將計算解除安裝到芯片中做計算。
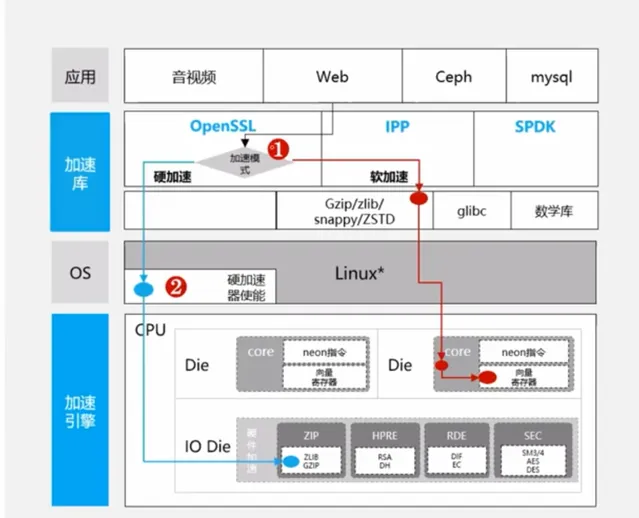
在壓縮演算法中,鯤鵬支持gzip/zlib、ZSTD以及snappy壓縮演算法,基於高效的壓縮引擎,鯤鵬處理器可大幅縮短檔的壓縮時間,具體如下圖所示:
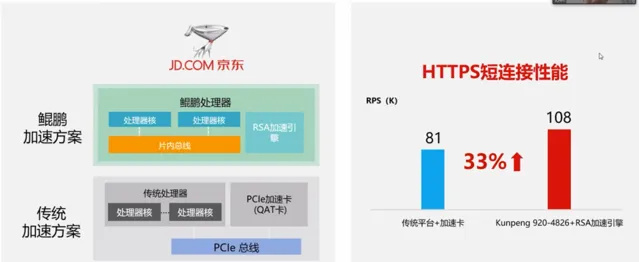
京東以鯤鵬RSA加密加速引擎,提升Web套用Https效能
京東的Web套用在未切換到鯤鵬加速方案之前,其使用的是傳統的加速方案,透過QAT卡進行加密加速,其效能是相對較低的。而在使用鯤鵬加速方案之後,其HTTPS短連線效能提升了33%,具體如下圖所示:
最佳化磁盤與網卡,給鯤鵬處理器一個更好的執行環境
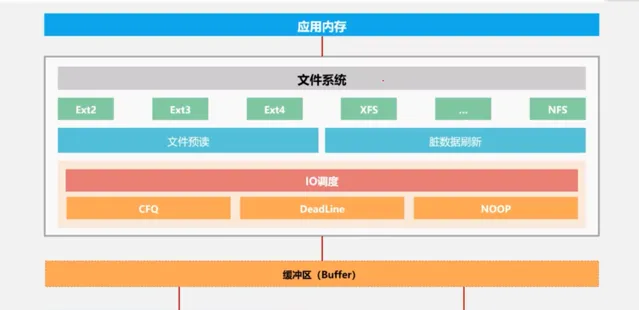
在前面提到的馮諾依曼架構中我們說到,除了CPU/記憶體以外,磁盤載入到記憶體過程的快慢也會影響業務的效能。下圖展示了磁盤數據載入到套用記憶體中的流程。可以透過選用XFS檔案系統、設定檔預讀、臟數據重新整理以及IO最佳化提高記憶體讀取速度。
網卡中斷產生頻率也會影響套用的吞吐和延遲。下圖展示了封包請求到來之後的抽象邏輯圖。簡單來說,當數據到達網卡時,網卡會通知CPU其接收到了封包,同時產生中斷。
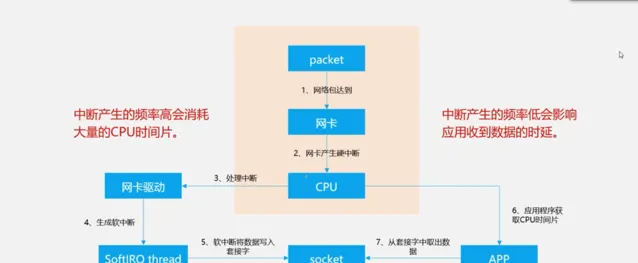
而透過調整網卡中斷策略,可以在低時延和高吞吐之間取更好的平衡點。

透過套用調優充分發揮硬體效能
從一般的套用調優角度來說,我們可以透過提高並行、數據緩存以及異步讀寫的方式來提高套用的效能。然而我們也會發現一個問題,如果我們CPU核心很多,那是不是並行越多越好,如果我們記憶體很大,那是不是數據緩存越多越好呢?其實不一定,軟體在適配硬體的同時,也要註意幾點細節,比如說,鎖機制以及Cache機制。
在多執行緒中,多個執行緒在存取一些公共變量時會出現搶鎖的情況,而搶鎖則會帶來CPU時間片消耗。當執行緒數越來越多時,搶鎖可能帶來的CPU時間片消耗也越多,從而導致效能下降。針對該情況,我們需要透過無鎖編程、大鎖變小鎖或者高效能原子操作指令等方式來最佳化並行效能。
在鎖與記憶體最佳化中,Tcmalloc透過減少記憶體分配中的鎖以提升高並行下的效能。

再來說一下針對鯤鵬的Cache機制最佳化來避免記憶體中偽共享的存取。CPU在將數據讀取到CPU記憶體中時是以CacheLine大小進行讀取的。在鯤鵬CPU中,CacheLine大小為128字節。在該128字節中,任何一個數據發生變化,那麽整個CacheLine都會被置為無效。以下圖為例,當有一個寫頻繁的變量和一個讀頻繁的變量放在一個CacheLine中,當寫頻繁的變量發生變化,會導致整個CacheLine失效,使得需要讀取讀頻繁的變量時不得不再從外部區域進行載入。

以MySQL 5.7.12為例,我們發現其記憶體對CacheLine進行寫死,並設定為64,在進行調優並將其設定為鯤鵬的CacheLine大小之後,整體效能提升了5%。
鯤鵬效能調優十板斧
鯤鵬社群根據使用經驗,總結了效能調優十板斧。
在CPU和記憶體方面,可針對如下方面進行調整:
調整記憶體頁大小
CPU預取
修改執行緒排程策略
在磁盤方面可針對如下方面進行調整:
臟數據重新整理
異步檔操作(libaio)
檔案系統參數
在網卡方面可針對如下方面進行調整:
網卡多佇列
開啟網卡TSO
開啟網卡CSUM
在套用方面,可針對如下方面進行調整:
最佳化編譯選項
檔緩存機制
緩存執行結果
NENO指令加速
以MariaDB為例看效能調優流程
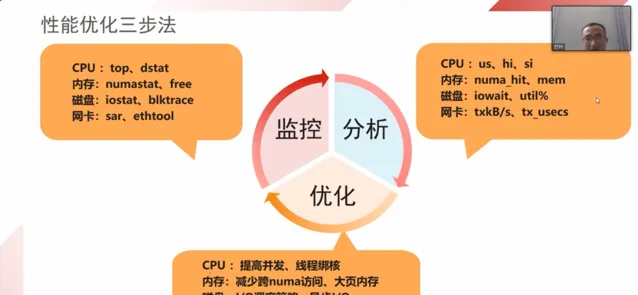
通常來說,效能調優可以分為三個步驟:監控、分析以及最佳化。在最佳化之後,如果未達預期,那麽我們還需要再進行監控、分析以及最佳化,如此反復。具體如下圖所示:
在監控階段,我們需要使用監控工具針對CPU、記憶體、磁盤以及網卡各項指標進行記錄。CPU的記錄指標包括硬中斷、軟中斷以及動態的CPU時間片占比;記憶體的記錄指標包括numa記憶體存取命中率,記憶體是否足夠;磁盤的記錄包括iowait以及磁盤使用率等;網卡則需記錄其傳輸頻寬等。透過上述收集的指標分析判斷最佳化方向。
在最佳化階段,CPU方面可透過提高並行和執行緒綁核的方式,記憶體方面可透過減少跨numa存取、大頁記憶體的方式,磁盤方面可透過I/O排程策略以及異步I/O的方式,而網卡方面則可透過中斷聚合、網卡中斷綁核的方式進行。
MariaDB效能最佳化-監控
sysbench壓測MariDB 10.3.8資料庫,OLTP模型讀寫比例為1:1。下圖為監控示意圖:
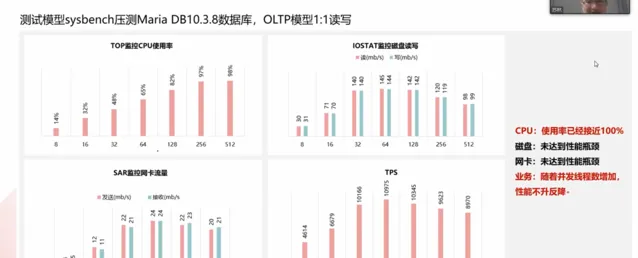
基於上圖,我們可以發現一個問題,當執行緒數增多時,CPU使用率越來越高,而TPS在到達頂點之後反而下降了。在綜合磁盤和網卡未到達效能瓶頸的情況下,我們可以得出CPU的使用瓶頸。
MariaDB效能最佳化-分析
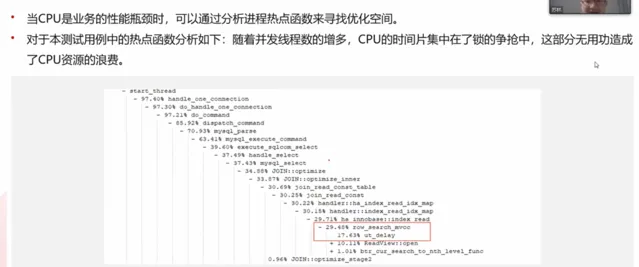
當CPU時業務的效能瓶頸時,可透過分析行程熱點函式來尋找最佳化空間,使用perf工具對本測試用例中的熱點函式分析如下:隨著並行執行緒數的增多,CPU的時間片集中在了鎖的爭搶中,這部份無用功造成了CPU資源的浪費。
MariaDB效能最佳化-最佳化
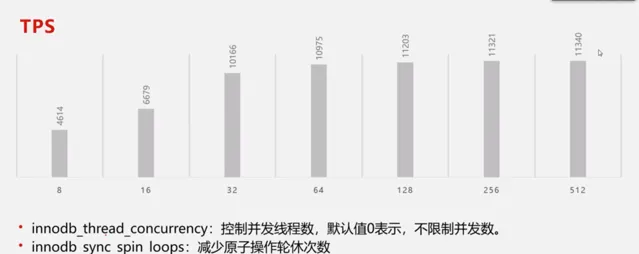
透過查閱MariaDB資料,我們可以透過調整一下參數提高效能。
innodb_thread_concurrency:控制並行執行緒數,預設值0表示,不限制並行
innodb_sync_spin_loops:減少原子操作輪休次數
innodb_spin_wait_delay:增加原子操作輪休間隔時間
總結
CPU/記憶體、磁盤、網卡、套用,是我們效能調優的四個主要方向
采集效能指標、分析效能瓶頸、最佳化相關參數程式碼,是調優的基本思路
充分利用硬體資源才能發揮軟體的最優效能
時延、吞吐、並行需要尋找一個均衡點
來源:https://lrting.top/backend/4046/
CPU技術篇
免責申明: 本號聚焦相關技術分享,內容觀點不代表本號立場, 可追溯內容均註明來源 ,釋出文章若存在版權等問題,請留言聯系刪除,謝謝。
推薦閱讀
更多 架構相關技術 知識總結請參考「 架構師全店鋪技術資料打包 (全) 」相關電子書( 41本 技術資料打包匯總詳情 可透過「 閱讀原文 」獲取)。
全店內容持續更新,現下單「 架構師技術全店資料打包匯總(全) 」一起發送「 」 和「 」 pdf及ppt版本 ,後續可享 全店 內容更新「 免費 」贈閱,價格僅收 249 元(原總價 339 元)。
溫馨提示:
掃描 二維碼 關註公眾號,點選 閱讀原文 連結 獲取 「 架構師技術全店資料打包匯總(全) 」 電子書資料詳情 。











