G it 是 由 Linux 之父 Linus Torvalds 開發的一個 開源 分布式版本控制系統,其廣受開發者青睞的同時,又因「難用」飽受詬病,成為讓人又愛又恨的存在。
本文作者 Mathew Duggan 是 Git 長達十年的忠實使用者,他一邊吐槽 Git 存在許多不足,不斷試用新產品尋找替代方案,一邊卻無奈地發現自己仍在使用。 Git 為什麽難以替代?讓我們跟隨作者,在不同的版本控制系統(VCS,version control system)的優劣對比中尋找答案吧~
我全職使用 Git 將近十年了。我每天都在使用它,主要依靠命令列版本。(針對Git使用,)我讀過書、聽過講座、練習實踐過,總之,我用 Git 有效地完成了工作。為了保持良好的工作狀態,我還在新的軟體倉庫中安裝了一些客製的 Git 勾點。
僅從曝光效應(譯者註:Exposure Effect,人們偏好自己熟悉的事物,只要某件事經常出現,就能增加人們的喜歡程度)的角度來說,我應該喜歡這個使用十年的工具,但我並不喜歡。
我不總是能「控制」Git 的工作,有時命令會導致意想不到的操作,這些操作與 Git 的工作方式一致,但與我偏好的工作方式不符。相反,我需要在腦子裏設想很多東西,才能讓它完成我想要的工作。
「好吧,我想把未暫存的編輯內容移到一個新的分支。如果該分支不存在,我想使用 checkout,但如果它存在,我就需要 stash、checkout,然後再 stash pop。」「如果現在問題是,我在錯誤的分支上做了修改,我需要stash apply 而不是 stash pop。」我需要引入一些跨版本的依賴關系,使用submodules還是subtree?
在工作中,我需要深刻理解reset、revert、checkout、clone、pull、fetch、cherrypick之間的區別,盡管這些詞在英語中的含義相同。
你需要記住,push和pull並不像它們的名字含義那樣對立。說到merge,你需要考慮清楚什麽情況下需要比較rebase、merge、merge --squash的邏輯。Merge的方向是什麽?糟糕,我不小心刪除了一個檔。我得記住 Git rev-list -n 1 HEAD - filename。Git reset --hard HEAD~1 可以糾正我的錯誤,我也得記住使用 --hard 時的具體作用,並確保傳遞的flag是正確的。
要記住這些操作,卻沒有人認為這不可能,而且很明顯,Git 對全世界數百萬人都大有用處。但我們能不能誠實地承認,以上操作對我幾乎每次工作都要用到的流程(如下所示)來說,實在是大材小用了:
建立分支
將分支推播到遠端
在分支上開展工作,然後送出拉取請求
合並 PR,通常是壓扁後合並,因為這樣更容易閱讀
讓 CI/CD 做它該做的事
我從未透過電子信件發送過修補程式,也從未從本地副本中還原過 repo。我不會花幾周時間離線工作,只為嘗試合並一個巨大的分支。我們不會讓版本庫的容量超過 1-2 GB,因為這樣一來,我需要修改三個檔並送出一份報告,同時它們會變得難以處理。典型的工作流程都無法從 Git 的復雜性中獲益。
更具體地說,Git 不能離線工作。它依賴於合並控制,而這種控制甚至不是 Git 和拉取請求的一部份。當我合並送出(squash)時,大部份的分布式歷史記錄都會被丟棄。我的本地磁盤上堆滿了過時的版本,以至於我不得不在開始工作前進行更新,但這種操作對我只是浪費時間。
現在有人提出「我不喜歡 Git 的工作方式」,這有點像從新穎的角度抱怨 PHP。讓我來闡述一下我心目中的完美 VCS(version control system,版本控制系統),並探討市面上的VCS能否滿足這些需求。
Gitlite
要取代 Git,我認為 VCS 需要增加(或減少)一些功能,滿足日常 95% 的使用需求。
拋棄分散模式。 我以及所有 Git 使用者使用大量的軟體倉庫,無論如何,我都需要經常存取伺服器才能完成工作。去中心化的復雜性並不劃算,我寧願做完下一部份就丟棄它。如果 GitHub 今天宕機了,無論如何也無法部署,那還不如把伺服器要求當成一種額外福利。
將大量工作轉移到伺服器端,按需進行。 如果我需要在一個版本庫中搜尋某個內容,與其從版本庫中復制所有內容,在本地搜尋到可能已經過時的資訊,不如在伺服器上執行搜尋,按需獲取我想的檔,而不是復制所有檔。
我需要大版本庫,但不想把所有檔都拷貝到磁盤上。 只在需要的時候提供給我對應檔,然後將剩下檔留存。為什麽我只要用 3 個檔,卻要不停下載數百個檔?
拉取請求是第一類公民 (譯者註:First- class Citizen,支持其他實體所有操作的實體)。我們了解「分支」的概念,也秉持「分支在合並前必須透過檢查」的理念。我提倡將其變成 CLI 流程的一部份。如果能在同一個工具中要求伺服器「空執行(dry-run)」一個 PR 檢查,檢視我的分支是否透過,那該有多好?想象一下,在不同的 Kubernetes 托管服務提供商中使用 gh CLI 的功能,而不使其針對特定平台,就像使用 kubectl 一樣。
認可並簡化跨版本依賴的理念。 子模組(submodules)的工作方式並不盡如人意,子樹(subtree)稍微好點,但將工作推回上遊依賴關系會讓人產生困惑與誤解。相反,我想要的是:https://Gitmodules.com/
如果我從遠端伺服器拉取內容,我的伺服器會與遠端伺服器保持同步,但我也可以選擇將版本固定在我的版本庫中。
如果我有許可權,我在版本庫中的更改會轉到遠端依賴庫中。
如果出現沖突,則透過 PR 來解決。
內建更好的視覺化工具。 使用者可透過瀏覽器或其他工具,更直觀地了解他們正在檢視的內容。很多人在使用 Git 時都會使用 CLI + 圖形化使用者介面工具來實作這個功能,我們可以把這個操作合並至一個步驟。
更易於集中管理送出資訊和規則。 沒錯,我可以使用一堆 Git 勾點,但如果能夠在複制 repo 時就被全面檢查就更好了,由此可以確保自己的做法正確,以免被 CI 外掛程式或送出資訊格式檢查器發現錯誤,浪費大量時間。我還希望能有一些提示,例如「嘿,這個分支越來越大了」或「每個送出都必須是 fix/feat/docs/ style/test/ci」等。
Read replica概念。 我很希望能將我的 CI/CD 系統指向一個唯讀副本集(Read replica box),並為實際使用者保留我的主 VCS box。主伺服器觸發一個 webhook,該 webhook 會觸發一個帶有標簽(tag)的計畫構建(build),然後點選唯讀副本,如果唯讀副本沒有該標簽,它就會從主伺服器中提取。最好能建立某種主/副模型,可以在配置中同時設定主伺服器和副伺服器,即使主伺服器(雲提供商)宕機,也能繼續將內容推播到有備份的地方。
因此,我嘗試了一些競品,看看「有沒有系統能在這些部份(比Git)設計得更好」。
2024 年的 SVN
我第一次接觸版本控制是 SVN(Subversion),當時的說法是「在工作滿一年之前不要嘗試建立分支」。不過,作為一名新手,SVN 的工作非常簡單,因為它功能並不多。Add、delete、copy、move、mkdir、status、diff、update、commit、log、revert、update -r、co -r 幾乎就是你所需要的所有命令。Subversion 有一個非常簡單的工作原理模型,即「我們把東西復制到檔伺服器上,然後在你要求時再傳回你的膝上型電腦」,這也有助於新使用者入門。
但不得不說,SVN 比我過往記憶中的體驗要好得多。產品存在的「粗糙邊緣」似乎都被打磨掉了,我沒有再遇到之前的問題,為 Subversion 團隊的出色工作點個大大的贊。
Subversion 基礎知識
實際上,Subversion 客戶端的基本功能是將所有檔作為單個原子事務送出到中央伺服器。無論何時,它都會為整個計畫建立一個新版本,稱為修訂版。這不是哈希值,只是一個從零開始的數位,所以新使用者不會混淆「新版本」和「舊版本」。這些數位是全域數位(global number),與檔無關,因此是world的狀態。每個檔都有 4 種狀態:
本地未修改 + 當前遠端: 保持不變
本地已更改 + 當前遠端: 要釋出更改,您需要將其送出,更新將不起任何作用
本地未修改 + 遠端已過期: SVN update 會將最新副本合並到工作副本中
本地已更改 + 遠端已過期: SVN commit 將不起作用,SVN update 會嘗試解決問題,但如果無法解決,使用者就要自行解決。
要「破壞」SVN幾乎是不可能的,因為向上推播並不意味著向下拉取。這意味著不同的檔和目錄可以設定為不同的版本,但只有執行 SVN update 時,整個world才會自動更新到最新版本。
使用 SVN 的工作流程如下:
確保已聯網
執行 SVN update,將工作副本升級到最新版本
進行所需的修改,切記不要使用作業系統工具來移動或刪除檔,而應使用 SVN copy 和 SVN move,這樣它就會知道這些更改
執行 SVN diff,確保你已經做了想做的任務
再次執行 SVN update,用 SVN resolve 解決沖突
感覺不錯?點選 SVN commit 就大功告成了
那為什麽 SVN 會被拋棄呢?一個原因:分支(branches)。
SVN 分支
在 SVN 中,分支其實就是把一個目錄貼上到正在工作的地方。 通常情況下,你會把它作為一個遠端拷貝,然後開始工作,所以看起來更像是把 URL 路徑復制到一個新的 URL 路徑。 但對使用者來說,它們看起來就像你建立的版本庫中的普通目錄。 在 SVN 1.4 之前,合並一個分支起碼需得要交給碩士學歷的員工,但他們增加了一個 SVN merge,簡化了合並。
實際上,你可以使用 SVN merge 來與主分支保持同步,然後當你準備就緒時,執行 SVN merge --reintegrate 來將分支推播到主分支。然後,你就可以刪除該分支,但如果需要讀取日誌,該分支的 URL 將始終有效。這一特性在票據系統特別有效,因為在票據系統中,URL 只是票據編號。不過,你也沒必要永遠用隨機目錄把事情搞得一團糟。
總之,SVN 分支以前的很多問題現在都不存在了。
那麽,SVN還存在什麽問題?
涉及 到 自動化功能,SVN 在我看來是失敗的,使用者只能親自動手。 雖然你可以對 repo 的不同部份進行細致入微的存取控制,但在實踐中並不常見。 如果沒有某種額外的控制或檢查,你就無法阻止他人合並分支。 即使你增加了計畫人員,也不太會有人更新這一功能,SVN 伺服器依舊負擔沈重。
此外,使用者介面已經過時,整個工具生態系也因為使用者的離開而開始腐化。我不知道現在還能否成功推薦別人從 Git 轉向使用 SVN,但我確實認為SVN有很多好的想法,能更接近我想要的工作方式。SVN只是在網路方面需要大量的 UI/UX 投入,才能讓我喜歡用它而不是 Git。但我認為,如果有人對這項工作感興趣,Subversion 的基本架構還是不錯的。
Sapling
與我共事過的每一位前 Meta 工程師都告訴我,他們非常懷念自己的 VCS。Sapling 就是這樣一個團隊,它讓我們能在一個更以 GitHub 為中心的世界裏玩轉功能。幾個月來,我一直在使用它Sapling來處理我的工作。我真的愛上了Sapling,它是為了易於理解而設計的,使用起來令人心情愉快。
Sapling和Git很多東西都是一樣的。用 sl clone 複制,用 sl status 檢查狀態,用 sl commit 送出。最明顯的不同之處在於堆疊的概念和 smartlog 的概念。堆疊是「送出的集合」,這一概念的含義是,可以透過命令列使用 sl pr submit 為這些變更釋出 PR,每個 GitHub PR 都是其中一個送出。這種檢視(顯然)既雜亂又惱人,所以還有另一種工具可以幫助你正確檢視變更,那就是 ReviewStack。
除非我向你展示我在說什麽,否則這一切都毫無意義。我新建了一個 repo,並向其中添加檔。首先,我檢查狀態:
❯ sl st? Dockerfile? all_functions.py? get-roles.sh? gunicorn.sh? main.py? requirements.in? requirements.txt
然後添加檔:
sl add .adding Dockerfileadding all_functions.pyadding get-roles.shadding gunicorn.shadding main.pyadding requirements.inadding requirements.txt
如果我想在本地執行一個更漂亮的網頁使用者介面,我會執行 sl web 並得到這個界面:
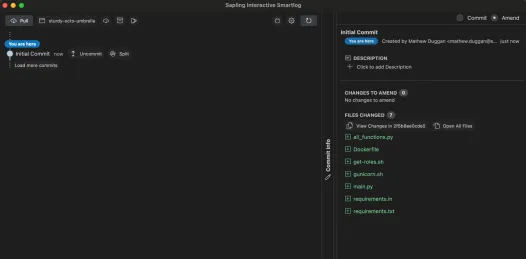
所以我把所有這些檔都添加到了初始送出中,很好,讓我們繼續添加:
❯ sl@ 5a23c603a 4 seconds ago mathew.duggan│ feat: adding the exceptions handler│o 2652cf416 17 seconds ago mathew.duggan│ feat: adding auth│o 2f5b8ee0c 9 minutes ago mathew.duggan Initial Commit
現在,如果我想瀏覽這個堆疊,只需使用 sl prev 即可上下移動堆疊:
sl prev 10 files updated, 0 files merged, 1 files removed, 0 files unresolved[2f5b8e] Initial Commit
這也體現在我的 sl 輸出中:
❯ slo 5a23c603a 108 seconds ago mathew.duggan│ feat: adding the exceptions handler│o 2652cf416 2 minutes ago mathew.duggan│ feat: adding auth│@ 2f5b8ee0c 11 minutes ago mathew.duggan Initial Commit
這也顯示在我的本地網路使用者介面上:
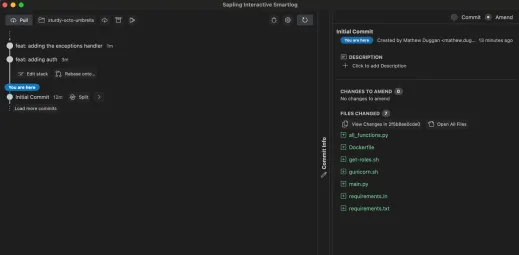
最後,流程以建立拉取請求的 sl pr 結束。它們是 GitHub 的拉取請求,但它們看起來與普通的 GitHub 拉取請求不同,你也不會以相同的方式,而是使用ReviewStack進行審查。
我為什麽喜歡 它?
Sapling符合我對 VCS 的期望,它更容易察覺到正在進行的工作,其設計旨在方便大型團隊合作,同時以更合理的方式提供所需資訊。命令對我來說更有意義,所有操作都能完成。
更具體地說,我喜歡它拋棄分支的概念。我所擁有的是一系列從開發主線分叉出來的送出,但我並沒有想要命名的明確內容,所以我要求添加這些送出。我想要的是在主線上添加一堆送出,然後由專人檢視這些送出集合,確保其合理性,並對其進行自動檢查。所以「分支」概念對我毫無用處,最後被我刪除了。
我還喜歡Sapling易於撤銷工作的特性,對我來說,uncommit、unamend、unhide 和 undo更加好用,而且幾乎總能達到預期效果。取消暫存區域,將重點放在易於使用的命令上,這樣的設計更符 合邏輯。
為什麽不應該切換?
既然我這麽喜歡Sapling,那還有什麽問題呢?為了讓Sapling達到我真正想要的效果,我需要執行更多的 Meta相關元件(譯者註:Sapling 是 Meta 開發和使用的原始碼控制系統)。Sapling在 GitHub 上執行得很好,但我最想得到的是:
Mononoke:Sapling的伺服器端元件
https://Github.com/facebook/sapling/blob/main/eden/mononoke/README.md
EdenFS
https://Github.com/facebook/sapling/blob/main/eden/fs/docs/Overview.md
以上元件基本囊括了Sapling的所有優點,如下所述:
按需獲取歷史檔(remotefilelog,2013)
檔案系統監控器,以更快地掌握工作副本狀態(watchman,2014)
回存稀疏配置檔以縮小工作副本(2015)
限制參照交換(選擇性拉取,2016)
按需獲取歷史樹(2017)
增量更新工作副本狀態(treestate,2017)
用於推播吞吐量和更快索引的新伺服器基礎設施(Mononoke,2017)
虛擬化工作副本,可按需獲取當前已簽出的檔或樹(EdenFS,2018)
更快的送出圖演算法(分段更新日誌,2020)
按需獲取送出(2021)
我很想嘗試將所有這些優點結合在一起(由於其中很多都有原始碼,我正在努力嘗試啟動),但到目前為止,我還無法復現完整的Sapling體驗。以上所有特點都吸引著人選擇過渡到 Sapling,但如果沒有這些特點,我就真的要在 GitHub 上添加很多自訂工作流了。我想我可以把 GitHub 整體遷移到其他地方,但 Meta 需要以一種更易於使用的方式釋出更多這些元件。
Scalar
Sapling 是 GitHub 其中一個很好的技術棧,但(實際上)我不會將一個團隊遷移到 Sapling 上,除非 Facebook(現Meta) 決定從頭到尾釋出整個軟體包。我能讓 Git 按照我想要的方式工作嗎?或者至少讓管理所有檔不那麽麻煩?
微軟有一款工具可以做到這一點,那就是 VFS for Git,但它只適用於 Windows,所以對我來說毫無用處。不過他們也提供了一款名為 Scalar 的跨平台工具,旨在「實作大規模的大型倉庫管理」。它最初是微軟的一項技術,最終被轉移到了 Git 身上,也許它能實作我想要的功能。
Scalar的作用是,有效設定所有最現代的 Git 選項,以便在大型倉庫中使用。以上內容包括,內建的檔案系統監視器、多包索引、送出圖、計劃後台維護、部份複制和複制模式稀疏檢出。
以上這些都是什麽?
檔案系統監視器是 FSMonitor,它是一個從作業系統跟蹤檔和目錄變化並將其加入佇列的守護行程。這就意味著 Git status 不需要查詢 repo 中的每個檔就能發現改動。
把帶有 pack 檔的 Git pack 目錄拆分成多個。
文件中的送出圖:
「commit-graph 檔儲存了送出圖結構以及一些額外的後設資料,以加快圖的走行速度。透過按詞典順序列出送出 OID,我們可以為每個送出確定一個整數位置,並使用這些整數位置來參照送出的父節點。我們使用二進制搜尋尋找初始送出,然後在過程中使用整數位置進行快速尋找。」
最後是複制模式 sparse-checkout。這允許人們將工作目錄限制為特定檔
這個工具的目的是建立一種處理大型單核計畫的簡便模式,著眼於實際上是微服務集合的單核計畫。好吧,但它能滿足我的需求嗎?
我為什麽喜歡它?
Scalar已經內建在 Git 中,這很好,便於使用者上手並使用。此外,它還能實作我想要的功能,把一堆現有的 repo 合並成一個巨大的 monorepo,效能出奇地好。稀疏簽出意味著我可以指定哪些是需要的,哪些是不需要的,還解決了「如果我有一個巨大的二進制檔目錄,但我不想讓別人擔心怎麽辦」的問題,因為它采用了與 .Gitignore 相同的模式匹配。
但Scalar並不能從根本上改變 Git 的本質。使用這些預設設定,你可以把倉庫擴大很多,但它仍然需要在本地處理很多事情,而且需要人工處理。不過我想說,Scalar讓我少了很多抱怨。結合用於 PR 的 gh CLI 工具,我能夠拼湊出一個相當滿意的工作流程。
因此,雖然這肯定是我以後要采用的模式(充滿微服務的 monorepo,我能夠用純量來管理規模),但我認為它代表了你能在多大程度上修改 Git 作為現有平台。這是目前最好的選擇,雖然已經很接近我的目標,但仍無法達到。
你可以親自試試:https://Git-scm.com/docs/scalar
結論
所以我們應該怎麽選擇VCS?老實說,我可以就這個問題再寫上 5000 字。在這一領域,我們總感覺自己離破解這個秘密越來越近,然後又放棄了,因為我們找到的解決方案基本上已經足夠好了。隨著工作流程的不斷發展,我們再也沒有回過頭來觸碰應用程式設計的「第三條軌域」(新方案)。
為什麽呢?我認為,人們之所以對 Git 不滿意,是因為他們不了解它。這種狀況讓人感覺,如果你不喜歡這個工具,那麽問題就出在你身上,而不是工具。我還認為,程式設計師之所以喜歡分散式設計,是因為它(在某種程度上)鼓勵了對可移植性的虛假希望。是的,我完全依賴於 GitHub 的操作(包括Pull Requests、GitHub 存取控制、SSO、secrets 和releases),但在緊要關頭,我可以將實際的 repo 本身轉移到另一個提供商那裏。
我非常希望有人能再次著手解決這個問題。我覺得我們的工作還沒有完成,而且從對所有這些問題的研究來看,似乎有很多低垂的最佳化果實可供任何人摘取。我認為主要的障礙是你需要離開 Git,遷移到一個完全不同的結構,這對我們來說可能太難了。不過,我始終期待這個問題能夠被解決。
作者丨 Mathew Duggan 編譯丨onehunnit
來源丨matduggan.com/why-dont-i-like-git-more/
dbaplus社群歡迎廣大技術人員投稿,投稿信箱: [email protected]












