Big Whale
巨鯨任務排程平台為美柚大數據研發的分布式計算任務排程系統,提供Spark、Flink等批次處理任務的DAG排程和流處理任務的執行管理和狀態監控,並具有Yarn套用管理、重復套用檢測、大記憶體套用檢測等功能。服務基於Spring Boot 2.0開發,打包後即可執行。
概述
1.架構圖
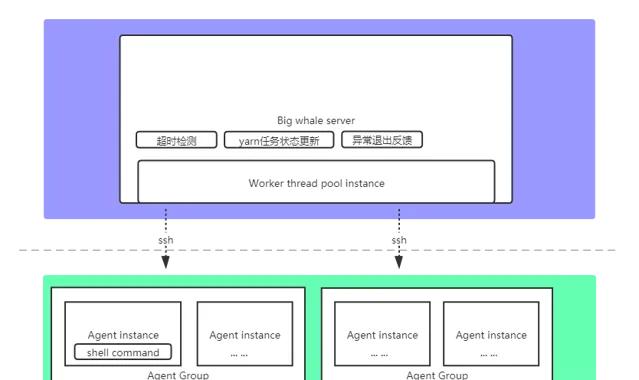
2.特性
基於SSH的指令碼執行機制,部署簡單快捷,僅需單個服務
基於Yarn Rest Api的任務狀態同步機制,對Spark、Flink無版本限制
支持失敗重試
支持任務依賴
支持復雜任務編排(DAG)
支持流處理任務執行管理和監控
支持Yarn套用管理
部署
1.準備
Java 1.8+
Mysql 5.1.0+
下載計畫或git clone計畫
為解決 github README.md 圖片無法正常載入的問題,請在hosts檔中加入相關網域名稱解析規則,參考: hosts
2.安裝
建立資料庫:big-whale
執行資料庫指令碼: big-whale.sql
根據Spring Boot環境,配置相關資料庫帳號密碼,以及SMTP資訊
配置: big-whale.properties
ssh.user: 擁有指令碼執行許可權的ssh遠端登入使用者名稱(平台會將該使用者作為統一的指令碼執行使用者)
ssh.password: ssh遠端登入使用者密碼
dingding.enabled: 是否開啟釘釘告警
dingding.watcher-token: 釘釘公共群機器人Token
yarn.app-memory-threshold: Yarn套用記憶體上限(單位:MB),-1禁用檢測
yarn.app-white-list: Yarn套用白名單列表(列表中的套用申請的記憶體超過上限,不會進行告警)
配置項說明
修改:$FLINK_HOME/bin/flink,參考: flink (因flink送出任務時只能讀取本地jar包,故需要在執行送出命令時從hdfs上下載jar包並替換指令碼中的jar包路徑參數)
打包:mvn clean package
3.啟動
檢查埠17070是否被占用,被占用的話,關閉占用的行程或修改計畫埠號配置重新打包
拷貝target目錄下的big-whale.jar,執行命令:java -jar big-whale.jar
4.初始配置
開啟:
http://localhost:17070
輸入帳號admin,密碼admin
點選:許可權管理->使用者管理,修改當前帳號的信箱為合法且存在的信箱地址,否則會導致信件發送失敗
添加集群
集群管理->集群管理->新增
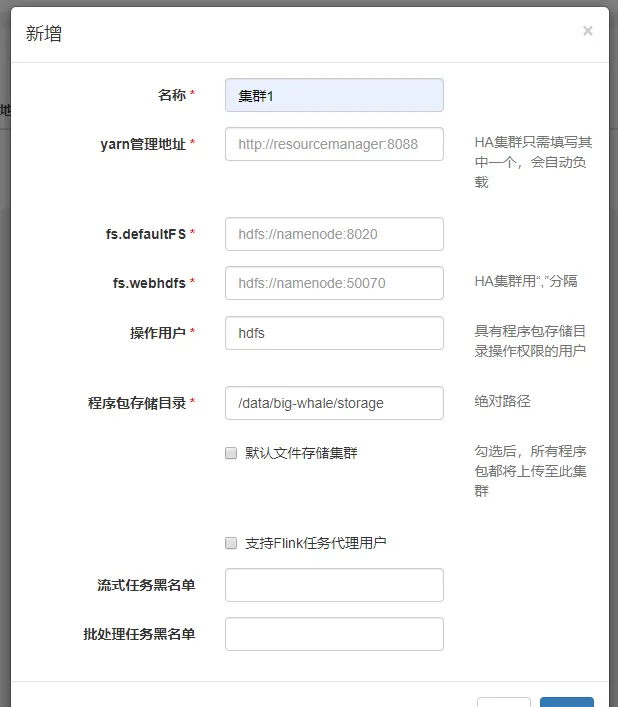
「yarn管理地址」為Yarn ResourceManager的WEB UI地址
「程式包儲存目錄」為程式包上傳至hdfs集群時的儲存路徑,如:/data/big-whale/storage
「支持Flink任務代理使用者」「流處理任務黑名單」和「批次處理任務黑名單」為內部客製的任務分配規則,勿填
添加集群使用者
集群管理->集群使用者->新增
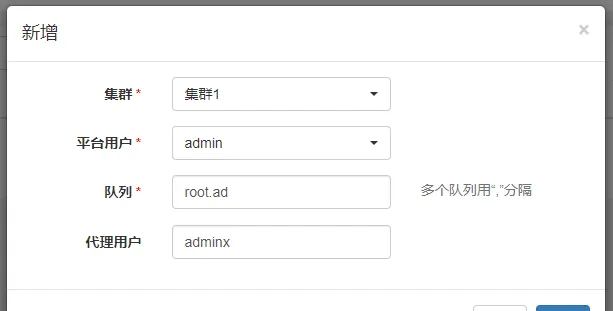
該配置的語意為:平台使用者在所選集群下可以使用的Yarn資源佇列(--queue)和代理使用者(--proxy-user)
添加代理
集群管理->代理管理->新增
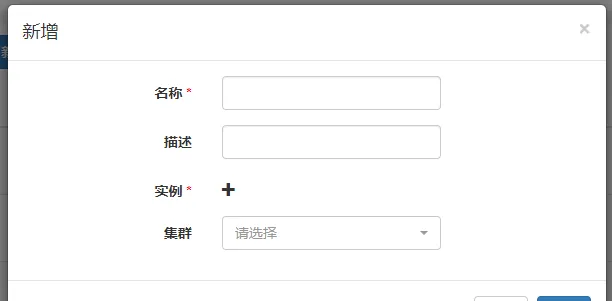
可添加多個例項(僅支持IP地址,可指定埠號,預設為22),執行指令碼的時候會隨機選擇一個例項執行,在例項不可達的情況下,會繼續隨機選擇下一個例項,在例項均不可達時執行失敗
選擇集群後,會作為該集群下送出Spark或Flink任務的代理之一
添加計算框架版本
集群管理->版本管理->新增
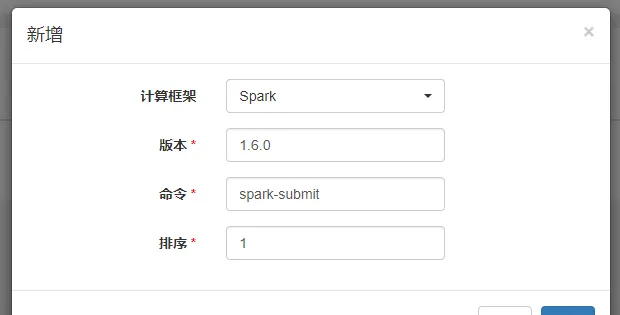
同一集群下不同版本的Spark或Flink任務的送出命令可能有所不同,如Spark 1.6.0版本的送出命令為spark-submit,Spark 2.1.0版本的送出命令為spark2-submit
使用
1.離線排程
1.1 新增
目前支持「Shell」、「Spark Batch」和「Flink Batch」三種型別的批次處理任務
透過拖拽左側工具列相應的批次處理任務圖示,可添加相應的DAG節點
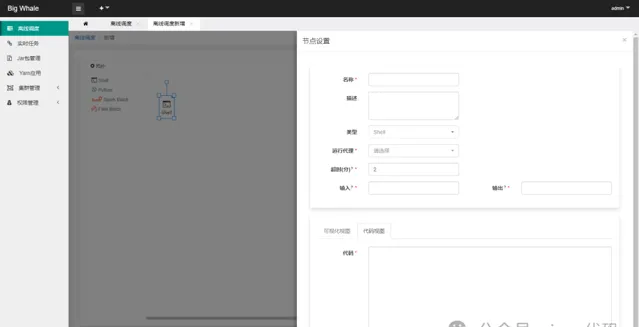
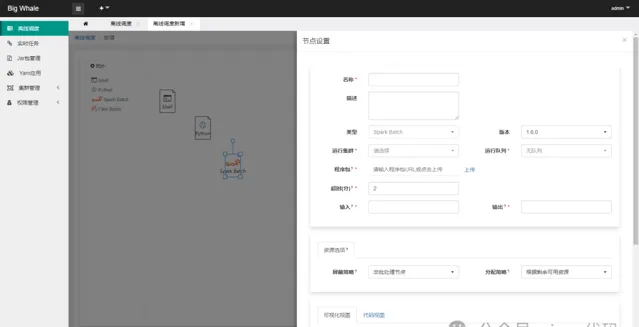
支持時間參數
${now} ${now - 1d} ${now - 1h@yyyyMMddHHmmss}
等(d天、h時、m分、s秒、@yyyyMMddHHmmss為格式化參數)
非「Shell」型別的批次處理任務應上傳與之處理型別相對應的程式包,此處為Spark批次處理任務打成的jar包
「資源選項」可不填
程式碼有兩種編輯模式,「視覺化檢視」和「程式碼檢視」,可互相切換
點選「測試」可測試當前節點是否正確配置並可以正常執行
為防止平台執行緒被大量占用,平台送出Saprk或Flink任務的時候都會強制以「後台」的方式執行,對應spark配置:--conf spark.yarn.submit.waitAppCompletion=false,flink配置:-d,但是基於後台「作業狀態更新任務」的回呼,在實作DAG執行引擎時可以確保當前節點所送出的任務執行完成後再執行下一個節點的任務
DAG節點支持失敗重試
將節點按照一定的順序連線起來可以構建一個完整的DAG
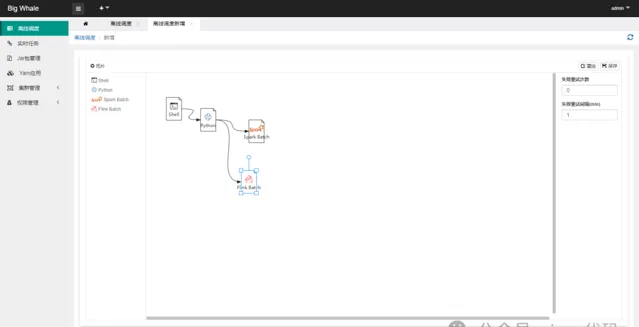
DAG構建完成後,點選「保存」,完成排程設定
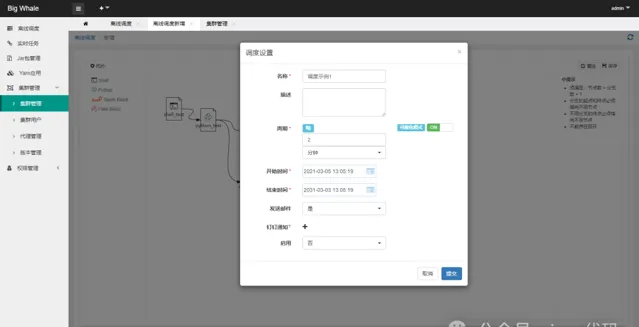
1.2 操作
開啟離線排程列表
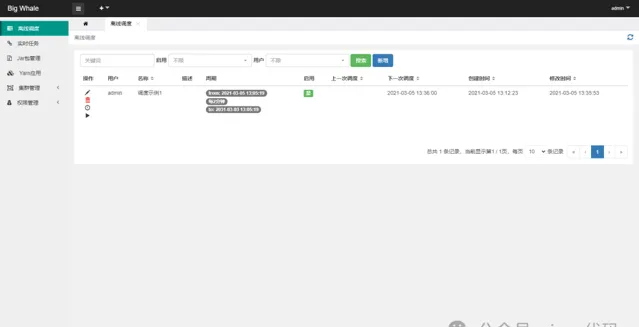
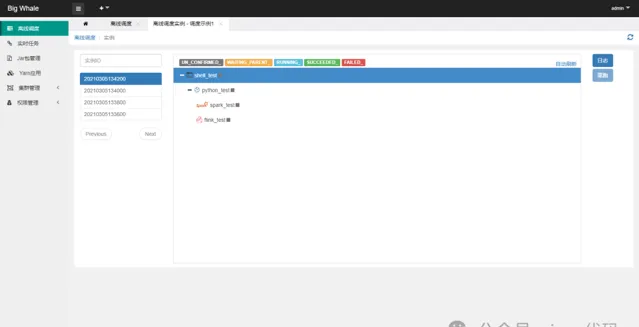
點選左側操作欄「排程例項」可檢視排程例項列表、執行狀態和節點啟動日誌
點選左側操作欄「手動執行」可觸發排程執行
2.即時任務
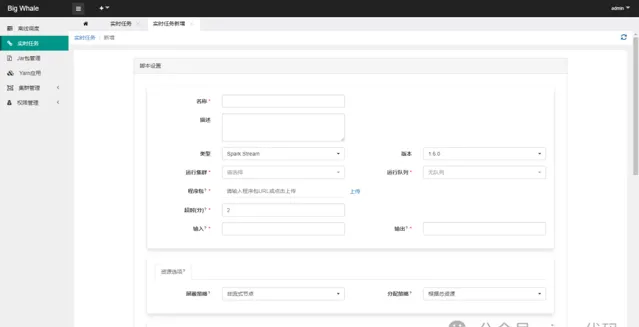
2.1 新增
目前支持「Spark Stream」和「Flink Stream」兩種型別的流處理任務
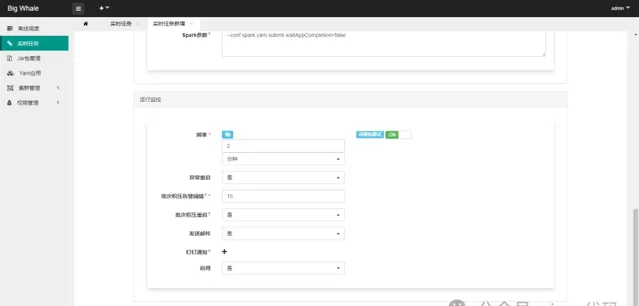
啟用監控可以對任務進行狀態監控,包括異常重新開機、批次積壓告警等
2.2 操作
開啟即時任務列表
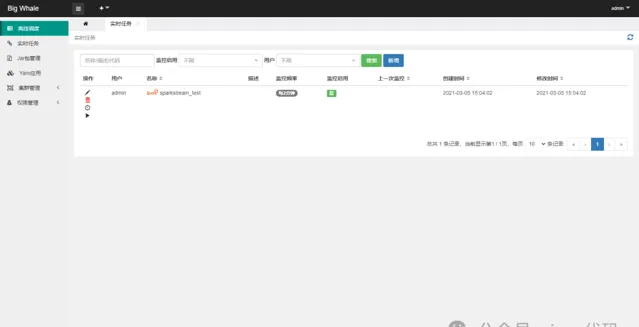
點選左側操作欄「日誌」可檢視任務啟動日誌
點選左側操作欄「執行」可觸發任務啟動
3.任務告警
正確配置信件或釘釘告警後在任務執行異常時會發送相應的告警信件或通知,以便及時進行相應的處理
<巨鯨任務告警>
代理: agent1
型別: 指令碼執行失敗
使用者: admin
任務: 排程範例1 - shell_test
時間: 2021-03-05 15:18:23
<巨鯨任務告警>
集群: 集群1
型別: spark離線任務異常(FAILED)
使用者: admin
任務: 排程範例1 - spark_test
時間: 2021-03-05 15:28:33
<巨鯨任務告警>
集群: 集群1
型別: spark即時任務批次積壓,已重新開機
使用者: admin
任務: sparkstream_test
時間: 2021-03-05 15:30:41
除上述告警資訊外還有其他告警資訊此處不一一列舉
Change log
v1.1開始支持DAG
v1.2開始支持DAG節點失敗重試
v1.3排程引擎進行重構升級,不支持從舊版本升級上來,原有舊版本的任務請手動進行遷移,離線排程移除「Python」型別指令碼支持
計畫地址:
https://gitee.com/meetyoucrop/big-whale.git











