計畫介紹
🎈 該計畫主要分析深圳通刷卡數據,透過大數據技術角度來研究深圳地鐵客運能力,探索深圳地鐵最佳化服務的方向;
✨ 強調學以致用,本計畫的原則是盡可能使用較多的常用技術框架,加深對各技術棧的理解和運用,在使用過程中體驗各框架的差異和優劣,為以後的計畫開發技術選型做基礎;
👑 解決同一個問題,可能有多種技術實作,實際的企業開發應當遵守最佳實踐原則;
🎉 學習過程優先選擇較新的軟體版本,因為新版踩坑一定比老版更多,坑踩的多了,技能也就提高了,遇到新問題可以見招拆招、對癥下藥;
架構圖
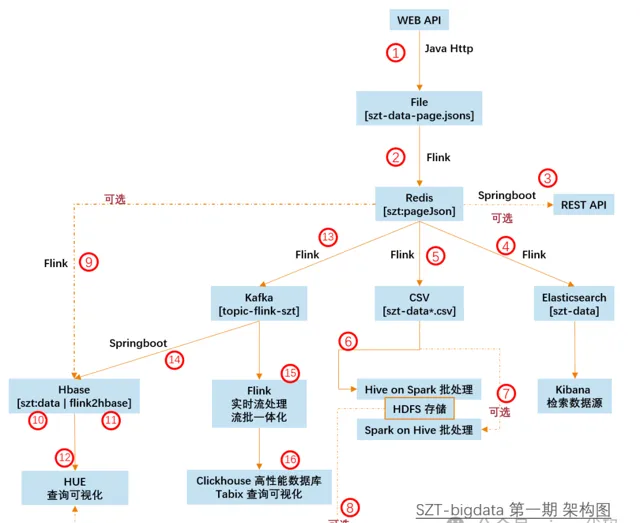
核心技術棧
Java-1.8/Scala-2.11
Flink-1.10,流式業務、ETL 首選
Redis-3.2,天然去重,自動排序
Kafka-2.1,訊息佇列業務解耦、流量消峰、訂閱釋出場景首選
kafka-eagle-1.4.5,集生產、消費、Ksql、大屏、監控、報警於一身,同時監控 zk
Zookeeper-3.4.5,集群基礎依賴,選舉時 ID 越大越優勢,透過會話機制維護各元件線上狀態
CDH-6.2,解決了程式設計師最難搞的軟體相容性問題,全家桶服務一鍵安裝;
Docker-19,最快速度部署一款新軟體,無侵入、無汙染、快速擴容、服務打包。
SpringBoot-2.13,通用 JAVA 生態,敏捷開發必備
knife4j-2.0
Elasticsearch-7,全文檢索領域唯一靠譜的資料庫,搜尋引擎核心服務,億級數據毫秒響應
Kibana-7.4,ELK 全家桶成員,前端視覺化
ClickHouse,家喻戶曉的 nginx 伺服器就是俄羅斯的代表作,接下來大紅大紫的 clickhouse 同樣身輕如燕,但是效能遠超目前市面所有同類資料庫,儲存容量可達PB級別。
MongoDB-4.0,文件資料庫,對 Json 數據比較友好,主要用於爬蟲資料庫
Spark-2.3,目前國內大數據框架即時微批次處理、離線批次處理主流方案
Hive-2.1,Hadoop 生態數倉必備,大數據離線處理 OLAP 結構化資料庫
Impala-3.2,像羚羊一樣輕快矯健,同樣的 hive sql 復雜查詢,impala 毫秒級返回
HBase-2.1 + Phoenix,Hadoop 生態下的非結構化資料庫,HBase 的靈魂設計就是 rowkey 和多版本控制
Kylin-2.5,麒麟多維預分析系統,依賴記憶體快速計算,但是局限性有點多啊,適用於業務特別穩定,緯度固定少變的場景
HUE-4.3,CDH 全家桶贈送的,強調使用者體驗,運算元倉很方便,許可權控制、hive + impala 查詢、hdfs 檔管理、oozie 任務排程指令碼編寫
阿裏巴巴 DataX,異構資料來源同步工具,主持大部份主流資料庫
Oozie-5.1,本身 UI 奇醜,但是配合 HUE 食用尚可接受,主要用來編寫和執行任務排程指令碼
Sqoop-1.4,主要用來從 Mysql 匯出業務數據到 HDFS 數倉
Mysql-5.7
Hadoop3.0(HDFS+Yarn),HDFS 是目前大數據領域最主流的分布式海量數據儲存系統,這裏的 Yarn 特指 hadoop 生態,主要用來分配集群資源,內建執行引擎 MR
阿裏巴巴 DataV 視覺化展示
準備工作:
Win10 IDEA 2019.3 旗艦版,JAVA|Scala 開發必備,集萬般功能於一身;
Win10 DBeaver 企業版 6.3,秒殺全宇宙所有資料庫客戶端,幾乎一切常用資料庫都可以連,選好驅動是關鍵;
Win10 Sublime Text3,地表最強輕量級編輯器,光速啟動,無限量外掛程式,主要用來編輯零散檔、markdown 即時預覽、寫前端特別友好
其他一些實用工具參考我的部落格:https://java666.cn/#/AboutMe
CentOS7 CDH-6.2 集群,包含如下元件,對應的主機角色和配置如圖,集群至少需要40 GB 總記憶體,才可以滿足基本使用
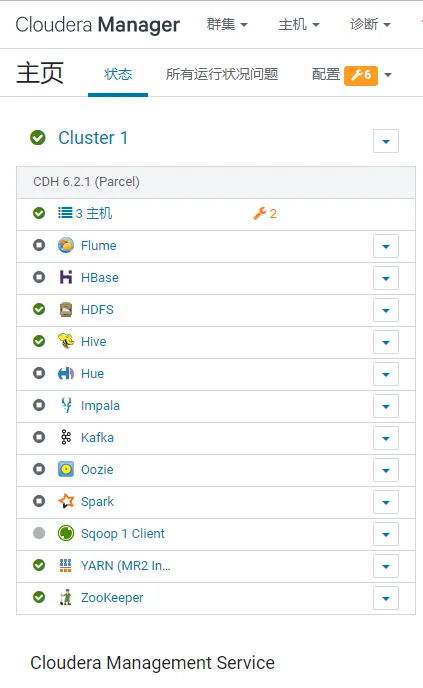

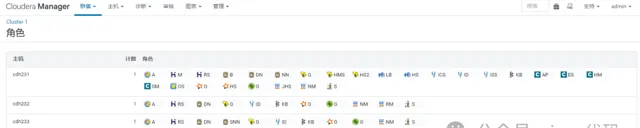
如果你選用原版 Apache 元件搭建大數據集群,那麽你會有踩不完的坑。我的頭發不夠掉了,所以我選 CDH 【2021 年以後,CDH 徹底收費,學習階段不再推薦,USDP 可以嘗試一下,但是占用記憶體台多,強行部署請準備好足夠的硬體,建議的集群配置是 32G RAM * 3,。補充:隨著 Hadoop 生態的軟體叠代,相容性問題日趨嚴重,為了解決相容問題,推薦自行部署 Apache 版本的原生 Hadoop 集群,你可以從頭到尾編譯和客製自己的每一個元件每一行程式碼
物理機配置
以上軟體分開部署在我的三台電腦上,Win10 筆記本 VMware + Win10 桌上型電腦 VMware + 古董筆記本 CentOS7。物理機全都配置 SSD + 千兆乙太網路卡,HDFS 需要最快的網卡。好馬配好鞍,當然你得有個千兆交換機配合千兆網線

如果你有一台超過 16G RAM 的閑置 Linux 主機,可以嘗試使用更快的方式初始化本計畫的 hadoop 集群環境,使用 vagrant 批次部署集群,快速體驗:
# 在 linux 機器(RAM > 16G)執行以下命令,目前只相容 centos7
# 科學上網環境部署:https://github.com/juewuy/ShellClash
curl -sSL https://raw.githubusercontent.com/geekyouth/vagrant/main/start.sh | sh -x
如果你想避免網線牽來牽去,可以采用電力貓實作分布式家用群組網方案;
資料來源
深圳市政府數據開放平台,深圳通刷卡數據 133.7 萬條【離線數據】貌似已經停止服務😒:
https://opendata.sz.gov.cn/data/api/toApiDetails/29200_00403601
備用資料來源(之前上傳的一批 jsons 數據有些紕漏,於是重新整理壓縮後放到本倉庫中,速度慢的同學可以嘗試碼雲 https://gitee.com/geekyouth/SZT-bigdata ):
.file/2018record3.zip
理論上可以當作即時數據,但是這個介面響應太慢了,如果采用 kafka 佇列方式,也可以模擬出即時效果。
本計畫采用離線 + 即時思路 多種方案處理。
開發進度
1- 獲取資料來源的 appKey:
https://opendata.sz.gov.cn/data/api/toApiDetails/29200_00403601
2- 程式碼開發:
2.1- 呼叫 cn.java666.etlspringboot.source.SZTData#saveData 獲取原始數據存盤 /tmp/szt-data/szt-data-page.jsons,核對數據量 1337,註意這裏每條封包含1000條子數據;
2.2- 呼叫 cn.java666.etlflink.sink.RedisSinkPageJson#main 實作 etl 清洗,去除重復數據,redis 天然去重排序,保證數據幹凈有序,跑完後核對 redis 數據量 1337。
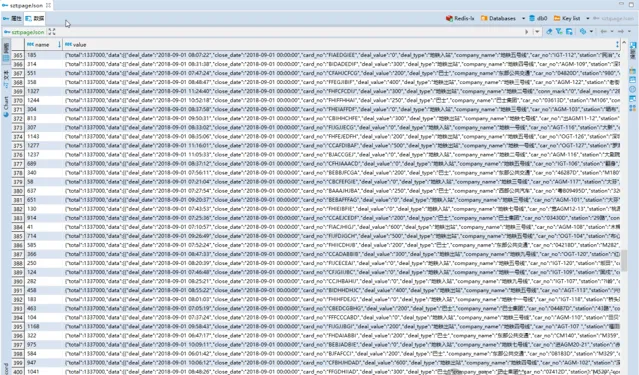
2.3- redis 查詢,redis-cli 登入後執行 hget szt:pageJson 1
或者 dbeaver 視覺化查詢:
2.4- cn.java666.etlspringboot.EtlSApp#main 啟動後,也可以用 knife4j 線上偵錯 REST API:
2.5- cn.java666.etlflink.source.MyRedisSourceFun#run 清洗數據發現 133.7 萬數據中,有小部份源數據欄位數為9,缺少兩個欄位:station、car_no;丟棄臟數據。
合格源數據範例:
{
"deal_date": "2018-08-31 21:15:55",
"close_date": "2018-09-01 00:00:00",
"card_no": "CBHGDEEJB",
"deal_value": "0",
"deal_type": "地鐵入站",
"company_name": "地鐵五號線",
"car_no": "IGT-104",
"station": "布吉",
"conn_mark": "0",
"deal_money": "0",
"equ_no": "263032104"
}
不合格的源數據範例:
{
"deal_date": "2018-09-01 05:24:22",
"close_date": "2018-09-01 00:00:00",
"card_no": "HHAAABGEH",
"deal_value": "0",
"deal_type": "地鐵入站",
"company_name": "地鐵一號線",
"conn_mark": "0",
"deal_money": "0",
"equ_no": "268005140"
}
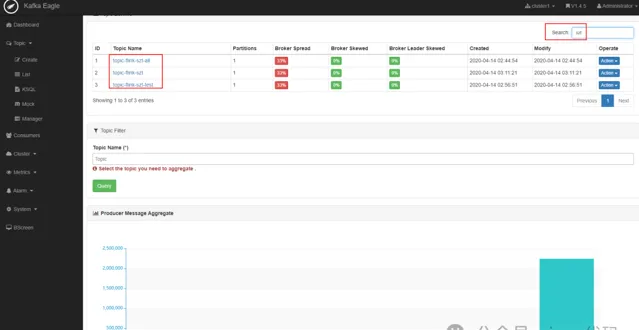
2.6- cn.java666.etlflink.app.Redis2Kafka#main 根據需求推播滿足業務要求的源數據到 kafka,topic-flink-szt-all 保留了所有源數據 1337000 條, topic-flink-szt 僅包含清洗合格的源數據 1266039 條。
2.7- kafka-eagle 監控檢視 topic,基於原版去掉了背景圖,漂亮多了:
}
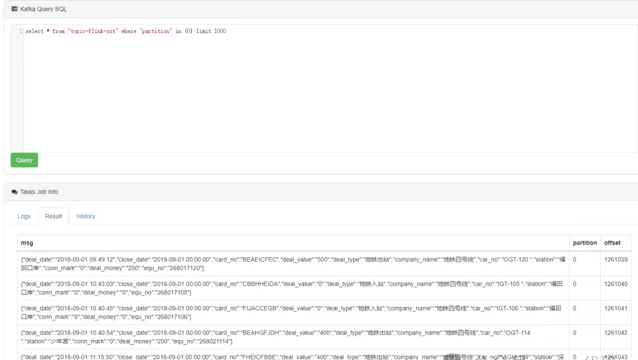
ksql 命令查詢:
select * from "topic-flink-szt" where "partition" in (0) limit 1000
2.8- cn.java666.etlflink.app.Redis2Csv#main 實作了 flink sink csv 格式檔,並且支持按天分塊保存。
2.9- cn.java666.etlflink.app.Redis2ES#main 實作了 ES 儲存源數據。實作即時全文檢索,即時跟蹤深圳通刷卡數據。
這個模組涉及技術細節比較多,如果沒有 ES 使用經驗,可以先做下功課,不然的話會很懵。
這部份內容有更新:修正了上一個版本時區問題。
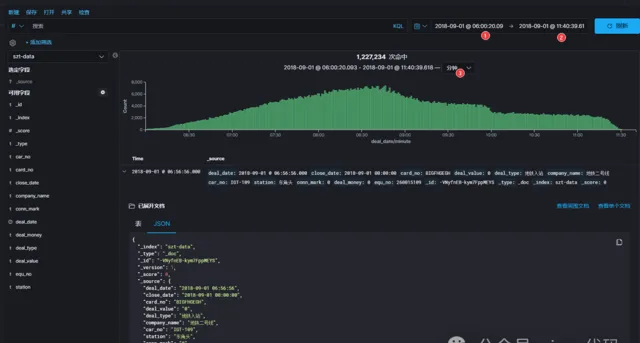
🎬接下來,讓我們時光倒流,回到 2018-09-01這一天,調整 kibana 面板時間範圍 2018-09-01 00:00:00.000~2018-09-01 23:59:59.999,看看當天深圳通刷卡記錄的統計圖曲線走向是否科學,間接驗證資料來源的完整性。
修正時區後統計數量,欄位完整的合格源數據 1266039 條,2018-09-01全天 1229180 條。
圖中可以看出 2018-09-01 這一天刷卡記錄集中在上午6點~12點之間,早高峰數據比較吻合,雖然這一天是周六,高峰期不是特別明顯。我們繼續縮放 kibana 時間軸看看更詳細的曲線:
回顧一下本計畫 ETL 處理流程:
1337000 條源數據清洗去除欄位不全的臟數據,剩余的合格數據條數 1266039 已經進入 ES 索引
szt-data
在 1266039 條合格數據中,有 1227234 條數據集中在 2018-09-01 這一天的上午時段;
我們暫且相信上午時段的數據是真實的,那麽是否說明官方提供的數據並不是全部的當天完整刷卡數據???
如果按照上午的刷卡量來估測全天的刷卡量,考慮到是周六,那麽深圳通全天的刷卡記錄數據應該在 122萬 X 2 左右,當然這麽武斷的判斷方式不是程式設計師的風格,接下來我們用科學的大數據分析方式來研究這些數據背後的意義。
註意,ES 大坑:
ES 存數據時,帶有時間欄位的數據如何即時展示到 kibana 的圖表面板上?需要在存入 index 之前設定欄位對映。
{
"properties": {
"deal_date": {
"format": "yyyy-MM-dd HH:mm:ss",
"type": "date"
}
}
}
這裏並沒有指定時區資訊,但是 ES 預設使用 0 時區,這個軟體很坑,無法設定全域預設時區。但是很多軟體產生的數據都是預設機器所在時區,國內就是東八區。因為我們的源始數據本身也沒有包含時區資訊,這裏我不想改源數據,那就假裝自己在 ES 的 0 時區。同時需要修改 kibana 預設時區為 UTC,才可以保證 kibana 索引圖表時間軸正確對位。不過這並不是一個科學的解決方案。
ES 存數據時,需要使用 json 格式包裝數據,不符合json 語法的純字元無法保存;
ES 序列化復雜的 bean 物件時,如果 fastjson 報錯,推薦使用 Gson
Gson 相比 fastjson:Gson 序列化能力更強,但是 反序列化時,fastjson 速度更快。
2.10- 檢視 ES 資料庫卡號,對比自己的深圳通地鐵卡,逐漸發現了一些脫敏規律。
日誌當中卡號脫敏欄位密文反解猜想:
由脫敏的密文卡號反推真實卡號,因為所有卡號密文當中沒有J開頭的數據, 但是有A開頭的數據,A != 0,而且出現了 BCDEFGHIJ 沒有 K,所以猜想卡號對映關系如圖!!!

類似摩斯電碼解密。。。我現在還不確定這個解密方式是否正確🙄🙄🙄
2.11-
cn.java666.sztcommon.util.ParseCardNo#parse
實作了支持自動辨識卡號明文和密文、一鍵互轉功能。
cn.java666.etlspringboot.controller.CardController#get
實作了卡號明文和密文互轉 REST API。

3- 搭建數倉:深圳地鐵數倉建模
3.1- 第一步,分析業務
確定業務流程 ---> 聲明粒度 ---> 確定維度 ---> 確定事實
3.2- 第二步,規劃數倉結構
參考行業通用的數倉分層模式:ODS、DWD、DWS、ADS,雖然原始數據很簡單,但是我們依然使用規範的流程設計資料倉儲。
第一層:ODS 原始數據層
ods/ods_szt_data/day=2018-09-01/
# szt_szt_page/day=2018-09-01/
第二層:DWD 清洗降維層
區分維表 dim_ 和事實表 fact_,為了使粒度更加細化,我們把進站和出站記錄分開,巴士數據暫不考慮。
dwd_fact_szt_in_detail 進站事實詳情表
dwd_fact_szt_out_detail 出站事實詳情表
dwd_fact_szt_in_out_detail 地鐵進出站總表
第三層:DWS 寬表層
dws_card_record_day_wide 每卡每日行程記錄寬表【單卡單日所有出行記錄】
第
四層: ADS 業務指標層【待補充】
【體現進站壓力】 每站進站人次排行榜
ads_in_station_day_top
【體現出站壓力】 每站出站人次排行榜
ads_out_station_day_top
【體現進出站壓力】 每站進出站人次排行榜
ads_in_out_station_day_top
【體現通勤車費最多】 每卡日消費排行
ads_card_deal_day_top
【體現路線運輸貢獻度】 每路線單日運輸乘客總次數排行榜,進站算一次,出站並且聯程算一次
ads_line_send_passengers_day_top
【體現利用率最高的車站區間】 每日運輸乘客最多的車站區間排行榜
ads_stations_send_passengers_day_top
【體現路線的平均通勤時間,運輸效率】 每條路線單程直達乘客耗時平均值排行榜
ads_line_single_ride_average_time_day_top
【體現深圳地鐵全市乘客平均通勤時間】 所有乘客從上車到下車間隔時間平均值
ads_all_passengers_single_ride_spend_time_average
【體現通勤時間最長的乘客】 單日從上車到下車間隔時間排行榜
ads_passenger_spend_time_day_top
【體現車站配置】 每個站點進出站閘機數量排行榜
每個站點入站閘機數量 ads_station_in_equ_num_top
每個站點出站閘機數量 ads_station_out_equ_num_top
【體現各路線綜合服務水平】 各路線進出站閘機數排行榜
各路線進站閘機數排行榜 ads_line_in_equ_num_top.png
各路線出站閘機數排行榜 ads_line_out_equ_num_top
【體現收入最多的車站】 出站交易收入排行榜
ads_station_deal_day_top
【體現收入最多的路線】 出站交易所線上路收入排行榜
ads_line_deal_day_top
【體現換乘比例、乘車體驗】 每天每路線換乘出站乘客百分比排行榜
ads_conn_ratio_day_top
【體現每條線的深圳通乘車卡普及程度 9.5 折優惠】 出站交易優惠人數百分比排行榜
ads_line_sale_ratio_top
【體現換乘的心酸】 換乘耗時最久的乘客排行榜
ads_conn_spend_time_top
【體現路線擁擠程度】 上車以後還沒下車,每分鐘、小時每條線線上人數
ads_on_line_min_top
3.3- 第三步:建庫建表計算指標
hdfs 關閉許可權檢查。hive 設定保存目錄 /warehouse;
hue 建立 hue 使用者,賦予超級組。hue 切換到 hue 使用者,執行 hive sql 建庫 szt;
庫下面建目錄 ods dwd dws ads;
上傳原始數據到 /warehouse/szt.db/ods/
szt-etl-data.csv szt-etl-data_2018-09-01.csv szt-page.jsons
檢視:
hdfs dfs -ls -h hdfs://cdh231:8020/warehouse/szt.db/ods/
接下來使用 HUE 按照
sql/hive.sql
依次執行 HQL 語句.....
也可以使用 IDEA Database 工具列操作,附送idea cdh hive 完美驅動 https://github.com/timveil/hive-jdbc-uber-jar/releases:
也可以使用 DBeaver (我只想說, 上古產品 Sqlyog、navicat、heidisql、workbench 全都是戰五渣),因為有時候復雜的查詢可以一邊執行一邊在另一個客戶端工具檢視結果,這對於復雜的巢狀查詢 debug 非常有助於分析和跟蹤問題。DBeaver 客戶端內建圖表,不過沒有 HUE 好看:
已經完成的指標分析:
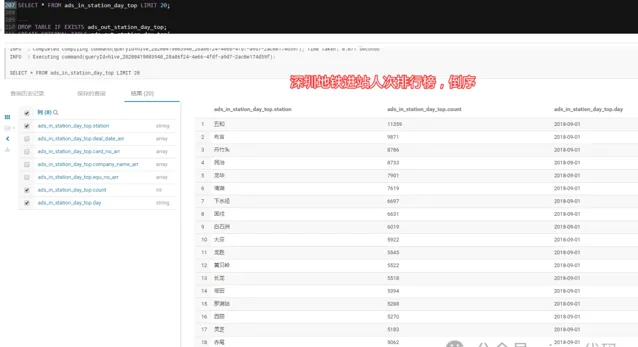
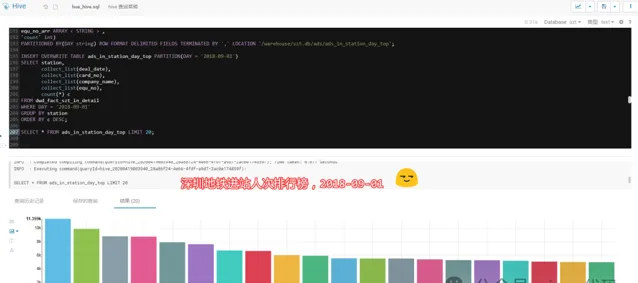
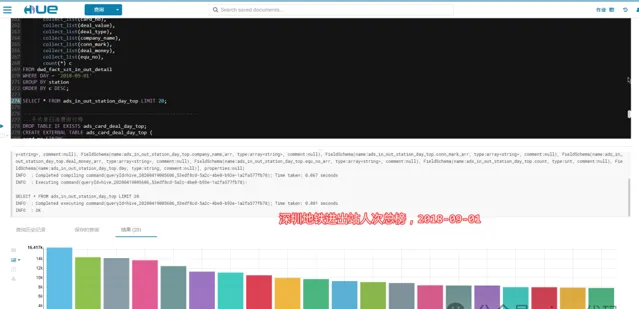
3.3.1 - 深圳地鐵進站人次排行榜:
2018-09-01,當天依次為:五和、布吉、丹竹頭,數據說明當天這幾個站點進站人數最多。
3.3.2 - 深圳地鐵出站人次排行榜:
2018-09-01,當天出站乘客主要去向分別為:深圳北高鐵站、羅湖火車站、福田口岸。
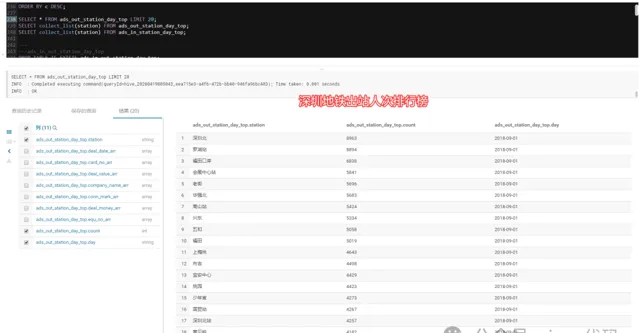
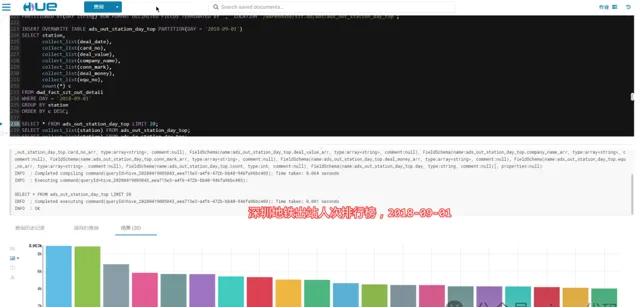
3.3.3- 深圳地鐵進出站總人次排行榜:
2018-09-01,當天車站吞吐量排行榜:
五和站???、布吉站(深圳東火車站)、羅湖站(深圳火車站)、深圳北(深圳北高鐵站)
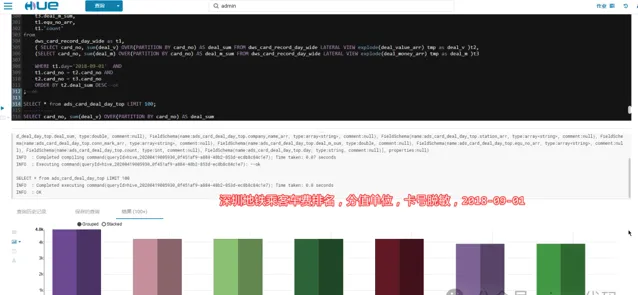
3.3.4- 深圳地鐵乘客車費排行榜:
2018-09-01,當天車費最高的乘客花了 48 元人民幣
🚄🚄🚄 說明:深圳通地鐵卡不記名,未涉及個人私密!!!
3.3.5- 深圳地鐵各路線單日發送旅客排行榜:
2018-09-01,當天五號線客運量遙遙領先,龍崗線碾壓一號線
3.3.6- 深圳地鐵每日運輸乘客最多的區間排行榜:
2018-09-01當天前三名分別是:赤尾>華強北,福民>福田口岸,五和>深圳北
3.3.7- 深圳地鐵每條路線單程直達乘客耗時平均值排行榜:
2018-09-01,當天五號線單程直達乘客平均耗時1500s,約合25分鐘,平均值最長的是 11號線,平均耗時 40 分鐘
3.3.8- 深圳地鐵所有乘客通勤時間平均值:
2018-09-01,當天所有乘客通勤時間平均值 1791 s,約合 30 分鐘
3.3.9- 深圳地鐵所有乘客通勤時間排行榜:
2018-09-01,當天所有乘客通勤時間排行榜,站內滯留最久的乘客間隔 17123 秒,約合 4.75 小時,實際情況只需要 20 分鐘車程
3.3.10- 深圳地鐵每個站點進出站閘機數量排行榜:
2018-09-01,當天福田站雙項第一
3.3.11- 深圳地鐵各路線進出站閘機數量排行榜:
2018-09-01,當天深圳地鐵一號線長臉了@_@,兩個指標都是第一,港鐵四號線全部墊底
3.3.12- 深圳地鐵各站收入排行榜:
2018-09-01,當天上午深圳北站收入 4 萬元人民幣,排名第一
3.3.12- 深圳地鐵各路線收入排行榜:
2018-09-01,數據顯示一號線依然是深圳地鐵最多收入的路線,1號線上午收入 30 萬元人民幣,其次是五號線緊隨其後
3.3.13- 深圳地鐵各路線換乘出站乘客百分比排行榜:
換乘後從五號線出來的乘客是占比最高的 15.6%,從九號線出站的乘客,換乘比例最低,僅 9.42%
3.3.14- 深圳地鐵各路線直達乘客優惠人次百分比排行榜:
目前可以確定的是,持有深圳通地鐵卡可以享受9.5折優惠乘坐地鐵,從統計結果看,2018-09-01當天,七號線使用地鐵卡優惠的乘客人次占比最高,達到 90.36%,排名最低的是五號線,占比 84.3%
3.3.15- 深圳地鐵換乘時間最久的乘客排行榜:
統計過程發現難以理解的現象,有幾個乘客進站以後,沒有刷卡出站就換乘了公交車,於是出現了同一個地鐵站進出站,但是標記為聯程的記錄
4- 新增模組:SZT-kafka-hbase
SZT-kafka-hbase project for Spring Boot2
看過開源的 spring-boot-starter-hbase、spring-data-hadoop-hbase,基礎依賴過於老舊,長期不更新;引入過程繁瑣,而且 API 粒度受限;資料庫連線沒有復用,導致資料庫服務讀寫成本太高。
於是自己實作了 hbase-2.1 + springboot-2.1.13 + kafka-2.0 的整合,一個長會話完成 hbase 連續的增刪改查,降低伺服器資源的開銷。
主要特色:
knife4j 線上偵錯,點選滑鼠即可完成 hbase 寫入和查詢,再也不用記住繁瑣的命令。
hbase 列族版本歷史設定為 10,支持配置檔級別的修改。可以查詢某卡號最近 10 次交易記錄。
hbase rowkey 設計為卡號反轉,使得字典排序過程消耗的伺服器算力在分布式環境更加均衡。
全自動的建庫建表【本計畫的 hbase 名稱空間為 szt】,實作冪等操作,無需擔心 hbase 資料庫的汙染。
效果展示:
準備部署完成的 hbase,適當修改本計畫配置檔,執行 SZT-kafka-hbase 計畫,效果如下:
啟動:
api-debug,隨便寫點東西進去,狂點發送。
hue-hbase 查表:
hue-hbase 檢視歷史版本:
hbase-shell 命令:
全表掃描,返回十個版本格式化為字串顯示
scan 'szt:data', {FORMATTER => 'toString',VERSIONS=>10
接下來接入 kafka
啟動
cn.java666.etlflink.app.Redis2Kafka
,生產訊息,適當調慢生產速度,以免機器崩潰。
不出意外的話,你會看到 SZT-kafka-hbase 計畫的控制台打印了日誌:
如果 hbase 崩潰了,看看記憶體夠不夠,我就直接懟上 2GB X 3 個節點
5-
SZT-flink
模組新增
cn.java666.etlflink.app.Json2HBase
實作了從 redis 或者其他資料來源取出 json 串,保存到 hbase 表。本計畫中從 redis 獲取 json(當然更推薦 kafka),透過 flink 清洗存到 hbase flink:flink2hbase 表中。用於即時保存深圳通刷卡記錄,透過卡號查詢可以獲取卡號最近10次(如果有10次)交易記錄。
valkeys= jsonObj.keySet().toList
valsize= keys.size()
for (i <-0 until size) {
valkey= keys.get(i)
valvalue= jsonObj.getStr(key)
putCell(card_no_re, cf, key, value)
}
6- 新增即時處理模組 SZT-flink
完成 flink 讀取 kafka,存到 clickhouse 功能。
原始碼下載地址:
https://github.com/geekyouth/SZT-bigdata.git
看到最後,如果這個計畫對你有用,一定要給我點個「 在看和贊 」。










