本文將分享一個Flink多維實分時析計畫,也是最近正在做的,覺得比較有價值,記錄一下,防止以後再次踩坑。主要涉及到的知識有 EventTime 和 ProcessTime 的使用、WaterMark 的使用、大數據量(一秒300MB)下維表 Join 的方案、定時器的使用、Flink DataStream 和 Flink Sql 的使用、Flink 任務調優等,幹貨多多!
一、需求背景
按照國際慣例,先說一下需求吧,由於需求涉及的維度比較多,實際情況比較復雜,這裏就以最簡單的一個維度來說吧,便於理解。
1. 數據來源
① 主數據來源於 kafka
② 維度數據來自於 Hive
2. 數據格式
① kafka 數據
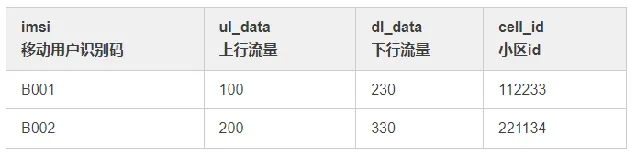
② 小區維表
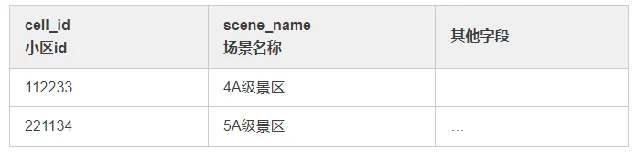
3. 輸出結果
要求每5分鐘統計一次使用者數和流量(上行流量 + 下行流量),維度為scene_name,要求結果如下表:
4. 需求解讀
從以上資訊可以得出,這個需求的意圖是:用 kafka 數據作為主流,關聯小區維表,根據場景維度分組,計算 uv 和 flow_data。
需要註意的一點是維表會非週期性更新,並不是一成不變的。
二、實作過程
拿到這個需求,首先想到的就是使用 look up join 維表,直接一個 SQL 就完事,然而過程並不像我們預料的這麽簡單。
由於計畫歷史問題,本次使用的Flink 版本為1.10,本次將分別使用 EventTime 和 ProcessingTime 兩種時間語意來完成這個需求。
1. 使用異步 Join
首先考慮使用 Flink SQL 基於 EventTime 來做這個需求,由於維表存在於 Hive 中,這裏直接查詢 Presto,效率會比較高,維表關聯使用的是 AsyncDataStream.unorderedWait 異步 join,用 Redis 做緩存,大體程式碼如下:
publicstaticvoid main(String[] args) throws Exception {// 設定時間語意為processTime env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime); FlinkKafkaConsumer<String> fkc = KafkaUtil.getKafkaSource(source_topic, "source_group");// 讀取kafka數據流 SingleOutputStreamOperator<String> sourceDs = env.addSource(fkc).name(source_topic + "_source");// 解析kafka數據 SingleOutputStreamOperator<SourceDpiHttp> mapDs = sourceDs.flatMap(new MultipleMessageParser(net_type)).name("multiple_message_parser");// 關聯小區場景維度表 SingleOutputStreamOperator<SourceDpiHttp> cellDimDs = AsyncDataStream.unorderedWait(mapDs, new DimAsyncFunction<SourceDpiHttp>(DataSourceType.PRESTO.name(), DIM_GZDP_XUNQI_CELL) {@SuppressWarnings("unchecked")@Overridepublic Tuple2<String, String>[] getJoinCondition(SourceDpiHttp obj) { Tuple2<String, String> tuple2 = Tuple2.of("id", String.valueOf(obj.getCellId()));returnnew Tuple2[]{tuple2}; }@Overridepublicvoid join(SourceDpiHttp model, JSONObject dimInfo) { model.setSceneName(dimInfo.getString("scene_name")); model.setCellName(dimInfo.getString("cell_name")); model.setCellType(dimInfo.getString("cell_type")); } }, 60, TimeUnit.SECONDS).name("cell_dim_join");// 設定waterMark時間欄位和視窗大小// 此處使用當前時間作為eventTime SingleOutputStreamOperator<SourceDpiHttp> wmStream = cellDimDs .assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks<SourceDpiHttp>() {private Long currentMaxTimestamp = 0L;@Overridepublic Watermark getCurrentWatermark() {// 最大允許的訊息延遲是0秒 Long maxOutOfOrderNess = 0L;returnnew Watermark(currentMaxTimestamp - maxOutOfOrderNess); }@Overridepublic long extractTimestamp(SourceDpiHttp item, long l) { long timestamp = 0; currentMaxTimestamp = Math.max(item.getEndTime(), currentMaxTimestamp);return timestamp; } }).name("window_setting");// 將流轉換為table Table table = tableEnv.fromDataStream(wmStream, "imsi,ulData,dlData,localCity,roamingType,cellId,cellName,sceneName,cellType,regionName,netType,rowtime.rowtime");// 計算場景維度String scene_sql = "select \n" +" TUMBLE_START(rowtime, INTERVAL '" + window_size + "' SECOND) AS windowStart, \n" +" netType, " +" '' as dateTime,\n" +" sceneName,\n" +" count(distinct imsi) as userCnt,\n" +" (sum(dlData)+sum(ulData)) as flowData\n" +"from " + table + "\n" +"GROUP BY \n" +" TUMBLE(rowtime, INTERVAL '" + window_size + "' SECOND), \n" +" netType,\n" +" sceneName\n"; Table result_scene = tableEnv.sqlQuery(scene_sql);// 型別轉換對映 TypeInformation<CaSceneResult> sceneTypes = new TypeHint<CaSceneResult>() { }.getTypeInfo();// 將table轉換為流並輸出結果到kafka SingleOutputStreamOperator<String> sceneMapDs = tableEnv .toAppendStream(result_scene, sceneTypes) .map(new SceneDateTimeParser()).name(sinkTopic_scene + "_transfer"); sceneMapDs.addSink(KafkaUtil.getKafkaSink(sinkTopic_scene)).name(sinkTopic_cell + "_sink"); env.execute("main_cell_job");}
這種方案看似很合理,其實存在一些問題:
① 由於是異步 join,需要資料來源支持異步操作 ,如果不支持需要用使用多執行緒模擬異步操作,如果操作不當會出現並行問題以及對資源的濫用。
② 會對 presto 造成很大的壓力 。
③ 上線會發現時區有問題 ,而且不是差8小時,很是疑惑。如果差8小時,可以在分配 waterMark 的時候主動加上8小時,不過不贊成這種做法,這種是沒有科學依據的,可能跟 Flink 版本有關系吧,在 Flink 社群也有人提到過這個問題,目前貌似並沒有好的解決辦法。
於是出現了第二種方案:
2. 使用廣播流
這種方案也是采用了 Flink SQL 來實作,這種和第一種一樣,也存在時區的問題。
唯一的區別就是將 Presto 數據轉為廣播流,定時廣播到子任務中。
這裏就不貼程式碼了,基本沒有解決上述提到的問題,僅僅作為 join 的一種方案吧,也算是練了個手。
3. 使用外掛程式
單獨寫一個程式,定時去將 Presto 的數據讀取到 Redis 中,在 FlatMap 階段,直接查詢 Redis 做維表關聯,並且還做了一層 Guava 緩存。
這種方案解決了 Presto 壓力大的問題。因為這裏仍然用的是 Flink SQL,因此時區問題仍然沒有得到解決。
4. 使用 DataStream
為了解決時區問題,放棄了 Flink SQL 的寫法,而是改用 DataStream,自己寫程式碼來實作聚合指標,這次仍然使用的是 EventTime,大概程式碼如下:
publicstaticvoid main(String[] args) throws Exception {// 設定時間語意為eventTime env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); FlinkKafkaConsumer<String> fkc = KafkaUtil.getKafkaSource(source_topic, consumerGroup);// 讀取kafka數據流 SingleOutputStreamOperator<String> sourceDs = env.addSource(fkc).name(source_topic + "_source").setParallelism(parallelism);// 解析kafka數據 SingleOutputStreamOperator<SourceDpiHttp> mapDs = sourceDs.flatMap(new MultipleMessageParser()).setParallelism(parallelism).name("multiple_message_parser");// 設定waterMark時間欄位和視窗大小 SingleOutputStreamOperator<SourceDpiHttp> wmStream = mapDs .assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks<SourceDpiHttp>() {private Long currentMaxTimestamp = 0L;@Overridepublic Watermark getCurrentWatermark() {// 最大允許的訊息延遲是0秒 Long maxOutOfOrderNess = waterMark * 1000;returnnew Watermark(currentMaxTimestamp - maxOutOfOrderNess); }@Overridepublic long extractTimestamp(SourceDpiHttp item, long l) { long timestamp = item.getEndTime(); currentMaxTimestamp = Math.max(timestamp, currentMaxTimestamp);return timestamp; } }).name("water_mark");// 計算場景維度 SingleOutputStreamOperator<String> sceneResultStream = wmStream. .keyBy((KeySelector<SourceDpiHttp, String>) SourceDpiHttp::getSceneName) .window(TumblingEventTimeWindows.of(Time.minutes(5))) .process(new ProcessWindowFunction<SourceDpiHttp, String, String, TimeWindow>() {@Overridepublicvoid process(String sceneKey, ProcessWindowFunction<SourceDpiHttp, String, String, TimeWindow>.Context context, Iterable<SourceDpiHttp> iterable, Collector<String> collector) throws Exception {try { long flowData = 0; Set<String> uvSet = new HashSet<>(); long windowEnd = context.window().getEnd();for (SourceDpiHttp sourceDpiHttp : iterable) { flowData += (sourceDpiHttp.getDlData() + sourceDpiHttp.getUlData()); uvSet.add(sourceDpiHttp.getImsi()); } CaSceneResult result = new CaSceneResult(); result.setDateTime(new SimpleDateFormat("yyyyMMddHHmm").format(windowEnd)); result.setNetType(netType); result.setSceneName(sceneKey); result.setUserCnt((long) uvSet.size()); result.setFlowData(flowData); collector.collect(JSON.toJSONString(result)); } catch (Exception e) { logger.error("場景維度計算出錯:", e); } } }); sceneResultStream.addSink(KafkaUtil.getKafkaSink(sinkTopic)).name(sinkTopic + "_sink").setParallelism(sinkParallelism); env.execute("main_cell_job");}
這種方式既解決了 Presto 的壓力,也解決了時區的問題(因為沒有使用Flink SQL了,也就不存在時區的問題了)。
5. 使用 ProcessTime + 定時器
這種方案沒有使用視窗,而是使用了定時器來實作5分鐘數據統計,想象是美好的,現實是殘酷的,這裏忘記了在使用定時器時,其實是對每一個元素都設定了一個5分鐘的定時,導致數據並不是按照我們預期的那樣每5分鐘統計一次,這裏僅僅貼出定時器的程式碼吧,這個場景不適用於定時器,僅僅作為學習吧。
public classSceneKeyedProcessFunctionextendsKeyedProcessFunction<String, SourceDpiHttp, String> {privatestaticfinal Logger logger = LoggerFactory.getLogger(SceneKeyedProcessFunction. class);privatetransient ValueState<Long> flowDataState;privatetransient ValueState<List<String>> userCntState;privatetransient ValueState<Boolean> timerRegisteredState;privatefinal String netType;privatefinal Integer windowSize;publicSceneKeyedProcessFunction(String netType, Integer windowSize){this.netType = netType;this.windowSize = windowSize; }@Overridepublicvoidopen(Configuration parameters)throws Exception { flowDataState = getRuntimeContext().getState(new ValueStateDescriptor<>("flowData", Types.LONG)); userCntState = getRuntimeContext().getState(new ValueStateDescriptor<>("userCnt", Types.LIST(Types.STRING))); timerRegisteredState = getRuntimeContext().getState(new ValueStateDescriptor<>("timerRegistered", Types.BOOLEAN)); }@OverridepublicvoidprocessElement(SourceDpiHttp sourceDpiHttp, KeyedProcessFunction<String, SourceDpiHttp, String>.Context ctx, Collector<String> out)throws Exception {try { Long flowData = flowDataState.value(); List<String> userCnt = userCntState.value();// 如果視窗內數據的和為null,表示第一次處理,初始化為0if (flowData == null) { flowData = 0L; }if (ObjectUtils.isEmpty(userCnt)) { userCnt = new ArrayList<>(); } userCnt.add(sourceDpiHttp.getImsi()); userCntState.update(userCnt);if (!"VOLTE".equalsIgnoreCase(netType) && ObjectUtils.isNotEmpty(sourceDpiHttp.getDlData()) && ObjectUtils.isNotEmpty(sourceDpiHttp.getUlData())) {// 更新視窗內數據的和 flowData += (sourceDpiHttp.getDlData() + sourceDpiHttp.getUlData()); flowDataState.update(flowData); }// 註冊5分鐘後的定時器 Boolean timerRegistered = timerRegisteredState.value();if (timerRegistered == null || !timerRegistered) { ctx.timerService().registerProcessingTimeTimer(ctx.timerService().currentProcessingTime() + windowSize * 60 * 1000); timerRegisteredState.update(true); } } catch (Exception e) { logger.error("小區維度計算出錯:{}", e, e); } }@OverridepublicvoidonTimer(long timestamp, OnTimerContext ctx, Collector<String> out)throws Exception { String sceneKey = ctx.getCurrentKey(); Long flowData = flowDataState.value(); Set<String> userCnt = new HashSet<>();if (ObjectUtils.isNotEmpty(userCntState) && ObjectUtils.isNotEmpty(userCntState.value())) { userCnt = new HashSet<>(userCntState.value()); } CaSceneResult result = new CaSceneResult(); result.setDateTime(new SimpleDateFormat("yyyyMMddHHmm").format(timestamp)); result.setNetType(netType); result.setSceneName(sceneKey); result.setUserCnt((long) userCnt.size()); result.setFlowData(flowData);// 輸出統計數據 out.collect(JSON.toJSONString(result));// 清除當前狀態 clearState(); ctx.timerService().deleteProcessingTimeTimer(timestamp); timerRegisteredState.update(false); }@Overridepublicvoidclose()throws Exception {super.close(); }publicvoidclearState(){if (Objects.nonNull(flowDataState)) { flowDataState.clear(); }if (Objects.nonNull(userCntState)) { userCntState.clear(); } }}
6. 使用 ProcessTime + 滑動視窗
這裏直接使用 ProcessTime 對應的滑動視窗實作,大體程式碼如下:
publicstaticvoid main() throws Exception {// 設定時間語意為processTime env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime); FlinkKafkaConsumer<String> fkc = KafkaUtil.getKafkaSource(source_topic, consumerGroup);// 讀取kafka數據流 SingleOutputStreamOperator<String> sourceDs = env.addSource(fkc).name(source_topic + "_source").setParallelism(parallelism);// 解析kafka數據 SingleOutputStreamOperator<SourceDpiHttp> mapDs = sourceDs.flatMap(new MultipleMessageParser()).setParallelism(parallelism).name("multiple_message_parser");// 計算場景維度 SingleOutputStreamOperator<String> sceneResultStream = mapDs.filter((FilterFunction<SourceDpiHttp>) item -> ObjectUtils.isNotEmpty(item.getSceneName()) && !"000000".equals(item.getSceneName())) .keyBy((KeySelector<SourceDpiHttp, String>) SourceDpiHttp::getSceneName) .window(TumblingProcessingTimeWindows.of(Time.minutes(windowSize))) .apply(new WindowFunction<SourceDpiHttp, String, String, TimeWindow>() {@Overridepublicvoid apply(String sceneKey, TimeWindow window, Iterable<SourceDpiHttp> input, Collector<String> out) throws Exception {try { long flowData = 0; Set<String> uvSet = new HashSet<>(); long windowEnd = window.getEnd();for (SourceDpiHttp sourceDpiHttp : input) { flowData += (sourceDpiHttp.getDlData() + sourceDpiHttp.getUlData()); uvSet.add(sourceDpiHttp.getImsi()); } CaSceneResult result = new CaSceneResult(); result.setDateTime(new SimpleDateFormat("yyyyMMddHHmm").format(windowEnd)); result.setNetType(netType); result.setSceneName(sceneKey); result.setUserCnt((long) uvSet.size()); result.setFlowData(flowData); out.collect(JSON.toJSONString(result)); } catch (Exception e) { logger.error("場景維度計算出錯:", e); } } }); sceneResultStream.addSink(KafkaUtil.getKafkaSink(sink_kafka_server, sinkTopic_scene)).name(sinkTopic_scene + "_sink").setParallelism(sinkParallelism); env.execute("main_cell_job");}
三、調優部份
透過之前的分析,最終方案4和方案6是滿足要求的,接下來要做的工作就是調優了,畢竟程式碼寫完了,還得保證正常執行起來。總結一下,調優大概分為這幾部份:
1. checkpoint 調優
由於數據量比較大,1秒鐘 300MB 左右的數據,所以直接禁用了 checkpoint,因為資料來源是 kafka,所以任務異常重新開機時會繼續消費上次的 offset,所以去掉會提升一部份效能。
2. 設定合適的重試策略
當網路原因等異常因素參與進來時,我們很難保障自己的程式能夠穩定執行,萬一程式異常重新開機了,不能讓他直接掛掉,除非你有很強的監控,掛了立馬能感知到,所以設定合理的任務重新開機策略是很重要的。
3. 調整並列度
針對不同的算子,設定不同的並列度,比如開窗,做ETL都是比較耗時的操作,可以將並列度設定大一點,source並列度可以設定和kafka分區數一致或者一半,sink並列度可以設定小一點,因為聚合之後,數據量會很小,不需要太大的並列度。
當然並列度的調整也可以參考 Flink 的反壓情況。
4. 調整 task manager 的記憶體
適當的增加 task manager 記憶體是很有必要的,不然可能數據量大的時候很容易造成 OOM,同時也要調整 slot 的數量,充分利用 task manager 的並列能力。
5. 調整 WaterMark
如果使用了 EventTime,可以適當的調整亂序大小,防止數據遺失。
6. 調整 kafka 參數
適當的調整 kafka consumer 參數,比如拉取的批次大小,拉取的數據量大小。
四、寫在最後
本篇文章透過實際操作 Flink,介紹了 Flink 的一些核心功能的用法,其中也踩了不少坑,當然踩得坑不僅僅是文中提到的,實際遇到的問題很多,一時想不起來了,但是只要耐心,一定能解決的,比如 kafka 分區壞了,數據為啥少了等問題。
總之,一定要看日誌,不能靠瞎猜。當然了,他人的指點和幫助也很重要,遇到解決不了的問題要勇於向他人請教。
如果你看完本文還有問題的話,歡迎隨時評論區交流。
作者丨毛毛小妖
來源丨公眾號:毛毛小妖的筆記(ID:eyeamoons)
dbaplus社群歡迎廣大技術人員投稿,投稿信箱: [email protected]












