大家好,我是哪咤。
一、前情提要
在上一篇文章中提到,有一個頁面載入速度很慢,是透過緩沖流最佳化的。
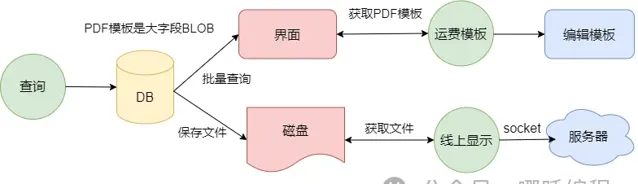
查詢的時候,會存取後台資料庫,查詢前20條數據,按道理來說,這應該很快才對。
追蹤程式碼,看看啥問題,最後發現問題有三:
表中有一個BLOB大欄位,儲存著一個PDF樣版,也就是上圖中的運費樣版;
查詢後會將這個PDF樣版儲存到本地磁盤
點選線上顯示,會讀取原生的PDF樣版,透過socket傳到伺服器。
大欄位批次查詢、批次檔落地、讀取大檔並進行網路傳輸,不慢才怪,這一頓騷操作,5秒能載入完畢,已經燒高香了。
經過4次最佳化,將頁面的載入時間控制在了1秒以內,實打實的提升了程式的秒開率。
批次查詢時,不查詢BLOB大欄位;
點選運費查詢時,單獨查詢+觸發索引,實作「懶載入」;
異步儲存檔
透過 緩沖流 -> 記憶體對映技術mmap -> sendFile零拷貝 讀取本地檔;

有一個小夥伴在評論中提到,還可以透過緩存繼續最佳化,確實是可以的,緩存也是復用最佳化的一種。
為了提高頁面的載入速度,使用了單條查詢 + 觸發索引,提高資料庫查詢速度。
歸根結底,還是查詢了資料庫,如果不查呢,存取速度肯定會更快。
這個時候,就用到了緩存,將運費樣版存到緩存中。
國內直接使用ChatGPT4o:
用官方一半價格的錢,用跟官方 ChatGPT4.0 一模一樣功能的工具。
國內直接使用 ChatGPT4o :
無需魔法,同時支持電腦、手機,瀏覽器直接使用
ChatGPT3.5永久免費
支持 Chat GPT-4o文本對話、 Copi lot編程、DALL-E AI繪畫、AI語音對話、論文外掛程式Consensus等
長按辨識下方二維碼,備註ai, 發給你


二、先了解一下,什麽是緩存
緩存 就是把存取量較高的熱點數據從傳統的關系型資料庫中載入到記憶體中,當使用者再次存取熱點數據時,是從記憶體中載入,減少了對資料庫的存取量,解決了高並行場景下容易造成資料庫宕機的問題。
我理解的緩存的本質就是一個用空間換時間的一個思想。
提供「緩存」的目的是為了讓數據存取的速度適應CPU的處理速度,其基於的原理是記憶體中「局部性原理」。
CPU 緩存的是記憶體數據,用於解決 CPU 處理速度和記憶體不匹配的問題,比如處理器和記憶體之間的快取,作業系統在記憶體管理上,針對虛擬記憶體 為頁表項使用了一特殊的快取TLB轉換檢測緩沖區,因為每個虛擬記憶體存取會引起兩次物理存取,一次取相關的頁表項,一次取數據,TLB引入來加速虛擬地址到實體位址的轉換。
1、緩存有哪些分類
作業系統磁盤緩存,減少磁盤機械操作
資料庫緩存,減少檔案系統 I/O
應用程式緩存,減少對資料庫的查詢
Web 伺服器緩存,減少應用程式伺服器請求
客戶端瀏覽器緩存,減少對網站的存取
2、本地緩存與分布式緩存
本地緩存 :在客戶端原生的實體記憶體中劃出一部份空間,來緩存客戶端回寫到伺服器的數據。當本地回寫緩存達到緩存閾值時,將數據寫入到伺服器中。
本地緩存是指程式級別的緩存元件,它的特點是本地緩存和應用程式會執行在同一個行程中,所以本地緩存的操作會非常快,因為在同一個行程內也意味著不會有網路上的延遲和開銷。
本地緩存適用於單節點非集群的套用場景,它的優點是快,缺點是多程式無法共享緩存。
無法共享緩存可能會造成系統資源的浪費,每個系統都單獨維護了一份屬於自己的緩存,而同一份緩存有可能被多個系統單獨進行儲存,從而浪費了系統資源。
分布式緩存 是指將套用系統和緩存元件進行分離的緩存機制,這樣多個套用系統就可以共享一套緩存數據了,它的特點是共享緩存服務和可集群部署,為緩存系統提供了高可用的執行環境,以及緩存共享的程式執行機制。
下面介紹一個小編最常用的本地緩存 Guava Cache。
三、Guava Cache本地緩存
1、Google Guava
Google Guava是一個Java編程庫,其中包含了許多高品質的工具類和方法。其中,Guava的緩存工具之一是LoadingCache。LoadingCache是一個帶有自動載入功能的緩存,可以自動載入緩存中不存在的數據。其實質是一個鍵值對(Key-Value Pair)的緩存,可以使用鍵來獲取相應的值。
Guava Cache 的架構設計靈感來源於 ConcurrentHashMap,它使用了多個 segments 方式的細粒度鎖,在保證執行緒安全的同時,支持了高並行的使用場景。Guava Cache 類似於 Map 集合的方式對鍵值對進行操作,只不過多了過期淘汰等處理邏輯。
Guava Cache對比ConcurrentHashMap優勢在哪?
Guava Cache可以設定過期時間,提供數據過多時的淘汰機制;
執行緒安全,支持並行讀寫;
在緩存擊穿時,GuavaCache 可以使用 CacheLoader 的load 方法控制,對同一個key,只允許一個請求去讀源並回填緩存,其他請求阻塞等待;
2、Loadingcache數據結構
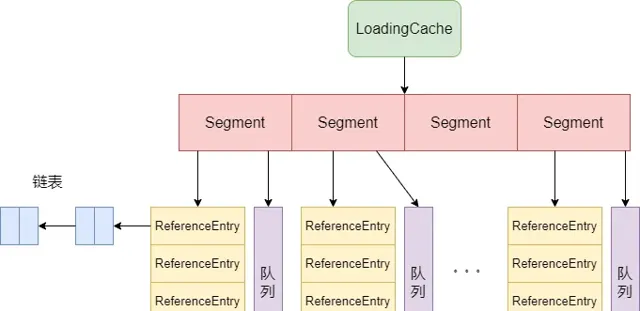
Loadingcache含有多個Segment,每一個Segment中有若幹個有效佇列;
多個Segment之間互不打擾,可以並行執行;
各個Segment的擴容只需要擴自己,與其它的Segment無關;
設定合適的初始化容量與並行水平參數,可以有效避免擴容,但是設定的太大了,耗費記憶體,設定的太小,緩存價值降低,需要根據業務需求進行權衡;
Loadingcache數據結構和ConcurrentHashMap很相似,ReferenceEntry用於存放key-value;
每一個ReferenceEntry都會存放一個雙向連結串列,采用的是Entry替換的方式;
每次存取某個元素就將元素移動到連結串列頭部,這樣連結串列尾部的元素就是最近最少使用的元素,替換的復雜度為o(1),但是存取的復雜度還是O(n);
佇列用於實作LRU緩存回收演算法;
3、Loadingcache數據結構構建流程:
初始化CacheBuilder,指定參數(並行級別、過期時間、初始容量、緩存最大容量),使用build()方法建立LocalCache例項;
建立Segment陣列,初始化每一個Segment;
為Segment內容賦值;
初始化Segment中的table,即一個ReferenceEntry陣列(每一個key-value就是一個ReferenceEntry);
根據之前類變量的賦值情況,建立相應佇列,用於LRU緩存回收演算法。
4、判斷緩存是否過期
expireAfterWrite,在put時更新緩存時間戳,在get時如果發現當前時間與時間戳的差值大於過期時間戳,就會進行load操作;
expireAfterAccess,在expireAfterWrite的基礎上,不管是寫還是讀都會記錄新的時間戳;
refreshAfterWrite,呼叫get進行值的獲取的時候才會執行reload操作,這裏的重新整理操作可以透過異步呼叫load實作。
5、Loadingcache如何解決緩存穿透
緩存穿透是指在Loadingcache緩存中,由於某些原因,緩存的數據無法被正常存取或處理,導致緩存失去了它的作用。
發生緩存穿透的原因有很多,比如數據量過大、數據更新頻繁、數據過期、數據許可權限制、緩存效能瓶頸等原因,這裏不過多糾結。
(1)expireAfterAcess和expireAfterWrite同步載入
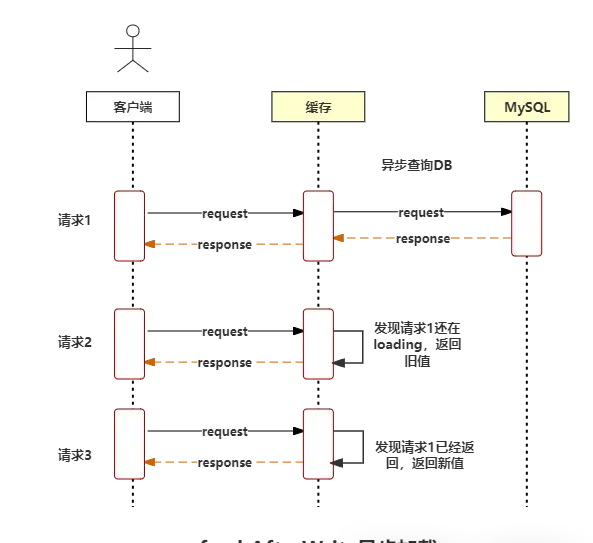
設定為expireAfterAcess和expireAfterWrite時,在進行get的過程中,緩存失效的話,會進行load操作,load是一個同步載入的操作,如下圖:
如果發生了緩存穿透,當有大量並行請求存取緩存時,會有一個執行緒去同步查詢DB,隨即透過reeatrantLock進入loading等待狀態,其它請求相同key的執行緒,一部份在waitforvalue,另一部份在reentantloack的阻塞佇列中,等待同步查詢完畢,所有請求都會獲得最新值。

(2)refreshAfterWrite同步載入
如果采用refresh的話,會透過scheduleRefresh方法進行load,也是一個執行緒同步獲取DB。
其它執行緒不會阻塞,效能比expireAfterWrite同步載入高,但是,可能返回新值、也可能返回舊值。

(3)refreshAfterWrite異步載入
當載入緩存的執行緒是異步載入的話,對於請求1,如果在異步結束前返回,就會返回舊值,反之是新值。
對於其他執行緒來說,不會被阻塞,直接返回,返回值可能是新值或者是舊值。
Loadingcache沒使用額外的執行緒去做定時清理和載入的功能,而是依賴於get()請求。
在查詢的時候,進行時間對比,如果使用refreshAfterWrite,在長時間沒有查詢時,查詢有可能會得到一個舊值,我們可以透過設定refreshAfterWrite(寫重新整理,在get時可以同步或異步緩存的時間戳)為5s,將expireAfterWrite(寫過期,在put時更新緩存的時間戳)設為10s,當存取頻繁的時候,會在每5秒都進行refresh,而當超過10s沒有存取,下一次存取必須load新值。
四、Redis中如何解決緩存穿透
如果發生了緩存穿透,可以針對要查詢的數據,在Redis中插入一條數據,添加一個約定好的預設值,比如defaultNull。
比如你想透過某個id查詢某某訂單,Redis中沒有,MySQL中也沒有,此時,就可以在Redis中插入一條,存為defaultNull,下次再查詢就有了,因為是提前約定好的,前端也明白是啥意思,一切OK,歲月靜好。
五、使用loadingCache最佳化頁面載入
1、引入pom
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.0.1-jre</version>
</dependency>
2、初始化LoadingCache
privatestatic LoadingCache<String, String> loadCache;
publicstaticvoidinitLoadingCache(){
loadCache = CacheBuilder.newBuilder()
// 並行級別設定為 10,是指可以同時寫緩存的執行緒數
.concurrencyLevel(10)
// 寫重新整理,在get時可以同步或異步緩存的時間戳
.refreshAfterWrite(5, TimeUnit.SECONDS)
// 寫過期,在put時更新緩存的時間戳
.expireAfterWrite(10, TimeUnit.SECONDS)
// 設定緩存容器的初始容量為 10
.initialCapacity(10)
// 設定緩存最大容量為 100,超過之後就會按照 LRU 演算法移除緩存項
.maximumSize(100)
// 設定要統計緩存的命中率
.recordStats()
// 指定 CacheLoader,緩存不存在時,可自動載入緩存
.build(new CacheLoader<String, String>() {
@Override
public String load(String key)throws Exception {
// 自動載入緩存的業務
return"error";
}
}
);
}
3、最佳化5:透過LoadingCache緩存樣版數據,在編輯樣版後,更新緩存
查詢樣版資訊後,透過
loadCache.put(uuid, pdf);
載入到記憶體中,在編輯樣版時,更新緩存過期時間,下次獲取樣版PDF時,直接從LoadingCache緩存中取,降低資料庫存取壓力,perfect!!!

然並卵,這種情況是不適合緩存的,因為樣版pdf本來就是一個BLOB大數據,你把它放記憶體裏緩存了,你告訴我,能放幾個?記憶體扛得住嗎?
最佳化炫技一時爽,BUG不斷一直爽,一直爽
·················END·················
用官方一半價格的錢,用跟官方 ChatGPT4.0 一模一樣功能的工具。
國內直接使用ChatGPT4o:
無需魔法,同時支持手機、電腦,瀏覽器直接使用
帳號獨享
ChatGPT3.5永久免費
長按辨識下方二維碼,備註ai,發給你
回復gpt,獲取ChatGPT4o直接使用地址
點選閱讀原文,國內直接使用ChatGpt4o










