寫在最前
文中所提及的事件並不僅限於故障,還包括運維工作中的告警、異常等。
"An incident is an unplanned interruption to an IT Service or a reduction in the Quality of an IT Service." Source: Incident Management -ITIL
一、背景
在【 】一文中,我們探討了AIOps在異常檢測的實踐。Horae( 美團AIOps平台 )在單時序異常檢測方面已有較多積累,智慧告警功能作為底層能力支撐了監控系統和異常檢測場景。服務運維團隊在此基礎上開展AIOps在事件管理領域的相關工作,本文主要分享過去兩年的探索與實踐,希望能對大家有所幫助或啟發。
事件管理的復雜性體現在兩個方面:
1.數據繁多
數據多樣化: 運維工作需要各種型別的數據來辨識、診斷、處理問題,包括告警、鏈路、指標、日誌、變更( 含發版 )等。
數據即時性強、關系復雜: 運維數據通常需要即時采集和處理。這些數據之間的關系錯綜復雜,如鏈路數據與告警數據、指標數據與日誌數據等可能存在密切的關聯,需要精細的統一處理。
領域知識強: 運維領域涉及的知識廣泛,包括網路、硬體、系統、資料庫、套用等多個層面,業務運維更需要不同的領域知識,這對運維人員和運維工具提出了較高的要求。
2.流程復雜
事件管理的時間線如下,每個環節都需要提效才能達成事件管理的效率提升。
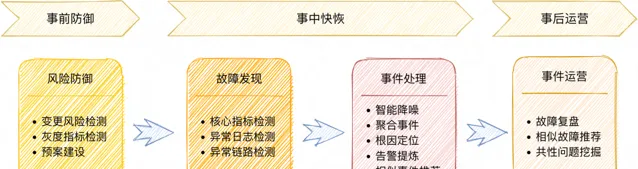
面對上述挑戰,美團運維團隊在過去幾年建設了豐富的工具體系,基於專家經驗、規則配置、流程管控等方式進行事件管理。本文聚焦的AIOps實踐,是對上述工作的賦能,可拆解為四個模組:
風險預防——變更風險智慧檢測: 以使用者和實體為物件,結合規則以及機器學習模型,對使用者行為進行分析和異常檢測。
故障發現——智慧辨識指標異常: 基於統計演算法和機器學習演算法辨識指標的異常模式,幫助使用者快速發現故障。
事件處理——診斷和預案推薦: 透過多模態數據和演算法規則引擎來幫助使用者快速定位故障,推薦止損預案。
事件營運——相似故障推薦: 基於NLP技術推薦相似故障復盤,挖掘共性問題。
二、事件管理中AI能力總覽
AIOps在事件管理領域中的能力框架如下:

圖2 AIOps事件管理領域能力框架
三、AIOps之事件管理場景
1.事前預防
1)風險辨識
變更檢測分成前、中、後三個階段。變更前風險預警的收益相對較高,因為它能夠攔截異常的發生。但由於變更動作尚未發生,變更前檢查所能獲取到的參考資訊少,檢測難度比較大。變更中、後檢測可以參考灰度組的變化情況以及是否有異常指標的出現,檢測的參考資訊更多,準確度更高。我們和MCM-線上變更管理平台( 美團變更管控系統,後文簡稱MCM )合作,共同探索了對變更前、變更中和變更後的一些異常進行檢測與辨識。
① 變更前
配置變更風險的檢測和辨識。當使用者進行配置變更時,我們會進行配置項變更風險檢查。我們根據該配置項的歷史合法變更資料探勘出該配置項的約束規則,對當前變更值進行風險檢測。約束項包括結構文本合法性、分隔符合法性、前後結構一致性等風險規則。
② 變更中/後
當灰度變更時部份系統指標會變化,比如集群中灰度機器的QPS、4XX、5XX指標可能會因為變更發生變化。系統需要辨識出因為錯誤變更而導致的異常,遮蔽灰度變更影響導致的異常。
我們需要註意,如果直接采用全量未變更分組進行參考組對待檢測組進行異常辨識,會有一些幹擾和雜訊。同一個集群的機器會由於自身配置、承載流量任務等差異,其機器指標會產生出不同的分布和聚類情況。將實際差異較大的機器指標作為參考組,會幹擾異常檢測的結果。因此,我們需要篩選出和待檢測指標相近的數據作為參考組,再在類內距離較近的多指標數據中辨識出該指標是否符合正常模式。
以灰度變更組的數據為待檢測數據點,以未變更組時序數據、變更歷史時序數據作為參考組進行異常辨識。演算法思路如下:
剔除參考數據的離群序列: 找到和檢測數據相近的參考組,再做異常檢測。我們使用最佳化後的自適應DBSCAN[1]進行聚類,排除參考組的離群時序序列。
檢測待檢測數據是否異常: 辨識待檢測的時序數據在參考組中是否存在異常情況,包括點異常、上下文異常、子序列模式異常等異常特征。
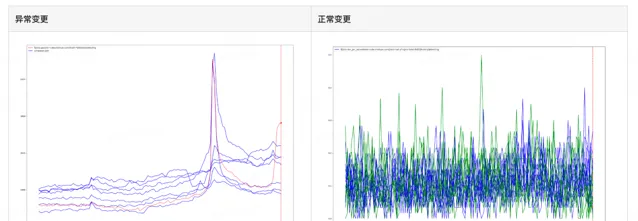
表1 異常集群變更 vs 正常集群變更
該功能已經上線到MCM,用於某核心平台系統集群變化後的變更復檢。檢測效果效果如下:
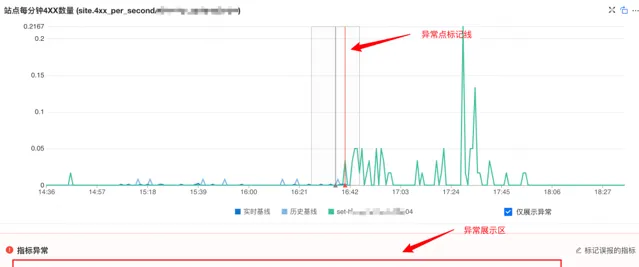
當使用者進行集群變更時,會觸發集群維度和機器維度的變更檢查,辨識核心指標(QPS、4XX、5XX)是否有一些異常。當指標中存在異常時,指標數據詳細展示區會有額外展示:
異常點標記線: 檢測異常的時間點上會有紅色的豎線標記。
異常項詳細展示區: 詳細展示出檢測到異常的伺服器主機名、時間點、指標值、與比對基線的偏離情況。
標記誤報按鈕: 如果發現異常為誤報,可以點選按鈕進行標記,便於後期演算法復盤最佳化。
2.事中快恢
當故障事件發生後,需要盡可能降低服務的異常對其他使用者的影響,提升服務的可用性。可以從MTTD( 平均檢測時間 )、MTTT( 最短定位時間 )、MTTR( 平均修復時間 )這三個指標入手。

1)異常發現
故障發現需要快速、準確。為避免誤報,服務運維團隊開發了一種基於歷史上鄰近的點分布相似( 時序特征相似 )思想的智慧異常檢測演算法。如果當前待檢測點相較其他歷史參考點相對異常( 存在點異常或者模式異常 ),檢測流程會將異常點辨識出來,並告知使用者待測指標出現異常現象。
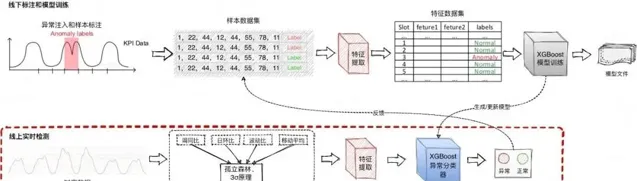
圖5 異常發現能力流程圖
在進行即時檢測流程中,待檢測點會先進入預檢測流程。預檢測元件會攔截絕大多數正常點,而當預檢測異常時,才會執行特征提取階段,進入模型異常分類;同分時類結果透過反饋機制可以增加到樣本集,提高模型泛化能力和精召率。整個演算法流程訓練、檢測、反饋閉環。
該項能力為美團監控系統提供無閾值的時序檢測能力。目前檢測流程中的分類器在真實線上樣本的精確率和召回率均在98%以上。團隊會每周定時抽樣核心指標並對檢測結果進行復盤,核心指標的異常檢出準確率在90%左右。
2)根因診斷
在事件處理階段,事件根因的自動定位可以大振幅降低定位時間(MTTT),幫助使用者快速處理事件。由於美團現有系統規模極其龐大且復雜,因此不能用一種簡單的定位方式來涵蓋所有的錯誤根因。我們從多個方面來定位故障根因,包括鏈路異常、日誌堆疊異常、服務異常等故障場景。這裏我們將從兩個方面來探討根因定位的探索和實踐。
①異常鏈路拓展
雷達系統是美團的統一的事件管理平台,用於高效處理告警、事件和故障,同時也提供對公司內微服務系統的根因定位能力( 後文簡稱為雷達 )。辨識微服務系統中的故障鏈路是重要且具有挑戰性的工作,根據服務的呼叫情況構建服務呼叫圖,並透過異常檢測進行擴充套件和剪枝,以獲得準確的異常鏈路圖。拓撲圖過大或過小都不利於根因定位。鏈路異常檢測工作有如下要求:
即時性高: 由於服務呼叫即時變化,異常計算工作不能過於耗時,過長的滯後結果將會導致拓撲圖更新的延遲,異常檢測沒有價值。
計算量大: 美團每分鐘產生幾十萬級別的鏈路數據,並且每一種鏈路數據都包含呼叫次數、TP耗時等關鍵指標。
精召率高: 我們需要準確辨識出當前鏈路是否存在異常,精準辨識可以防止拓撲爆炸或者根因節點缺失。
為了解決以上問題,我們和資料庫平台研發組合作,研發了一套基於預訓練的大容量異常檢測服務來進行鏈路異常檢測,其具有大容量,低時延,準確率高的特點。演算法使用了歷史長時序來挖掘時序特征參數,並在即時檢測中參考臨近120分鐘進行了波動過濾,可以在較短的時間內快速辨識指標的異常程度,實作了每分鐘百萬級別的異常檢測。整體檢測的平均流程耗時在1.5-3ms,檢測的異常點精確率在81%,異常點召回率在82%,F1值為81%。
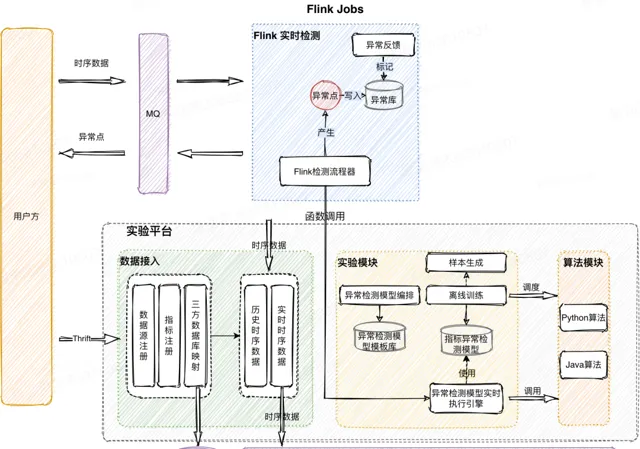
我們使用編排好的訓練流程對單指標進行單模型參數建模,存放到離線模型資料庫中。在即時檢測過程中從資料庫中載入對應的預訓練參數,根據檢測流程進行即時監測。
該工作的核心思想是:將大量的復雜的計算異步化,在即時流檢測的過程中,大振幅降低即時浮點計算量,提高整體的計算容量。該項工作對接了雷達鏈路中的流量和TP線的辨識,支持雷達在故障診斷的過程中,獲取異常節點與鄰接節點之間的呼叫量、耗時的波動,來獲取準確的故障全景圖,並獲取節點間呼叫異常的準確情況。
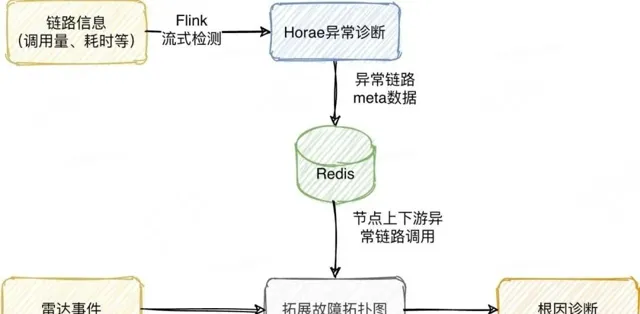
異常拓撲圖效果如下圖所示,雷達鏈路的拓展根據流量異常、失敗率上漲、耗時等多個方面進行拓展,可以有效地找到核心故障鏈路圖:

圖8 雷達異常鏈路
②指標多維度根因定位
大盤有一部份是多維度的指標,由於其業務特性比較強,這些指標波動很難用通用系統指標進行異常定位。我們目前探索了從指標自身維度的異常特征來進行異常維度定位的工作。
總的KPI指標異常,需要處理人員人工下鉆到不同維度分析。如果指標的維度較多,人工分析成本巨大。該項工作的困難和挑戰有以下兩個方面。
首先,不同的組合的KPI是相互依賴和影響的,真正的根因元素的KPI異常,可導致其他維度的KPI也發生變化,很難對KPI指標的根因做一個量化的判斷。
其次,由於KPI擁有多維度的內容,因此隨著維度的增加或粒度的細化,元素的數目往往呈現指數級增長的趨勢,可能需要從成千上萬的多維內容空間進行搜尋;此外,對如此多的維度快速做預測也是一個挑戰。
在演算法的套用場景中,我們需要考慮演算法的可落地性。什麽時候觸發、如何提升結果的準確度、有效性是我們需要解決的問題。

圖9 指標異常維度定位流程圖
上圖是我們執行異常維度定位的簡易流程,我們在Squeeze2的基礎上針對美團業務特性做了最佳化, 其具有以下特點:
自動化框定檢測時間範圍: 使用變點檢測等演算法自動框定時間區間,使用者無需人工框定所需要的檢測時間區間即可自動化的進行異常維度定位操作,並且該項工作提高了下鉆的效能和準確度。
多時間戳下鉆,定位結果匯總: 為了減少因為單點抖動而產生的錯誤下鉆,提高演算法的精確度,透過多時間戳的方式並列下鉆分析,然後根據各個指標的不同特征,區分匯總結果,提高結果的可用性。
裁剪非關鍵根因,減少幹擾維度的影響: 對於最後的根因維度,會計算每一個子維度的整體重要占比,裁剪非重要根因,減少無意義維度帶來的幹擾。將下鉆的根因編碼解析,提高定位結果的可讀性。
③ 結果展示
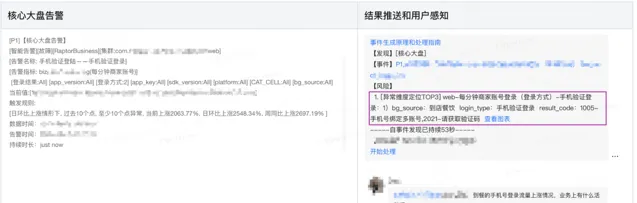
當核心大盤指標出現異常時,系統就會自動觸發下鉆分析,將異常維度的分析結果推播到群裏,幫助使用者快速定位該指標的異常維度是什麽。
3)相似事件推薦
雷達系統中經常出現相似事件,它們往往有著相似的根因,如同一個業務的促銷活動、某個中介軟體故障等。如果我們能夠根據當前事件的異常現象,找到歷史上最相似的一些Case推薦給處理人,則能為事件的定位和處理提供參考,提高處理效率。我們實作了一套相似事件推薦演算法,透過NLP技術和規則過濾,找到每個事件的Top歷史相似事件並推薦給處理人。演算法的整體流程如下:

整體而言,演算法在離線階段使用NLP技術,將每個歷史雷達事件進行向量化並儲存;在即時推薦時,演算法將新的雷達事件進行向量化後,透過向量相似度搜尋到最接近的歷史事件,並透過一些規則計算的特征進行排序和過濾,得到最終可推薦給使用者的Top相似事件。下面對一些實作細節進行介紹。
①離線訓練階段
數據型別區分
一個雷達事件中包含的數據可以分為兩種型別:結構化數據和文本數據。它們主要的區別如下:

如上表所示,這兩類數據的特點和作用有著很大的不同,且它們的可重復度也不一樣。如果我們把兩類數據都放到一個語料庫中去訓練一個向量化模型,會導致在後續的即時推薦階段中,對於文本數據較多的事件產生「不公平」的現象:由於使用者生成的文本數據的可重復度低,它們之間的相似度「天花板」會遠低於結構化型別的數據,這就意味著一個事件的群聊越豐富,就越不容易找到相似的事件,這不符合我們的預期。
所以我們針對這兩類數據分異位建語料庫,透過文本向量化演算法分別得到兩個向量集,以便後續做更精細化的控制。
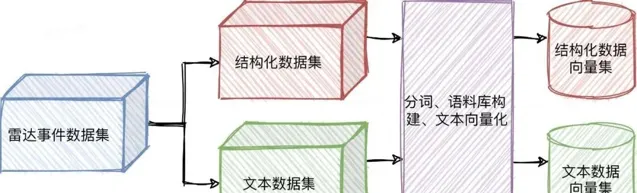
圖11 事件建模過程
分詞&向量化
分詞( Tokenization )是將文件分解為以字詞為單位的基本要素,方便後續處理。對於雷達事件中的文本型別數據,需要采用分詞器進行分詞,並去除停用詞後得到tokens( 即分詞後的詞語列表 );對於結構化欄位,則直接提取內容值或透過一些規則處理得到tokens。
為提升文本分詞效果,預先載入了IT領域詞庫、公司Appkey列表、公共服務名稱作為分詞器的詞庫。經過分詞後,對事件進行詞頻統計,再透過Tfidf演算法計算各詞語的權重。Tfidf演算法得到的向量長度等於詞庫的大小,向量第i個位置上的值表示詞庫中第i個詞在事件中的權重,計算方式會綜合考慮詞語在當前事件的出現次數和在歷史所有事件中的出現次數:
一個詞語在當前事件中出現得越多,且在越少的歷史事件中出現過,說明它是一個比較關鍵的詞語,Tfidf演算法將給予它比較大的權重。
註意,以上公式只是概念化表示,不是Tfidf演算法的實際公式,對於Tfidf演算法的具體實作感興趣的讀者可自行搜尋了解。我們對事件的結構化數據和文本數據分別經過以上步驟進行處理,每個事件將被用兩個Tfidf向量表征並儲存起來,用於後續在即時推薦階段計算事件相似度。
②即時推薦階段
基於向量相似度召回候選事件
在即時推薦階段,我們同樣將新的雷達事件分為結構化和文本型別數據,分別進行分詞並向量化。然後,我們計算它們與歷史事件向量的相似度,得到結構化和文本數據與所有歷史事件的相似度。我們設定不同的閾值來召回候選的歷史相似事件,在實踐中,設定的文本數據相似度閾值要低於結構化數據的相似度。兩類數據召回的相似事件取聯集,作為候選的相似事件列表,它們是與當前事件具有一定相似度的歷史事件,量級在1000個以下。
基於規則計算特征進行排序
一個歷史事件是否值得推薦給使用者,除了與當前事件的相似度之外,還需要考慮更多的維度,例如事件本身是否具有足夠的文本內容可以參考,以及距離當前事件的時間是否比較接近。為了使值得推薦的事件被展現給使用者,我們對每個候選事件透過規則計算一系列特征,用於後續的排序:
文本豐富度: 衡量歷史事件的內容品質,其中群聊、通告、反饋等文本數據較豐富的,能夠提供更多關於處理、定位過程的資訊,為當前事件的處理提供更多參考。
時效性: 衡量歷史事件發生時間與當前事件的距離,越臨近當前事件發生時間的歷史事件,參考價值越大。
根因匹配度: 判斷歷史事件診斷根因是否與當前事件診斷根因一致,如果一致那麽很有可能背後是同一個原因導致的問題。
告警匹配度: 衡量兩個事件告警列表的相似程度,計算過程中會降低通用兜底類告警的權重,提高具有明確業務含義告警的權重。
以上特征,再加上召回階段已經計算好的結構化數據、文本數據相似度,進行加權求和,得到最終的推薦得分,用於對候選事件進行排序。我們還需要對其進行過濾,去除不希望推薦給使用者的歷史事件。過濾的依據主要包括:對於系統發現事件,告警匹配度需要足夠大,對於人為發現事件,推薦的歷史事件的文本內容需要足夠豐富。
關鍵資訊提取&使用者展示
為了使使用者能夠更快速地從歷史事件中獲取有效資訊輸入,我們從每個待推薦的歷史事件提取出關鍵資訊,包括由使用者反饋的歷史事件的根因、解決方案等資訊,把這些附在推薦項上,在事件處理過程中推播到群裏,輔助使用者提高事件處理效率。同時,在Web端頁面也會展示Top相似事件列表,以供使用者參考。
案例展示:
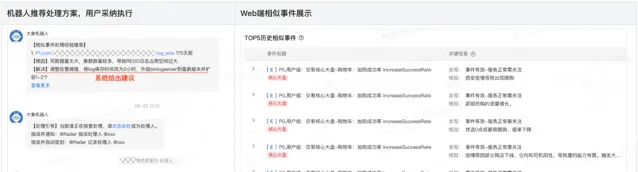
該功能上線後,有相似事件的Case覆蓋率為70%左右,對於系統發現且有推薦歷史相似事件的Case,其平均故障處理時長比無相似事件的Case縮短28%。為了評估推薦的準確率,我們對有推薦相似事件處理經驗且使用者反饋了真實根因的Case進行了人工復盤,若推薦的歷史事件與當前事件有類似的根因或解決方案,則標記為推薦準確,由此統計得到的推薦準確率約為76%。
在復盤過程中,我們發現,推薦的準確率很大程度上取決於使用者所配置的告警品質,對於粒度較粗的通用兜底類告警( 如網域名稱5xx告警 )所產生的事件,推薦準確率會低於細粒度的、具有明確業務含義的告警所產生的事件。原因也是顯然的:粗粒度的告警背後的根因可能千差萬別,所以即使一個歷史事件有著同樣的告警,也會有很大可能不是同一個根因導致的故障;而細粒度的告警則與之相反。
在後續的最佳化中,對於相似事件的排序策略,我們可能需要根據事件中告警的粒度,來調整不同告警型別對於相似度的貢獻大小,而告警的粒度如何衡量,則需要結合公司具體的現狀和我們的經驗判斷。總而言之,在數據驅動的演算法之外,需要結合一些專家知識來彌補數據的不足,從而使演算法的輸出更好地服務於使用者。
3.事後營運
在故障事後,使用者對於故障的營運和復盤有利於經驗沈澱,避免相同的問題再次發生,對於穩定性的長期提升有著重要作用。
COE( Correction Of Error )是美團的故障復盤系統,以文本形式記錄了公司大量的歷史故障復盤內容。我們在COE系統中基於主題分析等NLP技術,實作了故障復盤的主題展示和相似推薦能力,旨在幫助使用者找到更多相似的故障,挖掘出共性問題。目前該功能處於初期建設階段,正在叠代和探索的過程中。
四、總結和未來展望
本文簡單介紹了團隊在AIOps在事件管理這一領域的探索和實踐。我們從三個關鍵的運維階段——事前預防、事中處理以及事後營運,深入探討AIOps在這些場景中的具體套用和優勢。
之後我們也會從多個方面進一步探索AIOps在美團場景下的可能性。這裏我們簡單列舉了幾個可能且有價值的發展方向。
1.智慧日誌檢測

日誌異常檢測通常由四個模組組成,包括日誌收集上報、日誌解析、特征提取以及異常檢測器。我們期望透過提取日誌的計數、序列、語意等特征,來動態辨識當前服務的日誌是否存在異常情況,我們計劃從兩個方面進行探索:
日誌模版時序異常: 透過Drain3等日誌模版挖掘技術,將服務日誌轉化成日誌模版時序。基於時序異常檢測演算法,可以辨識日誌模版徒增、異常日誌出現等風險點。
日誌模版語意異常:
透過解析日誌模版的語意特征,結合機器學習和深度學習演算法,辨識當前日誌是否存在語意異常。
2.智慧化變更辨識
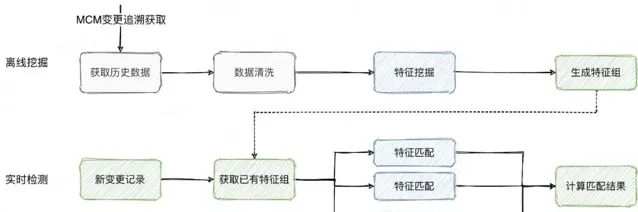
對於配置型別的變更(如:分布式記憶體配置變更、行銷活動配置變更等),一旦變更人員疏忽填寫錯誤或遺漏,會導致線上問題。同時,這類配置可能數量極其龐大,我們需要去動態分析辨識每一配置對應的模型資訊。
對於歷史上正常完結沒有回滾的配置變更,根據其變更值進行特征提取,學習該配置的Key、Value變化規律,從統計學、數據建模等多個角度構造每個配置值的特征組。當新變更到來時,就轉化成了特征相似匹配,從而發現人工填寫錯誤的問題。
> > > >
參考資料
[1] Ester M, Kriegel H P, Sander J, et al. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. AAAI Press. 1996.
[2] Li Z, Pei D, Luo C, et al. Generic and Robust Localization of Multi-dimensional Root Causes. 2019 IEEE 30th International Symposium on Software Reliability Engineering (ISSRE), IEEE. 2019.
[3] He P, Zhu J, Zheng Z, et al. Drain: An Online Log Parsing Approach with Fixed Depth Tree. 2017 IEEE International Conference on Web Services (ICWS), IEEE. 2017.
[4] M Du, F Li. Spell: Streaming Parsing of System Event Logs. 2016 IEEE 16th International Conference on Data Mining (ICDM). 2016.
[5] IBM. Drain3. https://github.com/IBM/Drain3
[6] Akiko A. An information-theoretic perspective of tf–idf measures. Information Processing and Management. 2003.
[7] David B, Andrew Ng, Michael J. Latent Dirichlet Allocation. Journal of Machine Learning Research. 2003.
[8] 曹臻, 威遠. 基於AI演算法的資料庫異常監測系統的設計與實作.
作者丨政東、迎港、張霖、俊峰等(美團基礎研發平台)
來源丨公眾號:美團技術團隊(ID:meituantech)
dbaplus社群歡迎廣大技術人員投稿,投稿信箱: [email protected]












