轉自:新智元
【導讀】 6月,IEEE刊登了一篇對ChatGPT程式碼生成任務進行系統評估的論文,數據集就是程式設計師們最愛的LeetCode題庫。研究揭示了LLM在程式碼任務中出現的潛在問題和能力局限,讓我們能夠對模型做出進一步改進,並逐漸了解使用ChatGPT寫程式碼的最佳姿勢。
有了ChatGPT,還需要人類程式猿編碼嗎?
上個月,一項發表在IEEE TSE期刊(Transactions on Software Engineering)上的研究評估了ChatGPT所生成的程式碼在功能性、復雜性和安全性方面的表現。
結果顯示,ChatGPT生成可用程式碼的能力差異很大。
其成功率從0.66%到89%不等,這主要取決於任務的難度、程式語言等多種因素。

論文地址:https://ieeexplore.ieee.org/document/10507163
具體來說,研究人員測試了GPT-3.5在5種程式語言(C、C++、Java、JavaScript和Python)中,解決LeetCode測試平台上的728個編碼問題,以及應對18個CWE(常見缺陷列舉)場景的能力。
雖然在某些情況下,AI能夠生成比人類更優質的程式碼,但分析也揭示了,一些AI生成程式碼的安全性問題。
論文作者、格拉斯哥大學助理教授Yutian Tang指出,「AI程式碼生成一定程度上,可以提升開發效率,自動化軟體工程。然而,我們必須認識這類模型優勢和不足,以便合理套用」。
「透過全面的分析,可以發現ChatGPT生成程式碼過程中,出現的潛在問題和局限性,進而改進生成技術」。
有網友慶幸地發出疑問,所以我還沒有被解雇?另一人對此表示,至少不是今天。
還有人指出,這項研究是關於GPT-3.5的評估。要是GPT-4早就在編碼能力上大幅提升,Claude 3.5更是如此。

確實,現在我們有了更好的模型,對於GPT-3.5模型的評估,並沒有太大的意義。
0.66%-89%,驚人反差率
總體而言,ChatGPT在不同程式語言的問題上表現相當不錯——特別是在嘗試解決2021年之前LeetCode上的編碼問題時。
例如,它能夠為簡單、中等和困難的問題生成可執行程式碼,成功率分別約為89%、71%和40%。
然而,當涉及到2021年之後的演算法問題時,ChatGPT生成正確執行程式碼的能力受到影響。即使是簡單級別的問題,它有時也無法理解問題的含義。

比如,ChatGPT在生成「簡單」編碼問題的可執行程式碼方面的能力,在2021年後從89%下降到52%。
而它在生成「困難」問題的可執行程式碼方面的能力也在此時間後從40%下降到0.66%。
Tang對比表示,「一個合理的假設是,ChatGPT在2021年之前的演算法問題上表現更好的原因是這些問題在訓練數據集中經常出現」。

接下裏,具體看看研究者們對ChatGPT進行了哪些方面的評估。
實驗評估
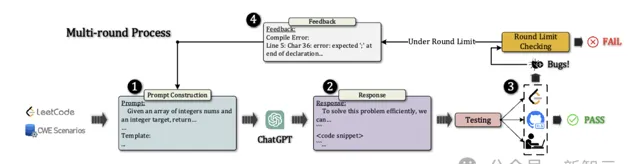
評估的整體流程如圖2所示。
首先為給定的LeetCode問題或CWE場景構造合適的提示並行送給ChatGPT,讓它根據提示和上一輪對話的上下文資訊給出響應。
之後,研究人員將模型響應中的程式碼片段送出給LeetCode平台,利用其線上判斷功能來檢驗程式碼的正確性,CWE漏洞則使用CodeQL進行手動分析。
如果測試結果透過,則生成結束,否則就需要利用LeetCode和CodeQL的反饋繼續建立新的提示、輸入給ChatGPT,再次進行程式碼生成。
如果ChatGPT在對話輪數限制(5輪)之內始終沒有生成出透過測試的程式碼,則認為生成任務失敗。
功能性正確程式碼生成
ChatGPT生成的程式碼在功能上是否正確?
研究動機:
給定提示,ChatGPT生成相應的文本,這種能力可能會提高開發者的生產力。首先去評估ChatGPT在單輪對話中,自動生成功能正確程式碼的能力。
研究方法:
- 讓ChatGPT閱讀問題描述,在單輪對話中生成相應程式碼。(最大對話輪數設為1)
- 使用LeetCode平台上的編程問題作為數據集,截止研究時,有2500個難度不等的問題。
- 將LeetCode所有問題分為2021年之前(Bef.problems)和2021年之後(Aft.problems)兩類,因為ChatGPT的訓練數據截止於2021年。
- 考慮到2021年之前的問題可能已存在於ChatGPT的訓練集中,這可能使程式碼生成任務退化為簡單的資料庫查詢(即程式碼復用)。為了進行全面評估,研究中同時考慮了這兩類問題。
具體而言,研究人員重點關註LeetCode上的演算法問題,因為演算法問題是該平台上最重要、最多和最多樣化的問題。
Bef.problems和Aft.problems的總數分別為1624個和354個。此外,兩者的難度分布為難、中、易,比例為1:2:1。
在所有Bef.problems中,作者隨機抽取了374個問題,其數量與Aft.problems相似,難度分布也與Aft.problems相同。
同樣,在354個Aft.problems和Bef.problems中,難、中、易問題的數量比例也是1:2:1,與LeetCode平台上所有問題的難度分布一致。
此外,研究人員還檢查了Bef.problems和Aft.problems之間是否存在顯著差異。
如果Aft.problems只是Bef.problems的重構,那麽ChatGPT很可能可以輕松解決這些問題,這可能會影響實驗結果在區分時間段方面的可靠性。
論文中,作者總共找到了142對問題。然後,再讓2名研究生獨立檢查這些問題對。
透過仔細核對和討論,結果發現這些相似的問題要麽情景相似,但求解目標完全不同;要麽情景和條件不同,但可以使用類似的演算法(如動態編程)求解。
經過仔細的人工分析,作者沒有發現在任何情況下,Bef.problems可以很容易地重新表述為Aft.problems。
因此,作者認為Aft.problems和Bef.problems之外,對於每個問題,都要求ChatGPT用5種不同的語言生成程式碼:C、C++、Java、Python3和JavaScript。
此外,他們還使用相同的提示樣版為每個 < 問題、語言> 對建立了相應的提示。
Bef.problems和Aft.problems分別共有1,870和1,770個提示。由於ChatGPT的查詢速度有限,研究者將每條提示輸入一次,要求生成程式碼。
然後,研究者將解析後的解決方案,送出給LeetCode進行功能正確性判斷,並得到送出狀態,包括接受、回答錯誤、編譯錯誤、超過時間限制和執行錯誤。
它們分別對應於A.、W.A.、C.E.、T.L.E.和R.E.。一個問題對應一個唯一的對話,以避免從其他問題觸發ChatGPT的推理。
實驗中,作者以狀態率(SR)來評估 ChatGPT 的程式碼生成能力。其中 和 分別是根據狀態生成的程式碼片段數和輸入的提示數。
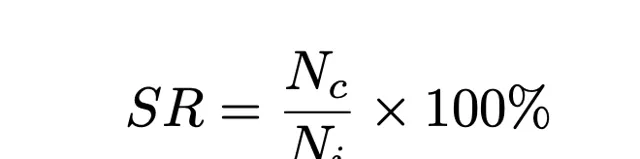
提示:
所設計的提示樣版由4個部份組成:它們分別是<Content>、<Examples>、<Template>和<Command>。
<Content> 用自然語言描述問題,<Examples> 顯示功能正確的程式碼 <input, output> 對,<Template> 指定生成程式碼的方法簽名(method signature),<Command> 要求用特定語言生成程式碼。

結果:
表1和表2顯示,LeetCode對五種程式語言在兩個時間段、兩種形式下的程式碼生成結果、SR以及相應的相對頻率柱形圖。
由於Python3和JavaScript都是動態程式語言,因此這兩列不包含C.E.。
從總體結果來看,ChatGPT為Bef.problems生成的功能正確程式碼的A.率明顯高於Aft.problems。
具體來說,Bef.problems的五種語言平均正確率(68.41%)比Aft.problems的(20.27%)高出 48.14%。
五種語言在不同階段的程式碼生成效能差異顯著,P值為0.008,效應大小值為1。

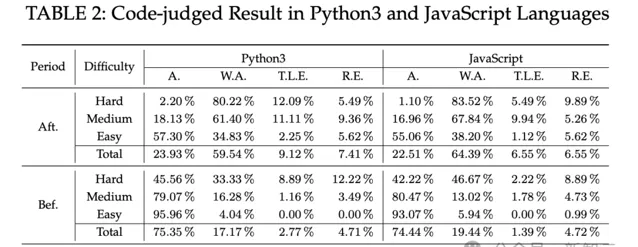
對於Aft.problems,總體正確率低於25%,其中難、中、易問題的正確率分別為0.66%、13.90%和52.47%。
用Holm-Bonferroni校正程式調整的P值和五種語言不同難度之間的效應大小值分別小於0.05和等於1。
結果表明,面對Aft.problems,隨著問題難度的增加,ChatGPT在功能上正確生成程式碼的能力明顯下降。
此外,即使是簡單的問題,它也只能正確回答一半。
在這五項/四項指標中,W.A.率是所有語言中最高的一項,達到58%。
此外,每個W.A.程式碼片段平均有109個測試用例,而ChatGPT生成的程式碼只能透過其中的25%。
難題、中難題和簡單難題的測試用例透過率分別為20.90%、21.03%和38.41%。因此,無論難度如何,生成程式碼的語意都與相應問題描述的邏輯有很大差異。
此外,C.E.率和R.E.率也都達到了16%,而且難題和中難題的C.E.率明顯高於簡單難題。
ChatGPT生成的中難題程式碼,更容易出現編譯和執行時錯誤。比如,圖4中顯示生成的函式cmpfunc,在呼叫前沒有聲明。語法錯誤只占這些錯誤的一小部份(3.7%)。

至於T.L.E.率,雖然數值不高(6%),但測試用例的平均透過率為51%,高於W.A.程式碼片段。
T.L.E.問題的難、中、易三個難度級別的測試用例,平均透過率分別為68%、50%和1%(易問題由於其T.L.E.率接近0%,可以忽略不計)。
由於T.L.E.程式碼片段的測試用例透過率是部份的,不過生成的程式碼中最多還有6%在功能上是正確的,盡管它們的時間復雜度可能並不理想。
細分到每種語言,C、C++、Java、Python3和JavaScript的A.率分別為15.38%、19.37%、20.17%、23.93%和22.51%。
此外,圖5顯示了將五種不同語言與每個問題(僅考慮至少有一個正確解決方案的問題)相結合的A.率分布(接受率分布)。
從圖中可以看出,Medium語言的平均線和中位線都≤0.5,而Easy語言的平均線和中位線都≥0.6。
對於簡單問題ChatGPT更容易將生成的程式碼泛化到不同的語言中。簡單問題和中等問題的中位數和均值分別為0.4和0.5。

對於Bef. Problems問題方面,難、中、易問題的正確率分別為40.13%、70.95%和89.80%,遠高於Aft. problems,但不同難度之間仍存在顯著差異。
用Holm-Bonferroni校正程式調整後的P值和難與中、難與易之間的效應大小值分別小於0.05和大於0.9。
五種語言中,中等難度和簡單難度之間的調整後P值和效應大小值分別為0.056和0.76。
ChatGPT在解決2021年之前訓練集中可能出現的問題時,表現更好,尤其是中等難度和簡單難度的問題。
解決難題的正確率提高了40%,但仍低於50%,這表明ChatGPT生成邏輯復雜問題程式碼的能力仍有很大的提升空間。
總體正確率下降到 17.03%,難、中、易問題的正確率分別為32.89%、15.05%和6%。
生成的程式碼仍能透過平均112個測試用例中的25%。難、中、易問題的測試用例透過率分別為19.19%、31.12%和47.32%。
後兩者都提高了10%,這表明ChatGPT對Bef. Problems有更好的理解力。
不過,C.E.率和R.E.率仍達到13%,接近Aft. problems的16%,兩個階段之間的P值和效應大小值分別為0.328和0.3125,且困難問題透過率最高,中難度問題透過率次之。
編譯錯誤和執行時錯誤與Aft. problems類似,例如,圖6所示程式碼用於重塑給定的二維矩陣,但在第15行引發了執行時錯誤,該行為*returnColumnSizes分配了錯誤大小的記憶體。
至此,T.L.E.率降至1.87%,測試用例平均透過率為74%。

接下來,再細分到每種語言,C、C++、Java、Python3和JavaScript的A.率分別為47.24%、68.63%、76.37%、75.35%和74.44%。
後四種語言的A.率值彼此接近,且大大高於C(最低階別語言)的A.率值,至少高出20%。
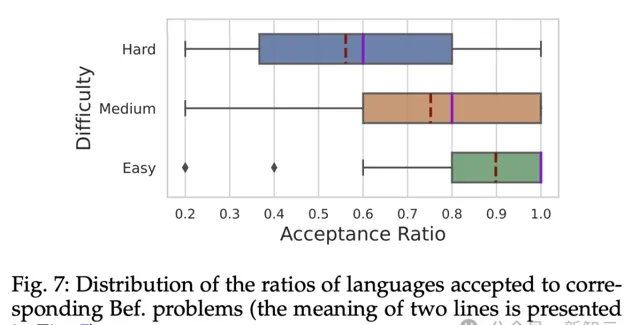
圖 7 顯示的是與圖 5 相同的Bef. Problems。從圖中可以看出,中等題和簡單題的平均線和中位線都≥0.75,而且它們的中位數和平均值之間的差異比之前的Aft. problems要小一半。
此外,有難度的平均線和中位線都≥ 0.55。對於Bef. Problems,ChatGPT更容易將程式碼擴充套件到不同的語言中。
ChatGPT接受的問題的人類平均接受率為55%,而ChatGPT未接受的問題的人類平均接受率為47%。
總而言之,透過實驗,ChatGPT在功能性正確程式碼生成任務上,比起Aft. problems,更加擅長解決不同程式語言中的Bef. Problems。
尤其是,前者的平均正確率比後者高出48.14%。此外,不同的難度也會影響基於ChatGPT的程式碼生成。
對於兩個階段的問題,ChatGPT都能生成執行時間和記憶體開銷小於至少50%的人類解決方案的程式碼。
無論哪個階段的問題,ChatGPT生成的程式碼出現編譯或執行時錯誤的機率都差不多,平均為14.23%。
在所有問題中,C++、Java、Python3和JavaScript的A.率值分別為44.75%、48.74%、50.00%和48.80%,彼此接近,且大大超越C的31.28%。

多輪修復功能管用嗎
在這個方面,作者想探究ChatGPT支持的多輪對話能力在改進程式碼正確性上究竟表現如何?人類能夠「知錯就改」,LLM可以嗎?
首先,研究人員對ChatGPT生成的157段程式碼的錯誤型別進行了分析,可以大致分為以下幾類:
- 細節錯誤(WD):程式碼細節上的錯誤一般源於誤解題意,或者程式碼與問題理解不一致,但大體邏輯基本正確,因此這類錯誤很容易被修復。
- 誤解某些內容(MCC):生成程式碼沒有滿足給定問題的主要條件,使用的演算法合適,但需要修改其核心。
- 誤解問題(MP):指ChatGPT完全錯解了題意,這是最難修復的一種情況,程式碼需要完全重寫,
將錯誤資訊反饋給ChatGPT的方式依舊延續了圖3所示的格式,包括原始問題、生成程式碼片段、LeetCode的報錯資訊以及相應指令。

進行不超過5輪的對話修復後,得到了表5所示的結果。
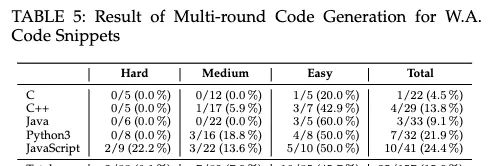
可以看到,157個問題中能透過自動化修復的只有25個,其中16個屬於簡單模式,困難問題的錯誤答案幾乎不可能被修復。
如果把對話輪數的上限增加到10輪呢?結果依舊不樂觀。
從157個問題中隨機選出10個,結果只有其中2個能在10輪內成功修復,剩下的8個依舊無法透過。這能讓研究人員進一步分析ChatGPT很難自動修復的原因。
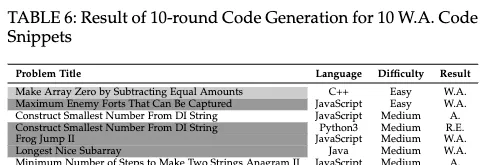
作者認為,一方面,ChatGPT缺乏掌握邏輯細節的能力;另一方面,在需要復雜邏輯推理的問題中,生成程式碼往往偏離問題的實際含義,這即使對於人類程式設計師也很難修復。
程式碼復雜度
程式碼的復雜性對於可讀性、可維護性以及整體品質來說,都是一個重要的影響因素。想象一下,如果ChatGPT對簡單的排序問題都生成出了你很難看懂的程式碼,那會大大拉低使用體驗。
作者利用了SonarQube和cccc兩個指標來評估LeetCode數據集中Bef.問題的復雜程度,並評估響應生成程式碼的迴圈復雜度(cyclomatic complexity)和認知復雜度(cognitive complexity)。
迴圈復雜度會計算執行時線性獨立路徑的數量,從而體現原始碼的測試難度。認知復雜度則從人類角度衡量理解、推理一段程式碼的難度。
由於以上量化標準不夠直觀,研究人員還同時評估了人類編寫的C++和Python3的LeetCode問題解答來與ChatGPT進行比較。

圖20的對比中可以看出,C程式碼的復雜度最高,C++、Java和JavaScript次之並基本處於同一水平,Python3是最不復雜的,這與我們的固有認知基本吻合。
此外,與人類相比,ChatGPT生成的程式碼雖然復雜度稍高,但差距並不明顯。

隨著LeetCode問題難度逐漸升高(表16),無論是人類還是ChatGPT,低復雜度程式碼的占比都會逐漸降低,復雜度被分類為「高」和「非常高」的占比也隨之逐漸提高,這種趨勢也是類似的。
然而,不好的訊息是,ChatGPT的多輪修復功能似乎沒法讓程式碼更簡潔,多數情況下會維持甚至提高程式碼的復雜
性,這或許也是多輪修復功能效果不理想的原因之一。
程式碼安全性
由於ChatGPT訓練時可能學習到了各種各樣的內容,包括品質較低、易受攻擊的程式碼,因此評估生成程式碼的安全性也非常重要。
由於LeetCode的演算法程式碼通常專註於解決特定的邏輯或計算問題,並不涉及管理系統資源、網路通訊等通常有敏感安全問題的操作,因此在這部份的評估中,論文同時采取了兩種路徑。
1)利用CodeQL對LeetCode答案的所有C、C++和Java程式碼進行漏洞檢測,針對MITRE Top25中的5個CWE問題,包括指標和記憶體相關的共30個查詢。
2)針對MITRE Top25中的18個CWE問題,每個問題提供3種上下文場景,給ChatGPT「挖坑」,要求它補全程式碼,再用CodeQL自動檢測看是否確實出現了相應問題。
在第一個測試中(表18),ChatGPT表現良好,91.8%的錯誤集中在MissingNullTest這一類,其余的漏洞的出現頻次則一般不超過5次。
但仍要註意的是,ChatGPT在CWE 787,即「越界寫入」問題上表現不佳,這可能會導致潛在的程式碼漏洞。
而且,由於這些漏洞的修復比較簡單,因此在給定錯誤資訊並要求生成修復程式碼後, ChatGPT也能較好完成任務。
要求ChatGPT修復CWE-787問題的提示樣版
在第二個測試——安全程式碼生成方面,ChatGPT共生成了2983(99.07%)個有效程式碼片段,其中994個存在安全漏洞,占比達到33.32%。
而且,C語言中的易受攻擊片段的百分比(51.64%)遠遠高於Python3(17.08%),這有可能是由於C程式碼本身就對程式的記憶體安全提出了更高的要求,也可能源於訓練數據中C和Python3程式碼的品質差距。
多輪修復功能依舊表現出色,89.4%的漏洞都能在給出CWE資訊後成功解決,比如溢位、數據泄露、不安全記憶體操作、未經身份驗證存取等相關問題。
ChatGPT非確定性
ChatGPT的非確定性輸出如何影響程式碼生成?
如下表所示,表22和表23分別列出了所選演算法問題和溫度為0.7時的實驗結果。
在溫度為0的條件下,10次試驗中,演算法問題和CWE程式碼場景的非確定性程式碼生成統計結果如表24、表25和表26所示。
其中表26列出了所選的20個CWE程式碼場景。
此外,作者還研究了非確定性對多輪修復過程的影響,修復結果如表27-32所示。
溫度設為0.7,5次試驗中演算法問題的多輪修復過程。
溫度設為0,5次試驗中演算法問題的多輪修復過程。
溫度設為0.7,5次試驗中演算法問題的CWE多輪修復過程。
溫度設為0,5次試驗中演算法問題的CWE多輪修復過程。
溫度設為0.7,5次試驗中安全程式碼生成的多輪修復過程。
溫度設為0,5次試驗中安全程式碼生成的多輪修復過程。
總之,實驗中,當溫度設定為0.7時,單輪流程中的程式碼生成可能會受到ChatGPT非確定性因子的影響,從而導致程式碼片段在功能正確性、復雜性和安全性方面出現差異。
要減輕ChatGPT在單輪過程中的非確定性,一種可能的策略是將溫度設定為0。
然而,在多輪修復過程中,無論溫度設定為0.7還是0,ChatGPT固定的程式碼片段在功能正確性、復雜性和安全性方面都可能存在差異。
參考資料:
https://ieeexplore.ieee.org/document/10507163
https://spectrum.ieee.org/chatgpt-for-coding
https://arxiv.org/abs/2308.04838











