點選上方↑↑↑「OpenCV學堂」關註我
來源:公眾號 新智元授權
【導讀】 近日,Stability AI又釋出了新作SV3D,基於視訊擴散模型的SV3D將3D模型生成的效果提升了一大截,模型權重已在huggingface開放。
Stability AI又有新動作了!這次給我們端上來的是全新的3D生成模型Stable Video 3D(SV3D)。
只需一張圖,SV3D就能生成對應的3D模型,相比於自家之前釋出的Stable Zero123,模型品質更高,功能更強!
與之前基於Stable Diffusion1.5的Stable Zero123不同,SV3D以Stable Video Diffusion為基礎,充分利用了視訊模型的功能性。
與影像擴散模型相比,視訊擴散模型在生成輸出的泛化和檢視一致性方面存在明顯優勢。
從上面的演示我們可以看到,SV3D的生成效果大大超越了當前的同類模型,視訊模型的理解能力確實不一般,籃球、玉米、鐘表都做的相當還原。
——不過還是需要說一句,開庭時請帶上你的SV3D。

計畫地址:https://sv3d.github.io/
模型下載:https://huggingface.co/stabilityai/sv3d
此外,Stability還給出了兩個進階版本:
SV3D_u,基於單個影像輸入生成軌域視訊,無需相機調節;
SV3D_p,擴充套件了SVD3_u的功能,既可以容納單個影像,也可以容納軌域檢視,從而允許沿著指定的攝影機路徑建立3D視訊。
目前,Stable Video 3D可以透過Stability AI會員資格用於商業目的。
對於非商業用途,可以在Hugging Face上下載模型權重。
多檢視和3D生成
單影像3D物件重建是電腦視覺中長期存在的問題,且在遊戲設計、AR/VR、電子商務、機器人等領域有著廣泛的套用。
這是一個非常具有挑戰性的問題,因為它需要將2D像素提升到3D空間,同時還要推理3D中物體看不見的部份。
對此,一個典型的策略是使用基於影像的2D生成模型(比如Imagen、Stable Diffusion等)為給定物件的不可見新檢視提供3D最佳化損失函式。
還有的方法是采用2D的影像生成模型,從單個影像執行新檢視合成(novel view synthesi,NVS)。
從概念上講,這些方法都是模仿了典型的基於攝影測量的3D物件捕獲管道,即首先拍攝物件的多檢視影像,然後進行3D最佳化。

這種方法的一個關鍵問題是,底層生成模型中缺乏多檢視一致性,導致新檢視不一致。
多檢視一致性和泛化
本文的工作以視訊擴散模型(Stable Video Diffusion,SVD)為基礎,來生成具有顯式相機姿態條件的給定物件的多個新檢視,具有出色的多檢視一致性。
另外,由於SVD是在比大規模3D數據更容易獲得的大規模影像和視訊數據上訓練的,所以具有更強的泛化能力。
SV3D的工作原理如下圖所示,首先根據輸入的單個影像,生成一致的多檢視影像。
然後使用生成的檢視最佳化3D表示,從而生成高品質的3D網格。
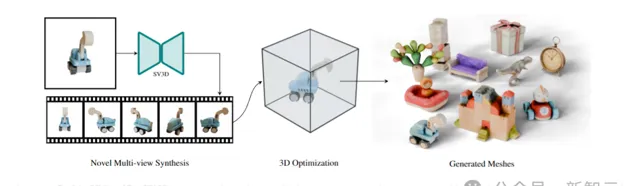
透過調整視訊擴散模型Stable Video Diffusion,並添加攝影機路徑調節,SV3D能夠生成物件的多檢視視訊。
此外,研究人員還提出了改進的3D最佳化,利用SV3D的強大功能來生成圍繞物體的任意軌域。
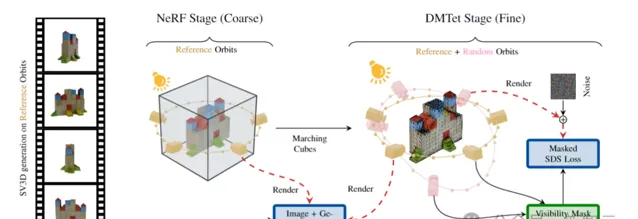
透過進一步實施解纏結照明最佳化(disentangled illumination optimization)、以及新的掩蔽分數蒸餾采樣損失功能(masked score distillation sampling loss function),SV3D能夠從單個影像輸入可靠地輸出高品質的3D網格。
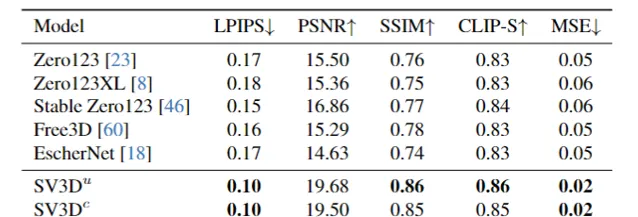
研究人員在具有2D和3D指標的多個數據集上進行了大量實驗,結果表明:SV3D在NVS和3D重建方面到達了目前最好的效能。
模型設計
SV3D的主要思想是重新利用視訊擴散模型中的時間一致性,以實作物件的空間3D一致性。
具體來說,研究人員對SVD進行微調,以在單檢視影像的基礎上圍繞3D物體生成軌域視訊。該軌域視訊不必處於相同的高度,也不必處於規則間隔的方位角。
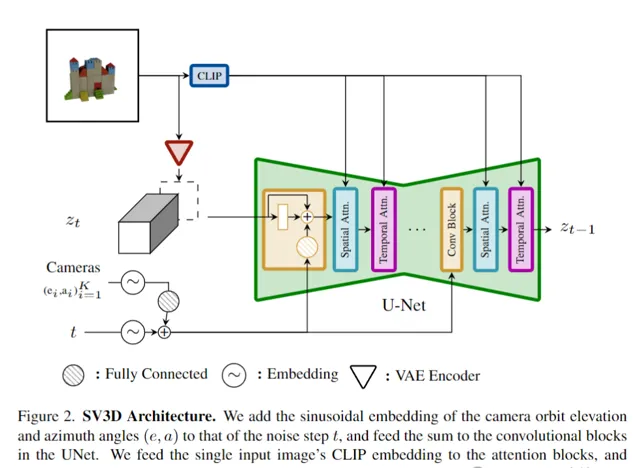
如上圖所示,SV3D的架構建立在SVD的基礎上,SVD由一個具有多個層的UNet組成,每層包含一個帶有Conv3D層的殘留誤差塊序列,以及兩個帶有註意力層的Transformer塊(空間和時間)。
作者對於SVD做了如下調整:
1. 刪除了fps id和motion bucket id的向量條件,因為它們與SV3D無關;
2. 在嵌入到SVD的VAE編碼器的潛空間之後,將條件影像根據雜訊潛態輸入連線到UNet;
3. 將條件影像的CLIPembedding矩陣作為鍵和值提供給每個Transformer塊的交叉註意力層。
4. 相機軌跡與擴散雜訊時間步長一起輸入殘留誤差塊。
動態軌域
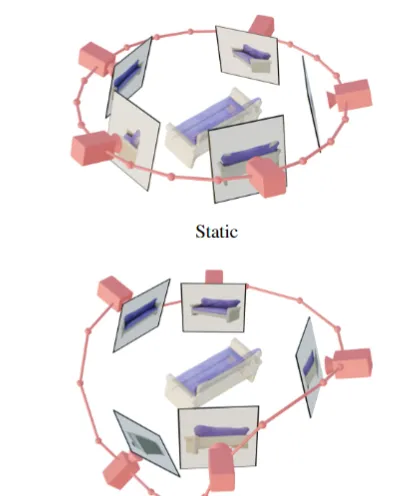
如上圖所示,研究人員設計了靜態和動態軌域來研究相機姿態調節的效果。
在靜態軌域上,相機以相同的仰角和規則間隔的方位角圍繞物體旋轉。
靜態軌域的缺點是,由於調節仰角,可能無法獲得有關物體頂部或底部的任何資訊。
而在動態軌域中,方位角可以不規則地間隔,並且仰角可以因檢視而異。
為了建立一個動態軌域,研究人員對靜態軌域進行采樣,在方位角上添加小的隨機雜訊,並在高度方向上添加具有不同頻率的正弦曲線的隨機加權組合。
三角形CFG縮放

還有一個問題是,SVD在生成的幀中使用線性遞增的無分類器引導(CFG)比例,這種縮放會導致生成軌域中的最後幾幀過度銳化,如上圖第20幀所示。
作者建議在推理過程中使用三角形CFG縮放(Triangular CFG Scalin),從上圖可以看出,使用三角形CFG縮放在後檢視(第12幀)中產生了更多細節。
模型
作者訓練了三個從SVD微調的影像到3D視訊模型。
首先是一個無姿態的模型SV3D,該模型僅以單檢視影像為條件,即可生成圍繞物體的靜態軌域視訊。請註意,與SVD-MV不同,這裏沒有為無姿態模型提供仰角,因為作者發現模型能夠從條件影像中推斷出它。
第二個模型是姿態條件的SV3D_u,它以輸入影像以及軌域上的相機仰角和方位角序列為條件,在動態軌域上進行訓練。
透過在訓練過程中逐漸增加任務難度,產生了第三個模型SV3D_p,首先微調SVD以無條件地產生靜態軌域,然後在具有相機姿態條件下的動態軌域上進行調整。
研究人員使用Objaverse數據集訓練了SV3D,該數據集包含涵蓋廣泛多樣性的合成3D物件。對於每個物件,在576×576分辨率、33.8度視野的隨機顏色背景上環繞渲染21幀。
所有三個模型總共訓練了105k次叠代,批次大小為64。總共使用了8個80GB A100 GPU(4個節點)訓練了6天 。
最後,我們直觀地看一下幾種3D生成模型的效果比較:

參考資料:
https://stability.ai/news/introducing-stable-video-3d?utm_source=Twitter&utm_medium=website&utm_campaign=blog












