共飲一杯無
來源:blog.csdn.net/qq_35427589/article/details/129665307
本文主要講述透過MyBatis、JDBC等做大數據量數據插入的案例和結果。
# 30萬條數據插入插入資料庫驗證
實體類、mapper和配置檔定義
User實體
mapper介面
mapper.xml檔
jdbc.properties
sqlMapConfig.xml
不分批次直接梭哈
迴圈逐條插入
MyBatis實作插入30萬條數據
JDBC實作插入30萬條數據
總結
驗證的資料庫表結構如下:
CREATETABLE`t_user` (`id`int(11) NOTNULL AUTO_INCREMENT COMMENT'使用者id',`username`varchar(64) DEFAULTNULLCOMMENT'使用者名稱稱',`age`int(4) DEFAULTNULLCOMMENT'年齡', PRIMARY KEY (`id`)) ENGINE=InnoDBDEFAULTCHARSET=utf8 COMMENT='使用者資訊表';
話不多說,開整!
# 實體類、mapper和配置檔定義
User實體
/** * <p>使用者實體</p> * * @Author zjq * @Date 2021/8/3 */@Datapublic classUser{privateint id;private String username;privateint age;}
mapper介面
publicinterfaceUserMapper {/** * 批次插入使用者 * @param userList */voidbatchInsertUser(@Param("list") List<User> userList);}
mapper.xml檔
<!-- 批次插入使用者資訊 --><insertid="batchInsertUser"parameterType="java.util.List"> insert into t_user(username,age) values<foreachcollection="list"item="item"index="index"separator=","> ( #{item.username}, #{item.age} )</foreach></insert>
jdbc.properties
jdbc.driver=com.mysql.jdbc.Driverjdbc.url=jdbc:mysql://localhost:3306/testjdbc.username=rootjdbc.password=root
sqlMapConfig.xml
<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"><configuration><!--透過properties標簽載入外部properties檔--><propertiesresource="jdbc.properties"></properties><!--自訂別名--><typeAliases><typeAliastype="com.zjq.domain.User"alias="user"></typeAlias></typeAliases><!--資料來源環境--><environmentsdefault="developement"><environmentid="developement"><transactionManagertype="JDBC"></transactionManager><dataSourcetype="POOLED"><propertyname="driver"value="${jdbc.driver}"/><propertyname="url"value="${jdbc.url}"/><propertyname="username"value="${jdbc.username}"/><propertyname="password"value="${jdbc.password}"/></dataSource></environment></environments><!--載入對映檔--><mappers><mapperresource="com/zjq/mapper/UserMapper.xml"></mapper></mappers></configuration>
不分批次直接梭哈
MyBatis直接一次性批次插入30萬條,程式碼如下:
@TestpublicvoidtestBatchInsertUser() throws IOException { InputStream resourceAsStream = Resources.getResourceAsStream("sqlMapConfig.xml"); SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream); SqlSession session = sqlSessionFactory.openSession(); System.out.println("===== 開始插入數據 =====");long startTime = System.currentTimeMillis();try { List<User> userList = new ArrayList<>();for (int i = 1; i <= 300000; i++) { User user = new User(); user.setId(i); user.setUsername("共飲一杯無 " + i); user.setAge((int) (Math.random() * 100)); userList.add(user); } session.insert("batchInsertUser", userList); // 最後插入剩余的數據 session.commit();long spendTime = System.currentTimeMillis()-startTime; System.out.println("成功插入 30 萬條數據,耗時:"+spendTime+"毫秒"); } finally { session.close(); } }
可以看到控制台輸出:
Cause: com.mysql.jdbc.PacketTooBigException: Packet for query is too large (27759038 >yun 4194304). You can change this value on the server by setting the max_allowed_packet’ variable.
超出最大封包限制了,可以透過調整max_allowed_packet限制來提高可以傳輸的內容,不過由於30萬條數據超出太多,這個不可取,梭哈看來是不行了 😅😅😅
既然梭哈不行那我們就一條一條迴圈著插入行不行呢
迴圈逐條插入
mapper介面和mapper檔中新增單個使用者新增的內容如下:
/** * 新增單個使用者 * @param user */voidinsertUser(User user);
<!-- 新增使用者資訊 --><insertid="insertUser"parameterType="user"> insert into t_user(username,age) values ( #{username}, #{age} )</insert>
調整執行程式碼如下:
@TestpublicvoidtestCirculateInsertUser() throws IOException { InputStream resourceAsStream = Resources.getResourceAsStream("sqlMapConfig.xml"); SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream); SqlSession session = sqlSessionFactory.openSession(); System.out.println("===== 開始插入數據 =====");long startTime = System.currentTimeMillis();try {for (int i = 1; i <= 300000; i++) { User user = new User(); user.setId(i); user.setUsername("共飲一杯無 " + i); user.setAge((int) (Math.random() * 100));// 一條一條新增 session.insert("insertUser", user); session.commit(); }long spendTime = System.currentTimeMillis()-startTime; System.out.println("成功插入 30 萬條數據,耗時:"+spendTime+"毫秒"); } finally { session.close(); } }
執行後可以發現磁盤IO占比飆升,一直處於高位。
等啊等等啊等,好久還沒執行完
先不管他了太慢了先搞其他的,等會再來看看結果吧。
two thousand year later …
控制台輸出如下:
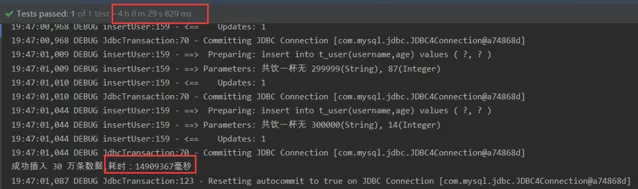
總共執行了14909367毫秒,換算出來是4小時八分鐘。太慢了。。
👇👇👇還是最佳化下之前的批次處理方案吧
# MyBatis實作插入30萬條數據
先清理表數據,然後最佳化批次處理執行插入:
-- 清空使用者表TRUNCATEtable t_user;
以下是透過 MyBatis 實作 30 萬條數據插入程式碼實作:
/** * 分批次批次插入 * @throws IOException */ @TestpublicvoidtestBatchInsertUser() throws IOException { InputStream resourceAsStream = Resources.getResourceAsStream("sqlMapConfig.xml"); SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream); SqlSession session = sqlSessionFactory.openSession(); System.out.println("===== 開始插入數據 =====");long startTime = System.currentTimeMillis();int waitTime = 10;try { List<User> userList = new ArrayList<>();for (int i = 1; i <= 300000; i++) { User user = new User(); user.setId(i); user.setUsername("共飲一杯無 " + i); user.setAge((int) (Math.random() * 100)); userList.add(user);if (i % 1000 == 0) { session.insert("batchInsertUser", userList);// 每 1000 條數據送出一次事務 session.commit(); userList.clear();// 等待一段時間 Thread.sleep(waitTime * 1000); } }// 最後插入剩余的數據if(!CollectionUtils.isEmpty(userList)) { session.insert("batchInsertUser", userList); session.commit(); }long spendTime = System.currentTimeMillis()-startTime; System.out.println("成功插入 30 萬條數據,耗時:"+spendTime+"毫秒"); } catch (Exception e) { e.printStackTrace(); } finally { session.close(); } }
使用了 MyBatis 的批次處理操作,將每 1000 條數據放在一個批次中插入,能夠較為有效地提高插入速度。同時請註意在迴圈插入時要帶有合適的等待時間和批次處理大小,以防止出現記憶體占用過高等問題。此外,還需要在配置檔中設定合理的連線池和資料庫的參數,以獲得更好的效能。
在上面的範例中,我們每插入1000行數據就進行一次批次處理送出,並等待10秒鐘。這有助於控制記憶體占用,並確保插入操作平穩進行。
五十分鐘執行完畢,時間主要用在了等待上。
如果低谷時期執行,CPU和磁盤效能又足夠的情況下,直接批次處理不等待執行:
/** * 分批次批次插入 * @throws IOException */ @TestpublicvoidtestBatchInsertUser() throws IOException { InputStream resourceAsStream = Resources.getResourceAsStream("sqlMapConfig.xml"); SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream); SqlSession session = sqlSessionFactory.openSession(); System.out.println("===== 開始插入數據 =====");long startTime = System.currentTimeMillis();int waitTime = 10;try { List<User> userList = new ArrayList<>();for (int i = 1; i <= 300000; i++) { User user = new User(); user.setId(i); user.setUsername("共飲一杯無 " + i); user.setAge((int) (Math.random() * 100)); userList.add(user);if (i % 1000 == 0) { session.insert("batchInsertUser", userList);// 每 1000 條數據送出一次事務 session.commit(); userList.clear(); } }// 最後插入剩余的數據if(!CollectionUtils.isEmpty(userList)) { session.insert("batchInsertUser", userList); session.commit(); }long spendTime = System.currentTimeMillis()-startTime; System.out.println("成功插入 30 萬條數據,耗時:"+spendTime+"毫秒"); } catch (Exception e) { e.printStackTrace(); } finally { session.close(); } }
則24秒可以完成數據插入操作:
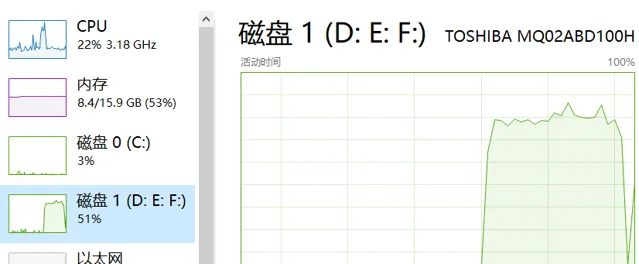
可以看到短時CPU和磁盤占用會飆高。
把批次處理的量再調大一些調到5000,在執行:
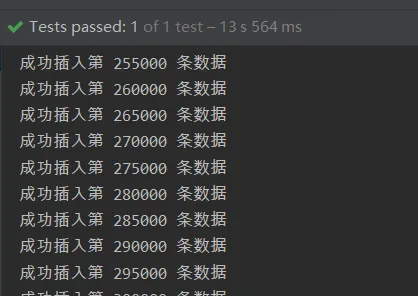
13秒插入成功30萬條,直接蕪湖起飛🛫🛫🛫
# JDBC實作插入30萬條數據
JDBC迴圈插入的話跟上面的mybatis逐條插入類似,不再贅述。
以下是 Java 使用 JDBC 批次處理實作 30 萬條數據插入的範例程式碼。請註意,該程式碼僅提供思路,具體實作需根據實際情況進行修改。
/** * JDBC分批次批次插入 * @throws IOException */ @TestpublicvoidtestJDBCBatchInsertUser() throws IOException { Connection connection = null; PreparedStatement preparedStatement = null; String databaseURL = "jdbc:mysql://localhost:3306/test"; String user = "root"; String password = "root";try { connection = DriverManager.getConnection(databaseURL, user, password);// 關閉自動送出事務,改為手動送出 connection.setAutoCommit(false); System.out.println("===== 開始插入數據 =====");long startTime = System.currentTimeMillis(); String sqlInsert = "INSERT INTO t_user ( username, age) VALUES ( ?, ?)"; preparedStatement = connection.prepareStatement(sqlInsert); Random random = new Random();for (int i = 1; i <= 300000; i++) { preparedStatement.setString(1, "共飲一杯無 " + i); preparedStatement.setInt(2, random.nextInt(100));// 添加到批次處理中 preparedStatement.addBatch();if (i % 1000 == 0) {// 每1000條數據送出一次 preparedStatement.executeBatch(); connection.commit(); System.out.println("成功插入第 "+ i+" 條數據"); } }// 處理剩余的數據 preparedStatement.executeBatch(); connection.commit();long spendTime = System.currentTimeMillis()-startTime; System.out.println("成功插入 30 萬條數據,耗時:"+spendTime+"毫秒"); } catch (SQLException e) { System.out.println("Error: " + e.getMessage()); } finally {if (preparedStatement != null) {try { preparedStatement.close(); } catch (SQLException e) { e.printStackTrace(); } }if (connection != null) {try { connection.close(); } catch (SQLException e) { e.printStackTrace(); } } } }
上述範例程式碼中,我們透過 JDBC 連線 MySQL 資料庫,並執行批次處理操作插入數據。具體實作步驟如下:
獲取資料庫連線。
建立 Statement 物件。
定義 SQL 語句,使用 PreparedStatement 物件預編譯 SQL 語句並設定參數。
執行批次處理操作。
處理剩余的數據。
關閉 Statement 和 Connection 物件。
使用setAutoCommit(false) 來禁止自動送出事務,然後在每次批次插入之後手動送出事務。每次插入數據時都新建一個 PreparedStatement 物件以避免狀態不一致問題。在插入數據的迴圈中,每 10000 條數據就執行一次 executeBatch() 插入數據。
另外,需要根據實際情況最佳化連線池和資料庫的相關配置,以防止連線超時等問題。
# 總結
實作高效的大量數據插入需要結合以下最佳化策略(建議綜合使用):
1.批次處理:批次送出SQL語句可以降低網路傳輸和處理開銷,減少與資料庫互動的次數。在Java中可以使用Statement或者PreparedStatement的addBatch()方法來添加多個SQL語句,然後一次性執行executeBatch()方法送出批次處理的SQL語句。
在迴圈插入時帶有適當的等待時間和批次處理大小,從而避免記憶體占用過高等問題:
設定適當的批次處理大小:批次處理大小指在一次插入操作中插入多少行數據。如果批次處理大小太小,插入操作的頻率將很高,而如果批次處理大小太大,可能會導致記憶體占用過高。通常,建議將批次處理大小設定為1000-5000行,這將減少插入操作的頻率並降低記憶體占用。
采用適當的等待時間:等待時間指在批次處理操作之間等待的時間量。等待時間過短可能會導致記憶體占用過高,而等待時間過長則可能會延遲插入操作的速度。通常,建議將等待時間設定為幾秒鐘到幾十秒鐘之間,這將使操作變得平滑且避免出現記憶體占用過高等問題。
可以考慮使用一些記憶體最佳化的技巧,例如使用記憶體資料庫或使用遊標方式插入數據,以減少記憶體占用。
總的來說,選擇適當的批次處理大小和等待時間可以幫助您平穩地進行插入操作,避免出現記憶體占用過高等問題。
2.索引: 在大量數據插入前暫時去掉索引,最後再打上,這樣可以大大減少寫入時候的更新索引的時間。
3.資料庫連線池:使用資料庫連線池可以減少資料庫連線建立和關閉的開銷,提高效能。在沒有使用資料庫連線池的情況,記得在finally中關閉相關連線。
資料庫參數調整:增加MySQL資料庫緩沖區大小、配置高效能的磁盤和I/O等。

熱門推薦











