面試的時候,面試官看著你做的計畫,大機率會問一句, 這個計畫(API)能支持多大 QPS ?
如果你是個已經工作有幾年的程式設計師,那想必這個問題難不倒你。但如果,我是說如果,面試官問你,你知道 QPS 的計算是怎麽實作的不,能詳細說下思路嗎? 閣下又該如何應對呢?這是個很有意思的問題,我們今天就來聊聊這個話題。考慮到有不少讀者還是學生,我們先來看下 QPS 的含義 。
QPS 是什麽
QPS(Queries Per Second) ,也就是「 每秒查詢數 」,它表示伺服器每秒能夠處理的請求數量,是一個衡量伺服器效能的重要指標。

比如說服務的使用者查詢 API 支持 100 QPS,就是指這個介面可以做到每秒查 100 次。你務必 牢牢記住這個概念 ,因為工作之後經常會聽別人提起它。很多面試官就特別愛問:"你的這個計畫(API)的讀寫效能怎麽樣,單個例項能支持多少 QPS?"。這個問題就是個 照妖鏡 。面試官可以透過這個問題了解你對計畫的了解程度。 如果你答不出來,那你在這個計畫中很可能就不是核心開發,或者說你這個計畫既不核心也不重要,甚至可能你就沒做過這個計畫。。。 並且這個 QPS 數值還會有一個 合理範圍 ,有經驗的開發能透過這個值判斷這個服務 API 底層大概是咋樣的。如果你回答的數值過小或過大,那又可以繼續細聊過小和過大的原因。
我說下我目前接觸下來比較合理的 QPS 範圍:帶了資料庫的服務一般寫效能在 5k 以下,讀效能一般在 10k 以下,能到 10k 以上的話,那很可能是在資料庫前面加了層緩存。如果你的服務還帶了個文本演算法模型,那使用了 gpu 的情況下 API 一般支持 100~400QPS 左右,如果是個同時支持文本和圖片的模型,也就是所謂的多模態模型,那一般在 100QPS 以內。

比如候選人上來就說服務單例項 API 讀寫效能都有上萬 QPS, 那我可以大概猜到這 應該 是個純 cpu+記憶體的 API 鏈路。但如果候選人還說這裏面沒做緩存且有資料庫呼叫,那我可能會追問這裏頭用的是哪款資料庫,底層是什麽儲存引擎?如果候選人還說這裏面帶了個文本檢測的演算法模型,那有點違反經驗,那我會多聊聊細節,說不定這對我來說是個開眼界的機會。
如何計算 QPS ?
現在了解完 QPS 了,假設我們想要獲得某個函式 的 QPS,該怎麽做呢?
這一般分兩個情況:
• 1. 即時性要求較低 的監控場景。
• 2. 即時性要求較高 的服務治理場景。
監控場景
監控服務 QPS 是最常見的場景,它對即時性要求不高。如果我們想要檢視服務的 QPS,可以在服務程式碼內部接入
Prometheus
的程式碼庫,然後在每個需要計算 QPS 的地方,加入類似
Counter.Inc()
這樣的程式碼,意思是函式執行次數加 1。這個過程也就是所謂的
打點
。
當函式執行到打點函式時,Prometheus 程式碼庫內部會計算這個函式的呼叫次數,將數據寫入到
counter_xx.db
的檔中,再同步到公司的
時序資料庫
中,然後我們可以透過一些監控面板,比如
grafana
調取時序資料庫裏的打點數據,在監控面板上透過特殊的運算式,也就是
PromQL
,對某段時間裏的打點進行求導計算速率,這樣就能看到這個函式的呼叫 QPS 啦。

服務治理場景
跟監控面板檢視服務 QPS 不同的是,我們有時候需要以
更高的即時性
獲取 QPS。比如在
服務治理
這一塊,我們需要在服務內部加入一些中間層,即時計算服務 api 當前的 QPS,當它大於某個閾值時,可以做一些自訂邏輯,比如是直接拒絕掉一些請求,還是將請求排隊等一段時間後再處理等等,也就是所謂的
限流
。
這樣的場景都要求我們即時計算出準確的 QPS,那麽接下來就來看下這是怎麽實作的?
基本思路
計算某個函式的執行 QPS 說白了就是計算每秒內這個函式被執行了多少次。我們可以參考監控場景的思路,用一個
臨時變量 cnt
記錄某個函式的
執行次數
,每執行一次就給變量
+1
,然後計算單位時間內的變化速率。公式就像這樣:
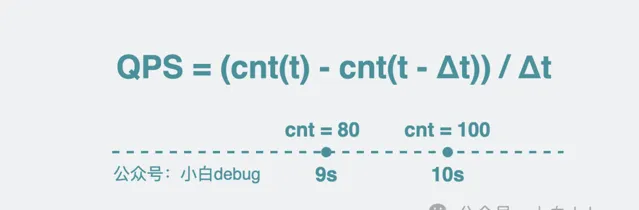
QPS = (cnt(t) - cnt(t - Δt)) / Δt
其中
cnt(t)
表示在時間
t
的請求數,
Δt
表示時間間隔。比如在第 9 秒的時候, cnt 是 80, 到第 10 秒的時候,cnt 是 100,那這一秒內就執行了
(100-80)/(10-9) = 20 次
, 也就是 20QPS。
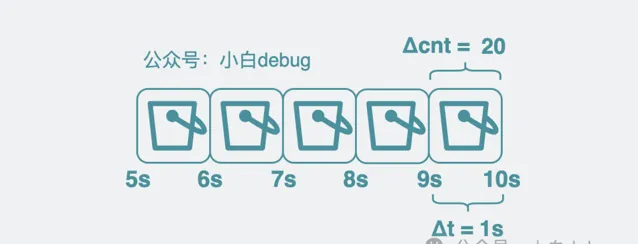
引入 bucket
但這樣會有個問題,到了第 10 秒的時候,有時候我還想回去知道第 5 和第 6 秒的 QPS,光一個變量的話,數據老早被覆蓋了,根本不夠用。於是我們可以將臨時變量 cnt,改成了一個陣列,陣列裏每個元素都用來存放(cnt(t) - cnt(t - Δt)) 的值。陣列裏的每個元素,都叫
bucket
.
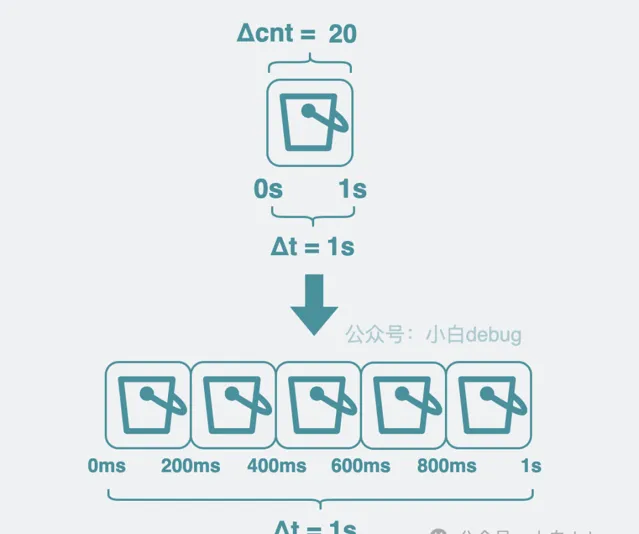
調整 bucket 範圍粒度
我們預設每個 bucket 都用來存放 1s 內的數據增量,但這 粒度比較粗 ,我們可以調整為 200ms,這樣我們可以獲得更細粒度的數據。 粒度越細,意味著我們計算 QPS 的元件越靈敏,那基於這個 QPS 做的服務治理能力響應就越快 。於是,原來用 1 個 bucket 存放 1s 內的增量數量,現在就變成要用 5 個 bucket 了。
引入環形陣列
但這樣又引入一個新的問題,隨著時間變長,
陣列的長度就越長
,需要的記憶體就越多,最終導致行程申請的記憶體過多,被
oom(Out of Memory) kill
了。為了解決這個問題,我們可以為陣列加入最大長度的限制,超過最大長度的部份,就從頭開始寫,覆蓋掉老的數據。這樣的陣列,就是所謂的
環狀陣列
。
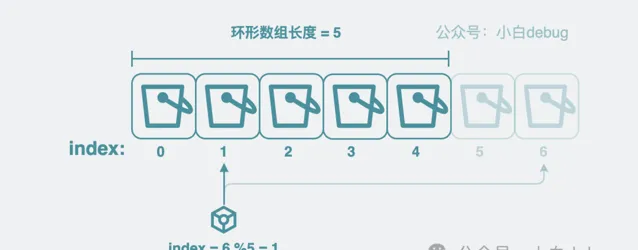
雖然環狀陣列聽起來挺高級了,但說白了就是
一個用%取模來確定寫入位置的定長陣列
,沒有想象的那麽高端。
比如陣列長度是 5,陣列 index 從 0 開始,要寫 index=6 的 bucket, 計算 6%5 = 1,那就是寫入 index=1 的位置上。
加入滑動視窗
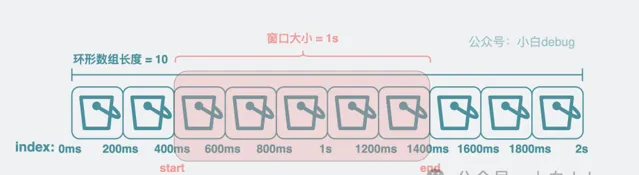
有了環形陣列之後,現在我們想要計算 qps,就需要引入
滑動視窗
的概念。這玩意聽著玄乎,其實就是
start
和
end
兩個變量。透過它來圈定我們要計算 qps 的 bucket 陣列範圍。將當前時間跟 bucket 的粒度做
取模
操作,可以大概知道
end
落在哪個 bucket 上,確定了 end 之後,將 end 的時間戳減個
1s
就能大概得到
start
在哪個 bucket 上,有了這兩個值,
再將 start 到 end 範圍內的 bucket 取出
。對範圍內的 bucket 裏的 cnt 求和,得到這段時間內的總和,再除以 Δt,也就是 1s。就可以得到 qps。
到這裏 qps 的計算過程就介紹完了。
如何計算平均耗時
既然 qps 可以這麽算,那同理,我們也可以計算某個函式的
平均耗時
,實作也很簡單,上面提到 bucket 有個用來統計呼叫次數的變量 cnt,現在再加個用來統計延時的變量
Latency
。每次執行完函式,就給 bucket 裏的 Latency 變量 加上耗時。再透過滑動視窗獲得對應的 bucket 陣列範圍,計算 Latency 的總和,再除以這些 bucket 裏的呼叫次數 cnt 總和。就像下面這樣:
函式的平均耗時 = Latency總和/cnt總和
於是就得到了這個函式的 平均耗時 。
sentinel-golang
看到這裏,你應該對「怎麽基於滑動視窗和 bucket 實作一個計算 QPS 和平均 Latency 的元件」有一定思路了。但沒程式碼,說再多好像也不夠解渴,對吧?其實,上面的思路,就是阿裏開源的
sentinel-golang
中 QPS 計算元件的實作方式。sentinel-golang 是個著名的服務治理庫,它會基於 QPS 和 Latency 等資訊提供一系列限流熔斷策略。
如果你想了解具體的程式碼實作,可以去看下。連結是:
https://github.com/alibaba/sentinel-golang
但茫茫碼海,從何看起呢?下面給出一些關鍵詞,大家可以作為入口去搜尋看下。首先可以基於
sliding_window_metric.go
裏的
GetQPS
開始看起,它是即時計算 QPS 的入口函式。這裏面會看到很多上面提到的內容細節,其中前面提到的
滑動視窗
,它在 sentinel-golang 中叫
LeapArray
。
bucket環形陣列
,在 sentinel-golang 中叫
AtomicBucketWrapArray
。環形陣列裏存放的 bucket 在程式碼裏就是
MetricBucket
,但需要註意的是 MetricBucket 裏的 count 並不是一個數位型別,而是一個 map 型別,它將上面提到的 cnt 和 Latency 等都作為一種 key-value 來存放。以後想要新增欄位就不需要改程式碼了,提高了程式碼
擴充套件性
。
最後
• QPS 指「每秒查詢數」,是程式設計師必知必會的內容。建議多了解你負責的計畫的 qps,以防面試官一問你三不知。
• 這篇文章介紹了程式碼即時計算 QPS 的實作細節,同時這也是著名的服務治理庫 sentinel-golang 的實作原理,除了 golang 版本,它還有 java,cpp,js 版本的庫,原理都大同小異,看完這篇文章等於一次性學了 4 個庫,這波不虧。
👇🏻 點選下方閱讀原文,獲取魚皮往期編程幹貨。
往期推薦










