
視訊生成模型又有新進展啦!!
由浙大聯合阿裏推出的框架—— MovieDreamer !
MovieDreamer實作了高品質、 長時段 的 連續性 視訊生成,這對於AI電影等長篇視訊制作十分有意義!

掃碼加入AI交流群
獲得更多技術支持和交流

計畫簡介
傳統的視訊生成方法在短視訊內容上取得了一定成果,但在處理復雜敘事和角色一致性上依然表現不好。
這些方法往往無法對復雜的敘事進行建模,也無法在較長時間內保持角色的一致性,而這對於電影等長篇視訊制作至關重要。
MovieDreamer將自回歸模型的優勢與基於擴散的渲染相結合,開創了具有 復雜情節發展 和 高視覺保真度 的 長時 視訊生成。
Demo
下面均是由MovieDreamer結合現有長視訊生成方法所生成的視訊片段。
MovieDreamer➕Luma
MovieDreamer➕their model
能夠看出這些視訊的前後人物相關性以及敘事連貫性都十分優秀,至少能夠讓觀眾感受到故事的存在。👏
下面是MovieDreamer在視訊生成中的人物的細節圖,可以說小編已經真真假假分不清是真人還是AI啦。🤔




技術原理
擴散模型在處理復雜邏輯和長時段敘事方面表現欠佳,但 自回歸 模型在處理 復雜推理和預測未來事件 方面具有明顯優勢。
MovieDreamer利用自回歸模型預測視覺令牌序列,透過擴散渲染將這些令牌轉換為高品質的視訊幀。
其中自回歸模型將 多模態 指令碼作為輸入,並預測關鍵幀的標記。
然後將這些標記渲染成影像,形成用於擴充套件視訊生成的錨幀。
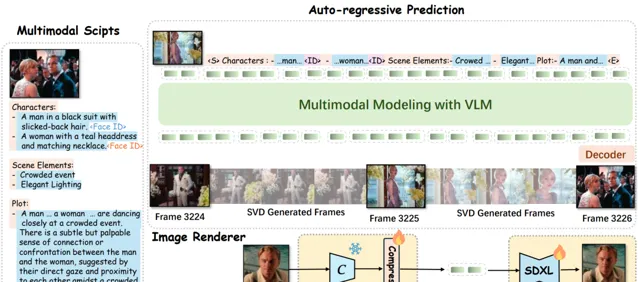
大家可以理解為傳統的電影制作過程,將復雜的故事分解為易於管理的場景拍攝,確保敘事的一致性和角色身份的連貫性。
透過保留ID的渲染器顯著增強了角色的感知身份。

並且MovieDreamer能夠在 小樣本 場景中生成具有更好 ID的結果。

由此MovieDreamer能夠零樣本下在 長時間跨度內保留角色身份 。

MovieDreamer在與其他方法的比較中也能夠達到突出的高品質效果。

MovieDreamer框架實作了高品質的視覺敘事,突破了短視訊生成的局限,為將來的 自動化電影制作 開辟了道路。
也許未來我們看到的許多影片都將由AI來生成,這樣演員是不是就輕松了許多呢??
🔗 計畫連結 :
https://aim-uofa.github.io/MovieDreamer
關註「 開源AI計畫落地 」公眾號
與AI時代更靠近一點
關註「 向量光年 」公眾號
加速全行業向AI的改變
關註「 AGI光年 」公眾號
獲取每日最新咨詢
更多AI資訊,盡在www.dongaigc.com










