量子位 | 公眾號 QbitAI
賽博照妖鏡下,AI美女全變鬼。
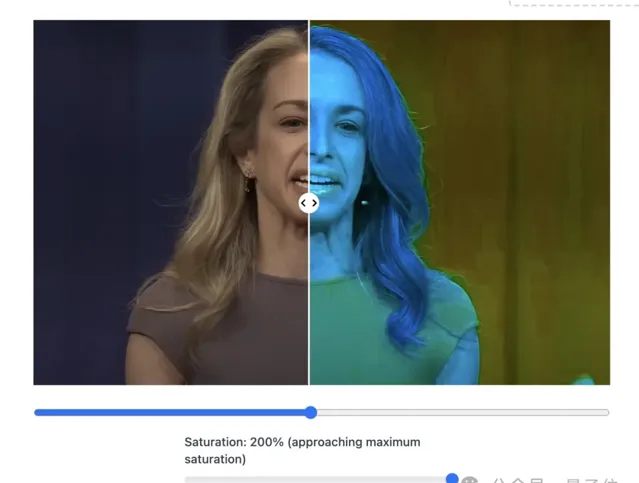
來看它的牙 。

把影像飽和度拉滿,AI人像的牙齒就會變得非常詭異,邊界模糊不清。
整體圖片的顏色也正常,麥克風部份更是奇怪。
對比 真實人類照片 ,則應該是這樣的。
牙齒是清晰的,圖片色塊都是均勻一致的。
這個工具已經開放,人人都能拿著照片去試試。
AI生成視訊中的某一幀,也難逃此大法。
不漏牙的照片也會暴露問題。

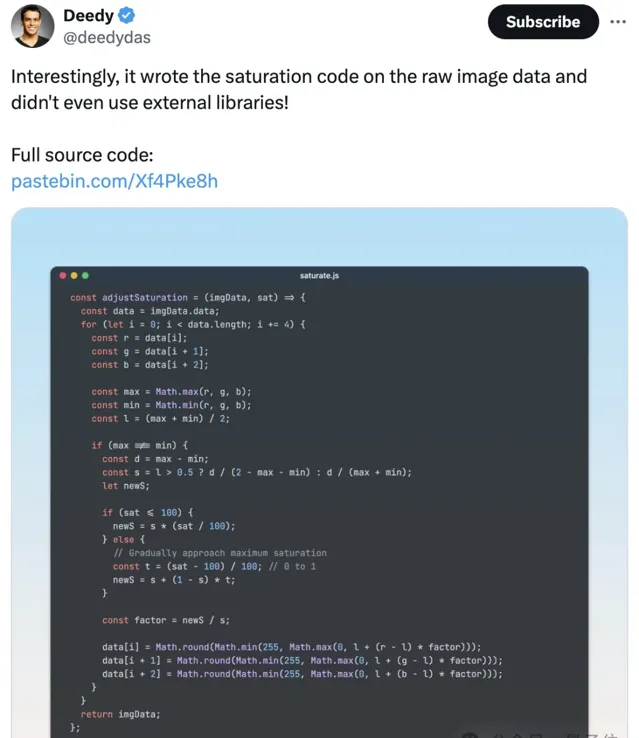
不過BTW,這個工具 出自Claude之手 。用AI破解AI,奇妙的閉環。
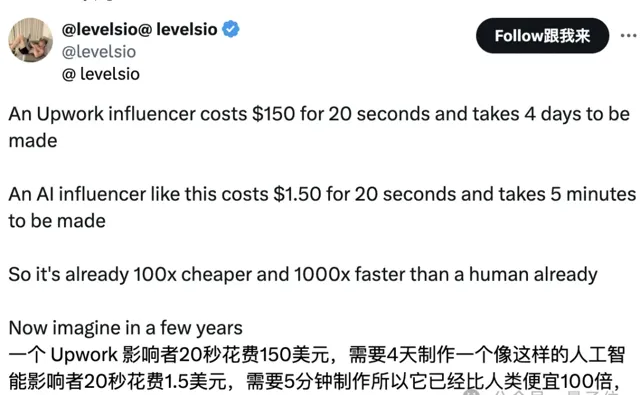
有一說一,最近AI人像太逼真又引發了不小討論,比如一組大火的「TED演講者視訊」,其實沒有一個是真人。
不只是人臉難以區分,就連之前AI的短板——寫字,現在都能完全以假亂真。

更關鍵的是,生成這樣的AI人像,成本也不高。低至5分鐘、每20秒1.5美元(人民幣10塊左右)的價格即可搞定。
這下網友們都坐不住了,紛紛搞起AI打假大賽。
近5千人來討論,這兩張圖到底哪張是真人。
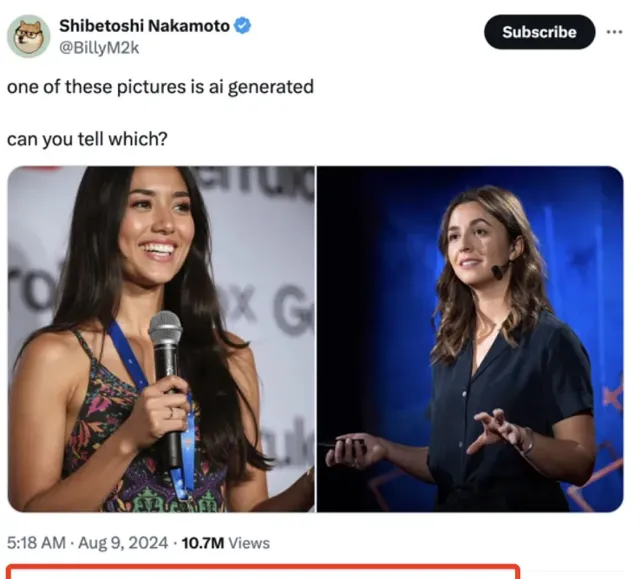
給出的理由五花八門。有人發現文字、花紋細節很抽象,有人則覺得人物眼神很空洞……
最先進的AI們生成人像有啥規律,逐漸被大家摸索出來了。
不看細節已很難分辨
匯總來看,調整飽和度或許是目前最快速辨別的方法。
AI群像照在這種方法下暴露得更加徹底。

不過它存在一個問題。如果影像用JPEG演算法壓縮過後,該方法可能失效。
比如確定這張照片是真人照片。
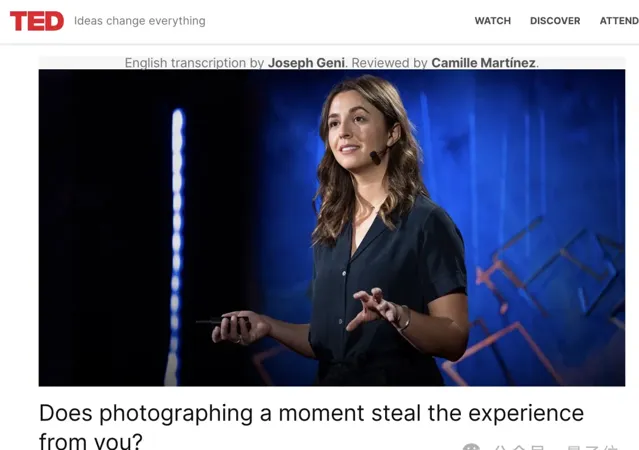
但是由於畫質壓縮以及光線等問題,人物牙齒也有點模糊。

所以網友們還列出了更多分辨人像是否是AI合成的方法。
第一種方法,簡單說就是依靠人類的知識判斷。
由於AI學習影像的方式和人類並不一致,難免無法100%掌握人類視角下的視覺資訊。
造成的結果就是,AI生成的圖片常常包含 與現實世界不符 之處,這就為影像的鑒別提供了著手之處。
用開頭的這張圖片作為例子。
從整體上看,人物的皮膚過於光滑,看不到任何的毛孔,這種過於完美的特征反而增加了不真實感。
當然這種「不真實感」並不完全等同於「造假」,畢竟經過磨皮處理的圖片同樣看不到毛孔。
但這也並非唯一的判斷因素,AI在圖片中留下的與常識的出入也未必只有一處。

實際上,這張圖只要稍微看以下細節,就能看到一個比較明顯的特征—— 胸牌上方掛鉤奇特的連線方式 。

還有在高飽和度模式下露出破綻的麥克風,放大之後直接用肉眼也能看出端倪。
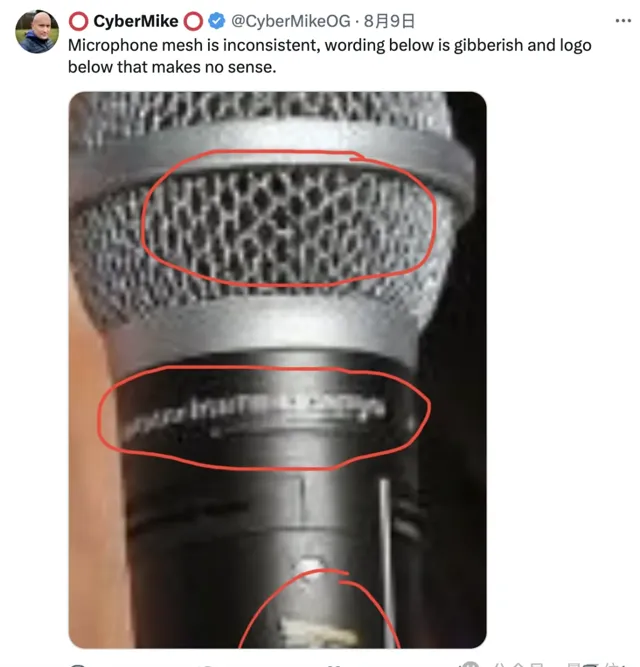
更為隱蔽的是,頭發末端有幾根毛發的位置很不合理,但這樣的特征,恐怕要擁有列文虎克級別的視力才能看到了。
不過,隨著生成技術的進步,能夠找到的特征越來越隱蔽,也是一個無法避免的趨勢。

還有一種方法是看文字,雖然AI在字型的刻畫上正逐漸克服「鬼畫符」的問題,但正確地渲染出有正確實際含義的文字還存在一些困難。
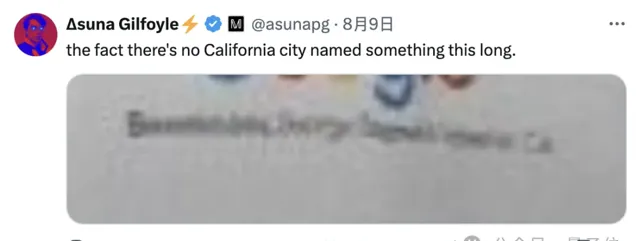
比如有網友發現,照片中的人佩戴的胸牌上,Google標誌的下方最後一行字中的兩個字母是「CA」,表示美國加州,前面的一大長串應該是城市名。
但實際上,加州根本沒有名字如此之長的城市。
除了這些物體本身的細節,還有光線、陰影等資訊也可以用來判斷真偽。
這張圖片是從一段視訊當中提取的,在它所在的視訊當中還有這樣的一幀。
在話筒右側的位置,有一片十分詭異的陰影,這片陰影對應的是人物的一只手,顯然AI在這裏處理得有所欠缺。

說到視訊,由於涉及前後內容一致性,AI倒是比在靜態影像中更容易露出 雞腳 馬腳。

還有一些特征不算「常識錯誤」,但也體現出了AI在生成影像時的一些偏好。
比如這四張圖,都是AI合成的「普通人」(average people),有沒有發現什麽共同之處?

有網友表示,這四張圖裏的人,沒有一個是笑臉,這點似乎就體現了AI生圖的某種特征。
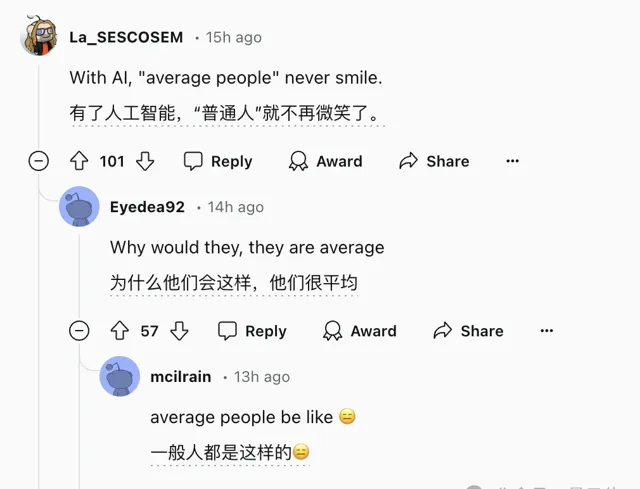
針對這幾張圖而言確實如此,但這樣的判斷方式很難形成系統,畢竟不同的AI繪圖工具,特點也都不盡相同。
總之,為了應對逐漸進步的AI,一方面可以加大「列文虎克」的力度,一方面還可以引入像拉高飽和度這樣的影像處理技術。
但如果這樣的「量變」積累得越來越多,肉眼判斷也會越來越困難,影像飽和度可能也有被AI攻破的一天。
所以人們也在轉變思路,想到了「以模制模」的方法,用AI生成的圖片訓練檢測模型,從影像中分析更多特征。
比如AI生成的影像在頻譜、雜訊分布等方面存在許多特點,這些特點依靠肉眼無法捕捉,但AI卻能看得很清楚。
當然,也不排除檢測方法落後、跟不上模型變化,甚至模型開發者專門進行對抗性開發的可能。
比如前文一直在討論的這張圖片,某AI檢測工具認為它是AI合成的機率只有2%。
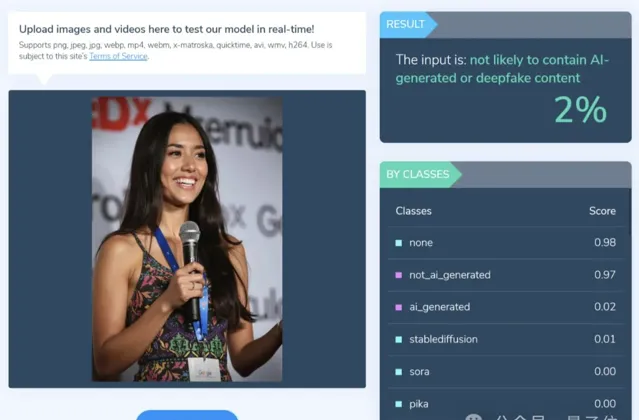
但AI造假和AI檢測之間的賽局過程,本身就是一場「貓鼠遊戲」。
所以在檢測之外,可能還需要模型的開發者也負起一些責任,例如給AI生成的圖片打上隱形浮水印,讓AI造假無處遁形。
AI魔高一尺
值得一提的是,如上引發恐慌的AI人像,不少都是由最近爆火的 Flux 生成/參與制作。
甚至大家已經開始預設,效果太好難以分辨的,就是Flux做的。
這些精美的假TED演講照片,都是出自它手。

還有人用Flux和Gen-3一起做出了精美的護膚品廣告。
以及多角度的各種合成效果。
它很好解決了AI畫手、AI生成圖片中文字等問題。
這直接導致現在人類區分AI畫圖,不能再直接看手和文字了,只能盯著蛛絲馬跡猜。
Flux應該是在手部、文字等指標上加強了訓練。
這也意味著,如果當下的AI繼續在紋理細節、色彩等方面下功夫訓練,等到下一代AI畫圖模型出來時,人類的辨認方法可能又要失效了……
而且Flux還是開源、膝上型電腦上可執行的。不少人現在已經在Forget Midjourney了。
從Stable Diffusion到Flux,用了2年。
從「威爾史密斯吃面條」到「Tedx演講者」,用了1年。
真不知道以後為了分辨AI生成,人類得想出哪些歪招了……
參考連結:
[1]https://x.com/ChuckBaggett/status/1822686462044754160
[2]https://www.reddit.com/r/artificial/comments/1epjlbl/average_looking_people/
[3]https://www.reddit.com/r/ChatGPT/comments/1epeshq/these_are_all_ai/
[4]https://x.com/levelsio/status/1822751995012268062
— 完 —











