大模型的強大能力給我們的現在的生活帶來了許多便利,但全球的研究人員們沒有就此止步~
因為AGI的實作是我們的最終目標!🎯
今天給大家介紹的模型無疑為AGI的未來打下了深厚的基礎。
它就是由Meta公司FAIR團隊研發的多模態模型—— Chameleon !
Chameleon是一款能夠 理解和生成任意序列的影像和文本 的 混合多模態 模型。
使用者可以輸入一個文本提示,要求生成一系列相關影像和描述。

掃碼加入AI交流群
獲得更多技術支持和交流

計畫簡介
多模態基礎模型由於能處理更加復雜多變的任務得到了廣泛的套用。
然而,當前的多模態模型仍然傾向於分開處理不同的模態,使用模態特定的編碼器或解碼器。
這種做法限制了模型跨模態整合資訊和生成包含任意序列影像和文本的多模態文件的能力。
作為能夠理解和生成任意序列影像和文本的混合模態模型的Chameleon可謂是這一技術突破的啟明燈✨
Demo
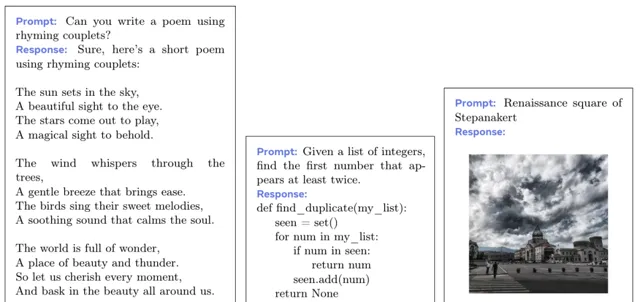
下面展示了透過給模型提供文字以及影像等Prompt,模型給予的影像結合文字的回答。
👇下面是一個分析所提供照片的細節,並讓模型分析變色龍的融入的難度的同時生成一張變色龍的照片的案例。

👇下面是一個讓模型提供一個用所給圖片制作食物的完整而詳細的食譜的案例。

👇下面是一個讓模型科普所給圖片中的小狗的種類相關的知識並生成一張同品種的小狗的案例。

👇下面是一個讓模型生成一張指定種類的熊並對其進行介紹的案例。

計畫原理
Chameleon模型采用了統一的基於token的表示方法,將影像量化為離散的tokens,類似於文本中的單詞。
這種方法允許使用相同的Transformer架構處理影像和文本tokens序列,而無需分離的影像或文本編碼器。
Chameleon的融合方法將所有模態從一開始就投射到一個共享的表示空間中,實作了跨模態的無縫推理和生成。

團隊還展示了如何將用於文本生成的監督微調方法適應混合模式設定,從而實作大規模的強對齊。
在微調期間,每個數據集例項都包含一個成對的提示及其對應的答案。
為了提高效率,團隊將盡可能多的提示和答案打包到每個序列中,插入一個不同的標記來劃分提示的結束和答案的開始。
下面是微調時的任務類別以及提示範例。

因此,Chameleon既可以推理任意混合模式文件,也可以生成任意混合模式文件。
同時也可以處理各種各樣的單模態或多模態復雜任務統統不在話下。👏
下面分別展示了Chameleon處理文本生成、編碼、影像生成、視覺問答、影像文字混合生成等各種任務。

Chameleon模型在多個任務上進行了廣泛的評估,結果表明,Chameleon不僅在影像描述任務上實作了最先進的效能,還在僅文本任務上超越了Llama-2。

此外,Chameleon在長篇混合模式生成評估中,匹配或超越了包括Gemini Pro和GPT-4V在內的更大模型的效能。
Chameleon的出現無疑代表了實作靈活推理和生成多模態內容的統一基礎模型的一個重要進步。
小編期待Chameleon未來能夠在更多領域發揮重要作用!
🔗 計畫連結 :
https://github.com/facebookresearch/chameleon
關註「 向量光年 」公眾號
加速全行業向AI的改變
關註「 開源AI計畫落地 」公眾號
與AI時代更靠近一點
關註「 AGI光年 」公眾號
獲取每日最新咨詢











