
HashMap相信所有學Java的都一定不會感到陌生,作為一個非常重用且非常實用的Java提供的容器,它在我們的程式碼裏面隨處可見。因此遍歷操作也是我們經常會使用到的。HashMap的遍歷方式現如今有非常多種:
使用叠代器(Iterator)。
使用
keySet()獲取鍵的集合,然後透過增強的 for 迴圈遍歷鍵。使用
entrySet()獲取鍵值對的集合,然後透過增強的 for 迴圈遍歷鍵值對。使用 Java 8+ 的 Lambda 運算式和流。
以上遍歷方式的孰優孰劣,在【阿裏巴巴開發手冊】中寫道:

這裏推薦使用的是
entrySet
進行遍歷,在Java8中推薦使用
Map.forEach()
。給出的理由是
遍歷次數
上的不同。
keySet遍歷,需要經過 兩次 遍歷。
entrySet遍歷,只需要 一次 遍歷。
其中keySet遍歷了兩次,一次是轉為Iterator物件,另一次是從hashMap中取出key所對應的value。
其中後面一段話很好理解,但是前面這句話卻有點繞,為什麽轉換成了Iterator遍歷了一次?
我查閱了各個平台對HashMap的遍歷,其中都沒有或者原封不動的照搬上句話。(當然也可能是我沒有查閱到靠譜的文章,歡迎指正)
keySet如何遍歷了兩次
我們首先寫一段程式碼,使用keySet遍歷Map。
public class Test {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("k1", "v1");
map.put("k2", "v2");
map.put("k3", "v3");
for (String key : map.keySet()) {
String value = map.get(key);
System.out.println(key + ":" + value);
}
}
}
執行結果顯而易見的是
k1:v1
k2:v2
k3:v3
兩次遍歷,第一次遍歷所描述的是轉為Iterator物件我們好像沒有從程式碼中看見,我們看到的後面所描述的遍歷,也就是遍歷
map,keySet()
所返回的
Set
集合中的key,然後去HashMap中拿取value的。
Iterator物件呢?如何遍歷轉換為Iterator物件的呢?

首先我們這種遍歷方式大家都應該知道是叫:
增強for迴圈,for-each
這是一種Java的語法糖~。
我們可以透過反編譯,或者直接透過Idea在 class檔中檢視對應的 class檔
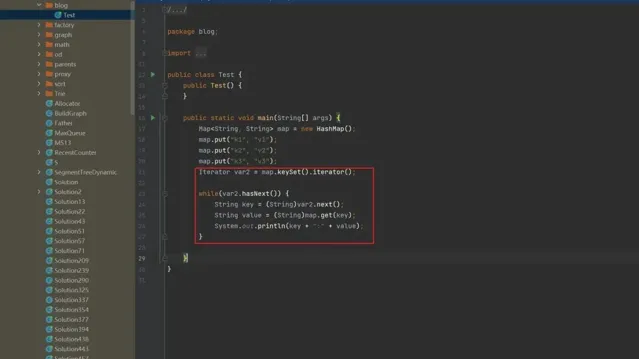
public class Test {
public Test() {
}
public static void main(String[] args) {
Map<String, String> map = new HashMap();
map.put("k1", "v1");
map.put("k2", "v2");
map.put("k3", "v3");
Iterator var2 = map.keySet().iterator();
while(var2.hasNext()) {
String key = (String)var2.next();
String value = (String)map.get(key);
System.out.println(key + ":" + value);
}
}
}
和我們編寫的是存在差異的,其中我們可以看到其中透過
map.keySet().iterator()
獲取到了我們所需要看見的
Iterator
物件。
那麽它又是怎麽轉換成的呢?為什麽需要遍歷呢?我們檢視
iterator()
方法
1 iterator()
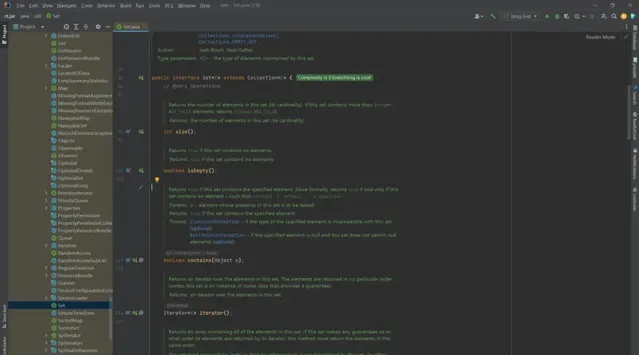
發現是Set定義的一個介面。返回此集合中元素的叠代器
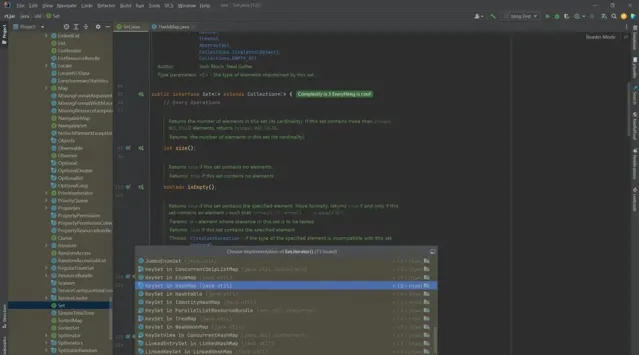
2 HashMap.KeySet#iterator()
我們檢視HashMap中keySet類對該方法的實作。
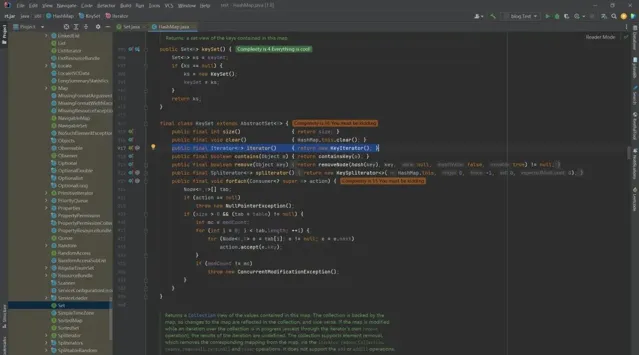
final class KeySet extends AbstractSet<K> {
public final int size() { return size; }
public final void clear() { HashMap.this.clear(); }
public final Iterator<K> iterator() { return new KeyIterator(); }
public final boolean contains(Object o) { return containsKey(o); }
public final boolean remove(Object key) {
return removeNode(hash(key), key, null, false, true) != null;
}
public final Spliterator<K> spliterator() {
return new KeySpliterator<>(HashMap.this, 0, -1, 0, 0);
}
public final void forEach(Consumer<? super K> action) {
Node<K,V>[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next)
action.accept(e.key);
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
}
其中的iterator()方法返回的是一個
KeyIterator
物件,那麽究竟是在哪裏進行了遍歷呢?我們接著往下看去。
3 HashMap.KeyIterator
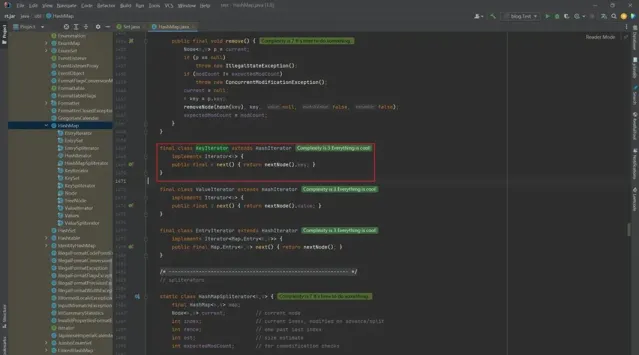
final class KeyIterator extends HashIterator
implements Iterator<K> {
public final K next() { return nextNode().key; }
}
這個類也很簡單:
繼承了
HashIterator類。實作了
Iterator介面。一個
next()方法。
還是沒有看見哪裏進行了遍歷,那麽我們繼續檢視
HashIterator
類
4 HashMap.HashIterator
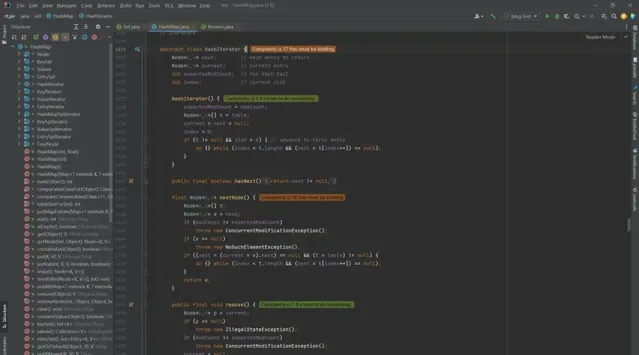
abstract class HashIterator {
Node<K,V> next; // next entry to return
Node<K,V> current; // current entry
int expectedModCount; // for fast-fail
int index; // current slot
HashIterator() {
expectedModCount = modCount;
Node<K,V>[] t = table;
current = next = null;
index = 0;
if (t != null && size > 0) { // advance to first entry
do {} while (index < t.length && (next = t[index++]) == null);
}
}
public final boolean hasNext() {
return next != null;
}
final Node<K,V> nextNode() {
Node<K,V>[] t;
Node<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
if ((next = (current = e).next) == null && (t = table) != null) {
do {} while (index < t.length && (next = t[index++]) == null);
}
return e;
}
public final void remove() {
Node<K,V> p = current;
if (p == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
K key = p.key;
removeNode(hash(key), key, null, false, false);
expectedModCount = modCount;
}
}
我們可以發現這個構造器中存在了一個
do-while
迴圈操作,目的是找到一個第一個不為空的
entry
。
HashIterator() {
expectedModCount = modCount;
Node<K,V>[] t = table;
current = next = null;
index = 0;
if (t != null && size > 0) { // advance to first entry
do {} while (index < t.length && (next = t[index++]) == null);
}
}
而
KeyIterator
是extend
HashIterator
物件的。這裏涉及到了繼承的相關概念,大家忘記的可以找相關的文章看看,或者我也可以寫一篇~~dog。
例如兩個類
public class Father {
public Father(){
System.out.println("father");
}
}
public class Son extends Father{
public static void main(String[] args) {
Son son = new Son();
}
}
建立Son物件的同時,會執行Father構造器。也就會打印出
father
這句話。
那麽這個迴圈操作就是我們要找的迴圈操作了。
Part3 總結
使用keySet遍歷,其實內部是使用了對應的
iterator()方法。iterator()方法是建立了一個KeyIterator物件。KeyIterator物件extendHashIterator物件。HashIterator物件的構造方法中,會遍歷找到第一個不為空的entry。
keySet->iterator()->KeyIterator->HashIterator
>>
END
精品資料,超贊福利,免費領
微信掃碼/長按辨識 添加【技術交流群】
群內每天分享精品學習資料

最近開發整理了一個用於速刷面試題的小程式;其中收錄了上千道常見面試題及答案(包含基礎、並行、JVM、MySQL、Redis、Spring、SpringMVC、SpringBoot、SpringCloud、訊息佇列等多個型別),歡迎您的使用。
👇👇
👇點選"閱讀原文",獲取更多資料(持續更新中)











