☞ 【幹貨】
☞ 【幹貨】
轉自:一口Linux
Linux 記憶體是後台開發人員,需要深入了解的電腦資源。合理的使用記憶體,有助於提升機器的效能和穩定性。本文主要介紹 Linu x 記憶體組織結構和頁面布局,記憶體碎片產生原因和最佳化演算法,Linux 內核幾種記憶體管理的方法,記憶體使用場景以及記憶體使用的那些坑。 從記憶體的原理和結構,到記憶體的演算法最佳化,再到使用場景,去探尋記憶體管理的機制和奧秘。
一、走進 linux 記憶體
1、記憶體是什麽?
1)記憶體又稱主記憶體,是 CPU 能直接尋址的儲存空間,由半導體器件制成
2)記憶體的特點是存取速率快
2、記憶體的作用
1)暫時存放 cpu 的運算數據
2)硬碟等外部記憶體交換的數據
3)保障 cpu 計算的穩定性和高效能

二、 Linux 記憶體地址空間
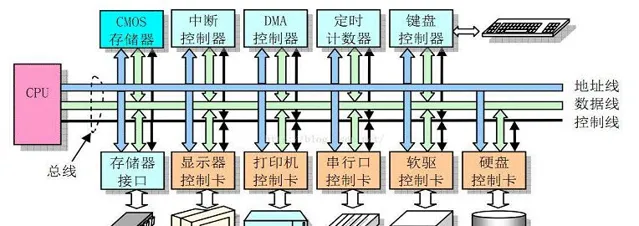
1、Linux 記憶體地址空間 Linux 記憶體管理全貌

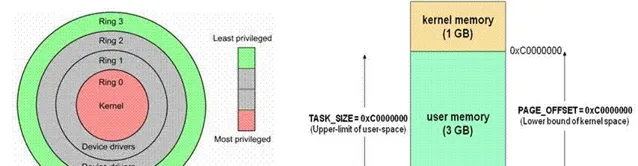
2、記憶體地址——使用者態&內核態
使用者態:Ring3 執行於使用者態的程式碼則要受到處理器的諸多
內核態:Ring0 在處理器的儲存保護中,核心態
使用者態切換到內核態的 3 種方式:系統呼叫、異常、外設中斷
區別:每個行程都有完全屬於自己的,獨立的,不被幹擾的記憶體空間;使用者態的程式就不能隨意操作內核地址空間,具有一定的安全保護作用;內核態執行緒共享內核地址空間;
3、記憶體地址——MMU 地址轉換
MMU 是一種硬體電路,它包含兩個部件,一個是分段部件,一個是分頁部件
分段機制把一個邏輯地址轉換為線性地址
分頁機制把一個線性地址轉換為實體位址
4、記憶體地址——分段機制
1) 段選擇符
為了方便快速檢索段選擇符,處理器提供了 6 個分段寄存器來緩存段選擇符,它們是:cs,ss,ds,es,fs 和 gs
段的基地址(Base Address):線上性地址空間中段的起始地址
段的界限(Limit):在虛擬地址空間中,段內可以使用的最大偏移量
2) 分段實作
邏輯地址的段寄存器中的值提供段描述符,然後從段描述符中得到段基址和段界限,然後加上邏輯地址的偏移量,就得到了線性地址

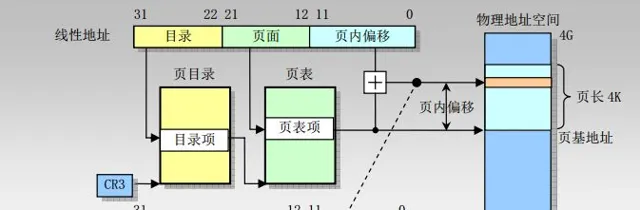
5、記憶體地址——分頁機制(32 位)
分頁機制是在分段機制之後進行的,它進一步將線性地址轉換為實體位址
10 位頁目錄,10 位頁表項, 12 位頁偏移地址
單頁的大小為 4KB
6、使用者態地址空間
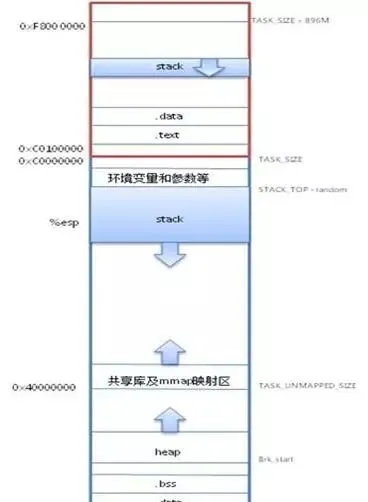
TEXT:程式碼段可執行程式碼、字串字面值、唯讀變量
DATA:數據段,對映程式中已經初始化的全域變量
BSS 段:存放程式中未初始化的全域變量
HEAP:執行時的堆,在程式執行中使用 malloc 申請的記憶體區域
MMAP:共享庫及匿名檔的對映區域
STACK:使用者行程棧
7、內核態地址空間
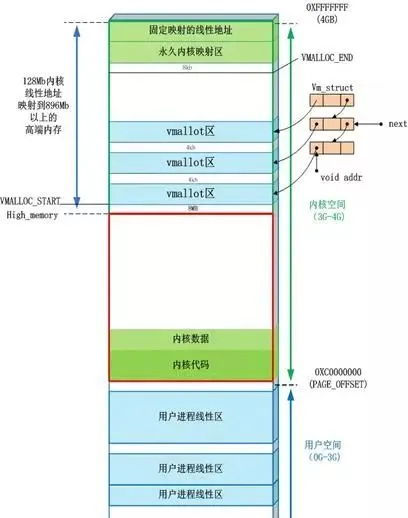
直接對映區:線性空間中從 3G 開始最大 896M 的區間,為直接記憶體對映區
動態記憶體對映區:該區域由內核函式 vmalloc 來分配
永久記憶體對映區:該區域可存取高端記憶體
固定對映區:該區域和 4G 的頂端只有 4k 的隔離帶,其每個地址項都服務於特定的用途,如:ACPI_BASE 等
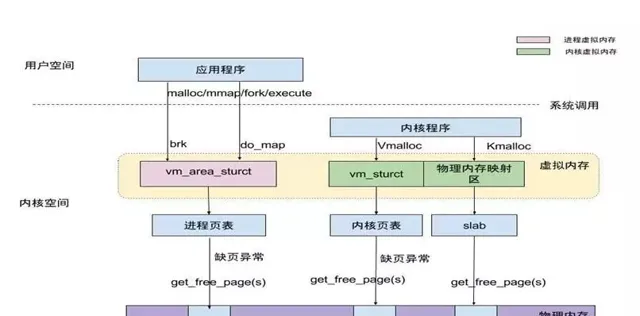
8、行程記憶體空間
使用者行程通常情況只能存取使用者空間的虛擬地址,不能存取內核空間虛擬地址
內核空間是由內核負責對映,不會跟著行程變化;內核空間地址有自己對應的頁表,使用者行程各自有不同額頁表
三、 Linux 記憶體分配演算法
記憶體管理演算法——對討厭自己管理記憶體的人來說是天賜的禮物
1、記憶體碎片
1) 基本原理
產生原因:記憶體分配較小,並且分配的這些小的記憶體生存周期又較長,反復申請後將產生記憶體碎片的出現
優點:提高分配速度,便於記憶體管理,防止記憶體泄露
缺點:大量的記憶體碎片會使系統緩慢,記憶體使用率低,浪費大
2) 如何避免記憶體碎片
少用動態記憶體分配的函式(盡量使用棧空間)
分配記憶體和釋放的記憶體盡量在同一個函式中
盡量一次性申請較大的記憶體,而不要反復申請小記憶體
盡可能申請大塊的 2 的指數冪大小的記憶體空間
外部碎片避免——夥伴系統演算法
內部碎片避免——slab 演算法
自己進行記憶體管理工作,設計記憶體池
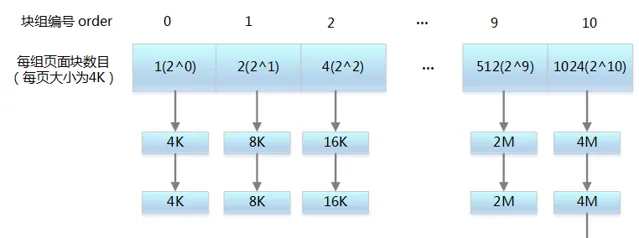
2、夥伴系統演算法——組織結構
1) 概念
為內核提供了一種用於分配一組連續的頁而建立的一種高效的分配策略,並有效的解決了外碎片問題
分配的記憶體區是以頁框為基本單位的
2) 外部碎片
外部碎片指的是還沒有被分配出去(不屬於任何行程),但由於太小了無法分配給申請記憶體空間的新行程的記憶體空閑區域3) 組織結構
把所有的空閑頁分組為 11 個塊連結串列,每個塊連結串列分別包含大小為 1,2,4,8,16,32,64,128,256,512 和 1024 個連續頁框的頁塊。最大可以申請 1024 個連續頁,對應 4MB 大小的連續記憶體
3、夥伴系統演算法——申請和回收
1) 申請演算法
申請 2^i 個頁塊儲存空間,如果 2^i 對應的塊連結串列有空閑頁塊,則分配給套用
如果沒有空閑頁塊,則尋找 2^(i 1) 對應的塊連結串列是否有空閑頁塊,如果有,則分配 2^i 塊連結串列節點給套用,另外 2^i 塊連結串列節點插入到 2^i 對應的塊連結串列中
如果 2^(i 1) 塊連結串列中沒有空閑頁塊,則重復步驟 2,直到找到有空閑頁塊的塊連結串列
如果仍然沒有,則返回記憶體分配失敗
2) 回收演算法
釋放 2^i 個頁塊儲存空間,尋找 2^i 個頁塊對應的塊連結串列,是否有與其實體位址是連續的頁塊,如果沒有,則無需合並
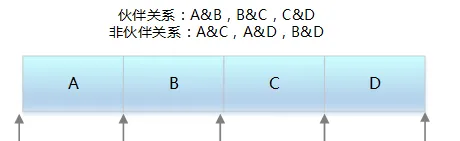
如果有,則合並成 2^(i 1)的頁塊,以此類推,繼續尋找下一級塊連結,直到不能合並為止
3) 條件
兩個塊具有相同的大小
它們的實體位址是連續的
頁塊大小相同
4、如何分配 4M 以上記憶體?
1) 為何限制大塊記憶體分配
分配的記憶體越大, 失敗的可能性越大
大塊記憶體使用場景少
2) 內核中獲取 4M 以上大記憶體的方法
修改 MAX_ORDER, 重新編譯內核
內核啟動選型傳遞"mem="參數, 如"mem=80M,預留部份記憶體;然後透過
request_mem_region 和 ioremap_nocache 將預留的記憶體對映到模組中。需要修改內核啟動參數, 無需重新編譯內核. 但這種方法不支持 x86 架構, 只支持 ARM, PowerPC 等非 x86 架構
在 start_kernel 中 mem_init 函式之前呼叫 alloc_boot_mem 函式預分配大塊記憶體, 需要重新編譯內核
vmalloc 函式,內核程式碼使用它來分配在虛擬記憶體中連續但在實體記憶體中不一定連續的記憶體
5、夥伴系統——反碎片機制
1) 不可移動頁
這些頁在記憶體中有固定的位置,不能夠移動,也不可回收
內核程式碼段,數據段,內核 kmalloc() 出來的記憶體,內核執行緒占用的記憶體等
2) 可回收頁
這些頁不能移動,但可以刪除。內核在回收頁占據了太多的記憶體時或者記憶體短缺時進行頁面回收3) 可移動頁
這些頁可以任意移動,使用者空間應用程式使用的頁都屬於該類別。它們是透過頁表對映的
當它們移動到新的位置,頁表項也會相應的更新
6、slab 演算法——基本原理
1) 基本概念
Linux 所使用的 slab 分配器的基礎是 Jeff Bonwick 為 SunOS 作業系統首次引入的一種演算法
它的基本思想是將內核中經常使用的物件放到快取中,並且由系統保持為初始的可利用狀態。比如行程描述符,內核中會頻繁對此數據進行申請和釋放
2) 內部碎片
已經被分配出去的的記憶體空間大於請求所需的記憶體空間3) 基本目標
減少夥伴演算法在分配小塊連續記憶體時所產生的內部碎片
將頻繁使用的物件緩存起來,減少分配、初始化和釋放物件的時間開銷
透過著色技術調整物件以更好的使用硬體快取
7、slab 分配器的結構
由於物件是從 slab 中分配和釋放的,因此單個 slab 可以在 slab 列表之間進行移動
slabs_empty 列表中的 slab 是進行回收(reaping)的主要備選物件
slab 還支持通用物件的初始化,從而避免了為同一目而對一個物件重復進行初始化
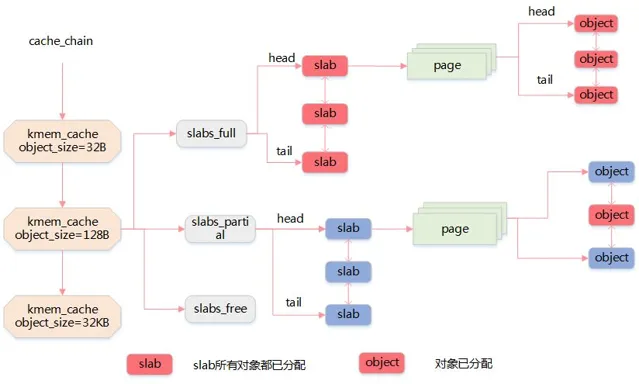
8、slab 快取
1) 普通快取
slab 分配器所提供的小塊連續記憶體的分配是透過通用快取實作的
通用快取所提供的物件具有幾何分布的大小,範圍為 32 到 131072 字節。
內核中提供了 kmalloc() 和 kfree() 兩個介面分別進行記憶體的申請和釋放
2) 專用快取
內核為專用快取的申請和釋放提供了一套完整的介面,根據所傳入的參數為具體的物件分配 slab 緩存
kmem_cache_create() 用於對一個指定的物件建立快取。它從 cache_cache 普通快取中為新的專有緩存分配一個快取描述符,並把這個描述符插入到快取描述符形成的 cache_chain 連結串列中
kmem_cache_alloc() 在其參數所指定的快取中分配一個 slab。相反, kmem_cache_free() 在其參數所指定的快取中釋放一個 slab
9、內核態記憶體池
1) 基本原理
先申請分配一定數量的、大小相等(一般情況下) 的記憶體塊留作備用
當有新的記憶體需求時,就從記憶體池中分出一部份記憶體塊,若記憶體塊不夠再繼續申請新的記憶體
這樣做的一個顯著優點是盡量避免了記憶體碎片,使得記憶體分配效率得到提升
2) 內核 API
mempool_create 建立記憶體池物件
mempool_alloc 分配函式獲得該物件
mempool_free 釋放一個物件
mempool_destroy 銷毀記憶體池
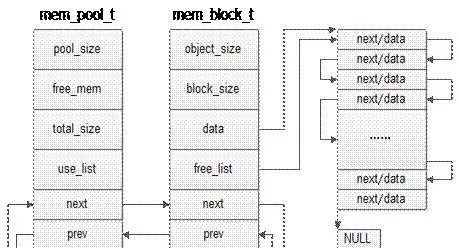
10、使用者態記憶體池
1) C++ 例項

11、DMA 記憶體
1) 什麽是 DMA
直接記憶體存取是一種硬體機制,它允許外圍裝置和主記憶體之間直接傳輸它們的 I/O 數據,而不需要系統處理器的參與2) DMA 控制器的功能
能向 CPU 發出系統保持(HOLD)訊號,提出匯流排接管請求
當 CPU 發出允許接管訊號後,負責對匯流排的控制,進入 DMA 方式
能對記憶體尋址及能修改地址指標,實作對記憶體的讀寫操作
能決定本次 DMA 傳送的字節數,判斷 DMA 傳送是否結束
發出 DMA 結束訊號,使 CPU 恢復正常工作狀態
2) DMA 訊號
DREQ:DMA 請求訊號。是外設向 DMA 控制器提出要求,DMA 操作的申請訊號
DACK:DMA 響應訊號。是 DMA 控制器向提出 DMA 請求的外設表示已收到請求和正進行處理的訊號
HRQ:DMA 控制器向 CPU 發出的訊號,要求接管匯流排的請求訊號。
HLDA:CPU 向 DMA 控制器發出的訊號,允許接管匯流排的應答訊號:
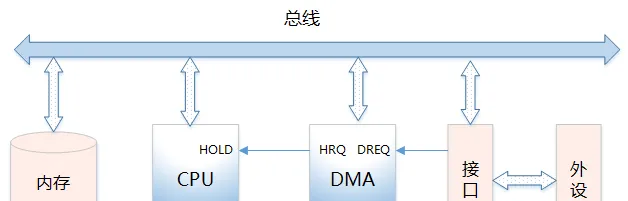
四、 記憶體使用場景
out of memory 的時代過去了嗎?no,記憶體再充足也不可任性使用。
1、記憶體的使用場景
page 管理
slab(kmalloc、記憶體池)
使用者態記憶體使用(malloc、relloc 檔對映、共享記憶體)
程式的記憶體 map(棧、堆、code、data)
內核和使用者態的數據傳遞(copy_from_user、copy_to_user)
記憶體對映(硬體寄存器、保留記憶體)
DMA 記憶體
2、使用者態記憶體分配函式
alloca 是向棧申請記憶體,因此無需釋放
malloc 所分配的記憶體空間未被初始化,使用 malloc() 函式的程式開始時(記憶體空間還沒有被重新分配) 能正常執行,但經過一段時間後(記憶體空間已被重新分配) 可能會出現問題
calloc 會將所分配的記憶體空間中的每一位都初始化為零
realloc 擴充套件現有記憶體空間大小
a) 如果當前連續記憶體塊足夠 realloc 的話,只是將 p 所指向的空間擴大,並返回 p 的指標地址。這個時候 q 和 p 指向的地址是一樣的
b) 如果當前連續記憶體塊不夠長度,再找一個足夠長的地方,分配一塊新的記憶體,q,並將 p 指向的內容 copy 到 q,返回 q。並將 p 所指向的記憶體空間刪除,微信搜尋公眾號:Linux技術迷,回復:linux 領取資料 。
3、內核態記憶體分配函式
函式分配原理最大記憶體其他_get_free_pages直接對頁框進行操作4MB適用於分配較大量的連續實體記憶體kmem_cache_alloc基於 slab 機制實作128KB適合需要頻繁申請釋放相同大小記憶體塊時使用kmalloc基於 kmem_cache_alloc 實作128KB最常見的分配方式,需要小於頁框大小的記憶體時可以使用vmalloc建立非連續實體記憶體到虛擬地址的對映物理不連續,適合需要大記憶體,但是對地址連續性沒有要求的場合dma_alloc_coherent基於_alloc_pages 實作4MB適用於 DMA 操作ioremap實作已知實體位址到虛擬地址的對映適用於實體位址已知的場合,如裝置驅動alloc_bootmem在啟動 kernel 時,預留一段記憶體,內核看不見小於實體記憶體大小,記憶體管理要求較高
4、malloc 申請記憶體
呼叫 malloc 函式時,它沿 free_chuck_list 連線表尋找一個大到足以滿足使用者請求所需要的記憶體塊
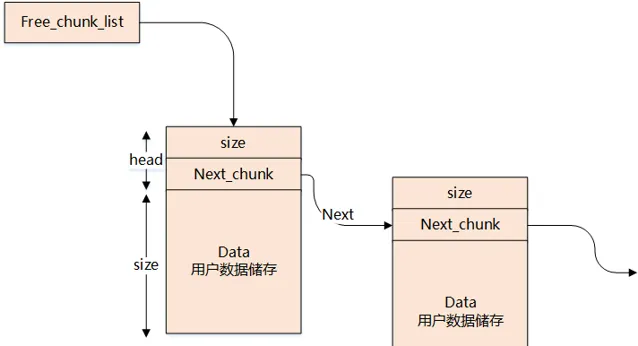
free_chuck_list 連線表的主要工作是維護一個空閑的堆空間緩沖區連結串列
如果空間緩沖區連結串列沒有找到對應的節點,需要透過系統呼叫 sys_brk 延伸行程的棧空間
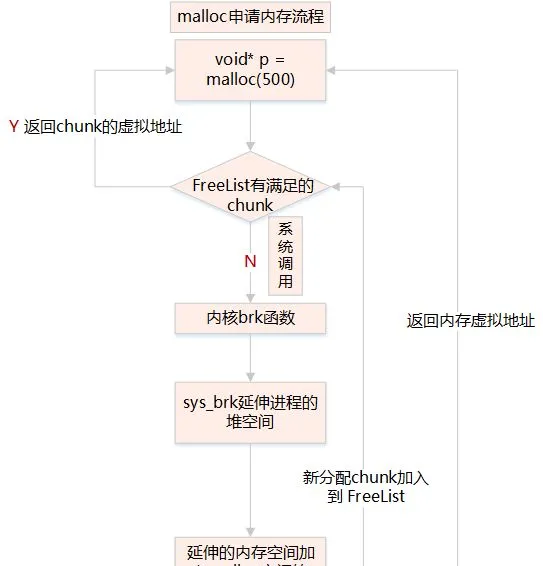
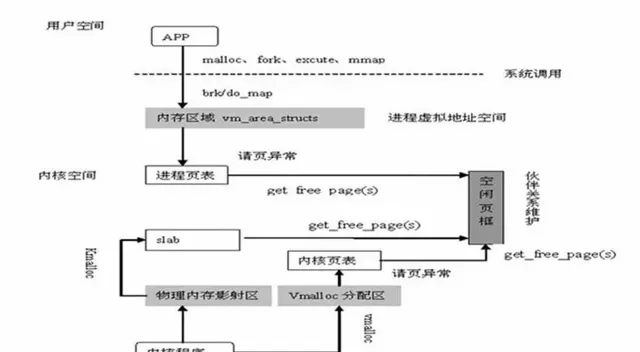
5、缺頁異常
透過 get_free_pages 申請一個或多個物理頁面
換算 addr 在行程 pdg 對映中所在的 pte 地址
將 addr 對應的 pte 設定為物理頁面的首地址
系統呼叫:Brk—申請記憶體小於等於 128kb,do_map—申請記憶體大於 128kb
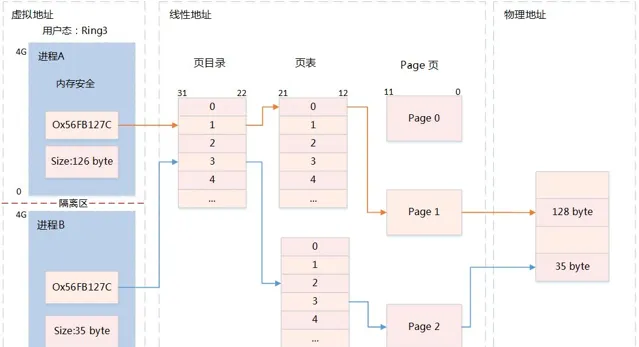
6、使用者行程存取記憶體分析
使用者態行程獨占虛擬地址空間,兩個行程的虛擬地址可相同
在存取使用者態虛擬地址空間時,如果沒有對映實體位址,透過系統呼叫發出缺頁異常
缺頁異常陷入內核,分配實體位址空間,與使用者態虛擬地址建立對映
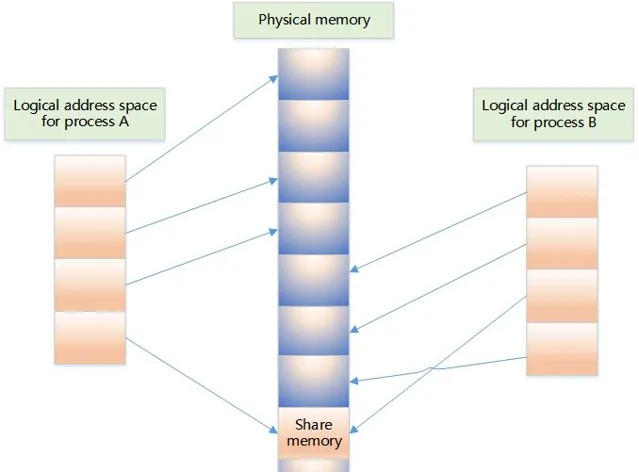
7、共享記憶體
1) 原理
它允許多個不相關的行程去存取同一部份邏輯記憶體
兩個執行中的行程之間傳輸數據,共享記憶體將是一種效率極高的解決方案
兩個執行中的行程共享數據,是行程間通訊的高效方法,可有效減少數據拷貝的次數
2) shm 介面
shmget 建立共享記憶體
shmat 啟動對該共享記憶體的存取,並把共享記憶體連線到當前行程的地址空間
shmdt 將共享記憶體從當前行程中分離
五、 記憶體使用那些坑
1、C 記憶體泄露
在類的建構函式和解構函式中沒有匹配地呼叫 new 和 delete 函式

沒有正確地清除巢狀的物件指標
沒有將基礎類別的解構函式定義為虛擬函式
當基礎類別的指標指向子類別物件時,如果基礎類別的解構函式不是 virtual,那麽子類別的解構函式將不會被呼叫,子類別的資源沒有得到正確釋放,因此造成記憶體泄露
缺少拷貝建構函式,按值傳遞會呼叫(拷貝)建構函式,參照傳遞不會呼叫
指向物件的指標陣列不等同於物件陣列,陣列中存放的是指向物件的指標,不僅要釋放每個物件的空間,還要釋放每個指標的空間
缺少多載設定運算子,也是逐個成員拷貝的方式復制物件,如果這個類的大小是可變的,那麽結果就是造成記憶體泄露
2、C 野指標
指標變量沒有初始化
指標被 free 或 delete 後,沒有設定為 NULL
指標操作超越了變量的作用範圍,比如返回指向棧記憶體的指標就是野指標
存取空指標(需要做空判斷)
sizeof 無法獲取陣列的大小
試圖修改常量,如:char p="1234";p='1';
3、C 資源存取沖突
多執行緒共享變量沒有用 valotile 修飾
多執行緒存取全域變量未加鎖
全域變量僅對單行程有效
多行程寫共享記憶體數據,未做同步處理
mmap 記憶體對映,多行程不安全
4、STL 叠代器失效
被刪除的叠代器失效
添加元素(insert/push_back 等)、刪除元素導致順序容器叠代器失效
錯誤範例: 刪除當前叠代器,叠代器會失效

正確範例: 叠代器 erase 時,需保存下一個叠代器

5、C++ 11 智慧指標
auto_ptr 替換為 unique_ptr
使用 make_shared 初始化一個 shared_ptr
weak_ptr 智慧指標助手(1)原理分析:
(2)數據結構:
(3)使用方法:a. lock() 獲取所管理的物件的強參照指標 b. expired() 檢測所管理的物件是否已經釋放 c. get() 存取智慧指標物件
6、C++ 11 更小更快更安全
std::atomic 原子數據型別 多緒安全
std::array 定長陣列開銷比 array 小和 std::vector 不同的是 array 的長度是固定的,不能動態拓展
std::vector vector 瘦身 shrink_to_fit():將 capacity 減少為於 size() 相同的大小
td::forward_list
forward_list 是單連結串列(std::list 是雙連結串列),只需要順序遍歷的場合,forward_list 能更加節省記憶體,插入和刪除的效能高於 list
std::unordered_map、std::unordered_set用 hash 實作的無序的容器,插入、刪除和尋找的時間復雜度都是 O(1),在不關註容器內元素順序的場合,使用 unordered 的容器能獲得更高的效能六、 如何檢視記憶體
系統中記憶體使用情況:/proc/meminfo
行程的記憶體使用情況:/proc/28040/status
查詢記憶體總使用率:free
查詢行程 cpu 和記憶體使用占比:top
虛擬記憶體統計:vmstat
行程消耗記憶體占比和排序:ps aux –sort -rss
釋放系統記憶體緩存:/proc/sys/vm/drop_caches
To free pagecache, use echo 1 > /proc/sys/vm/drop_caches
To free dentries and inodes, use echo 2 > /proc/sys/vm/drop_caches
To free pagecache, dentries and inodes, use echo 3 >/proc/sys/vm/drop_caches
<END>
點這裏👇關註我,記得標星呀~
往期精選:
GPT中文網站
可以在國內同ChatGPT直接進行對話,支持GPT4.0 和 AI繪圖,簡直太方便了,今天新註冊的直接送4.0提問次數 !
點「在看」的人都變好看了哦











