👉 導讀
對於人類的身體健康來說,「三高 」 是個大忌,但在電腦界,系統的「三高 」 卻是健康的終極目標。本文將介紹一下流量治理是如何維持這種「三高 」 系統的健康,保障數據流動的均衡與效率,就如同營養顧問在維持人類健康飲食中所起的作用一般。
👉 目錄
1 可用性的定義
2 流量治理的目的
3 流量治理的手段
4 總結
01
可用性的定義
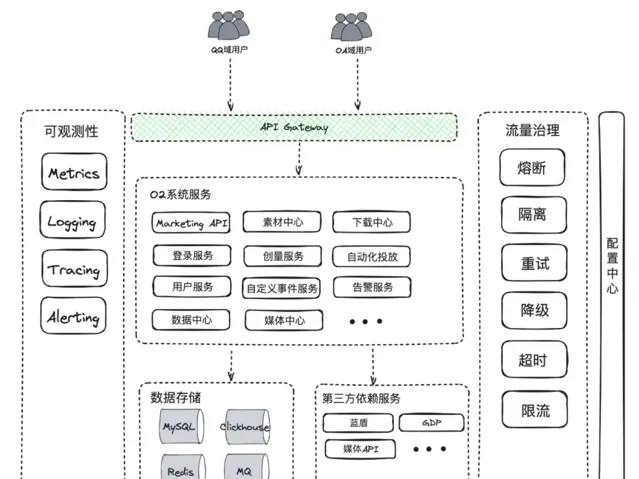
在探討高可用架構之前,讓我們以 O2 系統為例,解釋一下何謂可用性。O2 是騰訊內部的一個廣告投放系統,專註於提升投放效率、分析廣告效果,擁有自動化廣告投放、AIGC 自動化素材生產等多種功能。
其整體架構概覽如下:
一個完善的架構應該具備3個能力,也就是身體的「三高 」 :
高效能;
高可用;
易擴充套件。
理解高可用時,通常參考兩個關鍵指標:
平均故障間隔(Mean Time Between Failure,簡稱 MTBF):表示兩次故障的間隔時間,也就是系統正常執行的平均時間,這個時間越長,說明系統的穩定性越高;
故障恢復時間(Mean Time To Repair,簡稱 MTTR):表示系統發生故障後恢復的時間,這個時間越短,說明故障對使用者的影響越小。
可用性(Availability)的計算公式:Availability= MTBF / (MTBF + MTTR) * 100%
這個公式反映了一個簡單的事實: 只有當系統故障間隔時間越長,且恢復時間越短,系統的整體可用性才會更高。
因此,在設計高可用系統時,我們的核心目標是延長 MTBF,同時努力縮短 MTTR,以減少任何潛在故障對服務的影響。
02
流量治理的目的
在保障系統高可用性的過程中,流量治理扮演著關鍵角色:它不僅幫助平衡和最佳化數據流,還提高了系統對不同網路條件和故障情況的適應力,是確保服務高效連續執行的不可或缺的環節.
流量治理的主要目的包括:
網路效能最佳化: 透過流量分配、負載均衡等技術,確保網路資源的高效利用,減少延遲和避免擁塞;
服務品質保障: 確保關鍵套用和服務的流量優先級,以保障業務關鍵操作的流暢執行;
故障容錯和彈性: 在網路或服務出現問題時,透過動態路由和流量重新導向等機制,實作故障轉移和自我恢復,以維持服務的持續可用性;
安全性: 實施流量加密、存取控制和入侵檢測等措施,保護網路和數據不受未授權存取或攻擊;
成本效益: 透過有效管理流量,降低頻寬需求和相關成本,同時提高整體系統效率。
03
流量治理的手段
3.1 熔斷
微服務系統中,一個服務可能會依賴多個服務,並且有一些服務也依賴於它
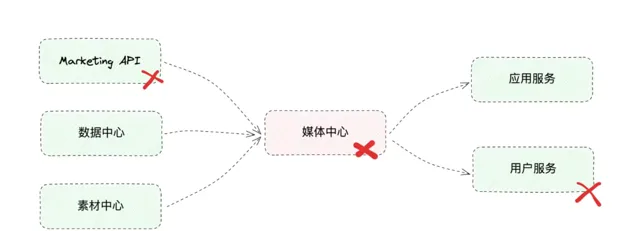
當「媒體中心」服務的其中一個依賴服務出現故障(比如使用者服務),媒體中心只能被動地等待依賴服務報錯或者請求超時;
下遊連線池會被逐漸耗光;
入口請求大量堆積,CPU、記憶體等資源被逐漸耗盡,最終導致服務宕掉。
而依賴「媒體中心」服務的上遊服務,也會因為相同的原因出現故障,一系列的 級聯故障 最終會導致整個系統不可用;
合理的解決方案是 引入熔斷器 和優雅降級,透過盡早失敗來避免局部不穩定而導致的整體雪崩。
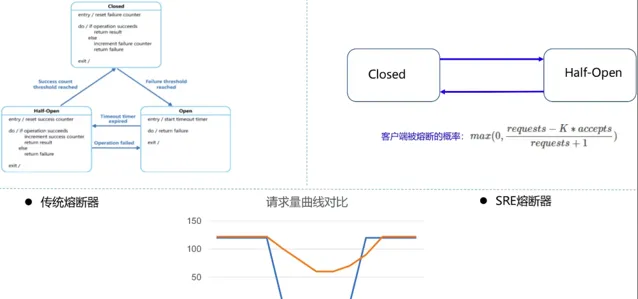
傳統熔斷器
當請求失敗比率達到一定閾值之後,熔斷器開啟,並休眠一段時間(由配置決定)。這段休眠期過後,熔斷器將處於半開狀態,在此狀態下將試探性地放過一部份流量,如果這部份流量呼叫成功後,再次將熔斷器關閉,否則熔斷器繼續保持開啟並進入下一輪休眠周期。
引入傳統熔斷器的請求時序圖:
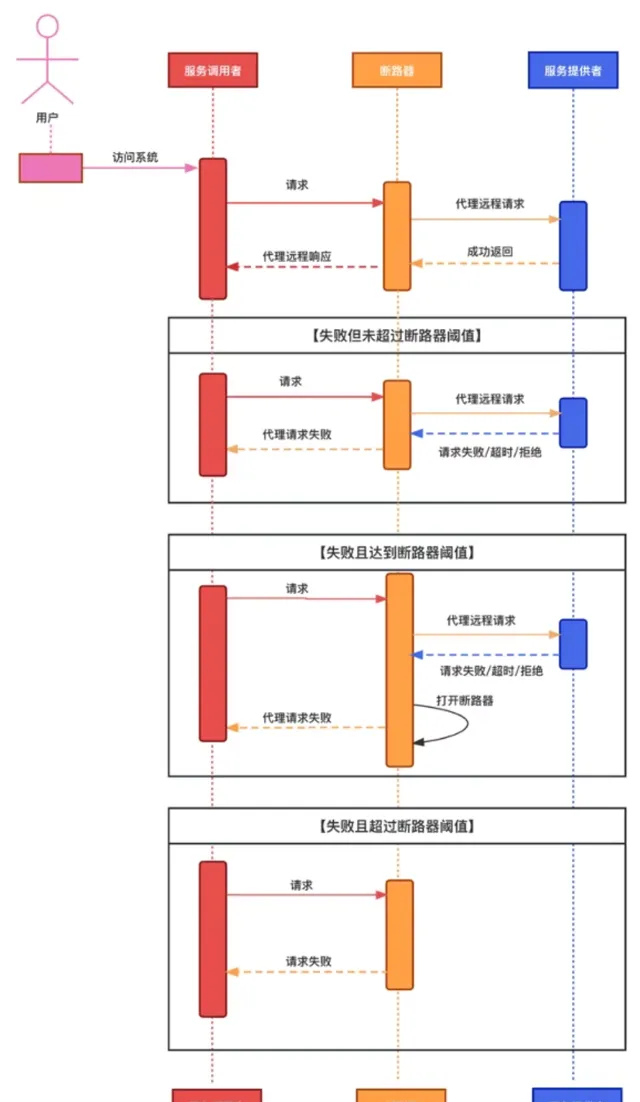
傳統熔斷器實作 關閉、開啟、半開 三個狀態;
關閉(Closed):預設狀態。允許請求到達目標服務,同時統計在視窗時間內的成功和失敗次數,如果達到錯誤率閾值將會切換為「開啟」狀態;
開啟(Open):對套用的請求會立即返回錯誤響應或執行預設的失敗降級邏輯,而不呼叫目標服務;
半開(Half-Open):進入「開啟」狀態會維護一個超時時間,到達超時時間後開始進入該狀態,允許應用程式一定數量的請求去呼叫目標服務。
熔斷器會對成功執行的呼叫進行計數,達到配置的閾值後會認為目標服務恢復正常,此時熔斷器回到「關閉」狀態;
如果有請求出現失敗的情況,則回到「開啟」狀態,並重新啟動超時計時器,再給系統一段時間來從故障中恢復。
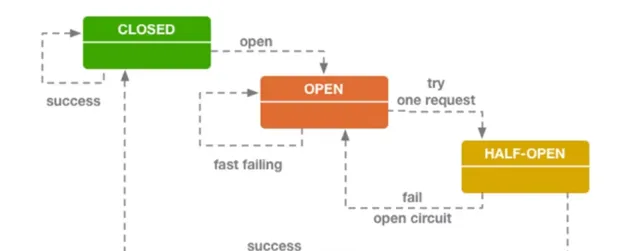
當進入 Open 狀態時會拒絕所有請求;進入 Closed 狀態時瞬間會有大量請求,這時伺服端可能還沒有完全恢復,會導致熔斷器又切換到 Open 狀態;而 Half-Open 狀態存在的目的在於實作了服務的自我修復,同時防止正在恢復的服務再次被大量打垮;
所以傳統熔斷器在實作上過於一刀切,是一種比較剛性的熔斷策略。
Google SRE 熔斷器
是否可以做到在熔斷器 Open 狀態下(但是後端未 Shutdown) 仍然可以放行少部份流量 呢?Google SRE 熔斷器提供了一種演算法: 客戶端自適應限流(client-side throttling)。
解決的辦法就是 客戶端自行限制請求速度,限制生成請求的數量 ,超過這個數量的請求直接在本地回復失敗,而不會真正發送到伺服端。
該演算法統計的指標依賴如下兩種,每個客戶端記錄過去兩分鐘內的以下資訊(一般程式碼中以滑動視窗實作)。
requests :客戶端請求總量
註:The number of requests attempted by the application layer(at the client, on top of the adaptive throttling system)
accepts :成功的請求總量 - 被 accepted 的量
註:The number of requests accepted by the backend
Google SRE 熔斷器的工作流程:
在通常情況下(無錯誤發生時) requests == accepts ;
當後端出現異常情況時,accepts 的數量會逐漸小於 requests;
當後端持續異常時,客戶端可以繼續發送請求直到 requests = K∗accepts ,一旦超過這個值,客戶端就啟動自適應限流機制,新產生的請求在本地會被機率(以下稱為p)丟棄;
當客戶端主動丟棄請求時,requests 值會一直增大,在某個時間點會超過 K∗accepts ,使 p 計算出來的值大於 0,此時客戶端會以此機率對請求做主動丟棄;
當後端逐漸恢復時,accepts 增加,(同時 requests 值也會增加,但是由於 K 的關系,K*accepts的放大倍數更快),使得 (requests − K×accepts) / (requests + 1) 變為負數,從而 p == 0,客戶端自適應限流結束。
客戶端請求被拒絕的機率(Client request rejection probability,以下簡稱為 p)
p 基於如下公式計算(其中 K 為倍率 - multiplier,常用的值為 2)。

當 requests − K∗accepts <= 0 時, p == 0 ,客戶端不會主動丟棄請求;
反之, p 會隨著 accepts 值的變小而增加,即成功接受的請求數越少,本地丟棄請求的機率就越高。
客戶端可以發送請求直到 requests = K∗accepts , 一旦超過限制, 按照 p 進行截流。
對於後端而言,調整 K 值可以使得自適應限流演算法適配不同的服務場景
降低 K 值會使自適應限流演算法更加激進 (允許客戶端在演算法啟動時拒絕更多本地請求);
增加 K 值會使自適應限流演算法變得保守一些 (允許伺服端在演算法啟動時嘗試接收更多的請求,與上面相反)。
熔斷本質上是一種快速失敗策略。旨在透過及時中斷失敗或超時的操作,防止資源過度消耗和請求堆積,從而 避免服務因小問題而引發的雪崩效應。
3.2 隔離
微服務系統中,隔離策略是流量治理的關鍵組成部份, 其主要目的是避免單個服務的故障引發整個系統的連鎖反應。
透過隔離,系統能夠局部化問題,確保單個服務的問題不會影響到其他服務,從而維護整體系統的穩定性和可靠性。
常見的隔離策略:
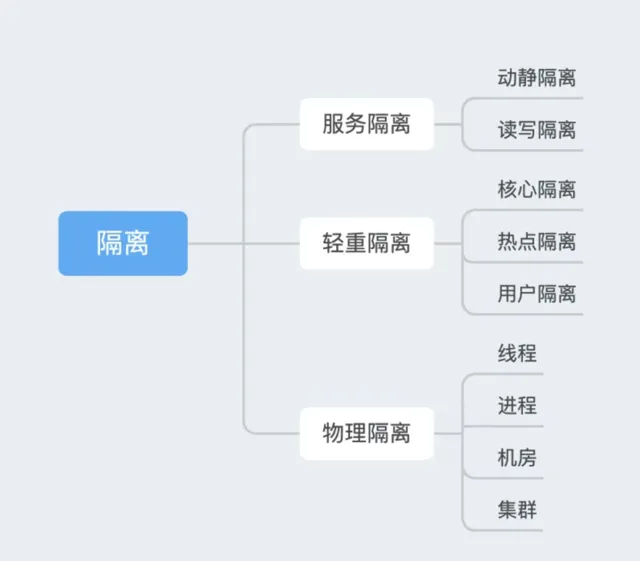
3.2.1 動靜隔離
動靜隔離通常是指將系統的動態內容和靜態內容分開處理
動態內容
指需要即時計算或從資料庫中檢索的數據,通常由後端服務提供;
可以透過緩存、資料庫最佳化等方法來提高動態內容的處理速度。
靜態內容
指可以直接從檔案系統中獲取的數據,例如圖片、音視訊、前端的 CSS、JS 檔等靜態資源;
可以儲存到 OSS 並透過 CDN 進行存取加速。

3.2.2 讀寫隔離
讀寫隔離通常是指將讀操作和寫操作分離到不同的服務或例項中處理
大部份的系統裏讀寫操作都是不均衡的,寫數據可能遠遠少於讀數據;
讀寫隔離得以讓讀服務和寫服務獨立擴充套件。
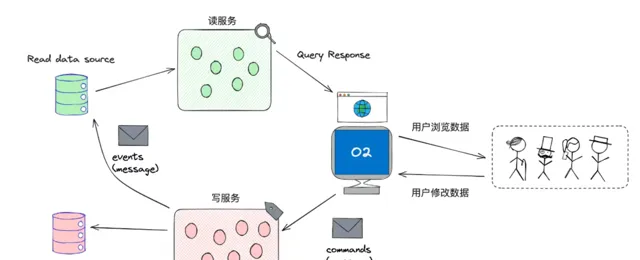
DDD中有一種常用的模式:CQRS(Command Query Responsibility Segregation,命令查詢職責分離)來實作讀寫隔離
寫服務
負責處理所有的寫操作,例如建立、更新和刪除數據;
通常會有一個或多個資料庫或數據儲存,用於保存系統的數據。
讀服務
負責處理所有的讀操作,例如查詢和檢索數據;
可以有獨立的資料庫或數據儲存,也可以使用緩存來提高查詢的效能。
事件驅動
當寫服務處理完一個寫操作後,通常會釋出一個事件,通知讀服務數據已經發生變化;
讀服務可以監聽這些事件,並更新其資料庫或緩存,以保證數據的一致性。
獨立擴充套件
透過 CQRS 模式,讀服務和寫服務可以獨立地進行擴充套件;
如果系統的讀負載較高,可以增加讀服務的例項數量;如果寫負載較高,可以增加寫服務的例項數量。
3.2.3 核心隔離
核心隔離通常是指將資源按照 「核心業務」與 「非核心業務」進行劃分,優先保障「核心業務」的穩定執行AI助手
核心/非核心故障域的差異隔離(機器資源、依賴資源);
核心業務可以搭建多集群透過冗余資源來提升吞吐和容災能力;
按照服務的核心程度進行分級。
1級:系統中最關鍵的服務,如果出現故障會導致使用者或業務產生重大損失;
2級:對於業務非常重要,如果出現故障會導致使用者體驗受到影響,但不會導致系統完全無法使用;
3級:會對使用者造成較小的影響,不容易註意或很難發現;
4級:即使失敗,也不會對使用者體驗造成影響。
3.2.4 熱點隔離
熱點隔離通常是指一種針對高頻存取數據(熱點數據)的隔離策略
可以幫助微服務系統更高效地處理熱點數據的存取請求;
需要有機制來辨識和監控熱點數據;
分析系統的歷史存取記錄;
觀察系統的監控告警資訊等。
將存取頻次最高的 Top K 數據緩存起來,可以顯著減少對後端儲存服務的存取壓力,同時提高數據存取的速度;
可以建立一個獨立的緩存服務來儲存和管理熱點數據,實作熱點數據的隔離。
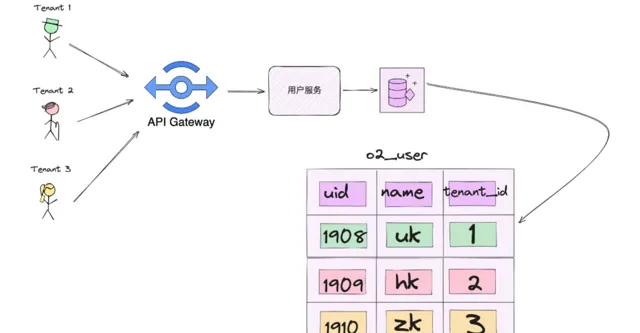
3.2.5 使用者隔離
使用者隔離通常是指按照不同的分組形成不同的服務例項。這樣某個服務例項宕機了也只會影響對應分組的使用者,而不會影響全部使用者
基於 O2-SAAS 系統的租戶概念,按照隔離級別的從高到低有如下幾種隔離方式:
1.每個租戶有獨立的服務與資料庫
閘道器根據 tenant_id 辨識出對應的服務例項進行轉發

2.每個租戶有共享的服務與獨立的資料庫
使用者服務根據 tenant_id 確定操作哪一個資料庫
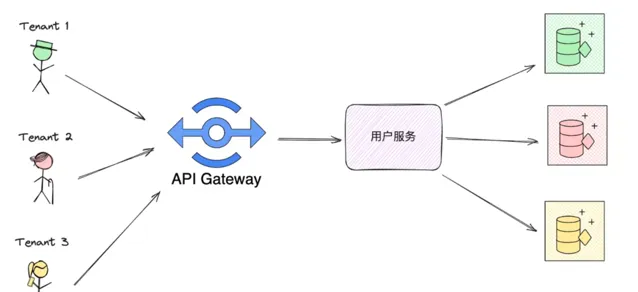
3.每個租戶有共享的服務與資料庫
使用者服務根據 tenant_id 確定操作資料庫的哪一行記錄
3.2.6 行程隔離
行程隔離通常是指系統中每一個行程擁有獨立的地址空間,提供作業系統級別的保護區。一個行程出現問題不會影響其他行程的正常執行,一個套用出錯也不會對其他套用產生副作用
容器化部署便是行程隔離的最佳實踐:
3.2.7 執行緒隔離
執行緒隔離通常是指執行緒池的隔離,在套用系統內部,將不同請求分類發送給不同的執行緒池,當某個服務出現故障時,可以根據預先設定的熔斷策略阻斷執行緒的繼續執行
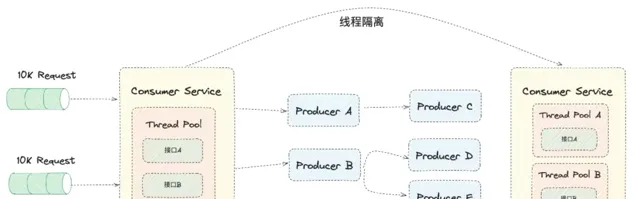
如圖, 介面A 和 介面B 共用相同的執行緒池,當 介面A 的存取量激增時,介面C 的處理效率就會被影響,進而可能產生雪崩效應;
使用執行緒隔離機制,可以將 介面A 和 介面B 做一個很好的隔離。
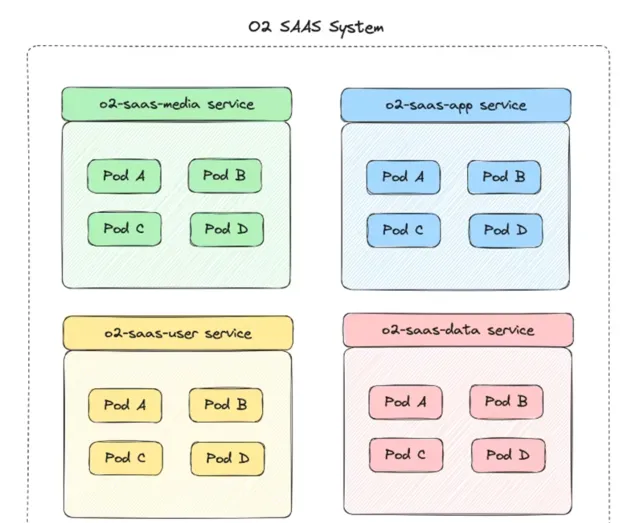
3.2.8 集群隔離
集群隔離通常是指將某些服務單獨部署成集群,或對於某些服務進行分組集群管理
具體來說就是每個服務都獨立成一個系統,繼續拆分模組,將功能微服務化:
3.2.9 機房隔離
機房隔離通常是指在不同的機房或數據中心部署和執行服務,實作實體層面的隔離
機房隔離的主要目的有兩個:
解決數據容量大、計算和 I/O 密集度高的問題。 將不同區域的使用者隔離到不同的地區,比如將湖北的數據儲存在湖北的伺服器,浙江的數據儲存在浙江的伺服器,這種區域化的數據管理能有效地分散流量和系統負載;
增強數據安全性和災難恢復能力。 透過在不同地理位置建立服務的完整副本(包括計算服務和數據儲存),系統可以實作異地多活或冷備份。這樣,即使一個機房因自然災害或其他緊急情況受損,其他機房仍能維持服務,確保數據安全和業務連續性。
3.3 重試
如何在不可靠的網路服務中實作可靠的網路通訊,這是電腦網路系統中避不開的一個問題
微服務架構中,一個大系統被拆分成多個小服務,小服務之間大量的 RPC 呼叫,過程十分依賴網路的穩定性。
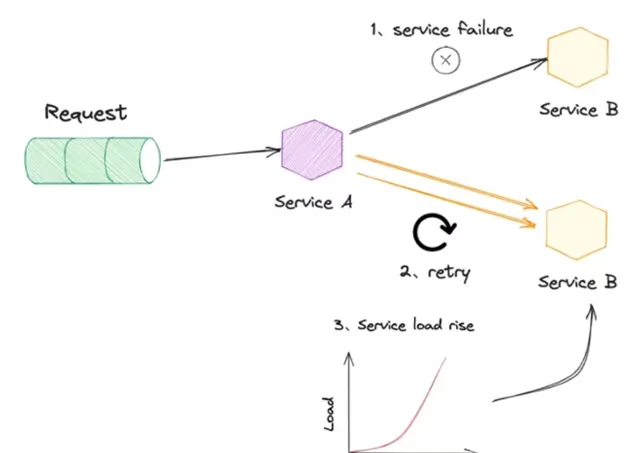
網路是脆弱的,隨時都可能會出現抖動,此時正在處理中的請求有可能就會失敗。場景:O2 Marketing API 服務呼叫媒體介面拉取數據。
對於網路抖動這種情況,解決的辦法之一就是重試。但重試存在風險,它可能會解決故障,也可能會放大故障。
對於網路通訊失敗的處理一般分為以下幾步:
1.感知錯誤;
透過不同的錯誤碼來辨識不同的錯誤,在 HTTP 中 status code 可以用來辨識不同型別的錯誤。
2.重試決策;
這一步主要用來減少不必要的重試,比如 HTTP 的 4xx 的錯誤,通常 4xx 表示的是客戶端的錯誤,這時候客戶端不應該進行重試操作,或者在業務中自訂的一些錯誤也不應該被重試。根據這些規則的判斷可以有效的減少不必要的重試次數,提升響應速度。
3.重試策略;
重試策略就包含了重試間隔時間,重試次數等。如果次數不夠,可能並不能有效的覆蓋這個短時間故障的時間段,如果重試次數過多,或者重試間隔太小,又可能造成大量的資源(CPU、記憶體、執行緒、網路)浪費。
4.對沖策略。
對沖是指在不等待響應的情況主動發送單次呼叫的多個請求,然後取第一個返回的回包。
如果重試之後還是不行,說明這個故障不是短時間的故障,而是長時間的故障。那麽可以對服務進行熔斷降級,後面的請求不再重試,這段時間做降級處理,減少沒必要的請求,等伺服端恢復了之後再進行請求,這方面的工程實作很多,比如 go-zero 、 sentinel 、hystrix-go。
3.3.1 重試方式
常見的重試主要有兩種方式:同步重試、異步重試
同步重試
程式在呼叫下遊服務失敗的時候重新發起一次;
實作簡單,能解決大部份網路抖動問題,是比較常用的一種重試方式。
異步重試
如果服務追求數據的強一致性,並且希望在下遊服務故障的時候不影響上遊服務的正常執行,此時可以考慮使用異步重試。
將請求資訊丟到訊息佇列中,由消費者消費請求資訊進行重試;
上遊服務可以快速響應請求,由消費者異步完成重試。
3.3.2 最大重試次數
無限重試可能會導致系統資源(網路頻寬、CPU、記憶體)的耗盡,甚至引發重試風暴
應評估系統的實際情況和業務需求來設定最大重試次數:
設定過低,可能無法有效地處理該錯誤;
設定過高,同樣可能造成系統資源的浪費。
3.3.3 退避策略
我們知道重試是一個 trade-off 問 題:
一方面要考慮到本次請求時長過長而影響到的業務的忍受度;
一方面要考慮到重試對下遊服務產生過多請求帶來的影響。
退避策略基於重試演算法實作。重試演算法有多種,思路都是在重試之間加上一個間隔時間
線性間隔(Linear Backoff)
每次重試間隔時間是固定的,比如每 1s 重試一次。
線性間隔+隨機時間(Linear Jitter Backoff)
有時候每次重試間隔時間一致可能會導致多個請求在同一時間請求;
加入隨機時間可以線上性間隔時間的基礎上波動一個百分比的時間。
指數間隔(Exponential Backoff)
間隔時間是指數型遞增,例如等待 3s、9s、27s 後重試。
指數間隔+隨機時間(Exponential Jitter Backoff)
與 Linear Jitter Backoff 類似,在指數遞增的基礎上添加一個波動時間。
上面有兩種策略都加入了 擾動(jitter) ,目的是防止 驚群問題 (Thundering Herd Problem) 的發生。
所謂驚群問題當許多行程都在等待被同一事件喚醒的時候,當事件發生後最後只有一個行程能獲得處理。其余行程又造成阻塞,這會造成上下文切換的浪費 所以加入一個隨機時間來避免同一時間同時請求伺服端還是很有必要的
gRPC 實作
gRPC 便是使用了 指數間隔+隨機時間 的退避策略進行重試:GRPC Connection Backoff Protocol https://github.com/grpc/grpc/blob/master/doc/connection-backoff.md
/*虛擬碼 */ConnectWithBackoff()current_backoff = INITIAL_BACKOFFcurrent_deadline = now() + INITIAL_BACKOFFwhile(TryConnect(Max(current_deadline, now() + MIN_CONNECT_TIMEOUT)) != SUCCESS)SleepUntil(current_deadline)current_backoff = Min(current_backoff * MULTIPLIER, MAX_BACKOFF)current_deadline = now() + current_backoff +UniformRandom(-JITTER* current_backoff, JITTER * current_backoff)
關於虛擬碼中幾個參數的說明:
INITIAL_BACKOFF :第一次重試等待的間隔;
MULTIPLIER :每次間隔的指數因子;
JITTER :控制隨機的因子;
MAX_BACKOFF :等待的最大時長,隨著重試次數的增加,我們不希望第N次重試等待的時間變成幾十分鐘這樣不切實際的值;
MIN_CONNECT_TIMEOUT :一次成功的請求所需要的時間,即使是正常的請求也會有響應時間,重試時間間隔需要大於這個響應時間才不會出現請求明明已經成功,但卻進行重試的操作。
3.3.4 重試風暴

透過一張圖來簡單介紹下重試風暴:
DB 負載過高時, Service C 對 DB 的請求出現失敗;
因為配置了重試機制, Service C 對 DB 發起了最多 3 次請求;
鏈路上為了避免網路抖動,上遊的服務均設定了超時重試 3 次的策略;
這樣在一次業務請求中,對 DB 的 存取可能達到 3^(n) 次。
此時負載高的 DB 便被卷進了重試風暴中,最終很可能導致服務雪崩。
應該怎麽避免重試風暴呢?筆者整理了如下幾種方式:
1、限制單點重試
一個服務不能不受限制地重試下遊,很容易造成下遊服務被打掛;
除了設定最大重試次數,還需要限制重試請求的成功率。
2、引入重試視窗
基於斷路器的思想,限制 請求失敗/請求成功 的比率,給重試增加熔斷功能;
常見的實作方式是引入滑動視窗。
這裏介紹一下重試視窗:

記憶體中為每一類 RPC 呼叫維護一個滑動視窗,視窗分多個 bucket ;
bucke t 每秒生成 1 個,記錄 1 秒內 RPC 的請求結果數據(成功/失敗 次數);
新的 bucket 生成時,淘汰最早的一個 bucket ;
新的請求到達該 RPC 服務並且失敗時,根據視窗內 失敗/成功 比率以及失敗次數是否超過閾值來判斷是否可以重試。比如閾值設定 0.1 ,即失敗率超過 10% 時不進行重試。
3、限制鏈路重試
多級鏈路中如果每層都配置重試可能導致呼叫量指數級擴大;
核心是限制每層都發生重試,理想情況下只有最下遊服務發生重試;
Google SRE 中指出了 Google 內部使用特殊錯誤碼的方式來實作。
關於 Google SRE 的實作方式,大致細節如下:
統一約定一個特殊的 status code ,它表示:呼叫失敗,但別重試;
任何一級重試失敗後,生成該 status code 並返回給上層;
上層收到該 status code 後停止對這個下遊的重試,並將錯誤碼再傳給自己的上層。
該方法可以有效避免重試風暴,但請求鏈路上需要上下遊服務約定好重試狀態碼並耦合對於的邏輯,一般需要在框架層面上做出約束。
3.3.5 對沖策略
有時候我們介面只是偶然會出問題,並且我們的下遊服務並不在乎多請求幾次,那麽我們可以考慮對沖策略AI助手
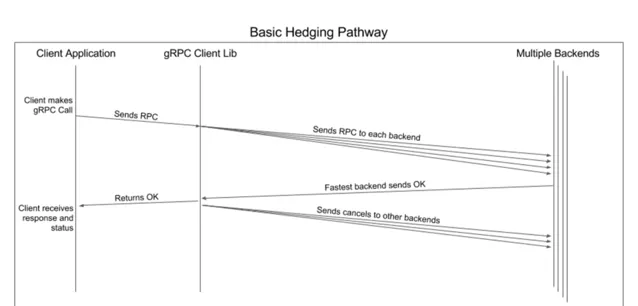
對沖是指在不等待響應的情況下主動發送單次呼叫的多個請求,然後取第一個返回的回包
請求流程
第一次正常的請求正常發出;
在等待固定時間間隔後,沒有收到正確的響應,第二個對沖請求會被發出;
再等待固定時間間隔後,沒有收到任何前面兩個請求的正確響應,第三個會被發出;
一直重復以上流程直到發出的對沖請求數量達到配置的最大次數;
一旦收到正確響應,所有對沖請求都會被取消,響應會被返回給套用層。
與普通重試的區別
對沖在超過指定時間沒有響應就會直接發起請求,而重試則必須要伺服端響應後才會發起請求。所以對沖更像是比較激進的重試策略。
使用對沖的時候需要註意一點是,因為下遊服務可能會做負載均衡策略,所以要求請求的下遊服務一般是要求冪等的,能夠在多次並行請求中是安全的,並且是符合預期的。
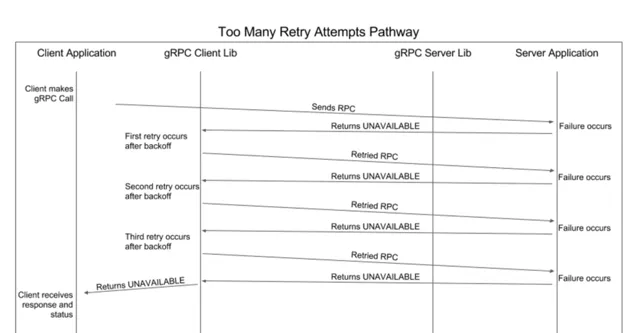
普通重試時序圖:
對沖重試時序圖:
3.4 降級
降級是從系統功能角度出發,人為或自動地將某些不重要的功能停掉或者簡化,以降低系統負載,這部份釋放的資源可以去支撐更核心的功能
目的是為了提升系統的可用性,同時要尋找到使用者體驗與降級成本的平衡點;
降級屬於失真操作。簡而言之,棄卒保帥。

3.4.1 降級策略
以 O2 系統舉例,有以下幾類降級策略:

雖說故障是不可避免的,要達到絕對高可用一般都是使用冗余+自動故障轉移,這個時候其實也不需要降級措施了。
但是這樣帶來的成本較高,而且可用性、成本、使用者體驗3者本身之間是需要權衡的,一般來說他們之前會是這樣的關系:
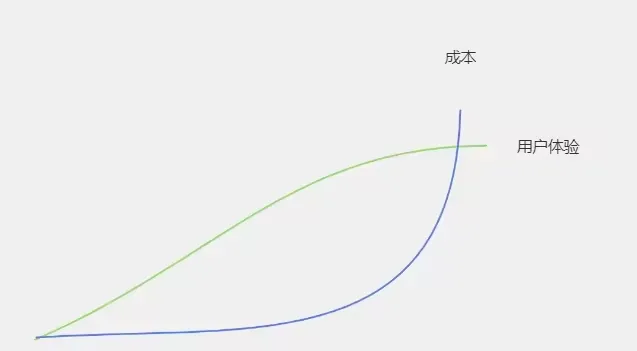
3.4.2 自動降級
適合觸發條件明確可控的場景,比如請求呼叫失敗次數大於一定的閾值,服務介面超時等情況;
對於一些旁路服務,服務負載過高也可以直接觸發自動降級。
3.4.3 手動降級
降級操作都是失真的,部份情況下需要根據對業務的影響程度進行手動降級;
通常需要先制定降級的分級策略,影響面由淺至深。
3.4.4 執行降級
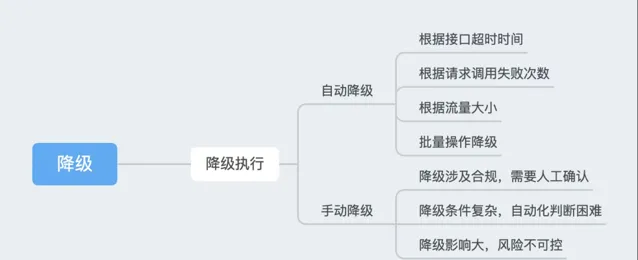
降級的策略還是比較豐富的,因此需要從多個角度去化簡
首先,將一部份判斷條件簡單的降級透過自動化手段去實作;
其次,根據對業務的影響程度,對降級進行分級,達到有層次的降級效果;
最後,透過高頻演練,確保降級的有效性。
3.4.5 與限流的區別
降級依靠犧牲一部份功能或體驗保住容量,而限流則是依靠犧牲一部份流量來保住容量。
一般來說,限流的通用性會更強一些,因為每個服務理論上都可以設定限流, 但並不是每個服務都能降級 ,比如 O2 系統中的登入服務和使用者服務,就不可能被降級(沒有這兩個服務,使用者都沒法使用系統了)。
3.5 超時
超時是一件很容易被忽視的事情
早期架構發展階段,大家或多或少有過遺漏設定超時或者超時設定太長導致系統被拖慢甚至掛起的經歷
隨著微服務架構的演進,超時逐漸被標準化到 RPC 中,並可透過微服務治理平台快捷調整超時參數
傳統超時會設定一個固定的閾值,響應時間超過閾值就返回失敗。在網路短暫抖動的情況下,響應時間增加很容易產生大規模的成功率波動
服務的響應時間並不是恒定的,在某些長尾條件下可能需要更多的計算時間,為了有足夠的時間等待這種長尾請求響應,我們需要把超時設定足夠長,但超時設定太長又會增加風險,超時的準確設定經常困擾我們
3.5.1 超時策略
目前業內常用的超時策略有:
固定超時時間;
EMA 動態超時。
3.5.2 超時控制
超時控制的本質是 fail fast ,良好的超時控制可以盡快清空高延遲的請求,盡快釋放資源避免請求堆積。
服務間超時傳遞
一個請求可能由一系列 RPC 呼叫組成,每個服務在開始處理請求前應檢查是否還有足夠的剩余時間處理,也就是應該在每個服務間傳遞超時時間。
如果都使用每個 RPC 服務設定的固定超時時間,這裏以上圖為例
A -> B ,設定的超時時間為 3s ;
B 處理耗時為 2s ,並繼續請求 C ;
如果使用了超時傳遞那麽 C 的超時時間應該為 1s ,這裏不采用所以超時時間為配置的 3s;
C 繼續執行耗時為 2s ,此時最上層 ( A) 設定的超時時間已截止;
C -> D 的請求對 A 來說已經失去了意義。
行程內超時傳遞
上圖流程如下:
一個行程內序列呼叫了 MySQ L 、 Redis 和 Service B ,設定總的請求時間為 3s;
請求 MySQL 耗時 1s 後再請求 Redis ,這時的超時時間為 2s , Redis 執行耗時 500 ms ;
再請求 Service B ,這時超時時間為 1.5s 。
由於每個元件或服務都會在配置檔中配置固定的超時時間,使用時應該取實際剩余時間與配置的超時時間中的最小值。
Context 實作超時傳遞
3.5.3 EMA 動態超時
如果我們的微服務系統對這種短暫的時延上漲具備足夠的容忍能力,可以考慮 基於 EMA 演算法動態調整超時時長。
EMA 演算法引入「平均超時」的概念,用平均響應時間代替固定超時時間,只要平均響應時間沒有超時即可,而不是要求每次請求都不能超時。
演算法實作
當平均響應時間(EMA)大於超時時間限制(Thwm),說明平均情況表現很差,動態超時時長(Tdto)就會趨近於超時時間限制(Thwm),降低彈性;
當平均響應時間(EMA)小於超時時間限制(Thwm),說明平均情況表現很好,動態超時時長(Tdto)就可以超出超時時間限制(Thwm),但會低於最大彈性時間(Tmax),具備一定的彈性。
演算法實作參考: https://github.com/jiamao/ema-timeout
總而言之:
總體情況不能超標;
平均情況表現越好,彈性越大;
平均情況表現越差,彈性越小。
適用條件
固定業務邏輯,迴圈執行;
程式大部份時間在等待響應,而不是 CPU 計算或者處理 I/O 中斷;
服務是序列處理模式,容易受異常、慢請求阻塞;
響應時間不宜波動過大;
服務可以接受失真。
使用方法
EMA 動態超時根據業務的請求鏈路有兩種用法:
1.用於非關鍵路徑
Thwm 設定的相對小,當非關鍵路徑頻繁耗時增加甚至超時時,降低超時時間,減少非關鍵路徑異常帶來的資源消耗,提升服務吞吐量。
2.用於關鍵路徑
Thwm 設定的相對大,用於長尾請求耗時比較多的場景,提高關鍵路徑成功率。
在 3.5.2 小節有提到,一般超時時間會在鏈路上傳遞,避免上遊已經超時,下遊繼續浪費資源請求的情況。
這個傳遞的超時時間一般是沒有考慮網路耗時或不同伺服器的時鐘不一致的,所以會存在一定的偏差。
3.5.4 超時策略的選擇
超時策略的選擇:剩余資源 = 資源容量 - QPS 單次請求消耗資源請求持續時長 – 資源釋放所需時長
- | 固定超時 | EMA動態超時 |
優點 | 穩定 | 可以根據耗時動態調整超時時間 |
缺點 | 如果某個服務一直出問題超時,會導致服務吞吐量降低 | 服務失真 |
關鍵路徑選擇固定超時;
非關鍵路徑開啟 EMA 動態超時,防止一直出問題導致服務耗時增加、吞吐量降低。
3.5.5 超時時間的選擇
合理的設定超時可以減少服務資源消耗、避免長時間阻塞、降低服務過載的機率;
超時時間過長容易引起降級失效、系統崩潰;
超時時間過短因⽹絡抖動⽽告警頻繁,造成服務不穩定。
如何選擇合適的超時閾值?超時時間選擇需要考慮的幾個點:
被調服務的重要性;
被調服務的耗時 P99、P95、P50、平均值;
網路波動;
資源消耗;
使用者體驗。
3.6 限流
預期外的突發流量總會出現,對我們系統可承載的容量造成巨大沖擊,極端情況下甚至會導致系統雪崩
當系統的處理能力有限時,如何阻止計劃外的請求繼續對系統施壓,這便是限流的作用之處
限流可以幫助我們應對突發流量,透過限制服務的請求率來保護服務不被過載
除了控制流量,限流還有一個套用目的是用於控制使用者行為,避免無用請求,比如頻繁地下載系統中的數據表格
限流一般來說分為客戶端限流和伺服端限流兩類。
3.6.1 客戶端限流
在客戶端限流中,由於請求方和被請求方的關系明確,通常采用較為簡單的限流策略,如結合分布式限流和固定的限流閾值。
客戶端的限流閾值可被視作被呼叫方對主調方的配額。
合理設定限流閾值的方法包括:
容量評估 :透過單機壓測確定服務的單機容量模型,並與下遊服務協商以了解他們的限流閾值
容量規劃 :根據日常執行、營運活動和節假日等不同場景,提前進行容量評估和規劃
全鏈路壓測 :透過模擬真實場景的壓測,評估現有限流值的合理性
在限流演算法方面,大家也都已經耳熟能詳。像 滑動視窗、漏桶 和 令牌桶 均是常用的限流演算法。
這些演算法各有特點,能有效管理客戶端的請求流量,保障系統的穩定執行。
這裏筆者簡單梳理了一張常用的限流演算法的思維導圖,主要闡述每個演算法的局限性,需要根據實際套用場景選擇合適的演算法:
3.6.2 伺服端限流
伺服端限流旨在透過主動丟棄或延遲處理部份請求,以應對系統過載的情況。
伺服端限流實作的兩個關鍵點:
1、如何判斷系統是否過載
常用的判斷依據包括:
資源使用率;
請求成功率;
響應時間;
請求排隊時間,
2、過載時如何選擇要丟棄的請求
常用的判斷依據包括:
按照主調方(客戶端)的重要性來劃分優先級;
根據使用者的重要性進行區分。
關於伺服端限流在業界內的實踐套用,筆者這裏整理了兩個範例:
開源的 Sentinel 采用類似 TCP BBR 的限流方法。它基於利特爾法則,計算時間視窗內的最大成功請求數 (MaxPass) 和最小響應時間 (MinRt) 。當 CPU 使用率超過 80% 時,根據 MaxPass 和 MinRt 計算視窗內理論上可以透過的最大請求量,進而確定每秒的最大請求數。如果當前處理中的請求數超過此計算值,則進行請求丟棄。
微信後台則使用請求的平均排隊時間作為系統過載的判斷標準。當平均等待時間超過 20 毫秒時,它會以一定的降速因子來過濾部份請求。相反,如果判斷平均等待時間低於 20 毫秒,則會逐漸提高請求的透過率。這種「快速降低,緩慢提升」的策略有助於防止服務的大幅波動。
04
總結
想要讓系統長期「三高 」 ,流量治理只是眾多策略的其中一個,其他還有像儲存高可用、緩存、負載均衡、故障轉移、冗余設計、可回滾設計等等均是確保系統長期穩定執行的關鍵因素,筆者也期待在後續就這些策略再和大家進行分享。
本文在介紹高可用架構中流量治理部份時,我們詳細討論了從熔斷機制到隔離策略、重試邏輯、降級方案,以及超時和限流控制等多種手段,這裏簡單歸納一下:
熔斷 機制,包括傳統熔斷器和 Google SRE 模型,作為防止系統過載的重要工具
隔離 策略,如動靜隔離、讀寫隔離和機房隔離,透過物理或邏輯上分離資源和請求,減少單點故障的影響
重 試 策略,包括同步和異步重試,以及各種退避機制,幫助在失敗時優雅地恢復服務。
降級 操作,區分自動和手動降級,作為服務負載過重時的應急措施
超 時 控制,透過精細的策略來避免長時間等待和資源浪費
限流 包括客戶端和伺服端限流,確保系統在高負載下仍能穩定執行
綜合這些策略,我們可以構建出一個既高效又穩健的系統,它能夠在各種網路條件和負載情況下保持高效能、高可用和易擴充套件。這些流量治理的手段不僅確保了服務的連續性和可靠性,還提高了使用者體驗和系統的整體效率。
最後想說, 高可用的本質就是 面向失敗設計 。它基於一個現實且務實的前提:系統中的任何元件都有可能出現故障。
因此,在架構設計時,我們不僅要接受故障的可能性,而且要學會擁抱故障。這意味著從一開始就將容錯和恢復能力納入設計考慮,透過增強系統的彈性、自適應力和恢復機制來應對可能出現的故障和變化。這種方法確保了在面對各種挑戰時,系統能夠保持持續的執行和服務品質。
··· ··········· END ·············
如喜歡本文,請點選右上角,把文章分享到朋友圈
如有想了解學習的技術點,請留言給若飛安排分享
因公眾號更改推播規則,請點「在看」並加「星標」 第一時間獲取精彩技術分享
·END·
相關閱讀:
作者:孔奕凱
來源:騰訊雲開發者
版權申明:內容來源網路,僅供學習研究,版權歸原創者所有。如有侵權煩請告知,我們會立即刪除並表示歉意。謝謝!
架構師
我們都是架構師!
關註 架構師(JiaGouX),添加「星標」
獲取每天技術幹貨,一起成為牛逼架構師
技術群請 加若飛: 1321113940 進架構師群
投稿、合作、版權等信箱: [email protected]











