點選上方「Linux開源社群」,選擇「設為星標」
優質文章,及時送達
轉自:一口Linux
1. 背景
最近在折騰網路編程,發現 IO 模型這塊比較模糊,翻了不少資料,這裏總結分享下。 關鍵字:網路編程;IO模型
2. 前置知識一:內核態,使用者態
想要弄懂 IO 模型,有一批前置知識需要掌握,首先是內核態和使用者態的概念。作業系統為了保護自己,設計了使用者態、內核態兩個狀態。應用程式一般工作在使用者態,當呼叫一些底層操作的時候(比如 IO 操作),就需要切換到內核態才可以進行。使用者態和內核態的切換需要消耗一些資源,零拷貝技術就是透過減少使用者態和內核態的轉換來提高效能的。
3. 前置知識二:應用程式從網路中接收數據的大致流程
伺服器從網路接收的大致流程如下:
數據透過電腦網路來到了網卡
把網卡的數據讀取到 socket 緩沖區
把 socket 緩沖區讀取到使用者緩沖區,之後應用程式就可以使用了
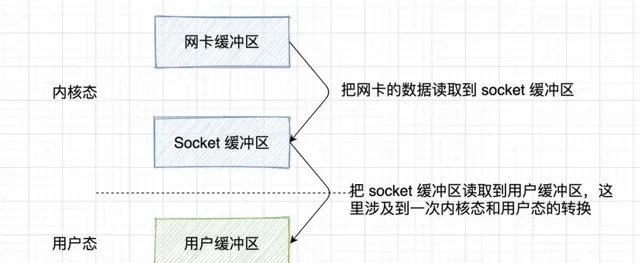
核心就是兩次讀取操作,五大 IO 模型的不同之處也就在於這兩個讀取操作怎麽互動。
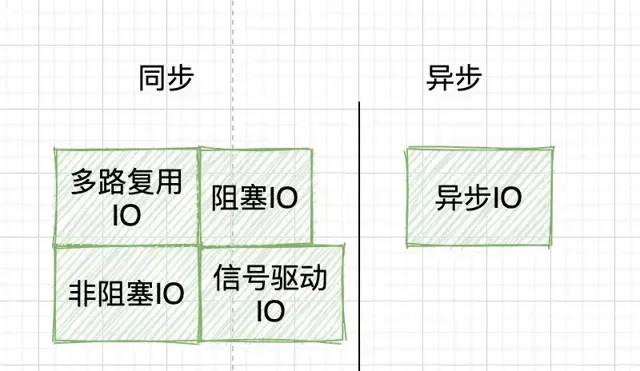
4. 前置知識三:理解同步/異步、阻塞/非阻塞
同步/異步:這個是套用層面的概念,指的是呼叫一個函式,我們是等這個函式執行完再繼續執行下一步,還是調完函式就繼續執行下一步,另起一個執行緒去執行所呼叫的函式。關註的是 執行緒間的協作 。阻塞/非阻塞,這個是硬體層面的概念,阻塞是指 cpu 「被」休息,處理其他行程去了,比如IO操作,而非阻塞則是 cpu 仍然會執行,不會切換到其他行程。關註的是CPU會不會「被」休息,表現在套用層面就 是執行緒會不會「被」掛起 。至於同步和阻塞有什麽區別,異步和非阻塞有什麽區別,其實這是不同層面的東西,不好相互比較的。在學習IO模型的過程中,千萬別鉆這個牛角尖。
5. 前置知識四:理解同步阻塞、同步非阻塞、異步阻塞、異步非阻塞
有很多 IO 模型的部落格,會把同步/異步、阻塞/非阻塞兩兩組合,把IO模型分成四類。
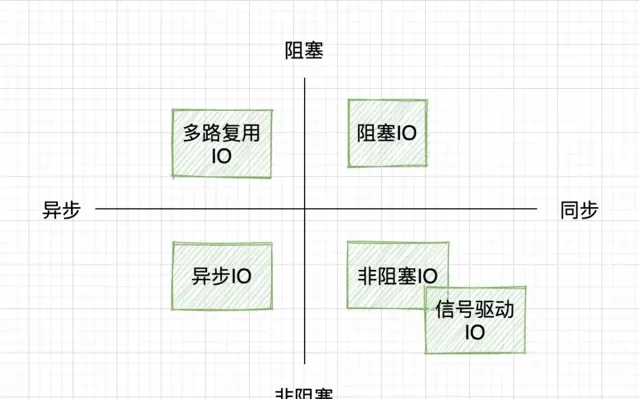
初看其實很納悶的,都異步了,還咋阻塞啊?
其實大可不必糾結這個,同步/異步、阻塞/非阻塞本身就是不同層面的東西,強行組合起來就是不好理解,甚至是錯誤的。
建議是拋開這個,直接去理解五大 IO 模型,千萬別鉆牛角尖。其實,真要分,也只能拆成兩個維度分,而不是四個維度。首先是按阻塞/非阻塞分:
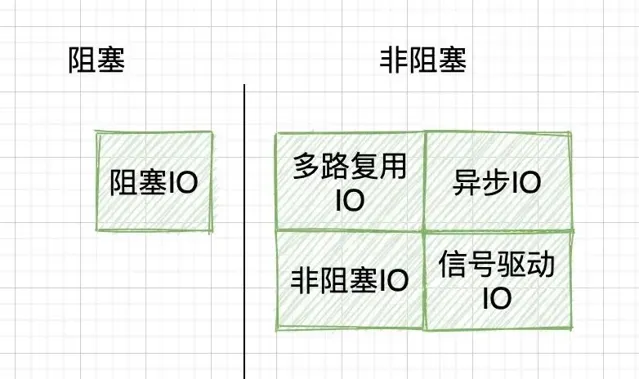
然後是按同步/異步分:
6. 五大 IO 模型之:阻塞 IO
好了,如果掌握了前面提到的的這些前置知識,理解IO模型就稍微輕松點了,現在開始。
之前提了,應用程式從網路中接收數據的大致流程就是兩步:
數據準備:等待網路數據,把網卡的數據讀取到 socket 緩沖區
數據復制:把 socket 緩沖區的數據讀取到使用者態 Buffer,供應用程式使用
IO模型的不同之處也就在於這兩個操作怎麽互動,我們先看看阻塞IO模型
當應用程式發起 read 呼叫時,呼叫執行緒會阻塞住直到第一步讀取操作的完成。等第一步讀取操作完成後,會將數據讀取到使用者態 Buffer 中,這個過程中呼叫執行緒仍然是阻塞的,直到數據復制完成,整個流程用圖來表示就張這樣:
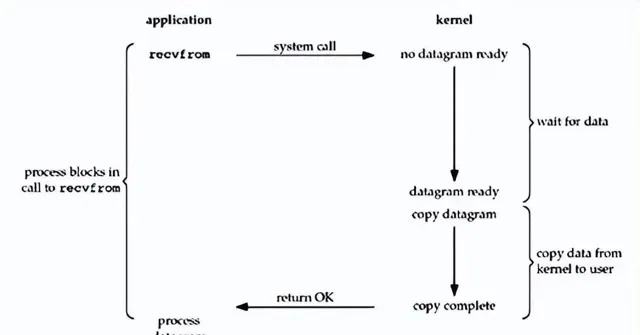
這種 IO 模型的好處就是好理解,API 簡單好上手,適用於連線數不多的網路套用。
7. 五大 IO 模型之:非阻塞 IO
當應用程式發起 read 呼叫時,如果沒有數據可讀,呼叫執行緒不會阻塞。但應用程式為了讀到數據,就會一直迴圈呼叫,直到有數據可讀。微信搜尋公眾號:架構師指南,回復:架構師 領取資料 。
等第一步讀取操作完成後,第二步就和阻塞IO一樣了。會將數據讀取到使用者態 Buffer 中,這個過程中呼叫執行緒仍然是阻塞的,直到數據復制完成,整個流程用圖來表示就張這樣:
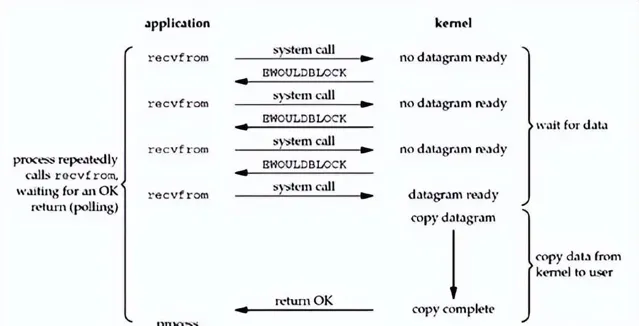
這種 IO 模型的並沒有特別好處,而且會一直迴圈呼叫底層的介面,效能堪憂,很少使用。
8. 五大 IO 模型之:訊號驅動 IO
當應用程式發起 read 呼叫,註冊一個handler,等待有數據後的回呼。應用程式一旦被回呼,就說明數據已經可以讀取了,就會進行第二步操作,把數據讀取到使用者態 Buffer 中。同樣,第二步仍然是阻塞的。
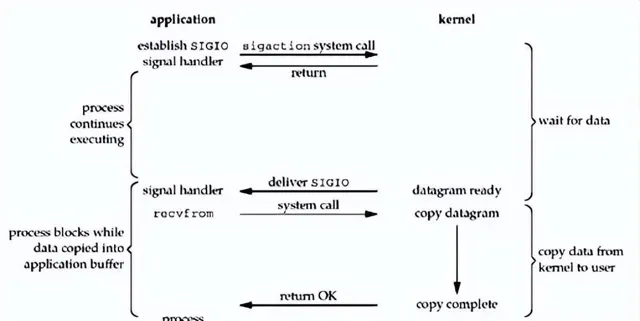
這種 IO 模型的好處就是相比於非阻塞IO,使用通知&回呼機制減少了迴圈的開銷,但是對於連線數多的場景,可能會因為訊號佇列溢位導致沒法通知,用的不多。
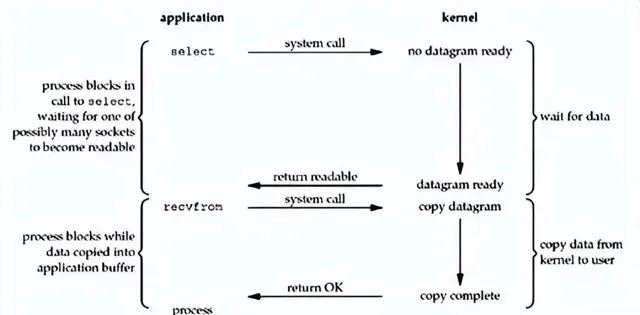
9. 五大 IO 模型之:多路復用 IO
當應用程式發起 read 呼叫時,如果沒有數據可讀,呼叫執行緒不會阻塞,系統會把 socket 註冊到一個「多路復用器」上,等到有數據了會把可讀的socket加入佇列,供套用層使用。
大概的程式碼如下:
java復制程式碼while (true) {
if (selector.select(READ_KEY) > 0) { // selector 就是多路復用器,READ_KEY 大於 1 說明有可讀的socket
Set<SelectionKey> set = clientSelector.selectedKeys();
Iterator<SelectionKey> keyIterator = set.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isReadable()) {
// 讀取數據
}
}
}
}
這種 IO 模型的好處是能夠應對大量的連線,尤其適用於大量的短連線。現在大多數網路套用,底層采用的都是多路復用IO。
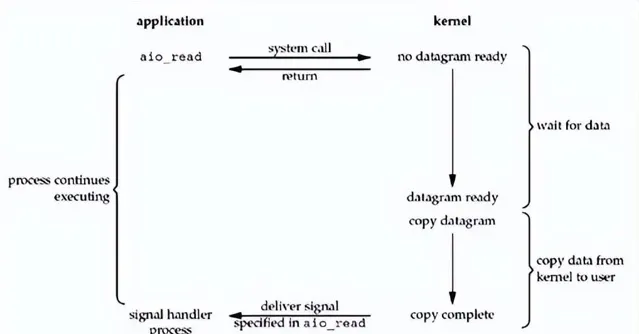
10. 五大 IO 模型之:異步 IO
異步IO 則和上面四種IO模型都不通,他是完完全全的異步,兩步操作都不會阻塞。應用程式發起 read 呼叫後,等收到回呼通知,就可以去使用使用者態 Buffer 的數據了,如下圖所示。
11. 打個比方
打個個人認為很貼切的比方,幫助理解。

大家都去醫院取過藥吧,五種IO模型就像是不同的取藥方式。
阻塞IO: 排隊等藥,排到我了但是藥還沒準備好,那我也繼續等著,別人也不能取。這種我沒好,別人也落不著好的方式,就是阻塞IO的體現。
非阻塞IO: 排隊等藥,排到我了但是藥還沒準備好,那我重新排吧。重新排隊就是輪詢,因為重新排了也沒有阻塞別人取消,就是非阻塞IO的體現。
訊號驅動IO: 不用排隊等藥,藥準備好了就直接簡訊通知你去取。簡訊通知就相當於訊號驅動了,因為不用排隊,節省了不少時間。
多路復用IO: 這個就是日常中常見的那種取藥方式了,付了錢後要去藥房的機器上掃碼,然後盯著顯視器,上面顯示了你的名字,再去取藥。在機器上掃碼就相當於註冊,顯示了你的名字就相當於有需要處理的IO事件了。現實中顯示了我的名字,我還是要去排隊,這也是對應上的,因為一個 selector 返回的是多個需要處理的IO時間,一個個處理就相當於一個個排隊取藥。
異步IO: 這個就很賽博龐克了,異步IO就像是不用排隊,不用取藥,藥好了直接寄你家,完全異步。
12. 可能會產生的疑問:
12.1 Java 的 nio 是對多路復用IO模型的實作,為什麽叫非阻塞?
首先 Java 的 nio 包可以用來實作多路復用IO模型,也可以用來實作非阻塞IO模型,只不過非阻塞IO模型效能差沒人用而已。其次,nio 中的那個「n」是 new 的意思。當時 JDK 的開發者為了和老的io包做區分,才用nio 來表示的,並不是 nonblocking 的「n」,所以叫「新IO包」更準確,也不容易弄混。
12.2 select、poll、epoll有什麽關系
select、poll、epoll 都是用來實作多路復用的,原理也都是透過遍歷找到可讀寫的socket,區別在於
select 有限制,最多1024個,poll、epoll沒有這個限制。
poll 對數據結構有最佳化,沒有 1024 個的限制,但還是要遍歷所有socket,目前很少用。
epoll 對遍歷有最佳化,不會遍歷所有socket,只會遍歷那些可讀的socket,所以效率有所提升。
12.3 訊號驅動 IO 和多路復用 IO 很難分辨
訊號驅動 IO 的底層機制是事件通知,多路復用 IO 的底層機制是遍歷+回呼,只不過在套用層麵包裝成了事件而已。
13. 總結
從網卡中讀取數據有兩步:第一步是網卡到 socket 緩存區,第二步是從 socket 緩沖區到內核態。
IO 模型有五種:阻塞IO、非阻塞IO、訊號驅動IO、多路復用IO、異步IO。
阻塞IO:兩步都阻塞
非阻塞IO:第一步不阻塞,但套用層不知道什麽時候數據可讀,所以需要不斷輪詢
訊號驅動IO:第一步不阻塞,但套用層不感知這一步的阻塞,機制是事件通知機制,數據準備好後直接通知套用層讀取
多路不用IO:第一步不阻塞,但套用層不感知這一步的阻塞,機制是遍歷所有 Socket,有準備好的再通知套用層讀取
異步IO:純異步,數據準備好後,套用層直接使用。
-End-
讀到這裏說明你喜歡本公眾號的文章,歡迎 置頂(標星)本公眾號 Linux技術迷,這樣就可以第一時間獲取推播了~
在本公眾號,後台回復:Linux,領取2T學習資料 !
推薦閱讀
1.
2.
3.
4.