不知道大家有沒有發現一個問題,凡是現在透過語音呼叫大模型的場景都會有延遲導致使用者體驗不好 ,比如AI陪伴類的硬體玩偶、AI電話客服還有即時對話的AI女友。
本質上都是因為跟大模型透過語音對話都要把語音轉換成文本發送給大模型,再把大模型的回答轉換成語音,我們才能聽得到。
這樣一來一回耗費的時間,才導致了我們跟大模型對話流暢度和自然感不夠完美。
Ultravox是一個端到端的多模態大模型,能直接理解音訊,不需要再把音訊和文本相互轉換。
現在已經在Llama 3、Mistral 和 Gemma 上訓練了版本,可用度就很高了。
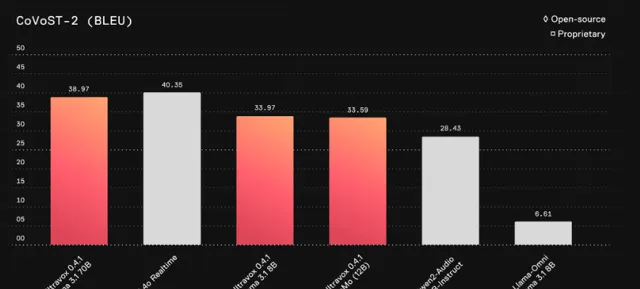
Ultravox 的語音理解能力接近GPT-4o的專有解決方案。
掃碼加入AI交流群
獲得更多技術支持和交流
(請註明自己的職業)

計畫簡介
Ultravox 是一種全新的多模態大語言模型,能夠直接理解文本和人類語音,無需獨立的語音辨識階段。Ultravox 透過與 LLM 高維空間的直接耦合,能夠快速響應語音輸入,具有約 150 毫秒的首次響應時間,並可達每秒 60 個 tokens。Ultravox 在 Llama 3、Mistral 和 Gemma 等 LLM 基礎上進行訓練,最佳化了多模態理解,且具有擴充套件性,可用於不同語言或自訂數據集的訓練。
DEMO
技術特點
1.多模態輸入處理:
Ultravox 能夠同時處理文本和語音輸入,並將音訊直接轉換為 LLM 所需的高維空間數據,而不需要額外的語音辨識(ASR)階段。這種設計使得系統在響應速度和資源消耗上都比傳統的分離式 ASR 與 LLM 系統更高效。
2.快速響應:
目前版本 Ultravox 0.4 在處理音訊輸入時,首次生成 token 的時間大約為 150 毫秒,並且每秒生成約 60 個 tokens,具備很高的即時響應能力。雖然已有較高的效能,但團隊認為還存在進一步最佳化的空間。
3.高效的模型耦合:
Ultravox 透過直接將音訊與 LLM 模型耦合,避免了傳統方法中將語音轉文本再進行理解的復雜流程。這種方法顯著減少了處理延遲,並提高了模型對語音的理解能力,未來還將加入情感和語音節奏等副語言線索的理解。
4.靈活的模型訓練:
Ultravox 支持使用者基於不同的 LLM(如 Llama 3、Mistral、Gemma 等)和音訊編碼器進行自訂訓練。使用者可以透過修改配置檔,選擇不同的基礎模型,並訓練介面卡以改進特定領域或語種的效能。
5.低資源需求的即時推理:
Ultravox 的即時推理可以透過 API 進行存取,並支持將音訊內容以 WAV 檔的形式輸入。對於需要即時語音理解的套用場景,Ultravox 提供了一套靈活且高效的推理框架。
6.支持擴充套件與自訂:
Ultravox 允許使用者使用自己的音訊數據進行訓練,以添加新的語言或領域知識。訓練過程支持透過 MosaicML 等平台進行大規模並列處理,也可以在本地環境中部署。
7.未來的語音流生成:
當前 Ultravox 支持將語音轉換為文本,未來將擴充套件為可以生成語音流(透過 vocoder 進行語音合成)。這意味著 Ultravox 不僅能夠理解語音,還能夠以自然語音的形式進行回應。
8.訓練和評估工具:
Ultravox 提供了豐富的訓練與評估工具,支持使用者自行訓練模型或進行實驗評估。模型訓練過程使用簡單的配置檔,支持多種分布式訓練方式,如 DDP(分布式數據並列)訓練,並且支持整合 WandB 等工具進行實驗日誌記錄。
計畫連結
https://github.com/fixie-ai/ultravox
關註「 開源AI計畫落地 」公眾號
與AI時代更靠近一點
關註「 AGI光年 」公眾號
獲取每日最新資訊
關註「 向量光年 」公眾號
加速全行業向AI轉變











