點選「 IT碼徒 」, 關註,置頂 公眾號
每日技術幹貨,第一時間送達!
一.背景
最近在做一個計畫的時候,由於涉及到需要將一個系統的基礎數據全量同步到另外一個系統中去,結果一看,基礎數據有十幾萬條,作為小白的我,使用單元測試,寫了一段程式碼,直接采用了MP(Mybaties-Plus)內建的
saveBatch()
方法,將基礎數據匯入到新的系統中去,但是後面涉及多次修正基礎數據的情況,導致,每次重新插入數據或者更新的時候,都需要花費十幾分鐘的時間,後面想著以下的方案進行了最佳化。
其實針對內建的
saveBatch()
方法插入很慢,一般都是由於資料庫連線url上沒有配置批次操作的內容,只需要在url上加上如下內容即可,如下:
rewriteBatchedStatements=true
在配置資料庫連線資訊的時候,配置類似如下:
jdbc:mysql://資料庫地址/資料庫名?useUnicode=true&characterEncoding=UTF8&allowMultiQueries=true&rewriteBatchedStatements=true
加上之後,你就會發現,saveBatch的速度直線提升,效果還是很不錯的,一萬條數據估計也就在幾百毫秒。
接下來的文章都是設定在
rewriteBatchedStatements=false
情況下,且MP(Mybaties-Plus)為3.5.3.1版本下進行測試的。
二.最佳化方法
如果在
rewriteBatchedStatements=false
情況下,使用內建的方法,插入幾十萬數據是比較慢的,我們先講解內建的方法,再講解MP給我們自訂空間的自訂方法,然後在加入一些多執行緒的情況下進行的測試和方案比較。
2.1 Mybaties-plus內建的批次saveBatch()方法
直接上程式碼
實體類如下:
@Data
@TableName("test_user")
public classTestUserimplementsSerializable{
private String id;
private String name;
private String managerId;
private String salary;
private String age;
private String departId;
private String remark;
private String province;
}
Mapper如下:
publicinterfaceTestUserMapperextendsBaseMapper<TestUser> {
}
Service如下:
publicinterfaceITestUserServiceextendsIService<TestUser> {
}
@Service
public classTestUserServiceImplextendsServiceImpl<TestUserMapper, TestUser> implementsITestUserService{
}
接下來我使用單元測試的方法,構造200000條數據,測試Mybaties-Plus內建的
saveBatch()
方法,程式碼如下:
@RunWith(SpringRunner. class)
@SpringBootTest(webEnvironment= SpringBootTest.WebEnvironment.RANDOM_PORT, classes = JeecgSystemApplication. class)
public classUserTest{
@Autowired
private ITestUserService userService;
@Test
publicvoidtestInsertBatch(){
List<TestUser> userList = new ArrayList<>();
for(int i = 0; i < 199999; i++){
TestUser user = new TestUser();
user.setName("張三");
user.setAge("20");
user.setProvince("重慶市");
user.setSalary("200000");
user.setRemark("diitch");
userList.add(user);
}
long s = System.currentTimeMillis();
userService.saveBatch(userList);
System.out.println("保存200000條數據消耗" + (System.currentTimeMillis() - s) + "ms");
}
}
測試結果如下,大概需要10s中的時間:
我們可以跟蹤源碼,它的實作如下:
defaultbooleansaveBatch(Collection<T> entityList){
returnthis.saveBatch(entityList, 1000);
}
publicbooleansaveBatch(Collection<T> entityList, int batchSize){
String sqlStatement = this.getSqlStatement(SqlMethod.INSERT_ONE);
returnthis.executeBatch(entityList, batchSize, (sqlSession, entity) -> {
sqlSession.insert(sqlStatement, entity);
});
}
publicstatic <E> booleanexecuteBatch( class<?> entity class, Log log, Collection<E> list, int batchSize, BiConsumer<SqlSession, E> consumer){
Assert.isFalse(batchSize < 1, "batchSize must not be less than one", new Object[0]);
return !CollectionUtils.isEmpty(list) && executeBatch(entity class, log, (sqlSession) -> {
int size = list.size();
int idxLimit = Math.min(batchSize, size);
int i = 1;
for(Iterator var7 = list.iterator(); var7.hasNext(); ++i) { ## 迴圈執行
E element = var7.next();
consumer.accept(sqlSession, element);
if (i == idxLimit) {
sqlSession.flushStatements();
idxLimit = Math.min(idxLimit + batchSize, size);
}
}
});
}
2.2 自訂批次插入或者更新的方法
直接上程式碼,首先我們自訂一個
RootMapper
,繼承
BaseMapper
,自訂自己的批次插入或者更新方法,如下:
/**
* @author diitich
* @param <T>
*/
publicinterfaceRootMapper<T> extendsBaseMapper<T> {
/**
* 批次新增
* @param batchList
* @return
*/
intinsertBatch(@Param("list") Collection<T> batchList);
/**
* 批次跟新
* @param batchList
* @return
*/
intupdateBatch(@Param("list")Collection<T> batchList);
}
定義
InsertBatchColumn
繼承
AbstractMethod
,下面基本就是一些通用的寫法,不同的Mybatis-plus有一點點區別,本文用的版本為3.5.3.1版本,程式碼如下:
@Slf4j
public classInsertBatchColumnextendsAbstractMethod{
@Setter
@Accessors(chain = true)
private Predicate<TableFieldInfo> predicate;
publicInsertBatchColumn(){
super("insertBatch");
}
publicInsertBatchColumn(Predicate<TableFieldInfo> predicate){
// 此處的名稱必須與後續的RootMapper的新增方法名稱一致
super("insertBatch");
this.predicate = predicate;
}
@SuppressWarnings("Duplicates")
@Override
public MappedStatement injectMappedStatement( class<?> mapper class, class<?> model class, TableInfo tableInfo){
KeyGenerator keyGenerator = NoKeyGenerator.INSTANCE;
SqlMethod sqlMethod = SqlMethod.INSERT_ONE;
List<TableFieldInfo> fieldList = tableInfo.getFieldList();
String insertSqlColumn = tableInfo.getKeyInsertSqlColumn(true,false) +
this.filterTableFieldInfo(fieldList, predicate, TableFieldInfo::getInsertSqlColumn, EMPTY);
String columnScript = LEFT_BRACKET + insertSqlColumn.substring(0, insertSqlColumn.length() - 1) + RIGHT_BRACKET;
String insertSqlProperty = tableInfo.getKeyInsertSqlProperty(true,ENTITY_DOT, false) +
this.filterTableFieldInfo(fieldList, predicate, i -> i.getInsertSqlProperty(ENTITY_DOT), EMPTY);
insertSqlProperty = LEFT_BRACKET + insertSqlProperty.substring(0, insertSqlProperty.length() - 1) + RIGHT_BRACKET;
String valuesScript = SqlScriptUtils.convertForeach(insertSqlProperty, "list", null, ENTITY, COMMA);
String keyProperty = null;
String keyColumn = null;
// 表包含主鍵處理邏輯,如果不包含主鍵當普通欄位處理
if (tableInfo.havePK()) {
if (tableInfo.getIdType() == IdType.AUTO) {
/* 自增主鍵 */
keyGenerator = Jdbc3KeyGenerator.INSTANCE;
keyProperty = tableInfo.getKeyProperty();
keyColumn = tableInfo.getKeyColumn();
} else {
if (null != tableInfo.getKeySequence()) {
keyGenerator = TableInfoHelper.genKeyGenerator(model class.getName(), tableInfo, builderAssistant);
keyProperty = tableInfo.getKeyProperty();
keyColumn = tableInfo.getKeyColumn();
}
}
}
String sql = String.format(sqlMethod.getSql(), tableInfo.getTableName(), columnScript, valuesScript);
SqlSource sqlSource = languageDriver.createSqlSource(configuration, sql, model class);
// 註意第三個參數,需要與後續的RootMapper裏面新增方法名稱要一致,不然會報無法繫結異常
returnthis.addInsertMappedStatement(mapper class, model class, "insertBatch", sqlSource, keyGenerator, keyProperty, keyColumn);
}
}
定義
UpdateBatchColumn
繼承
AbstractMethod
,程式碼如下:
public classUpdateBatchColumnextendsAbstractMethod{
publicUpdateBatchColumn(String methodName){
super(methodName);
}
@SuppressWarnings("Duplicates")
@Override
public MappedStatement injectMappedStatement( class<?> mapper class, class<?> model class, TableInfo tableInfo){
String sql = "<script>\n<foreach collection=\"list\" item=\"item\" separator=\";\">\nupdate %s %s where %s=#{%s} %s\n</foreach>\n</script>";
String additional = tableInfo.isWithVersion() ? tableInfo.getVersionFieldInfo().getVersionOli("item", "item.") : "" + tableInfo.getLogicDeleteSql(true, true);
String setSql = sqlSet(tableInfo.isWithLogicDelete(), false, tableInfo, false, "item", "item.");
String sqlResult = String.format(sql, tableInfo.getTableName(), setSql, tableInfo.getKeyColumn(), "item." + tableInfo.getKeyProperty(), additional);
SqlSource sqlSource = languageDriver.createSqlSource(configuration, sqlResult, model class);
// 第三個參數必須和RootMapper的自訂方法名一致
returnthis.addUpdateMappedStatement(mapper class, model class, "updateBatch", sqlSource);
}
自訂sql註入,
MysqlInjector
繼承
DefaultSqlInjector
,程式碼如下:
public classMysqlInjectorextendsDefaultSqlInjector{
@Override
public List<AbstractMethod> getMethodList( class<?> mapper class, TableInfo tableInfo){
List<AbstractMethod> methods = super.getMethodList(mapper class,tableInfo);
// 自訂的insert SQL註入器
methods.add(new InsertBatchColumn());
// 自訂的update SQL註入器,參數需要與RootMapper的批次update名稱一致
methods.add(new UpdateBatchColumn("updateBatch"));
return methods;
}
}
定義MybatiesPlus的配置檔,將
MysqlInjector
註入進去,程式碼如下:
@Configuration
public classMybatiesPlusConfig{
@Bean
public MysqlInjector sqlInjector(){
returnnew MysqlInjector();
}
}
接下來我們還是使用單元測試,構造200000萬條數據,當然我們不能一次性插入20萬條數據,進行分段插入,程式碼如下:
publicinterfaceTestUserMapperextendsRootMapper<TestUser> {
}
@RunWith(SpringRunner. class)
@SpringBootTest(webEnvironment= SpringBootTest.WebEnvironment.RANDOM_PORT, classes = JeecgSystemApplication. class)
public classUserTest{
@Autowired
private TestUserMapper testUserMapper;
/**
* 測試自訂批次新增
*/
@Test
publicvoidtestInsertBatchCustom(){
List<TestUser> userList = new ArrayList<>();
int batchSize = 5000; // 每批次插入的數據量
long s = System.currentTimeMillis();
for(int i = 0; i < 199999; i++){
TestUser user = new TestUser();
user.setName("張三");
user.setAge("20");
user.setProvince("重慶市");
user.setSalary("200000");
user.setRemark("diitch");
userList.add(user);
// 達到批次大小時進行插入
if(userList.size() == batchSize){
testUserMapper.insertBatch(userList);
userList.clear(); // 清空列表,準備下一批數據
}
}
// 插入剩余數據
if(!userList.isEmpty()){
testUserMapper.insertBatch(userList);
}
System.out.println("保存200000條數據消耗" + (System.currentTimeMillis() - s) + "ms");
}
}
上面的程式碼我們設定了一次性批次插入
batchSize = 5000
,執行結果如下,大概需要4~5秒,batchSize值設定不同,執行效率稍微有點不同:

2.3 多執行緒更新 + MP內建saveBatch()方法
上面我們講了自訂批次插入大概能提升一倍的效能,接下來我們使用多執行緒方式更新數據,首先我們先測試使用5個執行緒插入20萬條數據,使用Mybaties-plus內建的
saveBatch()
方法更新,直接上程式碼:
@RunWith(SpringRunner. class)
@SpringBootTest(webEnvironment= SpringBootTest.WebEnvironment.RANDOM_PORT, classes = JeecgSystemApplication. class)
public classUserTest{
@Autowired
private ITestUserService userService;
@Autowired
private TestUserMapper testUserMapper;
@Test
publicvoidtestInsertBatchMulThreadSaveBatch()throws Exception{
int totalRecords = 199999;
int batchSize = 5000;
int threadCount = 5; // 可以根據實際情況調整執行緒數量
ExecutorService executor = Executors.newFixedThreadPool(threadCount);
List<Future<Void>> futures = new ArrayList<>();
long s = System.currentTimeMillis();
for (int i = 0; i < totalRecords; i += batchSize) {
int startIndex = i;
int endIndex = Math.min(i + batchSize, totalRecords);
List<TestUser> batchList = new ArrayList<>();
for (int j = startIndex; j < endIndex; j++) {
TestUser user = new TestUser();
user.setName("張三");
user.setAge("20");
user.setProvince("重慶市");
user.setSalary("200000");
user.setRemark("diitch");
batchList.add(user);
}
Future<Void> future = executor.submit(() -> {
userService.saveBatch(batchList);
returnnull;
});
futures.add(future);
}
// 等待所有執行緒執行完成
for (Future<Void> future : futures) {
future.get();
}
executor.shutdown();
System.out.println("保存200000條數據消耗" + (System.currentTimeMillis() - s) + "ms");
}
}
執行結果如下,大概需要3s多:
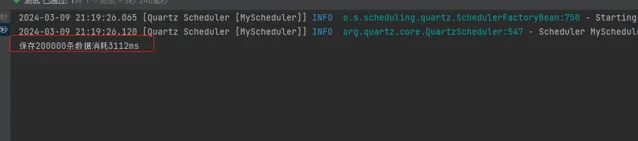
2.4 多執行緒 + 自訂批次插入方法
接下來我們還是使用5個執行緒來插入數據,只是使用我們自己定義的批次插入方法來插入數據,程式碼如下:
@RunWith(SpringRunner. class)
@SpringBootTest(webEnvironment= SpringBootTest.WebEnvironment.RANDOM_PORT, classes = JeecgSystemApplication. class)
public classUserTest{
@Autowired
private ITestUserService userService;
@Autowired
private TestUserMapper testUserMapper;
@Test
publicvoidtestInsertBatchMulThreadCustom()throws Exception{
int totalRecords = 199999;
int batchSize = 5000;
int threadCount = 5;
ExecutorService executor = Executors.newFixedThreadPool(threadCount);
List<Future<Void>> futures = new ArrayList<>();
Set<String> insertedData = Collections.synchronizedSet(new HashSet<>());
long s = System.currentTimeMillis();
for (int i = 0; i < totalRecords; i += batchSize) {
int startIndex = i;
int endIndex = Math.min(i + batchSize, totalRecords);
List<TestUser> batchList = new ArrayList<>();
for (int j = startIndex; j < endIndex; j++) {
TestUser user = new TestUser();
user.setName("張三");
user.setAge("20");
user.setProvince("重慶市");
user.setSalary("200000");
user.setRemark("diitch");
batchList.add(user);
}
List<TestUser> filteredList = batchList.stream()
.filter(user -> !insertedData.contains(user.getName()))
.collect(Collectors.toList());
Future<Void> future = executor.submit(() -> {
testUserMapper.insertBatch(filteredList);
filteredList.forEach(user -> insertedData.add(user.getName()));
returnnull;
});
futures.add(future);
}
// 等待所有執行緒執行完成
for (Future<Void> future : futures) {
future.get();
}
executor.shutdown();
System.out.println("保存200000條數據消耗" + (System.currentTimeMillis() - s) + "ms");
}
}
執行結果如下,大概需要2s左右時間

三.總結
一般我們設定
rewriteBatchedStatements=true
時,批次插入功能已經相對較快,如果還滿足不了需求,我們可以使用多執行緒進行批次插入,下面是在設定
rewriteBatchedStatements=true
時,插入20萬條數據
saveBatch()
以及 saveBatch + 多執行緒的方式的執行結果:
單獨的
saveBatch()
方法,差不多也是4秒多,也達到了我們自訂的批次插入方法效能:

saveBatch()
+ 多執行緒的方法,執行結果如下,大概只需要1秒多,比我們自訂批次插入 + 多執行緒方法還要快:

來源:https://blog.csdn.net/m0_37742400
— END —
PS:防止找不到本篇文章,可以收藏點贊,方便翻閱尋找哦。
往期推薦











