上周, PingCAP AI Lab 數據科學家 孫逸神的文章【 】從使用者的角度談了長視窗 & RAG 的看法, 引起了眾多同行的圍觀。
本周我們采訪了
張粲宇
,看看搞向量資料庫的業內人士,是怎麽看待這個問題的
?
作者簡介
張粲宇,Zilliz Senior Product Manager。Milvus 產品負責人,主導向量資料庫 Milvus 關鍵特性的定義與產品路線圖的規劃,Ask AI 計畫負責人。
Ask AI,一個基於 RAG 技術搭建的企業級產品文件問答機器人。

01 探索大模型的開啟方式:RAG 與長文本
隨著 GPT-4o 與 Astra 在 Google IO 大會上的釋出,生成式人工智慧(AIGC)的行程再次加速。在大模型的多模態能力與效果百花齊放的同時,價效比已然成為各大模型公司競爭的主要策略。
經過這一年多的狂飆,相較於過去簡單粗暴地依賴 Scaling Law 無視成本地堆積算力,現在 AIGC 的發展更加貼近實際套用,使用場景也逐漸明晰。人們開始以更務實和落地的視角來探索大模型的正確使用方式。
在眾多大模型的開啟方式中,檢索增強生成技術(Retrieval-Augmented Generation,簡稱 RAG)受到廣泛關註,並被套用在許多實際場景中,如知識庫問答、學習助手、情感陪伴機器人等。
一個典型的 RAG 框架由 檢索器(Retriever)和生成器(Generator) 兩部份組成。在檢索之前,需要對原始數據進行預處理,包括為數據(如 Documents)進行切分、嵌入向量(Embedding)並構建索引(Chunks Vectors)。
在檢索階段,透過向量檢索以召回相關結果,而在生成階段則利用基於檢索結果(Context)增強的 Prompt 來啟用 LLM 以生成 回答(Result) 。
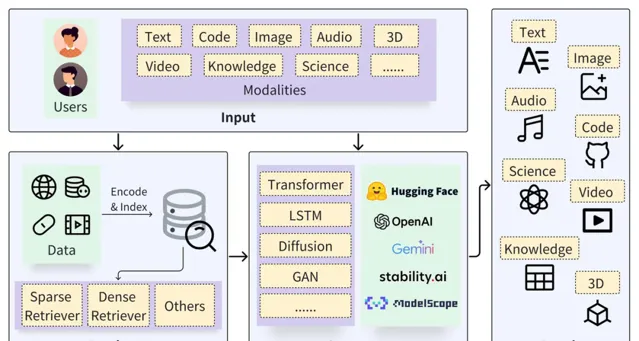
https://arxiv.org/pdf/2402.19473
RAG 技術的關鍵在於其結合了檢索系統與生成模型的優點: 檢索系統能提供具體、相關的事實和數據,而生成模型則能夠靈活地構建回答,並融入更廣泛的語境和資訊 。
這是一種典型取的取長補短、解耦分治的思想。這種結合使得 RAG 模型在處理復雜的查詢和生成資訊豐富的回答方面表現出強大的能力,因此 RAG 在問答系統、對話系統和其他需要理解和生成自然語言的套用中極具價值。
相較於原生的大型模型,RAG 提供了以下天然的優勢:
減輕 「幻覺」 問題 :RAG 透過檢索外部資訊作為輸入,輔助大型模型回答問題,這種方法能顯著減少生成資訊不準確的問題,同時增加回答的可追溯性。
數據私密和安全 :RAG 可以將知識庫作為外掛資料庫來管理企業或機構的私有數據資產,避免數據在模型學習後以不可控的方式泄露。
資訊的即時性 :RAG 允許從外部資料來源即時檢索資訊,因此可以獲取最新的、領域特定的知識,解決知識時效性問題。
同時,隨著大模型技術的不斷叠代,長上下文技術(Long-Context,簡稱長文本)能幫助大模型在 每輪對話中處理更多上下文 和背景知識,從而生成更佳的回答。
隨著上下文視窗長度的增加,模型可以獲取更豐富的語意資訊,有助於降低大型語言模型的錯誤率和產生 "幻覺" 的可能性,從而提高使用者體驗。
正因為此,長文本能力在近一年的時間裏一路狂飈,OpenAI 從最初 GPT-3.5 的 4k token 增加到 GPT-4 Turbo 的 128k,OpenAI 的最強競爭對手 Anthropic 釋出的 Claude 3 Opus 一次性將上下文長度提高到了 100 萬 token,谷歌宣布今年晚些時候將模型的現有上下文視窗再增加一倍,達到 200 萬 token。
這將使其能夠同時處理 2 小時的視訊、22 小時的音訊、超過 60,000 行程式碼或超過 140 萬個單詞。這意味著它幾乎可以一次性讀完任何一本長篇小說,理解並梳理小說脈絡,並且可以做到針對具體問題 「大海撈針」 般神奇地找到細節片段和相關描述。
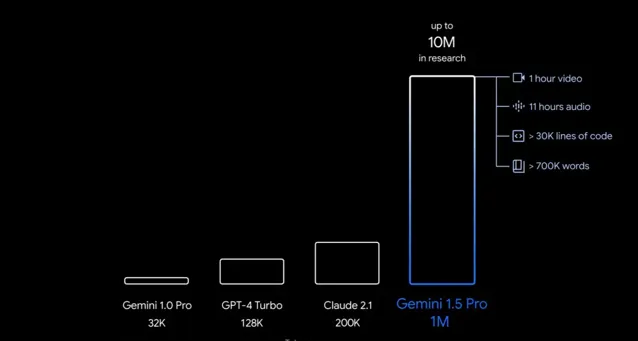
業界人士普遍認為,上下文長度的增加對模型能力的提升具有重大意義。正如 OpenAI 的開發者關系主管 Logan Kilpatrick 所說,「上下文就是一切,是唯一重要的事」。提供充足的上下文資訊是獲取有意義回答的關鍵。
隨著大模型公司對長文本技術的競爭加劇,上下文視窗的上限也在不斷被挑戰和突破。這種突破讓人們看到了全新的資訊檢索的可能性。
因此,有人提出了一個問題:隨著大模型長文本能力的進步,如果長文本能夠完全替代 RAG,那麽 RAG 是否還有存在的必要呢?
對此,我的個人觀點是,
長文本模型並不能取代 RAG,兩者將共同進步、互補發展。在 AI 時代,它們將協同工作,幫助人們更加有效地管理以及利用數據和知識。
02 長文本為何無法取代 RAG?
長文本在一些簡單任務上(如讀一篇研報、總結一篇論文等)確實可以很好滿足需求且能提供更簡單的使用體驗,然而在更復雜的 toC 和 toB 端使用場景下長文本無法取代 RAG。
長文本無法取代 RAG 的原因主要有兩方面:一個是從原理推匯出的物理限制,另一個則是實際場景中會面臨的各類挑戰 。
在分布式系統領域有著著名的 CAP 定理,即一致性(Consistency)、可用性(Availability)和分區容忍性(Partition tolerance)三個基本保證無法同時得到滿足。
而在長文本方面,同樣也存在 文本長度、註意力和算力的 「不可能三角」, 這表現為:文本越長,越難聚集充分註意力,難以完整消化;而在註意力限制下,短文本無法完整解讀復雜資訊;而要精準地處理長文本需要大量算力,進而提高成本。
在實際套用中,大模型的 呼叫成本和上下文文本長度的平方成正比 ,其 計算代價和響應延遲 都會受到上下文的影響。在保證精度不遺失的前提下,使用超長文本作為上下文輸入的消耗是巨大的,因此實際套用中很難找到能承受如此高代價的套用進行大規模落地。
即便拋開成本和響應延時不談,若要直接把長文本套用到實際場景中,依舊會遇到諸多方面的限制和問題。
首先,在 可延伸性 方面,即使是以業內翹楚 Google Gemini 的數百萬 token,在大型企業和互聯網的大數據面前也顯得微不足道。關於大模型的記憶結構,一個簡單的類比是:大模型的參數是寄存器,長文本是記憶體,而 RAG 則是硬碟。無論記憶體有多大,終究無法一次性裝下整個世界的數據。因此在擴充套件性方面,不是長文本不好用,而是 RAG 更具有價效比。
其次, 數據的管控和安全性 也是 RAG 系統的優勢。長文本可以很好地理解知識,但管理和維護知識的能力卻相對較弱。例如,在企業對部份規章或制度做了變更的情況下,這在 RAG 系統裏可以只是少量數據的部份更新,但在長文本裏卻需要重新開始。這就體現了在資訊更新和修改靈活度上的差異。再舉一個具體的例子,企業不同角色的員工應該有不同的存取許可權。例如,薪酬專員可以存取各部門員工薪資,而其他員工則不能,這裏的身份驗證和許可權管理是 RAG 數據管理系統的強項,而大模型的 prompt 目前很難做到精確的許可權管理。此外,透過 RAG 企業可以在本地管理和控制自己的數據,同時利用外部的推理模型進行查詢和生成,解耦的系統結構可以更好的確保數據安全性。
此外,在 可解釋性 方面,長文本的 「黑盒」 模型使得調優很難下手。而在醫療、金融、法律等高風險領域,AI 系統的溯源性至關重要。RAG 的分階段模型可以提供清晰的推理鏈條,每個階段的結果都可以稽核、分析、偵錯,在必要情況下可以引入人工幹預,這種人機協同既可以彌補演算法的不足,消除幻覺提升答案品質,又有助於發現數據問題並進行及時糾正和後續處理,這對許多嚴肅場景是更為系統的解法。
因此,在 更通用的場景下,RAG 依然是一個穩定、可靠且價效比高的選擇 。
實際上,在綜合考慮成本、效果、安全性等諸多方面因素後,大量 AIGC 套用也還是采用 RAG 的方式來構建服務的,這裏也包括我們自家產品 Milvus 官方文件站的 就是基於 RAG 來構建的,歡迎大家試用看看效果。
03 展望未來:相得益彰的 RAG 與長文本
從上述的分析來看,在資訊檢索領域長文本並不能完全取代 RAG,也不應該直接替代。我們需要根據實際需求和條件,選擇最合適的工具和方法。
展望未來,長文本和 RAG 其實都還有很多工作可以做。 長文本的未來會向著更長、更快、更便宜的方向發展。
隨著技術的進步,長文本將能夠處理更長的上下文,這將使 AI 能夠理解更復雜的對話和問題,生成更長和更深入的文本。
在這個過程中,價效比的最佳化方案也將成為重要的研究方向。如何透過更先進的演算法和硬體創新來保證模型效能的同時,降低長文本的計算成本,這將是長文本被更廣泛套用,在各種場景中發揮更大作用的關鍵。
而 RAG 的發展方向則是:更準確、更體系、資訊密度更高。
由於RAG 的檢索準確率是保證回答品質的基石,因此檢索一定是朝著更精準的方向探索,業界對於更高級的混合檢索等技術手段都還在積極探索。
此外,RAG 的發展也將更加註重知識結構的最佳化。例如,我們可以利用階層和圖結構來組織和管理知識,使得資訊檢索和生成更為準確和高效。
同時,透過一些前沿的技術手段如知識蒸餾,我們可以將大量重復了冗余的資訊濃縮成知識進行管理,因此更高效的處理檢索問題。
同時, 長文本模型和 RAG 模型的結合 將成為一種可能的發展趨勢。長文本決定了大模型能處理的視窗長度即資訊數量,而 RAG 則幫助最佳化了和大模型互動的資訊品質,這兩者的有機結合才是大模型在未來正確的開啟方式。
延伸閱讀:
Reference
https://arxiv.org/pdf/2402.19473
END
熱門文章
-
-
-
-
-












