前些天看到的兩篇論文,論文標題為:
【The Power of Noise Redefining Retrieval for RAG Systems】
【How Easily do Irrelevant Inputs Skew the Responses of Large Language Models】 主要講述了檢索文件是如何影響大模型輸出的以及相關實驗結果,為了浪費時間,大家可以參考下其中的結論。
0 1
論文1:【The Power of Noise Redefining Retrieval for RAG Systems】
研究問題
本篇論文探討了RAG系統中的檢索對系統效能的影響。與傳統的大型語言模型相比,RAG系統透過引入外部數據提高了其生成能力。然而,大多數關於RAG系統的研究主要集中在語言模型的生成方面,而忽略了IR的作用。透過對各種元素進行評估,如文件的相關性、位置和數量等,發現包含不相關文件可以意外地提高準確性超過30%。
本文旨在分析資訊檢索元件對Retrieval-Augmented Generation (RAG)系統的影響,探究文獻檢索的關鍵特征,以及檢索到的文獻應該具備哪些特點,從而提高RAG系統的生成能力。
主要研究內容
論文提出了以下研究問題:「構建問題所需的檢索器的基本特征是什麽?當前的檢索器是理想的嗎?」。
論文關註檢索器可以獲取的三種主要文件型別:直接相關、間接相關和不相關(relevant, related, and irrelevant)。
直接相關(Relevant)文件包含與查詢直接相關的資訊,提供直接回答或查詢的黃金標準數據(gold-standard data)。
間接相關文件(Related documents)雖然不能直接回答查詢,但與主題在語意或上下文上存在聯系。例如,如果有人詢問拿破侖馬的顏色,有個文件表達了拿破侖妻子馬的顏色,雖然不包含正確的資訊,但會高度相關。
不相關(irrelevant)的文件與查詢無關,代表了檢索過程中的一種資訊雜訊。
實驗方法
研究中,作者根據文件與查詢的相關性和關系,將文件分類為四種不同型別,每個型別由一個唯一的符號表示: 黃金文件( Gold Document):指的是NQ數據集中的原始上下文,具體是包含答案且與給定查詢相關的一個維基百科頁面的段落。
直接相關文件(Relevant Document):相關文件與黃金文件類似,包含正確答案且在回答查詢方面提供有用的上下文,提供了正確且與查詢相關的額外資訊來源。值得註意的是,黃金文件是一個相關文件。
間接相關文件:相關文件與查詢在語意上相似,但不包含正確答案。它們在評估生成器區分相關和不相關資訊的能力方面發揮著關鍵作用。
不相關文件:不相關文件與查詢無關,也不包含答案。它們在評估模型處理完全不相關資訊的能力方面發揮著關鍵作用,論文實驗中從語料庫中隨機采樣這些文件。
數據集:自然問題(Natural Questions, NQ)
自然問題(Natural Questions,NQ)數據集是一個來自谷歌搜尋數據的大規模真實世界查詢集合。數據集中的每個條目都包含一個使用者查詢和包含答案的相應維基百科頁面。該數據集旨在促進自然語言理解和開放域問答研究,為真實世界的問題和相關上下文的答案提供了豐富的來源。NQ-open數據集是NQ數據集的一個子集,其區別在於去除了將答案連結到特定維基百科段落的限制,從而模擬了類似網路搜尋的更一般的資訊檢索方案。
為了緩解時間不匹配問題,論文將原始NQ數據集中的黃金文件整合到維基百科文件集中,最終數據集包括21035236個文件,訓練集中有72209個查詢,測試集中有2889個查詢。

研究中,作者根據文件與查詢的相關性和關系,將文件分類為四種不同型別,每個型別由一個唯一的符號表示:
黃金文件( Gold Document):指的是NQ數據集中的原始上下文,具體是包含答案且與給定查詢相關的一個維基百科頁面的段落。
直接相關文件(Relevant Document):相關文件與黃金文件類似,包含正確答案且在回答查詢方面提供有用的上下文,提供了正確且與查詢相關的額外資訊來源。值得註意的是,黃金文件是一個相關文件。
間接相關文件:相關文件與查詢在語意上相似,但不包含正確答案。它們在評估生成器區分相關和不相關資訊的能力方面發揮著關鍵作用。
不相關文件:不相關文件與查詢無關,也不包含答案。它們在評估模型處理完全不相關資訊的能力方面發揮著關鍵作用,論文實驗中從語料庫中隨機采樣這些文件。
實驗內容
主要研究內容
使用兩步法,與典型的RAG設定一致。
作為第一元件,實驗使用基於BERT的密集檢索器Contriever 作為預設檢索器。它在沒有監督的情況下使用對比損失進行訓練。
為了增強語料庫(包含約2100萬文件)內的相似性搜尋效率,還采用了FAISS IndexFlatIP索引系統。每個文件和查詢的嵌入都是透過對模型最後一層的隱藏狀態進行平均獲得的。
LLM輸入
在接收到查詢後,檢索器根據給定的相似度測度從語料庫中選擇前k個文件。這些文件與任務指令和查詢一起構成了LLM生成響應的輸入。NQopen數據集的結構僅包括答案包含不超過5個標記的查詢。因此,LLM的任務是從提供的文件中提取一個響應,限制為最多5個標記。
提示的樣版如圖1所示,以斜體表示的任務指令開始。其次是上下文,包括所選文件。查詢接下來是文件的安排。雖然上下文的組成將根據單個實驗而變化,但指令將始終放在提示的開頭,查詢始終放在末尾。
實驗結果
準確性
NQ-open數據集允許每個查詢有一系列潛在的答案。通常,這些答案是相同概念的不同變體(例如,「D. Roosevelt總統」或「Roosevelt總統」),但在某些情況下,一個查詢可能會有多個不同的正確答案。為了評估LLMs生成的響應的準確性,論文采用:檢查LLMs生成的響應中是否包含預定義的至少一個正確答案,根據答案是否存在以二進制方式測量LLMs的響應的正確性。
一個主要問題在於確定響應的正確性,特別是在涉及日期表示或傳達相同含義的不同短語的情況下。例如,如果LLMs對查詢生成「Roosevelt」的響應,而已確定的正確答案是「Roosevelt總統」,則根據論文當前的評估模式,響應將被視為不正確。
相關但不包含答案文件的影響
相關但不包含答案文件設定為由檢索器分配了較高的分數,但不包含答案的文件。下表是LLM在使用由黃金文件和不同數量相關但不包含答案的文件組成的提示進行評估時的結果。「Far」,"Mid","Near"分別代表將黃金文件放置在不同的位置,第一行「0」代表沒有添加相關但不包含答案的文件,往後依次增加相關文件數量。「-」代表輸入超出LLM所支持的輸入長度。
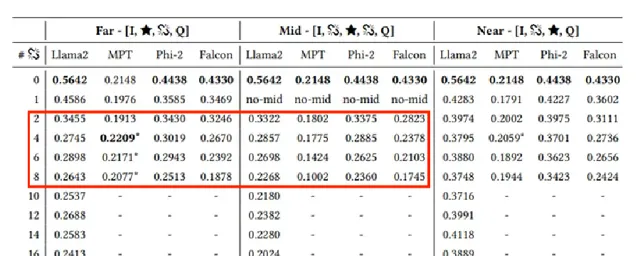
相關但不包含答案文件的影響
下圖是添加相關但不包含答案文件後導致輸出錯誤的例子,黃色代表金標準文件與正確答案,很明顯,那些相關但不包含答案文件誤導了LLM,導致準確率下降。

相關但不包含答案文件的影響
除此之外,作者還展示了模型分別對相關但不包含答案文件和黃金文件的註意力分數,如下圖所示,模型過分關註一個相關但不包含答案文件(最左邊)而忽視黃金文件(最右邊),可能導致錯誤的響應
雜訊影響
為了評估RAG系統對雜訊的魯棒性,為黃金文件中添加了一定數量的從語料庫中隨機挑選的文件作為不相關文件也就是雜訊。實驗結果如下表所示:
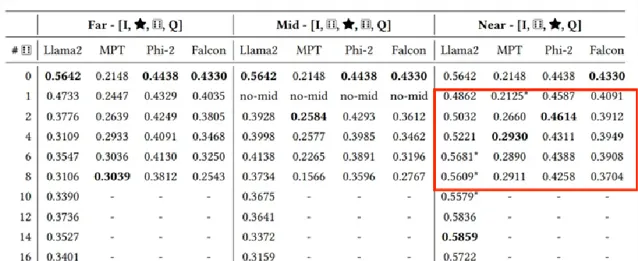
黃金文件位置影響
實驗進一步探討了黃金文件(即包含正確答案的文件)在上下文中的位置對模型效能的影響。「Far」,"Mid","Near"分別代表將黃金文件放置在不同的位置,。上述兩個大表中都可以看到。
實驗結果表明,黃金文件的位置對RAG系統的效能有顯著影響。
在添加相關但不包含答案文件的設定中,當黃金文件靠近查詢語句時,模型的準確度最高。相反,當黃金文件位於上下文中間或遠離查詢語句時,模型的準確度降低。在無關文件的設定中,某些模型即使在雜訊較多的情況下也能保持或提高效能。
這些發現強調了在RAG系統中,檢索器需要精心設計以確保黃金文件的最佳位置,以提高整體系統的準確度。
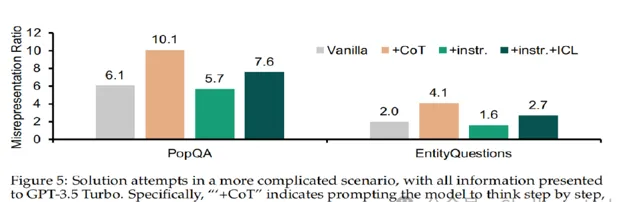
現實場景下的RAG檢索器
以上實驗都是在檢索到標準答案的假設下進行的,但在實際場景中,並不可能每次都能檢索到包含答案的文件。作者設定了一個更現實的場景。給定一個查詢,檢索一組文件,它們可以是相關的,也可能是相關但不包含答案的。向這組檢索到的文件中添加無關文件,如下表所示,行表示添加的不相關文件數量 ,列表示檢索到的文件數量。
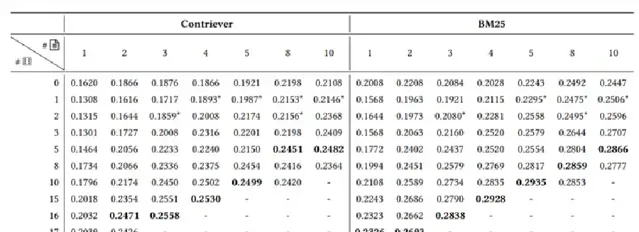
這些結果表明,在檢索器的設計中,需要找到相關文件和無關文件之間的最佳平衡點。
無關文件真的完全無關?
以上的實驗表明,添加無關文件能夠提高效能。但有人可能會認為這些文件並不是真正無關的,因為它們是來源於同一語料庫(維基百科),並且可能導致LLM以更符合該特定語料庫的方式作出回答,而不會引入實質性的雜訊。
因此,作者進行了另一個實驗,其中無關文件是從 Reddit Webis-TLDR-17 數據集中抽取的,為它在語氣和風格上與維基百科有著明顯的對比。
如下表所示,左側部份報告了添加Reddit中的無關文件的結果,右側部份報告了由隨機詞匯組成的無意義句子的結果。

為什麽雜訊有效?
有文獻認為即極低的註意力熵會導致LLM生成退化輸出並且效能急劇下降。這些情況被稱為熵崩塌。沿著這一研究方向,作者測量了僅提供金標準文件的情況下註意力分數的熵,與添加隨機文件的情況相對比。
結果發現,引入隨機文件後,系統的熵增加了3倍。但這一現象並不能完全解釋為什麽雜訊有效,留待未來繼續研究。
論文總結
從相關文件的位置應靠近查詢,否則模型很難關註到它。
與查詢語意相關但不包含答案文件對RAG系統極為有害,後續研究應該想辦法從檢索到的文件中剔除這些幹擾項。
與預期相反,無關的雜訊文件在正確放置時有助於RAG提高系統的準確性。
論文程式碼:https://github.com/florin-git/The-Power-of-Noise
0 2
論文2:【How Easily do Irrelevant Inputs Skew the Responses of Large Language Models】
研究問題
RAG(檢索增強生成)透過檢索系統找到使用者問題相關的資訊片段,利用大模型綜合生成一個答案,極大解決了大模型幻覺、資訊更新不及時等問題,已經成為了大模型落地的重要手段。但在檢索過程中,往往會檢索到與問題極度相似、但又不包含答案或包含幹擾答案的片段,這些答案無關片段對大模型生成答案有何影響呢?
本文的主要貢獻在於提出了一種新的構建高品質無關資訊的方法,並透過詳細的實驗分析了其在各種場景下的效能表現。相比於以往的研究,該方法更加全面、細致地考慮了無關資訊對模型效能的影響,並提供了一些實用的技術手段來幫助RAG系統更好地應對這一挑戰。
研究內容
本文主要解決了兩個問題:
一是如何構建高品質的無關資訊,以幫助RAG系統更好地過濾掉無關的內容;
二是如何評估模型在面對不同場景下的效能表現,以便更好地理解模型與無關資訊之間的關系,並為改進RAG系統的效率和效果提供指導。
這些問題都是當前RAG系統面臨的實際挑戰,而本文提出的解決方案可以為其帶來一定的改進和提升。
實驗方法
數據集
PopQA :PopQA 是一個大規模開放域問答 (QA) 數據集,由 14k 個以實體為中心的 QA 對組成。每個問題都是透過使用樣版轉換從維基數據檢索的知識元組來建立的。每個問題都帶有原文subject_entitiey和註釋,以及object_entity、relationship_type
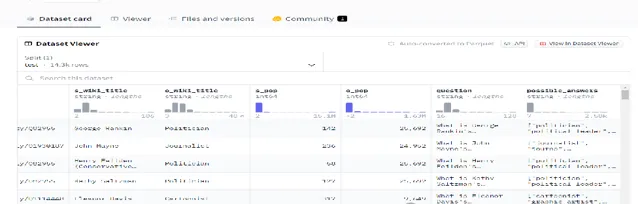
What is George Rankin's occupation?
["politician", "political leader", "political figure", "polit.", "pol"]
EntityQuestions 是基於維基數據事實的簡單、實體豐富的問題數據集
為了在套用場景中包含更廣泛的問題型別,作者采用了另一個廣泛使用的以實體為中心的QA數據集整體問題來擴大多樣性。排除了之前在POPQA中處理過的關系,以最小化冗余,在這個數據集中產生了17種不同的關系型別。與POPQA的規模一致,在每個關系中隨機抽取1500個條目,用於後續實驗。
https://github.com/princeton-nlp/EntityQuestions
答案不相關片段
語意不相關資訊(Unrelated Information):選擇與問題主題無關,但在檢索系統中可能因為高相似性得分而被檢索到的資訊。
部份相關資訊(Partially Related Information):包含與問題主題部份重疊的資訊,但不提供問題的答案。
相關資訊(Related Information):與問題高度相關,但並不提供正確答案的資訊,可能透過誤導性的聯系來幹擾模型。
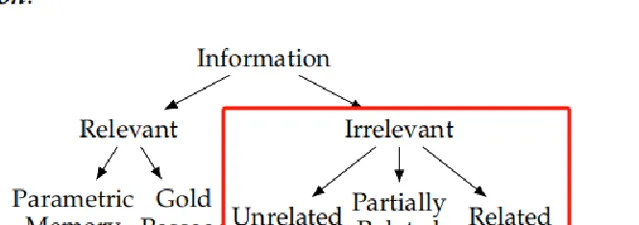
數據構造
透過檢索器直接檢索Top10的段落;無關:為了構建這樣的資訊,作者選擇一個來自具有最高相似性的相同關系(e.g., place of birth)的段落分數,前提是它包含另一個主語'和相應的賓語',作為「不相關的」資訊」。部份相關:從檢索Top10的段落中選擇一個包含subj,但缺少obj的段落,作為前半段;然後找到一個包含錯誤答案obj'的片段作為後半段;相關:與「部份相關」相比,「相關」片段與問題高度語意相關,但並不包含正確答案,主要涉及系誤導性聯型別、共同特征型別和虛構軼事型別。

評估指標
評估指標
誤表述比率(Misrepresentation Ratio,MR):衡量LLMs因受到無關資訊影響而改變正確回答內容的比例。
不確定比率(Uncertainty Ratio,UR):衡量LLMs在回答中表述「不確定」的比例。
為了方便評測,采用多項選擇題的形式進行LLMs評估,將「正確答案」、「錯誤答案」以及「不確定」作為選擇供LLMs選擇。

實驗結果
無關資訊數量的影響
無關資訊數量的增加會降低LLMs辨識真正相關資訊的能力,使它們更容易分心。
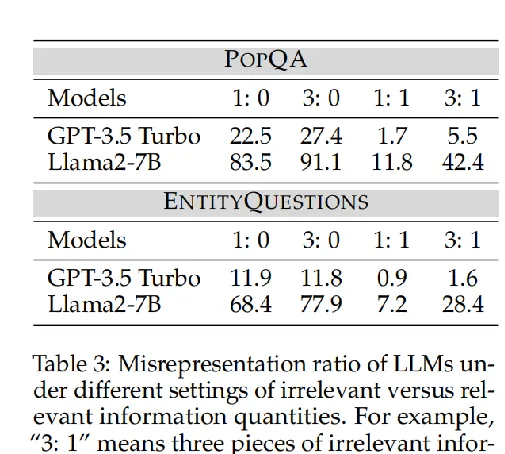
語意相關性的影響
與不相關資訊相比,LLMs更容易被高度語意相關的無關資訊所誤導。
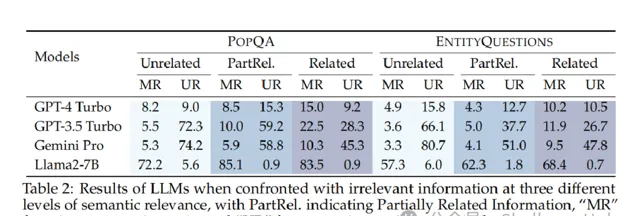
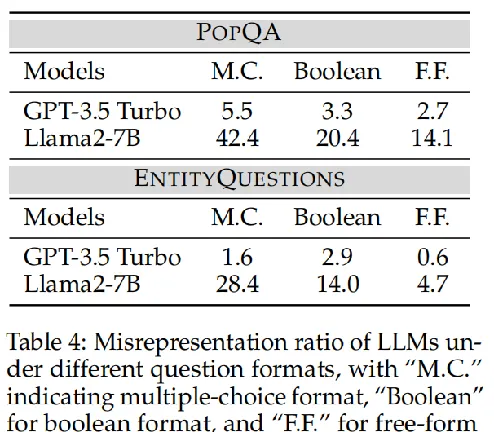
問題格式的影響
LLMs在自由形式的問題格式下表現出更強的魯棒性。
忽略式Prompt對結果有微弱的改善,COT、忽略式Prompt+ICL對結果有害,效果變得更差。