工具介紹
註意:該部份介紹摘抄自:https://www.aiwanyun.cn/archives/174
Prometheus、Grafana、Node Exporter 和Alertmanager是一組用於監控和視覺化系統效能的開源工具。它們通常一起使用,形成一個強大的完整的監控和告警系統。一般來說,這四個工具一起協作,形成了一個完整的監控和告警系統。Node Exporter用於收集主機級別的指標(本文暫未使用),Prometheus儲存和查詢這些指標,Grafana提供視覺化界面,而Alertmanager則負責管理和發送告警。整個系統的目標是幫助管理員和開發人員即時了解系統的狀態、效能和健康狀況,並在必要時采取措施。
Prometheus
Prometheus 是一種開源的系統監控和警報工具。它最初由 SoundCloud 開發,並成為 Cloud Native Computing Foundation(CNCF)的一部份。Prometheus 支持多維度的數據模型和強大的查詢語言,使得使用者可以輕松地收集和查詢各種型別的監控數據。
Grafana
Grafana 是一個開源的數據視覺化和監控平台。它提供了豐富的圖表和儀表盤,可以將各種資料來源的資訊視覺化展示。Grafana 支持多個資料來源,包括 Prometheus、Graphite、InfluxDB 等,因此可以與各種監控系統整合,提供靈活且強大的視覺化功能。
Alertmanager
Alertmanager 是 Prometheus 生態系中的一個元件,負責處理和管理告警。當 Prometheus 檢測到異常或達到某個預定的閾值時,它將生成告警並將其發送到 Alertmanager。Alertmanager 可以進行靜默、分組、抑制和路由告警,並將它們發送到不同的接收端,如電子信件、Slack 等
.NetCore計畫準備
基於我的一個範例計畫進行改造,計畫地址:https://gitee.com/AZRNG/my-example ,為了演示一個基本的監控效果,監控的數據也只是請求,具體生產環境需要監控什麽業務,這個看具體情況了,這裏需要在原來的計畫基礎上需要安裝以下nuget包
<PackageReference Include="OpenTelemetry.Exporter.Prometheus.AspNetCore" Version="1.7.0-alpha.1" />
<PackageReference Include="OpenTelemetry.Extensions.Hosting" Version="1.7.0" />
然後就可以註入服務,這裏只是舉例操作
services.AddOpenTelemetry()
.WithMetrics(builder =>
{
builder.AddPrometheusExporter();
builder.AddMeter("Microsoft.AspNetCore.Hosting", "Microsoft.AspNetCore.Server.Kestrel");
});
最後記得要使用服務
app.MapPrometheusScrapingEndpoint();
啟動計畫後存取 ip+ metrics存取頁面
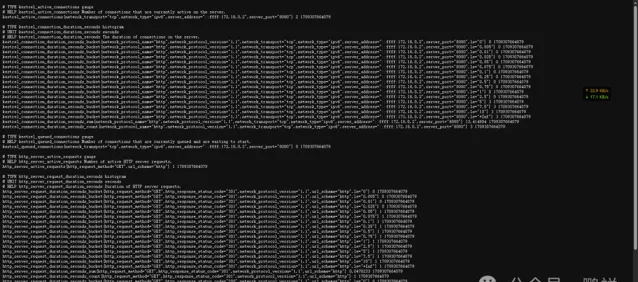
然後將該範例計畫使用docker部署到伺服器上 ,如果要使用該範例計畫,記得切換分支到develop,將計畫拉取到伺服器,然後進入計畫目錄,執行命令去生成容器
sudo docker-compose up -d
部署成功截圖如下
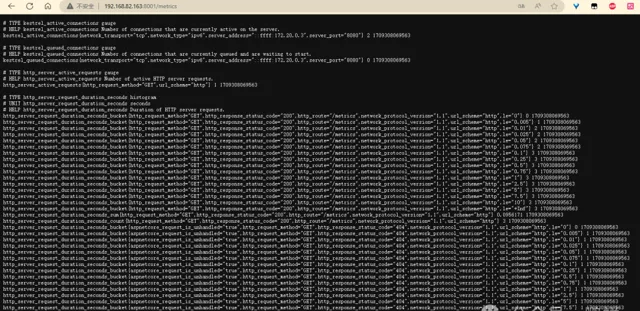
存取地址 http://192.168.82.163:8001/metrics
安裝監控和視覺化程式
準備一個伺服器,提前安裝好了docker以及docker-compose程式,版本範例如下
關於Prometheus和Grafana可以透過docker進行安裝到伺服器中,可以參考倉庫:https://gitee.com/AZRNG/common-docker-yaml
安裝Prometheus
因為這裏我只是用於做demo演示效果,所以我並沒有取考慮掛載的問題,生產環境使用記得掛載數據
version: '3'
services:
prometheus: # 存取:http://localhost:9090/targets
image: prom/prometheus:v2.37.6
container_name: prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.console.libraries=/usr/share/prometheus/console_libraries'
- '--web.console.templates=/usr/share/prometheus/consoles'
- '--web.external-url=http://localhost:9090/'
- '--web.enable-lifecycle'
- '--storage.tsdb.retention=15d'
volumes:
#- /etc/localtime:/etc/localtime:ro
- ./config/prometheus/:/etc/prometheus/
#- ./data/prometheus:/prometheus
ports:
- 9090:9090
links:
- alertmanager:alertmanager
alertmanager: # 告警服務
image: prom/alertmanager:v0.25.0
container_name: alertmanager
ports:
- 9093:9093
volumes:
# - /etc/localtime:/etc/localtime:ro
- ./config/prometheus/:/etc/alertmanager/
command:
- '--config.file=/etc/alertmanager/alertmanager.yml'
- '--storage.path=/alertmanager'
關於prometheus.yml內容如下
# 全域配置
global:
scrape_interval: 15s
evaluation_interval: 15s
# scrape_timeout is set to the global default (10s).
# 告警配置
alerting:
alertmanagers:
- static_configs:
- targets: ['localhost:9093']
# 載入一次規則,並根據全域「評估間隔」定期評估它們。
rule_files:
- "/config/rules.yml"
# 控制Prometheus監視哪些資源
# 預設配置中,有一個名為prometheus的作業,它會收集Prometheus伺服器公開的時間序列數據。
scrape_configs:
# 作業名稱將作為標簽「job=<job_name>`添加到此配置中獲取的任何數據。
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node'# .NetCore服務地址
static_configs:
- targets: ['localhost:9100']
labels:
env: dev
role: docker
alertmanager.yml檔,我並沒有做配置,暫時搞了一個預設的
global:
resolve_timeout: 5m
smtp_smarthost: 'xxx@xxx:587'
smtp_from: 'zhaoysz@xxx'
smtp_auth_username: 'xxx@xxx'
smtp_auth_password: 'xxxx'
smtp_require_tls: true
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'test-mails'
receivers:
- name: 'test-mails'
email_configs:
- to: '[email protected]'
rule.yml檔內容如下
groups:
- name: example
rules:
# Alert for any instance that is unreachable for >5 minutes.
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
serverity: page
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
然後就可以執行docker-compose命令去生成容器,範例如下
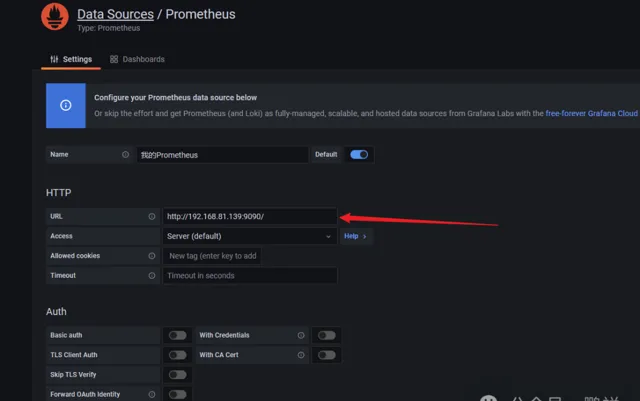
然後存取Ip地址加埠存取頁面,比如http://192.168.81.139:9090/
開啟這個界面就說明安裝好了,這個時候我們看下 http://192.168.81.139:9090/targets?search= 頁面
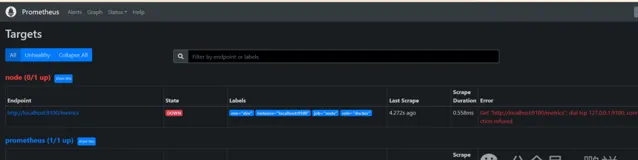
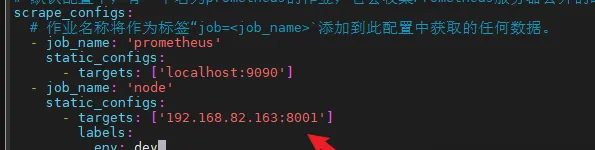
這個node報錯是因為這個地址是無效了,那麽修改為真是.NetCore的服務地址,修改配置檔然後重新啟動
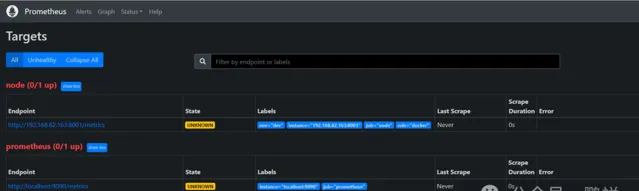
重新開機後界面顯示如下
安裝Granfana
這裏直接使用docker來安裝grafana
sudo docker run --name grafana -d -p 8000:3000 grafana/grafana
然後存取地址 ip+ 8000,預設帳號密碼為admin/admin
添加資料來源
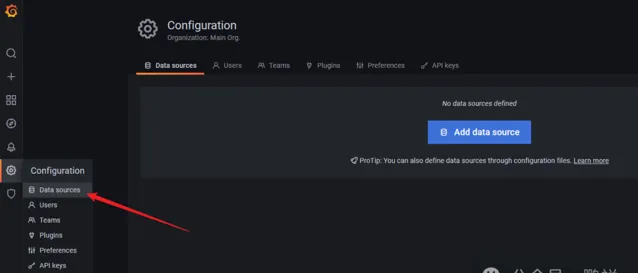
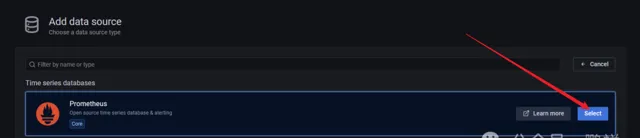
填寫prometheus地址
匯入儀表盤
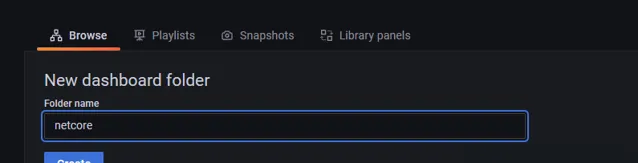
建立資料夾用來存放我們原生的要匯入的檔

想要在Grafana中進行數據的展示,需要匯入dashborards樣版,本文的樣版我是從微軟倉庫找到的,地址為:https://github.com/dotnet/aspire/tree/main/src/Grafana
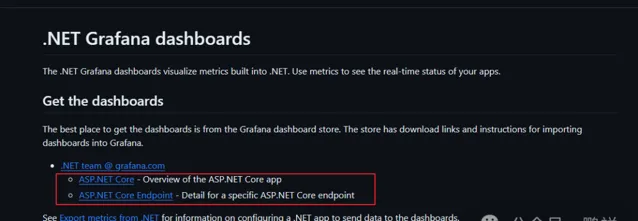
分別點進去下載這兩個儀表盤對應的的json檔即可,也可以去我common-docker-yaml倉庫中下載
然後匯入json檔
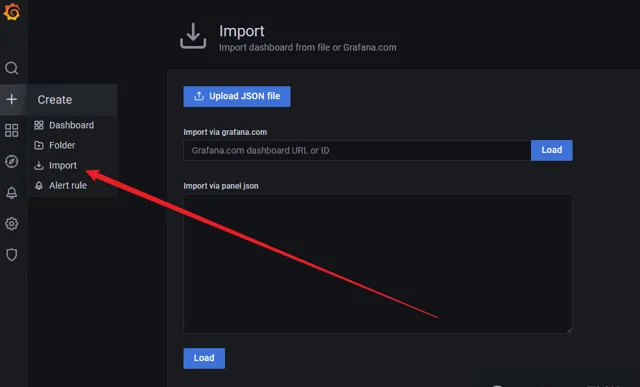
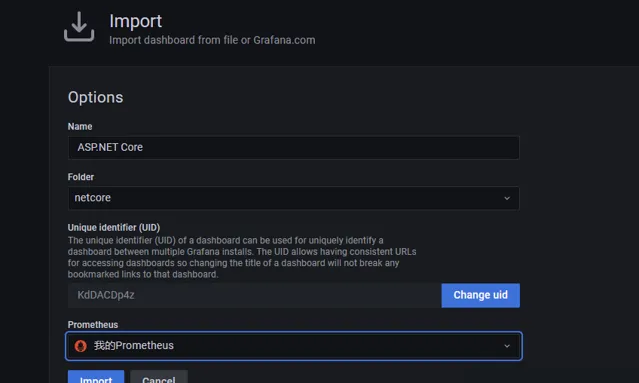
匯入aspnetcore.json檔,並選擇我們的netcore資料夾以及選擇剛剛我們建立的Prometheus資料來源
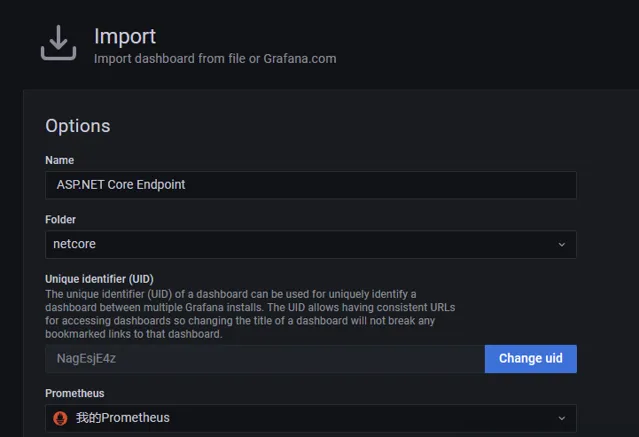
匯入aspnetcore-endpoint.json檔
這個時候我們就看到了好看的儀表盤
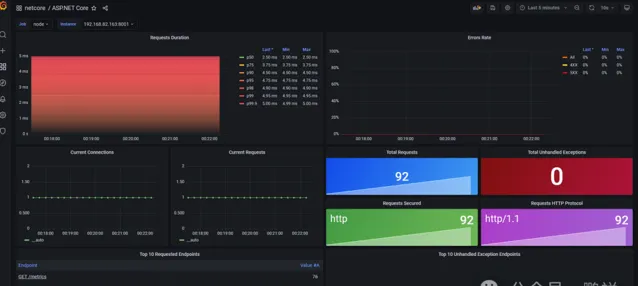
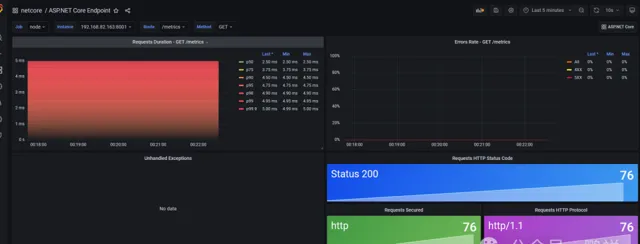
當我點選介面讓其報錯,那麽就顯示到界面上
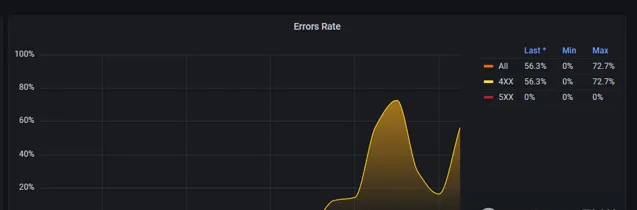
如果需要監控其他內容,也可以模仿著進行修改。











