本文根據徐新龍老師在 〖 2023 中國數據智慧管理峰會-上海站 〗現場演講內容整理而成 。 ( 文末有PPT獲取方式,不要錯過)

講師介紹
徐新龍, 螞蟻集團AIOps技術專家, 在螞蟻基礎設施團隊從事關於SLO的健康度體系建設,以及異常檢測、故障定位、預案推薦等場景下的AIOps實踐; 曾就職於攜程技術保障中心SRE專家崗,負責AIOps的實踐探索和落地,以及多個AIOps產品的設計研發 。
分享概要
一、SLO介紹——為什麽需要SLO
二、SLO健康度——從0到1構建SLO
三、AIOps賦能——SLO和智慧化結合
四、案例介紹——實踐場景和營運探索
五、總結
精細化運維是運維演進的必由之路,是綜合業務需求、研發效能、穩定性保障、成本最佳化、架構治理等多種因素驅動的必然結果。為了實作精細化運維,首先要完成運維的數位化轉型,管理學大師[美] 彼得.德魯克說過,If you can't measure it, you can't manage it。在實踐中,我們存在大量的運維數據,如何讓這些數據充分發揮價值、形成對企業有用的資產,是我們探索和實踐的主要方向之一。
本文的分享主要圍繞SLO體系建設展開,在相對標準、統一的框架下指導和推動服務品質的數位化建設,結合具體的運維場景和背景,沈澱對組織有價值的數據資產和流程規範。同分時享了一些SLO運維實踐案例供大家參考,希望有所啟發和收獲。
一、SLO介紹——為什麽需要SLO
在展開SLO(Service Level Objective)介紹之前,我們先從一個熟悉的運維場景出發,希望透過具體的案例可以讓大家快速代入。
值班處理故障,是大多數SRE和運維工程師的日常。在螞蟻,基礎設施負責的K8S,提供面向集團所有二方系統的算力交付,SRE的職責之一就是保障交付品質和穩定性。好幾年前的某天,我們在Pod交付的使用者群接到報障,反饋的現象是二方系統無法建立Pod資源或是交付時好時壞,接收到使用者側報障之後,值班SRE就展開了一些列的問題排查,這是一個典型的故障驅動型的問題發現。
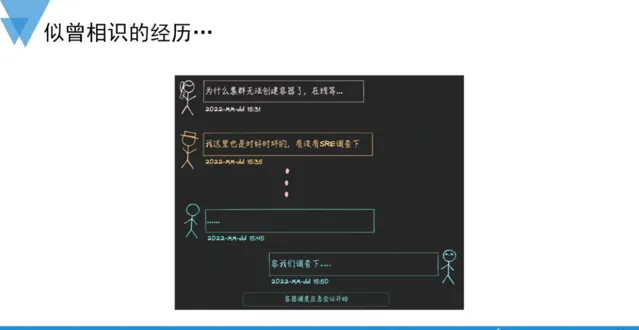
眾所周知,K8S是一套非常復雜的系統,由眾多的元件協同來異步完成資源交付。簡單概述下排查的思路,因為使用者報障現象是交付失敗時有發生,並非完全不可用,所以最先懷疑的方向是請求容量是否有激增,導致排程任務積壓,透過監控檢視佇列也確實如此,為了避免任務重試導致佇列進一步積壓,執行了一些列的降級操作,隨著時間的推移,故障有所緩解,但並沒有得到徹底修復。直到第二天,透過變更排查,定位到排程器的規格大小被做了limit限制,這意味著排程器元件將無法像之前一樣「貪婪」地使用到宿主機的空閑資源,進而導致處理能力受限。
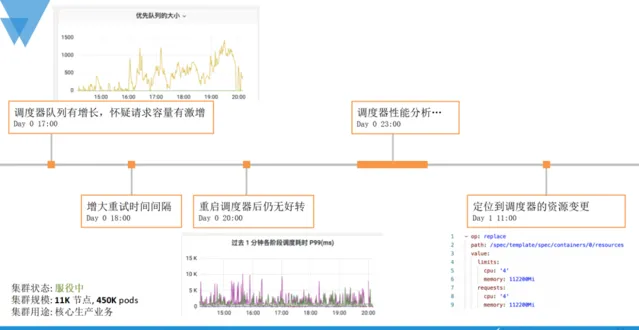
簡單復盤這次故障的時間線,排程器在5天前被限制了規格大小,導致排程任務佇列逐漸積壓、耗時增加,之後的Pod交付成功率受到影響並產生告警,透過一些列降級手段進行幹預,有所好轉但實際並未根治。終於在排程器「帶病」工作5天後,接收到了來自使用者側的報障。
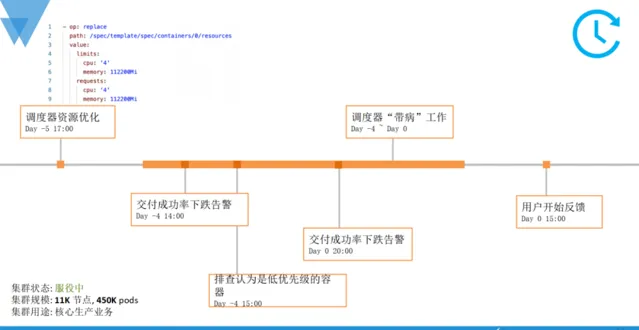
針對上述提到的這個「不完美」案例,相信大家可以提 出一些列的改進建議和措施。 然而,我們重點想要討論的並不是具體的方案,而是一種架構治理和營運的模式,如前文提到的,這是一個典型的故障驅動型的事件。 日常中,變更往往是導致故障最根本、最直接的根因,在經典的故障驅動治理模式下,為了避免故障和錯誤,在實施變更前後,一般會包括事前的變更管控、風險左移,事中的應急流程,以及事後的監控覆蓋等步驟。 在程序導向的資源交付場景下,這個套機制沒有任何問題。
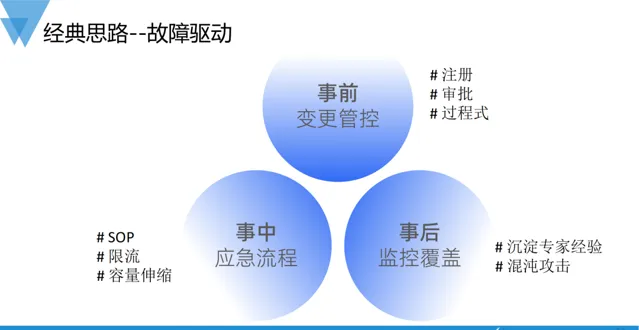
但是,在以K8S為代表的雲原生交付體系下,面向終態的聲明式操作逐步替代了早期的程序導向式的運維模式,經典的故障驅動型治理模式,逐漸暴露出了一些問題,強調是否產生故障或事件大過服務品質本身。隨著運維精細化的演進和架構治理需要,我們需要一種貼合雲原生、更普適和體系化的模式來驅動日常運維。
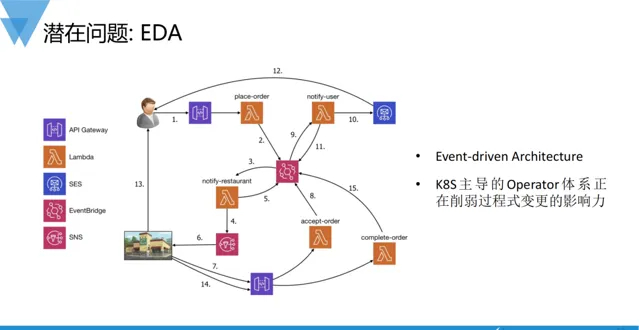
同時,圍繞雲原生的 套用生態已然成為了當下最主流的交付模式,企業上雲也是快速開展業務和節約成本的最佳選擇。 企業上雲之後可以不用關心底層的網路結構、計算資源、儲存、中介軟體、負載均衡等技術細節和實作,只要專註於業務邏輯的研發即可。 顯然,上雲提效的同時也失去了對於底層基礎設施能力的掌控力。 基礎設施能力不透明、雲廠商操作不可見,對於上層業務系統的穩定性都是巨大的風險隱患。 因此,雲服務品質的公開、透明化是企業選擇上雲與否以及選 擇哪家雲廠商重要考量因素之一。

另外,組織協調也需要共同的目標。 在套用生命周期的不同階段,會存在不同的角色分工,比如研發負責套用的功能開發和效能最佳化、SRE保障套用執行的穩定性和安全等,跨團隊協同需要有一致的共建目標來驅動套用架構的叠代和演進。因此,我們需要一種有效、可量化的機制對齊和牽引不同團隊間的合作。特別的,SRE需要及時將軟體缺陷和系統風險同步到研發側,確保系統執行期間的高可用性。故障驅動型的營運模式下,透過故障復盤來組織協同是常見的形式,主要問題是存在滯後性。如何主動提前辨識到服務異常、系統風險是穩定性建設的核心訴求之一。
透過前面的案例和背景介紹,相信大家已經很清楚我們接下來要介紹的內容了。在實踐探索中,我們透過建設SLO體系有效地解決了上述提到的問題,為精細化運維提供了的有力數據支撐和數據資產建設規範。借助SLO數據,針對不同的運維場景抽象、建設和組合相關的能力,讓SLO體系實踐落地具備普適性和可借鑒意義。
接下來我們介紹下圍繞SLO的幾個關鍵概念:
SLI(Service Level Indicator)
系統具備可觀測性是構建SLO的前提,系統需要具備一個或多個監控指標來反應某些維度上的服務能力,將服務水平跟觀測指標繫結。SLI(Service Level Indicator)的選擇和指定主要取決於服務哪些維度的能力需要被觀測到,以及現有的監控指標和手段是能夠否覆蓋到,亦或是需要設計開發侵入性的程式碼邏輯來實作。簡言之,SLI提供了服務水平的可觀測性。
SLO(Service Level Objective)
SLI提供了套用或系統服務能力和服務水平的可觀測性,SLO是針對其量化結果設定的目標,用以承諾和管理使用者對服務水平的預期。這種對預期的聲明式公開透明的、確定的,對於服務的不同消費端是一致的、無差別的。同時,SLO的結果可以用來通曬,對齊多方對於服務水平胡服務能力的認知和共識,以此改善使用者間的溝通。此外,還可以利用SLO的結果平衡研發效率和系統穩定性,當SLO不達標時,反映出穩定性受到挑戰,則需要放緩研發效率,投入更多的精力在穩定性建設上。
以系統可用性SLO為例,當伺服端承諾月度SLO為99.9%時,說明系統在以月為統計視窗的時間片結算時,其不可用時長不能超過43分鐘,超過則認為當月服務品質不達標。顯然,可用性目標設定地越高,意味著可接受的宕機或不可用時長更短。為了達成更高的目標,往往需要付出更多的投入和努力。
SLA(Service Level Agreement)
SLA(Service Level Agreement)的制定,是為了約束和監督服務方對於SLO承諾的履行結果,包括針對SLO執行不達標的懲罰和補償說明。比如,所有雲服務廠商都會對其銷售的服務出具SLA,主要包括服務介紹、度量服務品質使用的SLI、對客承諾的SLO、以及結算不達標時的補償方案等內容。
以AWS(Amazon Web Service)上的雲伺服器ECS(Elastic Compute Service)為例,該服務的SLA協定中明確指出了一旦服務水平不達標之後,在費用上會給出何種優惠措施,優惠的粒度會依據SLO不達標的程度區分出不同的檔位,並且當SLO破線到一定閾值後,將返還購買該服務的所有費用。
根據前面的介紹可以看出,SLO體系之所以可以運轉的核心驅動力來自於SLA。但是針對內部的套用和服務,我們不能像雲服務一樣,透過成本價格約束SLO的執行情況,因此需要尋找一種等價約束力來驅動SLO營運成了關鍵問題。實踐中,我們會將不達標的SLO結算成不同等級的技術風險事件,透過穩定性相關的例會透出通曬和治理。
域內公示SLA也是我們營運的重要環節,如下是一份SLA公示模版。透過SLA公示將服務等級公開透明地傳遞給消費端,以此對齊消費端預期。公示審批的過程中,促成上下遊服務之間握手、達成共識,打造SLO驅動的技術氛圍和文化。
實踐SLO,概括下就是 在相對標準、統一的框架下指導和推動服務品質的數位化建設,形成對組織有價值的數據資產和流程規範 。借用在人工智慧和機器學習領域的觀點,演算法的上限受限於數據品質的好壞,所以從源頭上建設高品質的數據非常重要。
對比傳統的基於Metric的明細監控,SLO健康度體系的構建更加聚焦服務核心的能力和品質。一般地,SLO的制定需要業務方、研發和SRE共同約定協商,然後由SRE主導產出度量指標。因為SLO設計之初只關註套用或系統向外輸出的服務能力和服務水平,天然遮蔽掉了大量細粒度的告警幹擾,值班人員只要關註各自運維系統的SLO告警即可。透過踐行SLO健康度體系,套用或系統的服務能力和服務水平得到了更好的度量和數位化,避免了傳統基於metric監控中的大多數問題。同時,在參與建設SLO過程中,SRE可以進一步了解和剖析系統,這樣也提高了SRE對於系統的掌控力。
二、SLO健康度——從0到1構建SLO
和大多互聯網企業一樣,螞蟻的基礎設施側存在眾多的異構系統,被上層的業務套用和服務所依賴。考慮到不同系統的技術棧、架構、部署等因素,我們需要找到一種通用的、泛化性強的數位化方案指導和構建基礎設施域內的健康度體系。基於這樣的客觀現狀,我們開啟了螞蟻基礎設施域內從0到1的SLO健康度體系建設和實踐。
系統架構
基於SLO的健康度體系具備很多優勢,然而所有的提升都是需要代價的,在建設SLO過程當中也需要更多地投入,這也意味著我們邁進了精細化運維的階段。從整體上看,我們把SLO的健康度體系分成了4層結構: 最下層是目標系統的執行層,是提供服務的物件實體,包括基礎設施域內所有提供服務的套用和系統;其上是SLO的數據層,數據層包括SLI數據收集、SLO數據加工、數據展示、SLO後設資料建模、數據清洗、以及常見分析的數據抽取等;再之上是基於SLO數據的場景分析處理能力層,包括基於場景的更高級的數據分析能力、異常檢測、故障發現、故障定位、預案關聯、以及相關產品建設等能力;最上層則是基於場景能力劃分的套用層,用於數據通曬的SLO健康度大盤、健康度應急流水線、輔助計價和成本分攤等套用,賦能到品質、效率、穩定性、成本等具體場景中去。
數據加工
實踐之初,我們主要是基於GitOps和Prometheus來構建SLO健康度體系。透過Git管理SLO相關的定義和後設資料,以Yaml的形式推播到部署在K8S集群的Prometheus上,Prometheus會按照Yaml中定義的規則抓取、計算和儲存目標系統的SLO數據,結合Grafana實作SLO數據的透視和視覺化。同時,基於Prometheus上配置的Recording rules可以實作基於SLO的告警能力,再結合電話、信件、釘釘等渠道完成告警通知。另外,利用Prometheus的SLO告警和時序數據,我們實作了故障發生時的異常檢測、定位和下鉆能力,再加上故障管理過程中沈澱的歷史專家經驗數據,針對部份運維場景實作了基於故障定位結果的預案推薦,打造了基於SLO健康度數據的一站式應急解決方案。
Recording rules
具體地,利用Prometheus計算生成SLO數據,只需要簡單掌握常用的PromQL(Prometheus Query Language)並編寫相應的Recording rules,透過Git程式碼倉庫維護管理SLO後設資料的版本及分支,再透過ArgoCD將對應的Recording rules配置推播到Prometheus並多載即可生效。
時序模型
為了更好的利用SLO數據,我們簡單介紹下Prometheus中的數據模型。Prometheus屬於單值數據模型的時間序列資料庫,監控數控是由時間戳、監控數值及標簽組構成。
同時,Prometheus還支持了非常豐富的OLAP操作以便於對時序數據進行鉆取和透視。另外,Prometheus提供了UI Explore功能,對PromQL提取到的時間序列數據做簡單視覺化。從純數據合成的視角,SLO序列是對空間維度和時間粒度更宏觀的聚合:空間(數據橫截面)上,聚合掉標簽維度資訊,只關註整體;時間尺度上,以天、周、月、季度等分辨率統計和計算,從而形成了無標簽或低標簽維度的時間序列數據。如之前所提到的,SLO關註的是統計視窗內套用或系統整體的服務能力和水平、是宏觀健康度的反映和度量,比如政府報告中不會羅列出每個具體區域的GDP明細,而是匯總成宏觀經濟指標對外公布。
SLF
為了擴充套件SLO在具體的運維場景中的套用,使得依賴相關性定位變得更加通用(將在第三部份介紹),結合SLO後設資料,我們定義了一些擴充套件概念。
Prometheus的數據模型,一條SLO數據是由時間戳、監控數值和眾多的維度標簽構成,每一組標簽代表了該條數據的歸屬,即將該條SLO數據可被分解的方向,於是我們引入了 服務水平影響因子 (Service Level Factor,SLF)。在構建SLO數據的過程中,我們將可能會影響到服務水平的維度註入到SLO數據中,以便在SLO序列預警的時候,遵循相關的維度對異常進行下鉆,從而定位出故障資訊。
SLD
受限於單條SLO數據所能攜帶的維度資訊量有限,以及維度資訊過多會導致異常下鉆時需要遍歷地笛卡爾積空間過大,會導致大量的算力消耗,以至於影響定位效率。針對這些問題,在SLF基礎上,我們又拓展了 服務水平依賴 (Service Level Dependencies, SLD),將相關的SLO數據集或監控集作為某一個SLO的依賴項,用來構建可能的故障傳播路徑。在依賴相關性定位時,不同的SLO或監控指標之間可以透過共同的維度傳遞下鉆資訊,以此挖掘出潛藏在上下遊系統中更多的異常資訊。
錯誤預算
和傳統的直接設定固定閾值預警不同,利用SLO序列發現異常時,我們引入了錯誤預算的概念(Error Budget)。客觀地,套用或系統發生錯誤在所難免,因為上下遊的依賴異常、網路異常、儲存異常、執行時異常、以及配置變更導致的錯誤,都可能導致套用或系統不可用。SLO本質是對服務品質(成功率、可用時間等SLI)的預期管理,反過來對錯誤做預算管理,也可以起到等價的效果。例如某個套用成功率的月度SLO設定為99.9%,則這個月總的錯誤預算就可以表示為(1-0.999)*月度總請求量。為了SLO能夠達標,必須合理地支配和消耗錯誤預算,一般地,我們把這個過程又稱作錯誤燃燒。
錯誤預算告警
盡管引入了SLO錯誤預算作為故障預警方案,實踐中還是會支持像固定閾值這樣的簡單告警方法,針對不同套用場景靈活地選取適合的解決方案。接下來我們按照由易到難、由簡到繁的次序介紹下SLO預警的常見方案。因為SLO序列大都由長時間視窗統計計算而來,在靈敏度上不容發現故障,故而可以采用較短的時間視窗計算錯誤占比,一旦錯誤率超過了固定閾值,則發出告警通知。實作容易、解釋簡單,不依賴歷史數據。對於成功率型別SLO序列,月度目標設定為SLOm、短視窗錯誤率告警閾值設定為1-SLOm時,如果當月不發生告警,則SLO必然達標。
錯誤預算+燃燒速率告警
燃燒率(Burn Rate)是指將總的錯誤預算均勻地分配到告警視窗中的系數。比如月度SLO剛好達標時,將錯誤預算剛好消耗殆盡的燃燒系數定義為1,故當燃燒率為2時,錯誤預算會在月中被消耗完,然後SLO破線不達標。基於這些概念,我們就可以用公式簡單推匯出觸發告警所需要的時間,即告警靈敏度。同時,我們也可以大致估計出,告警觸發時消耗了總錯誤預算的比例。
利用錯誤預算和燃燒率,在告警發生時,我們可以大致推算出本次告警對SLO的威脅,因此設定不同的燃燒速率,可以有效預估告警的嚴重程度。
根據不同燃燒速率的SLO預警指定告警程度,再為不同級別的告警配置不同的通知渠道和接收人。同時可以結合精度不同的告警視窗,設定更加靈活的多消耗速率告警,既保證了告警發現的時間分辨率和敏感度,也能保持良好的召回和準確率。當然,該預警方案的缺點也非常明顯,需要設定多個視窗和不同燃燒速率對應的告警參數,使得告警設定變得略有難度,如何解此問題將在下一章內容中展開介紹。盡管如此,當所有參數設定得當,該方案依然是最佳選擇。基於SLO錯誤預算預警的方案,最大的優勢在於告警發生時,我們可以近似地預估一次告警對於SLO能否達標的影響程度。
透過SLO預警機制,SRE的註意力更多地聚焦在了服務能力和服務水平之上,從疲於應對的單機告警泥淖和深淵中解放出來。在SLO健康度體系下,伺服端和客戶端基於服務水平胡服務能力對齊共識,利用SLO數據做橫向通曬,針對高優先級別的SLO告警進行故障復盤,根據復盤內容沈澱專家經驗和構建應急知識庫。如此迴圈,透過SLO驅動,套用或系統不斷地持續叠代和打磨,服務品質也會顯著得到提升。
三、AIOps賦能——SLO和智慧化結合
在SLO健康度體系建設中,存在眾多基於經驗或者規則的設定。例如對套用或系統的月度成功率SLO約定,設定多少認為是合理呢,99%還是99.9%?又如,利用錯誤預算和燃燒速率設定SLO預警的前提假設是可以把錯誤量均勻地分攤在時間維度上,然而對於朝夕錯誤量存在顯著差異的場景下,該方案是否依舊有效?SLO預警方面是否可以進一步提效?如何將故障定位和SLO告警結合在一起?SLO預警的設定需要相對專業的知識,如何利用演算法降低使用門檻等等。另外,我們希望借助AIOps的能力,在故障應急方面,將SLO健康度體系打造成完整的一站式應急解決方案,賦能到基礎設施域內眾多的運維場景。

AIOps
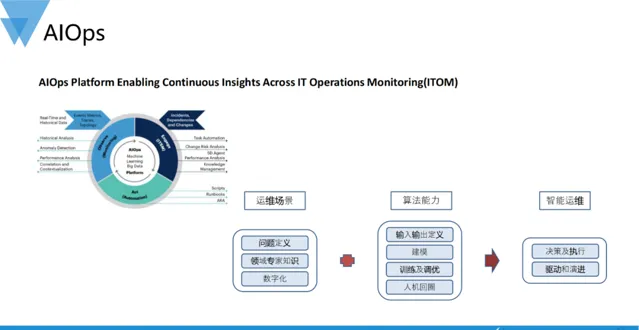
AIOps(Artificial Intelligence for IT Operations,智慧運維)將人工智慧的能力與運維相結合,透過機器學習的方法提升運維效率。AIOps屬於跨領域結合的能力,需要能夠理解運維場景、運用機器學習演算法、構建一定的工程能力對運維數據進行分析、處理和加工,以此解決或最佳化傳統運維中存在的難題。
經過多年不斷地實踐總結,我們更願意把AIOps實踐稱之為一種範式,即透過結合運維場景和演算法能力產出 可以支撐運維決策和驅動架構演進的智慧 。
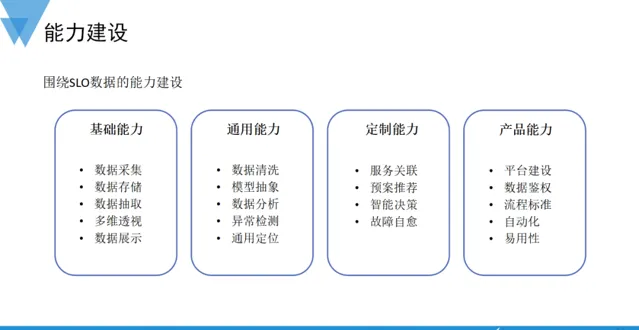
AIOps賦能SLO,提高了SLO健康度體系在套用場景中的泛化能力和普適性。實踐中,圍繞SLO健康度體系在故障應急場景下的梳理和抽象,涉及到的能力可以劃分為:基礎能力、通用能力、客製能力和產品能力。基礎能力主要圍繞數據面建設鋪開;產品能力關註的是使用者接入並使用SLO健康度體系時的費力度和易用性,以及透過自動化來提升效率。結合AIOps相關的能力主要體現在通用能力和客製能力建設兩個方面,包括對數據的深度挖掘、透視、和下鉆等處理,針對分析得到的結果,結合歷史沈澱的專家經驗以及相關的運維自動化能力,努力逼近無人值守的運維終極理想。
數據分析
SLO序列本質屬於時間序列數據,針對時間序列數據的分析方法,一般分為時間域分析和頻率域分析。常見的統計演算法、回歸演算法、神經網路等,都屬於時間域分析;頻率域主要借助傅立葉變化、小波變換等手段,將時間域數據對映到頻率域進行譜成分分析。
所謂合抱之木,生於毫末。再復雜的演算法也是由簡單的運算和統計規則組合而來,所以掌握基礎的分析方法和原理對於理解復雜演算法具有顯著幫助。具體的,我們羅列了一些常用的數據分析方法。透過均值、眾數、以及不同刻度的分位數可以反映出數據集的居中程度;變異數、極差、以及四分位差(切邊極差)反映了數據集的離散程度;回歸模型、時間序列模型、以及神經網路模型可以分析提取時間序列的趨勢、季節指數等特征,並用作未來數據的預測;利用傅氏變換、小波變換、序列分解等手段可以檢測出時間序列中隱藏的周期和規律性。

目標值推薦
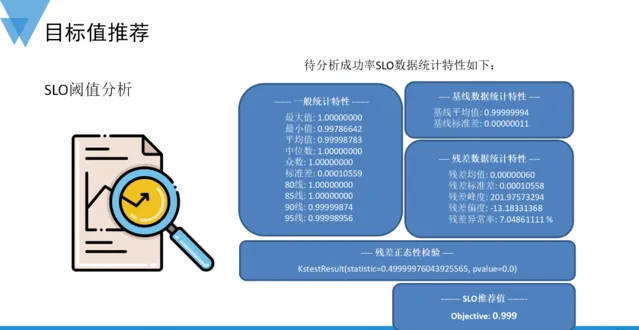
構建SLO健康度過程中一個重要的環節就是設定套用或系統的SLO,當SLO設定過低時,目標輕松完成並達標,失去了挑戰性,同時也不能有效發現和改進最佳化系統;當SLO制定過高時,又會造成SLO到期不達標,根據SLA中的約定,執行相應的懲罰機制。所以,如何設定一個合理又富有挑戰性的SLO目標值,對於系統的持續演進和叠代至關重要。一般地,經驗豐富的專家一開始就可能設定出比較合理的目標值,然而對於新手或者大多數普通使用者來說,需要花費大量的時間嘗試探索,才能確定出合適的SLO目標值。
針對這個痛點,結合歷史數據設計演算法自動分析,為每一個套用或系統,計算出其合理的SLO推薦值。其中關鍵的步驟包括:針對月度成功率SLO數據,對其過往的一個月數據分析一般的統計特性;透過回歸模型計算SLO時序的基線水平胡基線的波動程度;利用基線計算出殘留誤差序列,然後分析殘留誤差序列的分布特性,按照其分布特性進行正態性檢驗,以確保模型的正確性。綜合以上步驟的輸出,設計演算法進行數據融合,最終給出SLO的推薦值。
一般地,對於演算法推薦的SLO目標值,最終還是需要業務方、SRE以及研發共同確認後才可生效,根據實際情況,後續也可以加以適當調整。事實上,套用和系統時刻處在不斷演進變化的過程中,因而SLO的目標值也會因為業務需要定期或非週期性地加以調整。
異常檢測
異常檢測是AIOps實踐中提及最普遍的能力,無論是學術界還是工業界都有很多相關的文獻和實踐介紹。之所以被廣泛地實踐和研究,主要在於其豐富的套用場景和業務需求。從統計視角,異常檢測是透過統計學原理發現存在樣本集中的離群點或野值。抽象地解釋,異常檢測過程可以視為將實際觀測和預期目標之間的差異和判定閾值做比對,如果差異超出了預期的閾值,則辨識為異常,反之,則視為正常。從這個意義出發,我們可以將異常檢測描述成兩個核心問題:即, 預測 和 檢驗 。
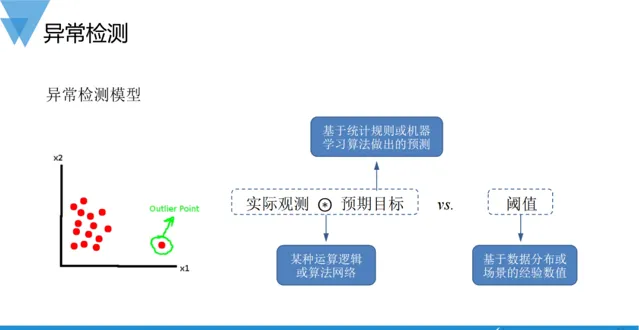
基於統計原理的 異常檢驗 演算法,一般需要對樣本集(殘留誤差時間序列)的分布做出假設或定義,構建統計量,然後根據假設檢驗原理,在一定的顯著性水平下,拒絕原假設或者接受備擇假設。常見的異常判斷準則主要包括:依拉達準則(又稱為3 sigma準則,在標準正太分布的數據集中,+/-3sigma的區間可以包含99.7%的分布)、箱體圖法(上下四分位刻度結合極差構成,同樣,在標準正太分布的數據集中,該區間可以包含99.5%的分布)、Tukey檢驗、格魯布斯檢驗法、迪克遜檢驗法、以及t檢驗等方法。判斷數據異常與否的關鍵,在工業場景中主要還是依照經驗值,比如假設檢驗中的顯著性水平,亦或是借助大數定理,指定異常數據分布的機率等。

時間序列預測
時序的預測問題 可以理解為 基於t時刻之前的數據 來預測t+1時刻或者未來一段時間的 趨勢 。
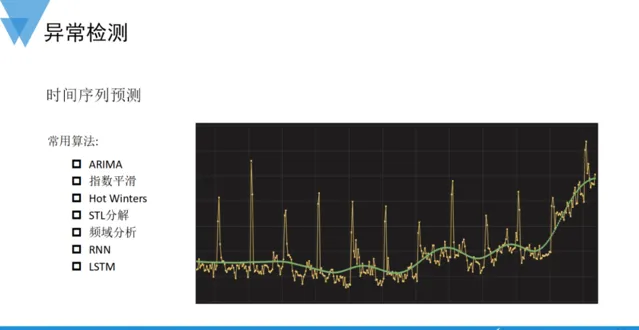
一般在 弱平穩性 假定下,對時間序列分析和預測的常見演算法,主要是我們羅列的這些種類。 預測的本質是希望從歷史數據中提取出規律性和確定性,以此來做數據外推和預期管理 。
在弱平穩性的假定下,對時間序列分析和預測的常見演算法有差分整合移動平均自回歸模型(ARIMA)、指數平滑(EMA)、三次指數平滑(Hot Winters)、基於局部加權回歸的季節趨勢時序分解(STL)、時頻變換分析、以及基於人工神經網路原理的迴圈神經網路(RNN)和長短期記憶網路(LSTM)。預測的本質是希望從歷史數據中提取出規律性和確定性,以此來做數據外推和預期管理。AIOps實踐中,圍繞成本、品質、效率、穩定性等眾多場景都需要具備相應的預測能力。
預測+檢測模式解決了大部份場景下的異常辨識問題,在實踐中具有非常出色的泛化能力和檢驗效果。然而,開展異常檢測過程中,也是存在諸多問題和挑戰。例如,如何利用異常數據定義異常的程度,1變化到10的異常度和100變化到150的異常程度,前者更加顯著還是後者更加顯著?很多時候都是取決於業務場景。再比如,從數據角度檢驗出的異常未必是業務側需要感知到的告警,異常和告警之間如何轉換,是需要基於實際場景來分析和定義。同時,通用的異常檢演算法,大多未考慮具體場景和專家經驗,效果上不如客製化的檢測演算法,而客製化的演算法受限於場景和領域知識的捆綁,其外推和泛化能力比較薄弱。另外,如何有效地異常檢測的結果進行采集和評價,以及利用這些反饋數據實作人機回圈的閉環,實踐場景中,也是極具挑戰性的難題。

故障定位
除異常檢測外,故障定位也是AIOps實踐的一個重要方向。套用或系統故障在所難免,如何在預警發生之後快速地定位出故障域和故障根因是後續采取止損措施的關鍵,其重要性不言而喻。從相對通用的定位思路出發,我們將故障定位歸類為: 時間相關性定位、依賴相關性定位、空間相關性定位 和 歷史相關性定位 。
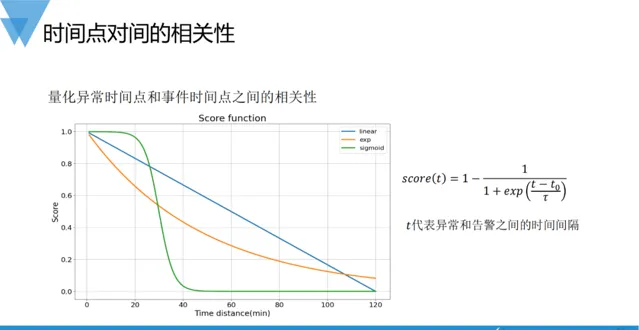
時間相關性定位關註的重點在於兩個或多個事件發生的時間點是否相近和匹配。為了考慮通用性,一般將多個事件(告警事件和運維變更事件等)同時量化為時間序列數據,計算皮爾遜相關系數矩陣(近似理解為歸一化的共變異數矩陣),因其歸一化的結果,非常適合相關性打分。根據場景和專家經驗設定閾值,即可判斷多個事件在發生時間上的匹配程度。這種方法也可以檢驗不同時序形態上的相似程度,前提是需要序列長度和時間點對齊。另外,動態時間規整(Dynamic Time Wraping,DTW)方法也可以計算兩個時序之間的相似程度,雖然沒有對序列長度和時間點對齊的要求,但其結果一般不能歸一化,適合做候選結果的排序。
時間相關性
用來檢驗不同時序形狀上的相似程度,一般是需要序列長度和時間點對齊,主要使用皮爾遜相關系數計算,因為計算結果的歸一化特點,非常適合做關聯打分,另外余弦距離也可以是備選的策略。

依賴相關性
依賴相關性定位 側重點在於定位故障鏈上的傳導。復雜系統通常是由數個子模組或依賴組成,往往牽一發而動全身。所以依賴相關性定位需要能夠提前梳理好系統的上下遊依賴、系統的拓撲結構等知識。例如,Kubernetes作為雲原生的事實標準,其復雜程度可見一斑,在如此復雜的系統中想要夠快速定位出故障根因,必須弄清楚不同元件之間的呼叫關系和依賴。一旦系統發生預警,順著故障可能傳播的路徑就可以相對容易地定位出問題的根源。
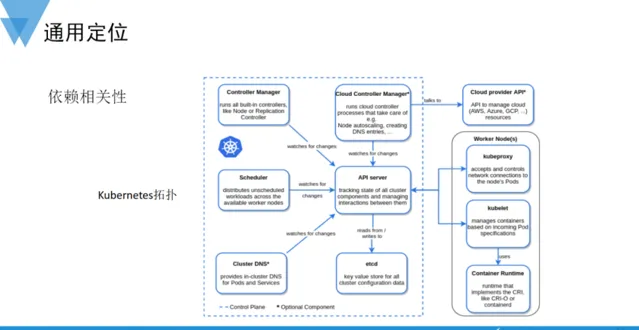
如前面提過的SLD,透過SLF維度擴充套件,將相關的SLO組合成拓撲依賴關系圖,透過故障維度傳導定位出故障域。
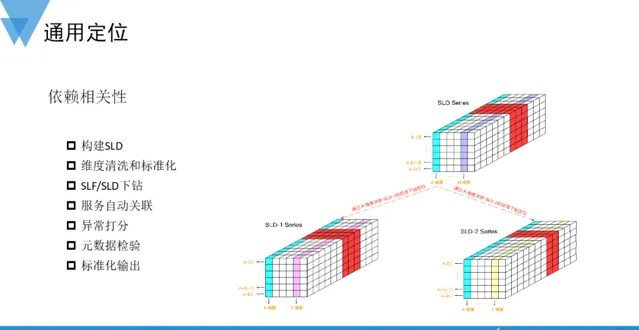
為了清楚起見,我們展示了基於SLD做故障依賴相關性定位的一份配置片段。在工程實作上,由於SLO數據模型的標準化構建,結合專家經驗的梳理,相應的定位配置也非常容易生成,其中dependencies欄位描述了該SLO依賴的所有服務和監控指標。

空間相關性
空間相關性定位 更多的是從物理拓撲的視角挖掘故障域資訊。需要利用套用或系統的後設資料描述故障定位時的下鉆方向,這些資產數據一般被定義在CMDB或PaaS中,例如機房資訊、機櫃機架編排資訊、網路裝置和布線資訊、物理伺服器和網卡資訊,再到具體套用或系統部署資訊等。為了更加高效地使用這些資產拓撲資訊,在做故障定位時,一般將這些資訊儲存在圖數據中,借助圖演算法的多樣化查詢檢索能力,快速關聯聚合故障實體,以此確定故障域。
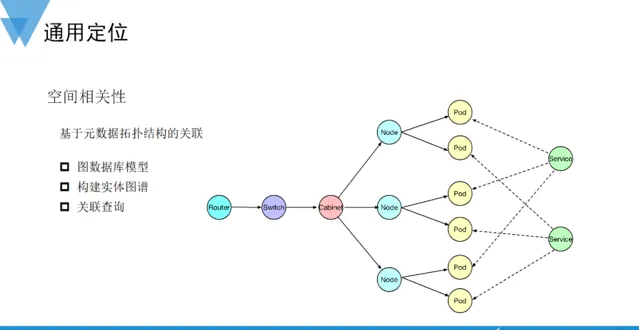
歷史相關性
歷史相關性定位 基於對以往的故障數據提煉加工、構建故障知識庫,透過異常特征匹配和檢索找到故障根因。構建故障知識庫是一個精細又漫長的過程,需要垂直領域的專家經驗沈澱,將歷史的故障資訊和原因歸類梳理,形成故障手冊,演算法側需要將對應故障手冊的經驗數據抽象和建模,透過特征工程構建知識庫。透過歷史相關性實施故障定位,本質上屬於機率推理,即貝葉斯原理,基於歷史數據計算的先驗機率(比如,某類運維操作下發生故障的頻次等),求解最大化後驗機率的條件。這種方案的難點主要在於樣本數據(覆蓋比較齊全的故障數據)的收集需要很長的時間,以及需要非常專業的領域知識梳理。

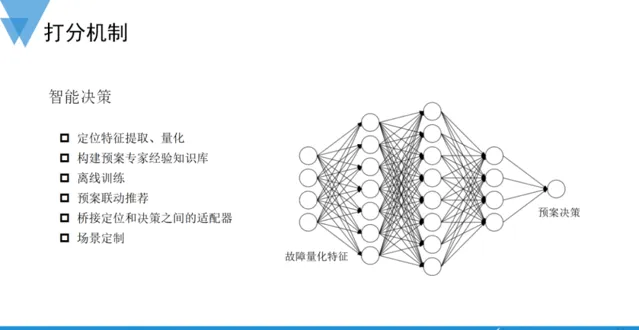
智慧決策
AIOps的願景是希望借助人工智慧技術,最終實作運維場景下的無人值守。在運維應急場景中,故障的自動發現、定位,需要能夠為決策提供足夠充分的輸入,以便系統決策采用何種預案執行快速止損。為了實作故障自愈,運維需要具備相當高的自動化水平,這些自動化能力需要專業領域的知識來構建,因而故障自愈可以理解為垂直領域的AIOps實踐。自愈的關鍵在於 智慧決策 ,基於定位輸出的故障域和根因資訊,結合專家經驗和離線訓練模型,索引到分數最高的恢復預案。實踐中,需要在通用定位結果和預案索引之間客製化很多的場景適配邏輯,模型抽象的好壞決定了方案的泛化能力。
在AIOps實踐中,像異常檢測、故障定位等場景中,為了使得其結果具備可比較性,需要將不同尺度的數據做歸一化變換,這種歸一化的處理,我們可以理解成一種打分機制。前面我們提到的皮爾遜相關系數可以用作兩個時序相關性打分,除此外還有余弦相關系數、Jaccord距離等方法,因為其歸一化的輸出,皆可被用來做相關性打分。特別地,在故障定位中,我們經常需要為異常發生的時間點和某個運維操作事件的關聯性打分,以時間間隔作為自變量,設計經驗函式,比如隨著時間間隔地增加,分數線性遞減、指數遞減、或開關式遞減等。具體使用何種方法,還是得依據實際場景確定,例如在大多數情況下,我們會選用類似Sigmoid函式的柔性開關式打分方案。
在介紹異常檢測的時候我們提到過,在不同場景下,橫向對比異常程度是一個比較難的問題,因為可能涉及到業務的敏感性,所以很難給出通用的量化方案。實踐中,一種可行的方案是結合異常數據的絕對量和相對量進行異常打分,也能取得不錯的效果。另外,在對多維度打分結果做數據融合時,可以采用調和平均分數據綜合。透過將尺度不一的數據對映到相同的尺度下,結合經驗規則或閾值,顯著提高了相關演算法的適應力和泛化能力。
四、案例介紹——實踐場景和探索
前面兩章主要介紹了關於SLO健康度體系建設和AIOps相關的解決方案,本章會重點分享下螞蟻基礎設施團隊圍繞SLO健康度體系展開的一些實踐和探索案例。其中,最主要的探索實踐在於,圍繞SLO健康度打造出一條應急流水線,將「散裝」的AIOps能力(異常發現、故障定位、智慧決策、自愈等)串起來,提供了一站式的應急解決方案和指導。
具體地,圍繞SLO健康度體系主要介紹三方面的實踐場景:SLO品質大盤、K8S SLO健康度體系、以及基於SLO的故障應急流程。SLO品質大盤主要用來匯總基礎設施域所有服務SLO的達標情況,同時做橫向或跨組織的數據通曬,對齊SLO目標和共識;K8S SLO健康度是基於SLO構建的K8S服務能力可觀測性體系,透過對各個元件構建SLO指標,除了直觀地反映元件服務能力外,也為持續性營運提供了有效的度量;SLO故障應急流程打通了SLO預警、定位、預案推薦、決策等一系列AIOps能力,將散裝的能力組裝在一起,再借助釘釘承載各階段的展示或互動,以此實作掌上運維的應急能力。
SLO品質大盤
像第二章介紹過的,如下展示了實踐中一份相對完整的SLO後設資料Yaml配置,其中包括SLO的名稱定義、樣版型別、SLI、統計視窗、目標值,以及使用錯誤預算配置SLO預警方面的參數設定。
透過解析SLO的Yaml配置,定期采集並計算不同粒度的SLO數據和達標結果,SLO品質大盤按照產品集將相關的服務歸類後,把相同產品集下的不同粒度SLO的達標結果直觀地呈現出來。如下圖表所示,我們提供了月度視角、周視角、以及天視角來展示SLO的結果和達標情況,紅色的表格代表了在對應的時間視窗內,該產品集存在部份SLO不達標的情況,點選行首列的產品集名稱,即可展開所有SLO達標與否的明細資訊和具體SLO數值,以及相關的外鏈。未來,SLO品質大盤還會和故障定位下鉆報告打通,提升大盤的分析能力和互動體驗。
數據通曬是SRE常態化的營運機制,透過定期采集並計算不同粒度的SLO數據和達標結果,SLO品質大盤按照產品集將相關的服務歸類後,把相同產品集下不同粒度SLO的達標結果直觀的呈現出來。
如下圖表所示,我們提供了月度視角、周視角、以及天視角來展示SLO的結果和達標情況,紅色的表格代表了在對應的時間視窗內,該產品集存在部份SLO不達標的情況,透過顏色區分,直觀明了。
同時,在SLO品質大盤我們還和故障定位、下鉆報告等營運機制打通,提升了數位大盤的分析能力、互動體驗和驅動力。
K8S SLO體系
K8S以聲明式的模式提供異步資源交付能力,以Pod建立為例,使用者呼叫APIServer將Deployment的Yaml傳遞給K8S,經歷身份認證、數據校驗等一系列邏輯後儲存到Etcd中,然後控制器透過將現態和預期終態之間的數量做比對,不間斷調和,將後設資料和差異數量遞交到排程器,透過排程器分配資源和部署編排,最終在目標Node上透過Kubelet拉起Pod。實際上,K8S具體的處理邏輯會比這個描述復雜得多,從SLO體系建設角度,我們重點在於梳理出核心鏈路和服務水平的關鍵依賴。
在構建K8S SLO體系時,我們從不同的使用者視角出發,制定相應的SLO,這是因為角色不同的使用者所關心的能力和側重點是不盡相同的。直接使用K8S的原生能力,對大多數業務研發來說是有一定的門檻,另外後設資料的治理也會異常困難。所以,K8S直接提供服務的使用者主要包括像PaaS、研發效能、新計算等一些二方使用者。這部份使用者主要關註K8S所提供的資源交付能力和存取APIServer的服務水平,因為定義了PaaS級的交付成功率和耗時等SLO;從研發和SRE的視角,除了關註PaaS級的SLO外,也會關心K8S針對單個Pod交付能力相關的SLO,以及Pod執行時的健康度SLO。
站在研發和SRE的視角,我們定義了K8S對Pod新增、升級、刪除能力的成功率SLO,以及APIServer成功率、耗時和Pod健康度的SLO。透過這些SLO數據驅動SRE的日常工作和方向,對外數據通曬拉齊和研發的共同目標,基於SLO的告警或品質數據,開展故障復盤和技術共建等。另外,結合核心鏈路和服務水平的關鍵依賴,單獨從SRE視角,我們還定義了像核心元件相關的SLO、Node健康度SLO、以及交付鏈路上強依賴的下遊系統的SLO等。核心元件方面,比如針對控制器、排程器、Etcd等構建可用性SLO;Node健康度方面,比如故障節點自愈率成功率、故障節點Pod自動遷移成功率等場景的SLO;在K8S強依賴的下遊系統方面,以客戶端的視角構建如DNS、網路、映像、儲存等服務的延時和可用性SLO。
在構建K8S SLO體系的過程和實踐中,我們還沈澱了大量關於SLO預警的故障應急手冊和完善的故障管理流程等,這些數據資產和專家經驗對於結合人工智慧技術賦能運維具有非常大的幫助。
SLO故障應急
基於SLO健康度體系的故障應急流程是圍繞SRE日常工作重點實踐和探索的方向,如前面所介紹的,用以構建基於SLO預警、故障定位、預案推薦、自愈等應急能力的流水線模式,透過AIOps對各個環節賦能提效。實踐中,隨著日益完善的能力建設,這套應急流程已經可以覆蓋我們大部份的SLO。同時,借助故障演練平台常態化的演練,可以更加便捷地驗證相關能力的有效性,以此提升基礎設施側服務的可用性和穩定性。應急過程最關註時效性,於是我們以釘釘為載體,在移動端裝置開發掌上運維能力,以此提升應急效率。
當SLO產生預警時,會根據SLO配置中的告警優先級,選擇不同的通知方式進行投遞。例如低優先級的告警,只推播告警資訊到相應的釘釘應急群;而高優先級的告警除了推播到釘釘應急群外,還會透過電話外呼值班SRE及時關註處理。應急完成後,一個重要的步驟是需要對告警的有效性進行打標,以便日後的統計分析、以及最佳化。
在SLO預警之後,相應的故障定位流程就會被啟用,按照前面介紹的相關性定位方法,以此實作異常下鉆和根據歸類。一般的,故障定位報告包括:故障域資訊(異常SLF和SLD)和根因資訊(大部份情況下,故障都是由某個具體的變更引起)。為了更加清晰地呈現出故障報告內容,我們也實作了桌面端的拓撲圖展示,透過釘釘訊息卡片的連結跳轉過去。為了獲得更多的定位結果反饋資訊,在UI側增加更全面的反饋選項,這些反饋資訊可以幫助定位能力更好地最佳化和演進。
當完成故障定位的分析後,結合垂直領域的專業知識設計的智慧索引,將匹配到的最佳預案自動推播給應急值班SRE,每種預案都對應了相應的故障恢復操作,值班人員透過ChatOps的互動能力或外鏈跳轉完成預案執行。為了證實預案操作後有效與否,最直接的方式是觀察SLO告警是否恢復,以及借助異常檢測能力自動檢驗SLO是否恢復到正常水平。
拿到定位結果後,我們會設定大量預案。若僅涉及一些輕量級的恢復操作,可以直接呼叫。針對略微繁重的操作,則添加一個人工確認的步驟,透過點選釘釘上的傳送連結,在其他系統中點選確認,執行預案操作,最後以SLO的指標恢復作為整個故障恢復的衡量標準。
五、總結
SLO主要目的是數位化度量服務品質和服務水平,基於服務相關效能指標的統計分析,對服務水平劃分等級目標;透過對服務設定SLO和服務等級公示,有效實作對於服務品質的預期管理、使得服務水平更加透明,公示SLA促使上下遊系統之間握手達成共識;在穩定性治理和精細化運維方面,完成從故障驅動到SLO驅動的轉變。透過AIOps賦能,建設SLO針對運維場景的應急流水線能力,擴充套件SLO套用和生態。
當前我們的實踐已經基本完成了產品化,將相關的能力和流程沈澱、組裝進產品,為使用者提供統一的SLO平台服務。後續我們會持續推廣和完善,在產品輸出、SaaS化和開源方面也會進一步投入。概括總結產品化就是,借助SLO實作服務水平的數位化,讓服務品質可觀測、可衡量、可通曬,助力服務高品質叠代演進。
其余是一些實踐心得方面的感悟和總結,讀者自行解讀即可。
↓↓ 點選 閱讀原文 獲取本期PPT (提取碼:istn)











