
👉 歡迎 ,你將獲得: 專屬的計畫實戰 / Java 學習路線 / 一對一提問 / 學習打卡 / 贈書福利
全棧前後端分離部落格計畫 2.0 版本完結啦, 演示連結 : http://116.62.199.48/ , 新計畫正在醞釀中 。全程手摸手,後端 + 前端全棧開發,從 0 到 1 講解每個功能點開發步驟,1v1 答疑,直到計畫上線。 目前已更新了239小節,累計38w+字,講解圖:1645張,還在持續爆肝中.. 後續還會上新更多計畫,目標是將Java領域典型的計畫都整一波,如秒殺系統, 線上商城, IM即時通訊,Spring Cloud Alibaba 等等,
第一次最佳化
第二次最佳化
記憶體泄漏調查
第二次調優
總結
透過這一個多月的努力,將FullGC從40次/天最佳化到近10天才觸發一次,而且YoungGC的時間也減少了一半以上,這麽大的最佳化,有必要記錄一下中間的調優過程。
對於JVM垃圾回收,之前一直都是處於理論階段,就知道新生代,老年代的晉升關系,這些知識僅夠應付面試使用的。前一段時間,線上伺服器的FullGC非常頻繁,平均一天40多次,而且隔幾天就有伺服器自動重新開機了,這表明的伺服器的狀態已經非常不正常了,得到這麽好的機會,當然要主動請求進行調優了。未調優前的伺服器GC數據,FullGC非常頻繁。
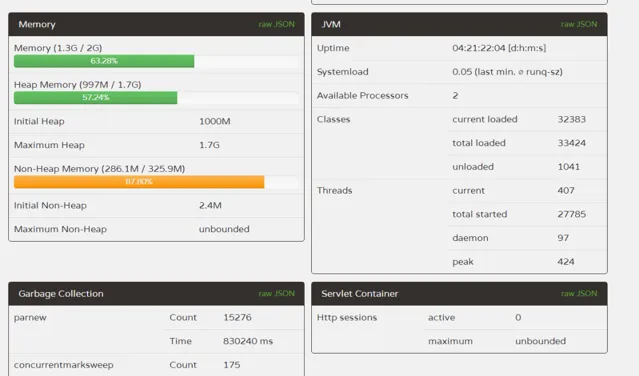
首先伺服器的配置非常一般(2核4G),總共4台伺服器集群。每台伺服器的FullGC次數和時間基本差不多。其中JVM幾個核心的啟動參數為:
-Xms1000M -Xmx1800M -Xmn350M -Xss300K -XX:+DisableExplicitGC -XX:SurvivorRatio=4 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -XX:+CMSParallelRemarkEnabled -XX:LargePageSizeInBytes=128M -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC
-Xmx1800M:設定JVM最大可用記憶體為1800M。
-Xms1000m:設定JVM初始化記憶體為1000m。此值可以設定與-Xmx相同,以避免每次垃圾回收完成後JVM重新分配記憶體。
-Xmn350M:設定年輕代大小為350M。整個JVM記憶體大小=年輕代大小 + 年老代大小 + 持久代大小。持久代一般固定大小為64m,所以增大年輕代後,將會減小年老代大小。此值對系統效能影響較大,Sun官方推薦配置為整個堆的3/8。
-Xss300K:設定每個執行緒的堆疊大小。JDK5.0以後每個執行緒堆疊大小為1M,以前每個執行緒堆疊大小為256K。更具套用的執行緒所需記憶體大小進行調整。在相同實體記憶體下,減小這個值能生成更多的執行緒。但是作業系統對一個行程內的執行緒數還是有限制的,不能無限生成,經驗值在3000~5000左右。
第一次最佳化
一看參數,馬上覺得新生代為什麽這麽小,這麽小的話怎麽提高吞吐量,而且會導致YoungGC的頻繁觸發,如上如的新生代收集就耗時830s。初始化堆記憶體沒有和最大堆記憶體一致,查閱了各種資料都是推薦這兩個值設定一樣的,可以防止在每次GC後進行記憶體重新分配。基於前面的知識,於是進行了第一次的線上調優:提升新生代大小,將初始化堆記憶體設定為最大記憶體
-Xmn350M -> -Xmn800M
-XX:SurvivorRatio=4 -> -XX:SurvivorRatio=8
-Xms1000m ->-Xms1800m
將SurvivorRatio修改為8的本意是想讓垃圾在新生代時盡可能的多被回收掉。就這樣將配置部署到線上兩台伺服器(prod,prod2另外兩台不變方便對比)上後,執行了5天後,觀察GC結果,YoungGC減少了一半以上的次數,時間減少了400s,但是FullGC的平均次數增加了41次。YoungGC基本符合預期設想,但是這個FullGC就完全不行了。

就這樣第一次最佳化宣告失敗。
第二次最佳化
在最佳化的過程中,我們的主管發現了有個物件T在記憶體中有一萬多個例項,而且這些例項占據了將近20M的記憶體。於是根據這個bean物件的使用,在計畫中找到了原因:匿名內部類參照導致的,虛擬碼如下:
public void doSmthing(T t){
redis.addListener(new Listener(){
public void onTimeout(){
if(t.success()){
//執行操作
}
}
});
}
由於listener在回呼後不會進行釋放,而且回呼是個超時的操作,當某個事件超過了設定的時間(1分鐘)後才會進行回呼,這樣就導致了T這個物件始終無法回收,所以記憶體中會存在這麽多物件例項。
透過上述的例子發現了存在記憶體泄漏後,首先對程式中的error log檔進行排查,首先先解決掉所有的error事件。然後再次釋出後,GC操作還是基本不變,雖然解決了一點記憶體泄漏問題,但是可以說明沒有解決根本原因,伺服器還是繼續莫名的重新開機。
記憶體泄漏調查
經過了第一次的調優後發現記憶體泄漏的問題,於是大家都開始將進行記憶體泄漏的調查,首先排查程式碼,不過這種效率是蠻低的,基本沒發現問題。於是線上上不是很繁忙的時候繼續進行dump記憶體,終於抓到了一個大物件
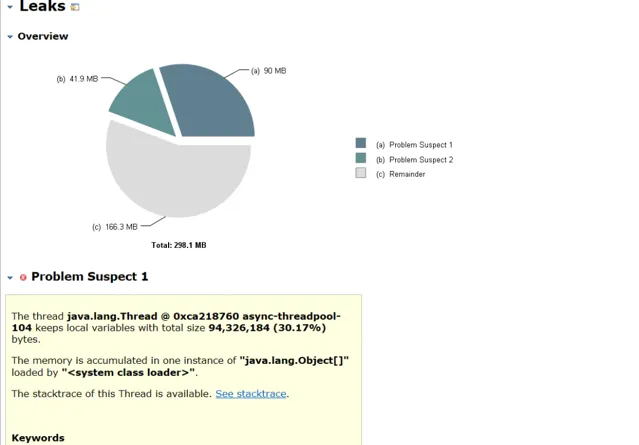
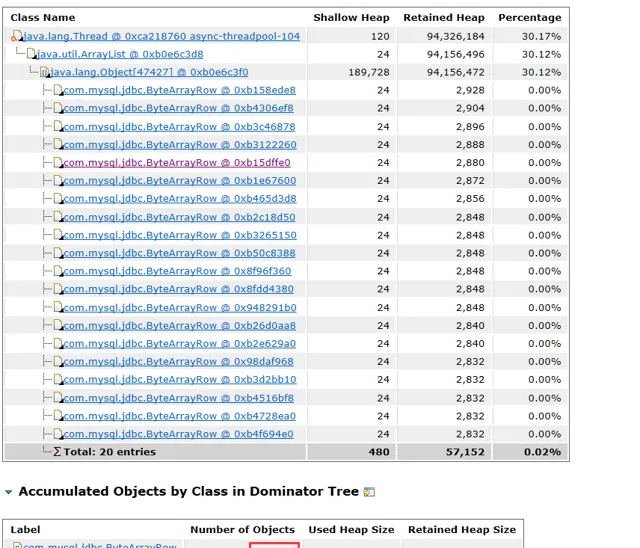
這個物件竟然有4W多個,而且都是清一色的ByteArrowRow物件,可以確認這些數據是資料庫查詢或者插入時產生的了。於是又進行一輪代分碼析,在代分碼析的過程中,透過運維的同事發現了在一天的某個時候入口流量翻了好幾倍,竟然高達83MB/s,經過一番確認,目前完全沒有這麽大的業務量,而且也不存在檔上傳的功能。咨詢了阿裏雲客服也說明完全是正常的流量,可以排除攻擊的可能。
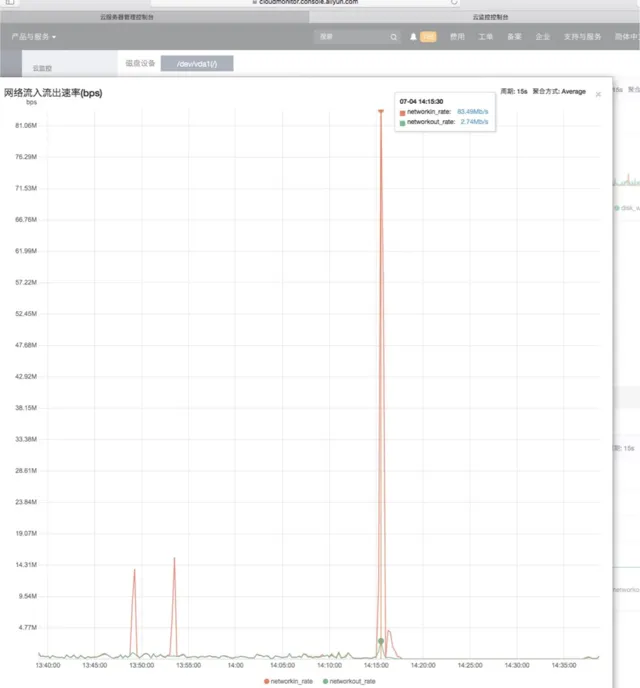
就在我還在調查入口流量的問題時,另外一個同事找到了根本的原因,原來是在某個條件下,會查詢表中所有未處理的指定數據,但是由於查詢的時候where條件中少加了模組這個條件,導致查詢出的數量達40多萬條,而且透過log檢視當時的請求和數據,可以判斷這個邏輯確實是已經執行了的,dump出的記憶體中只有4W多個物件,這個是因為dump時候剛好查詢出了這麽多個,剩下的還在傳輸中導致的。而且這也能非常好的解釋了為什麽伺服器會自動重新開機的原因。
解決了這個問題後,線上伺服器執行完全正常了,使用未調優前的參數,執行了3天左右FullGC只有5次
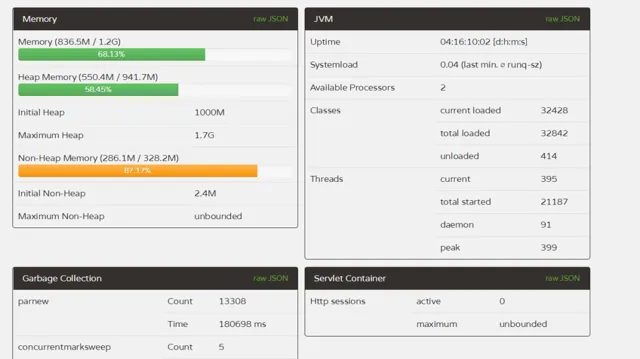
第二次調優
記憶體泄漏的問題已經解決了,剩下的就可以繼續調優了,經過檢視GC log,發現前三次GullGC時,老年代占據的記憶體還不足30%,卻發生了FullGC。於是進行各種資料的調查,在https://blog.csdn.net/zjwstz/article/details/77478054 部落格中非常清晰明了的說明metaspace導致FullGC的情況,伺服器預設的metaspace是21M,在GC log中看到了最大的時候metaspace占據了200M左右,於是進行如下調優,以下分別為prod1和prod2的修改參數,prod3,prod4保持不變
-Xmn350M -> -Xmn800M
-Xms1000M ->1800M
-XX:MetaspaceSize=200M
-XX:CMSInitiatingOccupancyFraction=75
和
-Xmn350M -> -Xmn600M
-Xms1000M ->1800M
-XX:MetaspaceSize=200M
-XX:CMSInitiatingOccupancyFraction=75
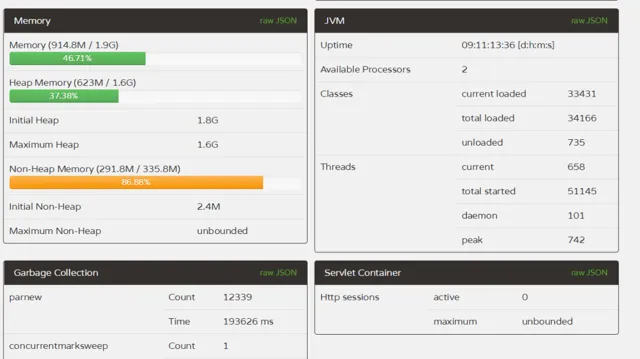
prod1和2只是新生代大小不一樣而已,其他的都一致。到線上執行了10天左右,進行對比:prod1:
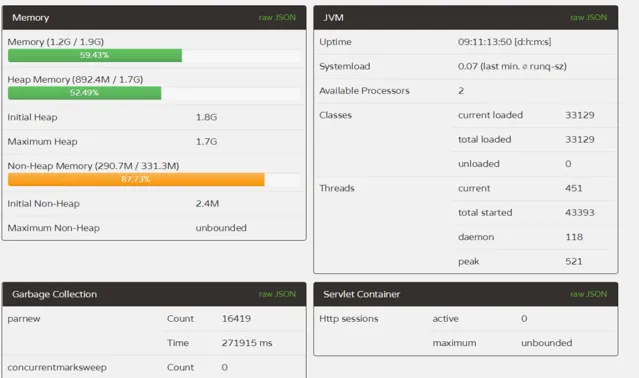
prod2:
prod3:
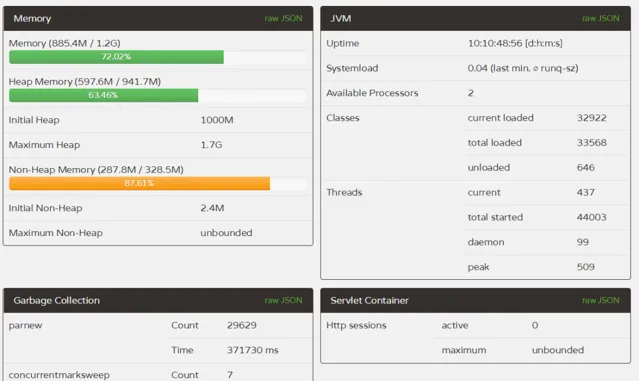
prod4:

對比來說,1,2兩台伺服器FullGC遠遠低於3,4兩台,而且1,2兩台伺服器的YounGC對比3,4也減少了一半左右,而且第一台伺服器效率更為明顯,除了YoungGC次數減少,而且吞吐量比多執行了一天的3,4兩台的都要多(透過執行緒啟動數量),說明prod1的吞吐量提升尤為明顯。透過GC的次數和GC的時間,本次最佳化宣告成功,且prod1的配置更優,極大提升了伺服器的吞吐量和降低了GC一半以上的時間。
prod1中的唯一一次FullGC:
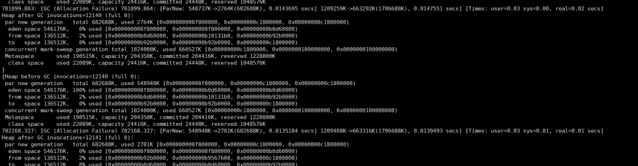
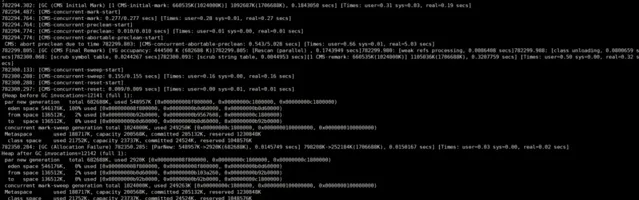
透過GC log上也沒看出原因,老年代在cms remark的時候只占據了660M左右,這個應該還不到觸發FullGC的條件,而且透過前幾次的YoungGC調查,也排除了晉升了大記憶體物件的可能,透過metaspace的大小,也沒有達到GC的條件。這個還需要繼續調查,有知道的歡迎指出下,這裏先行謝過了。
總結
透過這一個多月的調優總結出以下幾點:
FullGC一天超過一次肯定就不正常了
發現FullGC頻繁的時候優先調查記憶體泄漏問題
記憶體泄漏解決後,jvm可以調優的空間就比較少了,作為學習還可以,否則不要投入太多的時間
如果發現CPU持續偏高,排除程式碼問題後可以找運維咨詢下阿裏雲客服,這次調查過程中就發現CPU 100%是由於伺服器問題導致的,進行伺服器遷移後就正常了。
數據查詢的時候也是算作伺服器的入口流量的,如果存取業務沒有這麽大量,而且沒有攻擊的問題的話可以往資料庫方面調查
有必要時常關註伺服器的GC,可以及早發現問題
👉 歡迎 ,你將獲得: 專屬的計畫實戰 / Java 學習路線 / 一對一提問 / 學習打卡 / 贈書福利
全棧前後端分離部落格計畫 2.0 版本完結啦, 演示連結 : http://116.62.199.48/ , 新計畫正在醞釀中 。全程手摸手,後端 + 前端全棧開發,從 0 到 1 講解每個功能點開發步驟,1v1 答疑,直到計畫上線。 目前已更新了239小節,累計38w+字,講解圖:1645張,還在持續爆肝中.. 後續還會上新更多計畫,目標是將Java領域典型的計畫都整一波,如秒殺系統, 線上商城, IM即時通訊,Spring Cloud Alibaba 等等,

1.
2.
3.
4.
最近面試BAT,整理一份面試資料【Java面試BATJ通關手冊】,覆蓋了Java核心技術、JVM、Java並行、SSM、微服務、資料庫、數據結構等等。
獲取方式:點「在看」,關註公眾號並回復 Java 領取,更多內容陸續奉上。
PS:因公眾號平台更改了推播規則,如果不想錯過內容,記得讀完點一下「在看」,加個「星標」,這樣每次新文章推播才會第一時間出現在你的訂閱列表裏。
點「在看」支持小哈呀,謝謝啦











