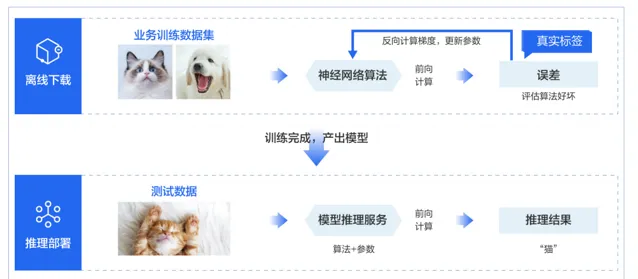
通常,在在AI智算系統中,一個模型從生產到套用,一般包括離線訓練和推理部署兩大階段;本文選自「 」,常用的對IB和ROCE V2高效能網路進行全面的分析對比。
智算網路的選型和建設階段的典型問題包括:
1. 智算網路是復用當前的TCP/IP通用網路的基礎設施,還是新建一張專用的高效能網路?
2. 智算網路技術方案采用 InfiniBand 還是 RoCE ?
3. 智算網路如何進行運維和管理?
4. 智算網路是否具備多租戶隔離能力以實作對內和對外的營運?
離線訓練,就是產生模型的過程。使用者需要根據自己的任務場景,準備好訓練模型所需要的數據集以及神經網路演算法。模型訓練開始後,先讀取數據,然後送入模型進行前向計算,並計算與真實值的誤差。然後執行反向計算得到參數梯度,最後更新參數。訓練過程會進行多輪的數據叠代。訓練完成之後,保存訓練好的模型,然後將模型做上線部署,接受使用者的真實輸入,透過前向計算,完成推理。因此,無論是訓練還是推理,核心都是數據計算。為了加速計算效率,一般都是透過 GPU 等異構加速芯片來進行訓練和推理。
隨著以 GPT3.0 為代表的大模型展現出令人驚艷的能力後,智算業務往海量參數的大模型方向發展已經成為一個主流技術演進路徑。以自然語言處理(NLP)為例,模型參數已經達到了千億級別。電腦視覺(CV) 、廣告推薦、智慧風控等領域的模型參數規模也在不斷的擴大,正在往百億和千億規模參數的方向發展。
在自動駕駛場景中,每車每日會產生 T 級別數據,每次訓練的數據達到 PB 級別。大規模數據處理和大規模仿真任務的特點十分顯著,需要使用智算集群來提升數據處理與模型訓練的效率。
大模型訓練中大規模的參數對算力和視訊記憶體都提出了更高的要求。以GPT3為例,千億參數需要2TB視訊記憶體,當前的單卡視訊記憶體容量不夠。即便出現了大容量的視訊記憶體,如果用單卡訓練的話也需要32年。為了縮短訓練時間,通常采用分布式訓練技術,對模型和數據進行切分,采用多機多卡的方式將訓練時長縮短到周或天的級別。
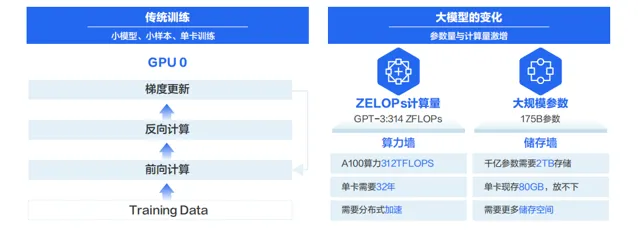
分布式訓練就是透過多台節點構建出一個計算能力和視訊記憶體能力超大的集群,來應對大模型訓練中算力墻和儲存墻這兩個主要挑戰。而聯接這個超級集群的高效能網路直接決定了智算節點間的通訊效率,進而影響整個智算集群的吞吐量和效能。要讓整個智算集群獲得高的吞吐量,高效能網路需要具備低時延、大頻寬、長期穩定性、大規模擴充套件性和可運維幾個關鍵能力。
分布式訓練系統的整體算力並不是簡單的隨著智算節點的增加而線性增長,而是存在加速比,且加速比小於 1。存在加速比的主要原因是:在分布式場景下,單次的計算時間包含了單卡的計算時間疊加卡間通訊時間。因此,降低卡間通訊時間,是分布式訓練中提升加速比的關鍵,需要重點考慮和設計。
降低多機多卡間端到端通訊時延的關鍵技術是 RDMA 技術。RDMA 可以繞過作業系統內核,讓一台主機可以直接存取另外一台主機的記憶體。
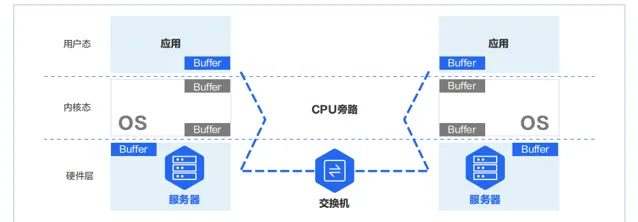
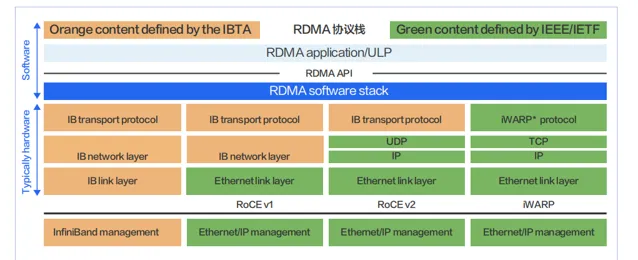
實 現 RDMA 的 方 式 有 InfiniBand、RoCEv1、RoCEv2、i WARP 四 種。其 中 RoCEv1 技 術 當 前 已 經 被 淘 汰,iWARP 使用較少。當前 RDMA 技術主要采用的方案為 InfiniBand 和 RoCEv2 兩種。
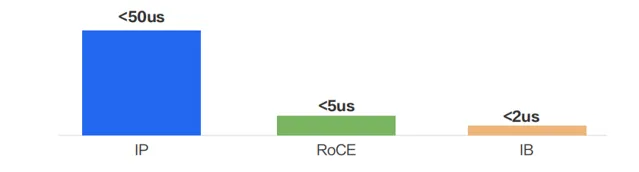
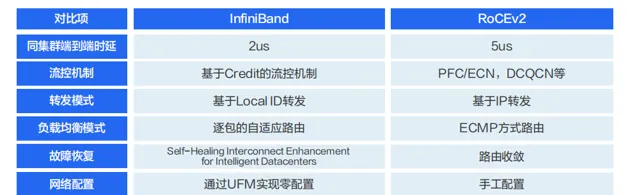
在 InfiniBand 和 RoCEv2 方案中,因為繞過了內核協定棧,相較於傳統 TCP/IP 網路,時延效能會有數十倍的改善。在同集群內部一跳可達的場景下,InfiniBand 和 RoCEv2 與傳統 IP 網路的端到端時延在實驗室的測試數據顯示,繞過內核協定棧後,套用層的端到端時延可以從 50us(TCP/IP),降低到 5us(RoCE)或 2us(InfiniBand)。
在完成計算任務後,智算集群內部的計算節點需要將計算結果快速地同步給其他節點,以便進行下一輪計算。在結果同步完成前,計算任務處於等待狀態,不會進入下一輪計算。如果頻寬不夠大,梯度傳輸就會變慢,造成卡間通訊時長變長,進而影響加速比。
要滿足智算網路的 低時延、大頻寬、穩定執行、大規模以及可運維 的需求, 目前業界比較常用的網路方案是 InfiniBand方案和 RoCEv2 方案 。
一、InfiniBand網路介紹
InfiniBand網路的關鍵組成包括Subnet Manager(SM)、InfiniBand 網卡、InfiniBand交換機和InfiniBand連線線纜。
支持 InfiniBand 網卡的廠家以 NVIDIA 為主。下圖是當前常見的 InfiniBand 網卡。InfiniBand 網卡在速率方面保持著快速的發展。200Gbps 的 HDR 已經實作了規模化的商用部署,400Gbps 的 NDR的網卡也已經開始商用部署。

在InfiniBand交換機中,SB7800 為 100Gbps 埠交換機(36*100G),屬於 NVIDIA 比較早的一代產品。Quantum-1 系列為 200Gbps 埠交換機(40*200G),是當前市場采用較多的產品。
在 2021 年,NVIDIA 推出了 400Gbps 的 Quantum-2 系列交換機(64*400G)。交換機上有 32 個 800G OSFP(Octal Small Form Factor Pluggable)口,需要透過線纜轉接出 64 個 400G QSFP。
InfiniBand 交換機上不執行任何路由協定。整個網路的轉發表是由集中式的子網路管理器(Subnet Manager,簡稱 SM)進行計算並統一下發的。除了轉發表以外,SM 還負責管理 InfiniBand 子網路的 Partition、QoS 等配置。InfiniBand 網路需要專用的線纜和光模組做交換機間的互聯以及交換機和網卡的互聯。
InfiniBand 網路方案特點
(1)原生無失真網路
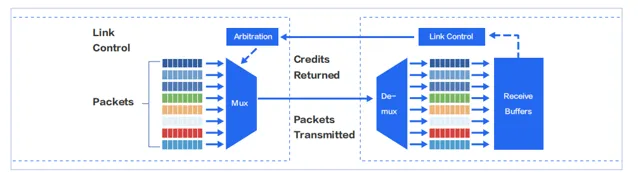
InfiniBand 網路采用基於 credit 信令機制來從根本上避免緩沖區溢位丟包。只有在確認對方有額度能接收對應數量的報文後,發送端才會啟動報文發送。InfiniBand 網路中的每一條鏈路都有一個偏好設定緩沖區。發送端一次性發送數據不會超過接收端可用的偏好設定緩沖區大小,而接收端完成轉發後會騰空緩沖區,並且持續向發送端返回當前可用的偏好設定緩沖區大小。依靠這一鏈路級的流控機制,可以確保發送端絕不會發送過量,網路中不會產生緩沖區溢位丟包。
(2)萬卡擴充套件能力
InfiniBand 的 Adaptive Routing 基於逐包的動態路由,在超大規模組網的情況下保證網路最優利用。InfiniBand 網路在業界有較多的萬卡規模超大 GPU 集群的案例,包括百度智慧雲,微軟雲等。
目前市場上主要的 InfiniBand 網路方案及配套裝置供應商有以下幾家。其中,市場占有率最高的是 NVIDIA,其市場份額大於 7 成。
NVIDIA: NVIDIA是InfiniBand技術的主要供應商之一,提供各種InfiniBand介面卡、交換機和其他相關產品。
Intel Corporation: Intel是另一個重要的InfiniBand供應商,提供各種InfiniBand網路產品和解決方案。
Cisco Systems: Cisco是一家知名的網路裝置制造商,也提供InfiniBand交換機和其他相關產品。
Hewlett Packard Enterprise: HPE是一家大型IT公司,提供各種InfiniBand網路解決方案和產品,包括介面卡、交換機和伺服器等。
2、RoCEv2 網路介紹
InfiniBand 網路在一定程度上是一個由 SM(Subnet Manager,子網路管理器)進行集中管理的網路。而 RoCEv2 網路則是一個純分布式的網路,由支持 RoCEv2 的網卡和交換機組成,一般情況下是兩層架構。
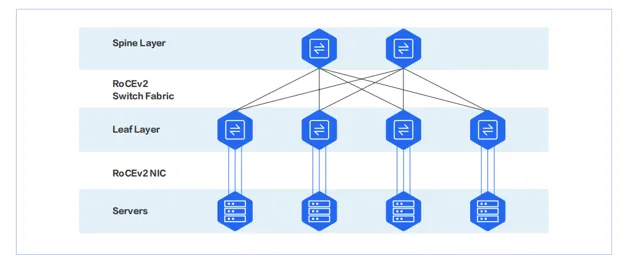
支持 RoCE 網卡的廠家比較多,主流廠商為 NVIDIA、Intel、Broadcom。數據中心伺服器網卡主要以 PCIe 卡為主。RDMA 網卡的埠 PHY 速率一般是 50Gbps 起,當前商用的網卡單埠速率已達 400Gbps。

當前大部份數據中心交換機都支持 RDMA 流控技術,和 RoCE 網卡配合,實作端到端的 RDMA 通訊。國內的主流數據中心交換機廠商包括華為、新華三等。
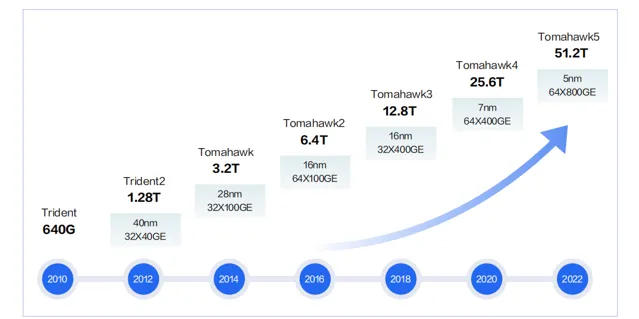
高性 能 交 換 機的核心 是 轉發 芯片。當前 市場上的商用轉發 芯片用的比 較 多的是博通的 Tomahawk 系列芯片。其中Tomahawk3 系列的芯片在當前交換機上使用的比較多,市場上支持 Tomahawk4 系列的芯片的交換機也逐漸增多。
RoCEv2 承載在乙太網路上,所以傳統乙太網路的光纖和光模組都可以用。
RoCEv2 網路方案特點
RoCE 方案相對於 InfiniBand 方案的特點是通用性較強和價格相對較低。除用於構建高效能 RDMA 網路外,還可以在傳統的乙太網路絡中使用。但在交換機上的 Headroom、PFC、ECN 相關參數的配置是比較復雜的。在萬卡這種超大規模場景下,整個網路的吞吐效能較 InfiniBand 網路要弱一些。
支持 RoCE 的交換機廠商較多,市場占有率排名靠前的包括新華三、華為等。支持 RoCE 的網卡當前市場占有率比較高的是 NVIDIA 的 ConnectX 系列的網卡。
3、InfiniBand 和 RoCEv2網路方案對比
從技術角度看,InfiniBand 使用了較多的技術來提升網路轉發效能,降低故障恢復時間,提升擴充套件能力,降低運維復雜度。
具體到實際業務場景上看,RoCEv2 是足夠好的方案,而 InfiniBand 是特別好的方案。
業務效能方面: 由於 InfiniBand 的端到端時延小於 RoCEv2,所以基於 InfiniBand 構建的網路在套用層業務效能方面占優。但 RoCEv2 的效能也能滿足絕大部份智算場景的業務效能要求。
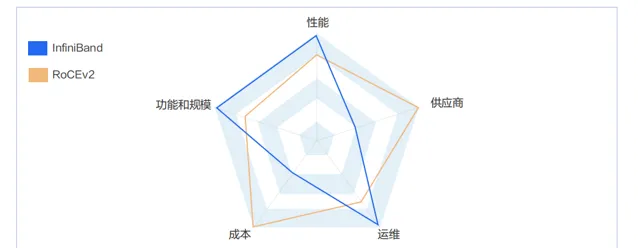
業務規模方面: InfiniBand 能支持單集群萬卡 GPU 規模,且保證整體效能不下降,並且在業界有比較多的商用實踐案例。RoCEv2 網路能在單集群支持千卡規模且整體網路效能也無太大的降低。
業務運維方面: InfiniBand 較 RoCEv2 更成熟,包括多租戶隔離能力,運維診斷能力等。
業務成本方面: InfiniBand 的成本要高於 RoCEv2,主要是 InfiniBand 交換機的成本要比以太交換機高一些。
業務供應商方面: InfiniBand 的供應商主要以 NVIDIA 為主,RoCEv2 的供應商較多。
相關閱讀:
轉載申明:轉載 本號文章請 註明作者 和 來源 ,本號釋出文章若存在版權等問題,請留言聯系處理,謝謝。
推薦閱讀
更多 架構相關技術 知識總結請參考「 架構師全店鋪技術資料打包 (全) 」相關電子書( 41本 技術資料打包匯總詳情 可透過「 閱讀原文 」獲取)。
全店內容持續更新,現下單「 架構師技術全店資料打包匯總(全) 」一起發送「 」 和「 」 pdf及ppt版本 ,後續可享 全店 內容更新「 免費 」贈閱,價格僅收 249 元(原總價 399 元)。
溫馨提示:
掃描 二維碼 關註公眾號,點選 閱讀原文 連結 獲取 「 架構師技術全店資料打包匯總(全) 」 電子書資料詳情 。