一.RabbitMQ訊息遺失的三種情況
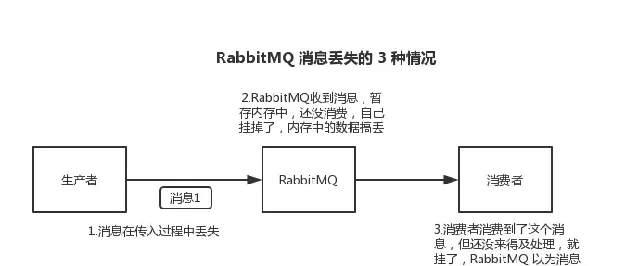
第一種:生產者弄丟了數據。生產者將數據發送到 RabbitMQ 的時候,可能數據就在半路給搞丟了,因為網路問題啥的,都有可能。
第二種:RabbitMQ 弄丟了數據。MQ還沒有持久化自己掛了。
第三種:消費端弄丟了數據。剛消費到,還沒處理,結果行程掛了,比如重新開機了。
二.RabbitMQ訊息遺失解決方案
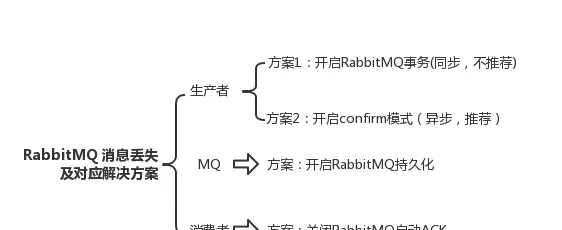
1.針對生產者
方案1 :開啟RabbitMQ事務
可以選擇用 RabbitMQ 提供的事務功能,就是生產者發送數據之前開啟 RabbitMQ 事務channel.txSelect,然後發送訊息,如果訊息沒有成功被 RabbitMQ 接收到,那麽生產者會收到異常報錯,此時就可以回滾事務channel.txRollback,然後重試發送訊息;如果收到了訊息,那麽可以送出事務channel.txCommit。
// 開啟事務
channel.txSelect();
try {
// 這裏發送訊息
} catch (Exception e) {
channel.txRollback();
// 這裏再次重發這條訊息
}
// 送出事務
channel.txCommit();
缺點:
RabbitMQ 事務機制 是同步的,你送出一個事務之後會阻塞在那兒,采用這種方式基本上吞吐量會下來,因為太耗效能。
方案2:使用confirm機制
事務機制和 confirm 機制最大的不同在於,事務機制是同步的,你送出一個事務之後會阻塞在那兒,但是 confirm 機制是異步的
在生產者開啟了confirm模式之後,每次寫的訊息都會分配一個唯一的id,然後如果寫入了rabbitmq之中,rabbitmq會給你回傳一個 ack訊息 ,告訴你這個訊息發送OK了;如果rabbitmq沒能處理這個訊息,會回呼你一個 nack 介面,告訴你這個訊息失敗了,你可以進行重試。而且你可以結合這個機制知道自己在記憶體裏維護每個訊息的id,如果超過一定時間還沒接收到這個訊息的回呼,那麽你可以進行重發。
//開啟confirm
channel.confirm();
//發送成功回呼
publicvoidack(String messageId){
}
// 發送失敗回呼
publicvoidnack(String messageId){
//重發該訊息
}
2.針對RabbitMQ
主要需要應對三點:
要保證rabbitMQ不遺失訊息,那麽就需要開啟rabbitMQ的持久化機制,即把訊息持久化到硬碟上,這樣即使rabbitMQ掛掉在重新開機後仍然可以從硬碟讀取訊息;
如果rabbitMQ單點故障怎麽辦,這種情況倒不會造成訊息遺失,這裏就要提到rabbitMQ的3種安裝模式,單機模式、普通集群模式、映像集群模式,這裏要保證rabbitMQ的高可用就要配合HAPROXY做映像集群模式;
如果硬碟壞掉怎麽保證訊息不遺失。
(1)訊息持久化
RabbitMQ 的訊息預設存放在記憶體上面,如果不特別聲明設定,訊息不會持久化保存到硬碟上面的,如果節點重新開機或者意外crash掉,訊息就會遺失。
所以就要對訊息進行持久化處理。如何持久化,下面具體說明下。要想做到訊息持久化,必須滿足以下三個條件,缺一不可。
Exchange 設定持久化
Queue 設定持久化
Message持久化發送:發送訊息設定發送模式deliveryMode=2,代表持久化訊息
(2)設定集群映像模式
先來介紹下RabbitMQ三種部署模式:
單節點模式:最簡單的情況,非集群模式,節點掛了,訊息就不能用了。業務可能癱瘓,只能等待。
普通模式:訊息只會存在與當前節點中,並不會同步到其他節點,當前節點宕機,有影響的業務會癱瘓,只能等待節點恢復重新開機可用(必須持久化訊息情況下)。
映像模式:訊息會同步到其他節點上,可以設定同步的節點個數,但吞吐量會下降。屬於RabbitMQ的HA方案
為什麽設定映像模式集群,因為佇列的內容僅僅存在某一個節點上面,不會存在所有節點上面,所有節點僅僅存放訊息結構和後設資料。下面畫了一張圖介紹普通集群遺失訊息情況:
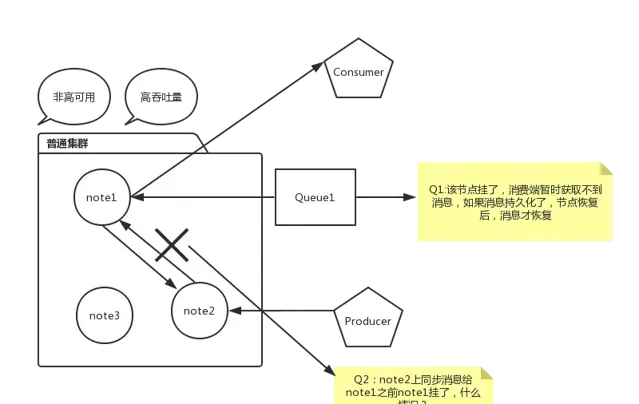
如果想解決上面途中問題,保證訊息不遺失,需要采用HA 映像模式佇列。
下面介紹下三種HA策略模式:
同步至所有的
同步最多N個機器
只同步至符合指定名稱的nodes
命令處理HA策略模版:
rabbitmqctl set_policy [-p Vhost] Name Pattern Definition [Priority]
1)為每個以
rock.wechat
開頭的佇列設定所有節點的映像,並且設定為自動
同步模式
rabbitmqctl set_policy ha-all "^rock.wechat" '{"ha-mode":"all","ha-sync-mode":"automatic"}'
rabbitmqctl set_policy -p rock ha-all "^rock.wechat" '{"ha-mode":"all","ha-sync-mode":"automatic"}'
2)為每個以
rock.wechat.
開頭的佇列設定兩個節點的映像,並且設定為自動同步模式
rabbitmqctl set_policy -p rock ha-exacly "^rock.wechat" \
'{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
3)為每個以
node.
開頭的佇列分配指定的節點做映像
rabbitmqctl set_policy ha-nodes "^nodes\." \
'{"ha-mode":"nodes","ha-params":["rabbit@nodeA", "rabbit@nodeB"]}'
但是:HA 映像佇列有一個很大的缺點就是系統的吞吐量會有所下降。
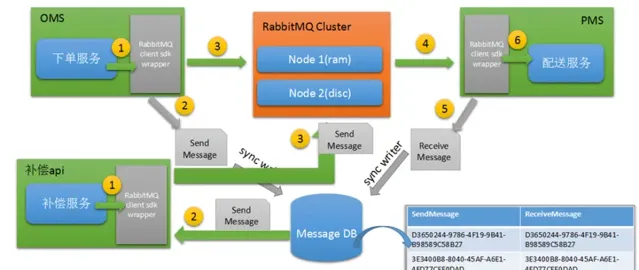
(3)訊息補償機制
為什麽還要訊息補償機制呢?難道訊息還會遺失,沒錯,系統是在一個復雜的環境,不要想的太簡單了,雖然以上的三種方案,基本可以保證訊息的高可用不遺失的問題。
但是作為有追求的程式設計師來講,要絕對保證我的系統的穩定性,有一種危機意識。
比如:持久化的訊息,保存到硬碟過程中,當前佇列節點掛了,儲存節點硬碟又壞了,訊息丟了,怎麽辦?
1)生產端首先將業務數據以及訊息數據入庫,需要在同一個事務中,訊息數據入庫失敗,則整體回滾。
2)根據訊息表中訊息狀態,失敗則進行訊息補償措施,重新發送訊息處理。
3.針對消費者
方案一:ACK確認機制
多個消費者同時收取訊息,比如訊息接收到一半的時候,一個消費者死掉了(邏輯復雜時間太長,超時了或者消費被停機或者網路斷開連結),如何保證訊息不丟?
使用rabbitmq提供的ack機制,伺服端首先關閉rabbitmq的自動ack,然後每次在確保處理完這個訊息之後,在程式碼裏手動呼叫ack。這樣就可以避免訊息還沒有處理完就ack。才把訊息從記憶體刪除。
這樣就解決了,即使一個消費者出了問題,但不會同步訊息給伺服端,會有其他的消費端去消費,保證了訊息不丟的case。
總結
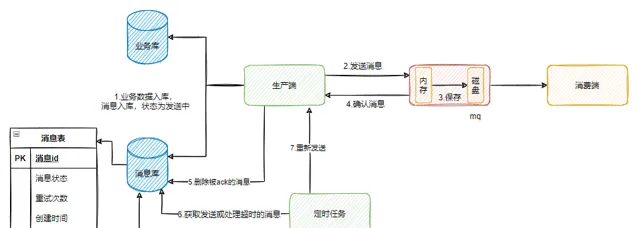
如果需要保證訊息在整條鏈路中不遺失,那就需要生產端、mq自身與消費端共同去保障。
生產端:對生產的訊息進行狀態標記,開啟confirm機制,依據mq的響應來更新訊息狀態,使用定時任務重新投遞超時的訊息,多次投遞失敗進行報警。
mq自身:開啟持久化,並在落盤後再進行ack。如果是映像部署模式,需要在同步到多個副本之後再進行ack。
消費端:開啟手動ack模式,在業務處理完成後再進行ack,並且需要保證 冪等 。
透過以上的處理,理論上不存在訊息遺失的情況,但是系統的吞吐量以及效能有所下降。在實際開發中,需要考慮訊息遺失的影響程度,來做出對可靠性以及效能之間的權衡。
原文地址: https://blog.csdn.net/w20001118/article/details/12659597











