
👉 歡迎 ,你將獲得: 專屬的計畫實戰 / 1v1 提問 / Java 學習路線 / 學習打卡 / 每月贈書 / 社群討論
新計畫: 【從零手擼:仿小紅書(微服務架構)】 正在持續爆肝中,基於 Spring Cloud Alibaba + Spring Boot 3.x + JDK 17..., ;
【從零手擼:前後端分離部落格計畫(全棧開發)】 2期已完結,演示連結: http://116.62.199.48/ ;
截止目前, 累計輸出 48w+ 字,講解圖 2090+ 張,還在持續爆肝中.. 後續還會上新更多計畫,目標是將 Java 領域典型的計畫都整一波,如秒殺系統, 線上商城, IM 即時通訊,Spring Cloud Alibaba 等等,
1. 業務場景概述
目標是實作一個公司的申請審批流程,整個業務流程涉及到兩種角色,分別為商務角色與管理員角色。整個流程如下圖所示:
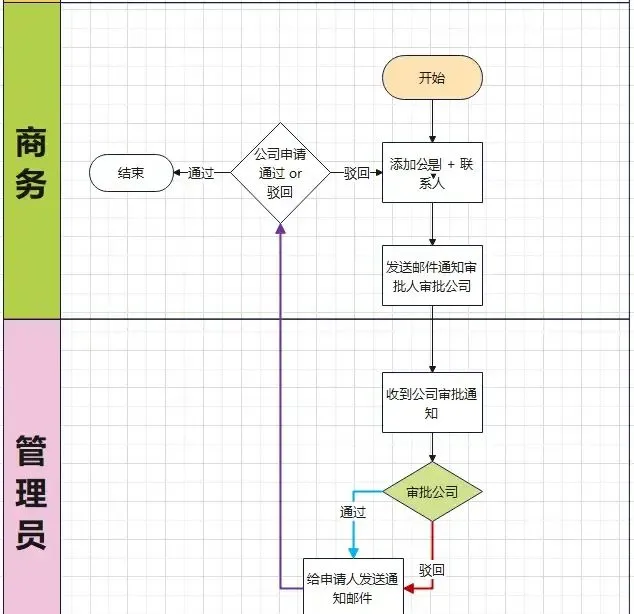
核心流程總結為一句話: 商務角色申請添加公司後由管理員進行審批。
商務在添加公司時,可能為了方便,直接填寫公司簡稱,而公司全稱可能之前已經被添加過了,為了防止添加重復的公司,所以管理員在針對公司資訊審批之前,需要檢視以往添加的公司資訊裏有無同一個公司。
2. 實作思路
以上是一個業務場景的大概介紹。從技術層面需要考慮實作的功能點:
• 分詞
• 與柯瑞已有數據進行匹配
• 按照匹配度對結果進行排序
分詞功能有現成的分詞器,所以整個需求的核心重點在於如何與資料庫中的數據匹配並按照匹配度排序。
3. 模糊匹配技術選型
• 方案一:引入ES
• 方案二:利用MySQL實作
本系統規模較小,單純為了實作這個功能引入ES成本較大,還要涉及到數據同步等問題,系統復雜性會提高,所以盡量使用MySQL已有的功能進行實作。
MySQL提供了以下三種模糊搜尋的方式:
• like匹配: 要求模式串與整個目標欄位完全匹配;
• RegExp正則匹配: 要求目標欄位包含模式串即可;
•
Fulltext全文索引:
在欄位型別為
CHAR
、
VARCHAR
、
TEXT
的列上建立全文索引,執行SQL進行查詢。
針對於上述業務場景,對相關技術進行優劣分析:
• like匹配: 無法滿足需求,所以pass;
• 全文索引: 可客製性差,不支持任意匹配查詢,pass;
• 正則匹配: 可實作任意模式匹配,缺點在於執行效率不如全文索引。
針對於這個場景,記錄數目相對來說沒有那麽多,所以對於效率稍低的結果可以接受,因此技術選型方面采用RegExp正則匹配來實作模糊匹配的需求。
4. 實作效果展示
5. 核心程式碼
整個邏輯基於 提取公司名稱關鍵資訊 -->分詞 --> 匹配 三個核心步驟。
5.1 提取公司關鍵資訊
對輸入的公司名稱去除廢料,保留關鍵資訊。這裏的廢料指的是地名,圓括弧,以及集團,股份,有限等。
匹配前處理公司名稱
/**
* 匹配前去除公司名稱的無意義資訊
* @param targetCompanyName
* @return
*/
privateStringformatCompanyName(String targetCompanyName){
Stringregex="(?<province>[^省]+自治區|.*?省|.*?行政區|.*?市)"+
"?(?<city>[^市]+自治州|.*?地區|.*?行政單位|.+盟|市轄區|.*?市|.*?縣)"+
"?(?<county>[^(區|市|縣|旗|島)]+區|.*?市|.*?縣|.*?旗|.*?島)"+
"?(?<village>.*)";
Matchermatcher=Pattern.compile(regex).matcher(targetCompanyName);
while(matcher.find()){
Stringprovince= matcher.group("province");
log.info("province:{}",province);
if(StringUtils.isNotBlank(province)&& targetCompanyName.contains(province)){
targetCompanyName = targetCompanyName.replace(province,"");
}
log.info("處理完省份的公司名稱:{}",targetCompanyName);
Stringcity= matcher.group("city");
log.info("city:{}",city);
if(StringUtils.isNotBlank(city)&& targetCompanyName.contains(city)){
targetCompanyName = targetCompanyName.replace(city,"");
}
log.info("處理完城市的公司名稱:{}",targetCompanyName);
Stringcounty= matcher.group("county");
log.info("county:{}",county);
if(StringUtils.isNotBlank(county)&& targetCompanyName.contains(county)){
targetCompanyName = targetCompanyName.replace(county,"");
}
log.info("處理完區縣級的公司名稱:{}",targetCompanyName);
}
String[][] address =AddressUtil.ADDRESS;
for(String[] city: address){
for(String b : city ){
if(targetCompanyName.contains(b)){
targetCompanyName = targetCompanyName.replace(b,"");
}
}
}
log.info("處理後的公司名稱:{}",targetCompanyName);
return targetCompanyName;
}
地名工具類
public classAddressUtil{
publicstaticfinalString[][] ADDRESS ={
{"北京"},
{"天津"},
{"安徽","安慶","蚌埠","亳州","巢湖","池州","滁州","阜陽","合肥","淮北","淮南","黃山","六安","馬鞍山","宿州","銅陵","蕪湖","宣城"},
{"澳門"},
{"香港"},
{"福建","福州","龍巖","南平","寧德","莆田","泉州","廈門","漳州"},
{"甘肅","白銀","定西","甘南藏族自治州","嘉峪關","金昌","酒泉","蘭州","臨夏回族自治州","隴南","平涼","慶陽","天水","武威","張掖"},
{"廣東","潮州","東莞","佛山","廣州","河源","惠州","江門","揭陽","茂名","梅州","清遠","汕頭","汕尾","韶關","深圳","陽江","雲浮","湛江","肇慶","中山","珠海"},
{"廣西","百色","北海","崇左","防城港","貴港","桂林","河池","賀州","來賓","柳州","南寧","欽州","梧州","玉林"},
{"貴州","安順","畢節地區","貴陽","六盤水","黔東南苗族侗族自治州","黔南布依族苗族自治州","黔西南布依族苗族自治州","銅仁地區","遵義"},
{"海南","海口","三亞","直轄縣級行政區劃"},
{"河北","保定","滄州","承德","邯鄲","衡水","廊坊","秦皇島","石家莊","唐山","邢台","張家口"},
{"河南","安陽","鶴壁","焦作","開封","洛陽","漯河","南陽","平頂山","濮陽","三門峽","商丘","新鄉","信陽","許昌","鄭州","周口","駐馬店"},
{"黑龍江","大慶","大興安嶺地區","哈爾濱","鶴崗","黑河","雞西","佳木斯","牡丹江","七台河","齊齊哈爾","雙鴨山","綏化","伊春"},
{"湖北","鄂州","恩施土家族苗族自治州","黃岡","黃石","荊門","荊州","十堰","隨州","武漢","鹹寧","襄樊","孝感","宜昌"},
{"湖南","長沙","常德","郴州","衡陽","懷化","婁底","邵陽","湘潭","湘西土家族苗族自治州","益陽","永州","嶽陽","張家界","株洲"},
{"吉林","白城","白山","長春","吉林","遼源","四平","松原","通化","延邊北韓族自治州"},
{"江蘇","常州","淮安","連雲港","南京","南通","蘇州","宿遷","泰州","無錫","徐州","鹽城","揚州","鎮江"},
{"江西","撫州","贛州","吉安","景德鎮","九江","南昌","萍鄉","上饒","新余","宜春","鷹潭"},
{"遼寧","鞍山","本溪","朝陽","大連","丹東","撫順","阜新","葫蘆島","錦州","遼陽","盤錦","沈陽","鐵嶺","營口"},
{"內蒙古","阿拉善盟","巴彥淖爾","包頭","赤峰","鄂爾多斯","呼和浩特","呼倫貝爾","通遼","烏海","烏蘭察布","錫林郭勒盟","興安盟"},
{"寧夏回族","固原","石嘴山","吳忠","銀川","中衛"},
{"青海","果洛藏族自治州","海北藏族自治州","海東地區","海南藏族自治州","海西蒙古族藏族自治州","黃南藏族自治州","西寧","玉樹藏族自治州"},
{"山東","濱州","德州","東營","菏澤","濟南","濟寧","萊蕪","聊城","臨沂","青島","日照","泰安","威海","濰坊","煙台","棗莊","淄博"},
{"山西","長治","大同","晉城","晉中","臨汾","呂梁","朔州","太原","忻州","陽泉","運城"},
{"陜西","安康","寶雞","漢中","商洛","銅川","渭南","西安","鹹陽","延安","榆林"},
{"上海"},
{"四川","阿壩藏族羌族自治州","巴中","成都","達州","德陽","甘孜藏族自治州","廣安","廣元","樂山","涼山彜族自治州","瀘州","眉山","綿陽","內江","南充","攀枝花","遂寧","雅安","宜賓","資陽","自貢"},
{"西藏","阿裏地區","昌都地區","拉薩","林芝地區","那曲地區","日喀則地區","山南地區"},
{"新疆維吾爾","阿克蘇地區","阿勒泰地區","巴音郭楞蒙古自治州","博爾塔拉蒙古自治州","昌吉回族自治州","哈密地區","和田地區","喀什地區","克拉瑪依","克孜勒蘇柯爾克孜自治州","塔城地區","吐魯番地區","烏魯木齊","伊犁哈薩克自治州","直轄縣級行政區劃"},
{"雲南","保山","楚雄彜族自治州","大理白族自治州","德宏傣族景頗族自治州","迪慶藏族自治州","紅河哈尼族彜族自治州","昆明","麗江","臨滄","怒江僳僳族自治州","普洱","曲靖","文山壯族苗族自治州","西雙版納傣族自治州","玉溪","昭通"},
{"浙江","杭州","湖州","嘉興","金華","麗水","寧波","衢州","紹興","台州","溫州","舟山"},
{"重慶"},
{"台灣","台北","高雄","基隆","台中","台南","新竹","嘉義"},
};
}
5.2 分詞相關程式碼
pom檔:引入IK分詞器相關依賴
<!-- ikAnalyzer 中文分詞器 -->
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
<exclusions>
<exclusion>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- lucene-queryParser 查詢分析器模組 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>7.3.0</version>
</dependency>
IKAnalyzerSupport類:用於配置分詞器
@Slf4j
public classIKAnalyzerSupport{
/**
* IK分詞
* @param target
* @return
*/
publicstaticList<String>iKSegmenterToList(String target)throwsException{
if(StringUtils.isEmpty(target)){
returnnewArrayList();
}
List<String> result =newArrayList<>();
StringReadersr=newStringReader(target);
// false:關閉智慧分詞 (對分詞的精度影響較大)
IKSegmenterik=newIKSegmenter(sr,true);
Lexeme lex;
while((lex=ik.next())!=null){
StringlexemeText= lex.getLexemeText();
result.add(lexemeText);
}
return result;
}
}
ServiceImpl類:進行分詞處理
/**
* 對目標公司名稱進行分詞
* @param targetCompanyName
* @return
*/
privateStringsplitWord(String targetCompanyName){
log.info("對處理後端公司名稱進行分詞");
List<String> splitWord =newArrayList<>();
Stringresult= targetCompanyName;
try{
splitWord = iKSegmenterToList(targetCompanyName);
result = splitWord.stream().map(String::valueOf).distinct().collect(Collectors.joining("|"));
log.info("分詞結果:{}",result);
}catch(Exception e){
log.error("分詞報錯:{}",e.getMessage());
}
return result;
}
5.3 匹配
ServiceImpl類:匹配核心程式碼
public JsonResultmatchCompanyName(CompanyDTO companyDTO, String accessToken, String localIp){
// 對公司名稱進行處理
StringsourceCompanyName= companyDTO.getCompanyName();
StringtargetCompanyName= sourceCompanyName;
log.info("處理前公司名稱:{}",targetCompanyName);
// 處理圓括弧
targetCompanyName = targetCompanyName.replaceAll("[(]|[)]|[(]|[)]","");
// 處理公司相關關鍵詞
targetCompanyName = targetCompanyName.replaceAll("[(集團|股份|有限|責任|分公司)]","");
if(!targetCompanyName.contains("銀行")){
// 去除行政區域
targetCompanyName = formatCompanyName(targetCompanyName);
}
// 分詞
StringsplitCompanyName= splitWord(targetCompanyName);
// 匹配
List<Company> matchedCompany = companyRepository.queryMatchCompanyName(splitCompanyName,targetCompanyName);
List<String> result =newArrayList();
for(Company companyInfo : matchedCompany){
result.add(companyInfo.getCompanyName());
if(companyDTO.getCompanyId().equals(companyInfo.getCompanyId())){
result.remove(companyInfo.getCompanyName());
}
}
returnJsonResult.successResult(result);
}
Repository類:編寫SQL語句
/**
* 模糊匹配公司名稱
* @param companyNameRegex 分詞後的公司名稱
* @param companyName 分詞前的公司名稱
* @return
*/
@Query(value =
"SELECT * FROM company WHERE isDeleted = '0' and companyName REGEXP ?1
ORDER BY length(REPLACE(companyName,?2,''))/length(companyName) ",
nativeQuery = true)
List<Company> queryMatchCompanyName(String companyNameRegex,String companyName);
按照匹配度排序這個功能點,
LENGTH(companyName)
返回
companyName
的長度,
LENGTH(REPLACE(companyName, ?2, ''))
計算出
companyName
中關鍵詞出現的次數。透過這種方式,我們可以根據匹配程度進行排序,匹配次數越多的公司名稱排序越靠前。
👉 歡迎 ,你將獲得: 專屬的計畫實戰 / 1v1 提問 / Java 學習路線 / 學習打卡 / 每月贈書 / 社群討論
新計畫: 【從零手擼:仿小紅書(微服務架構)】 正在持續爆肝中,基於 Spring Cloud Alibaba + Spring Boot 3.x + JDK 17..., ;
【從零手擼:前後端分離部落格計畫(全棧開發)】 2期已完結,演示連結: http://116.62.199.48/ ;
截止目前, 累計輸出 48w+ 字,講解圖 2090+ 張,還在持續爆肝中.. 後續還會上新更多計畫,目標是將 Java 領域典型的計畫都整一波,如秒殺系統, 線上商城, IM 即時通訊,Spring Cloud Alibaba 等等,

1.
2.
3.
4.
最近面試BAT,整理一份面試資料【Java面試BATJ通關手冊】,覆蓋了Java核心技術、JVM、Java並行、SSM、微服務、資料庫、數據結構等等。
獲取方式:點「在看」,關註公眾號並回復 Java 領取,更多內容陸續奉上。
PS:因公眾號平台更改了推播規則,如果不想錯過內容,記得讀完點一下「在看」,加個「星標」,這樣每次新文章推播才會第一時間出現在你的訂閱列表裏。
點「在看」支持小哈呀,謝謝啦











