
👉 歡迎 ,你將獲得: 專屬的計畫實戰 / Java 學習路線 / 一對一提問 / 學習打卡 / 每月贈書
新計畫: 仿小紅書 (微服務架構)正在更新中... , 全棧前後端分離部落格計畫 2.0 版本完結啦, 演示連結 : http://116.62.199.48/ 。全程手摸手,後端 + 前端全棧開發,從 0 到 1 講解每個功能點開發步驟,1v1 答疑,直到計畫上線。 目前已更新了261小節,累計41w+字,講解圖:1806張,還在持續爆肝中.. 後續還會上新更多計畫,目標是將Java領域典型的計畫都整一波,如秒殺系統, 線上商城, IM即時通訊,Spring Cloud Alibaba 等等,
Mysql 的索引結構
Mysql 的查詢過程
Mysql 的 Limit 效能問題
那麽,有沒有辦法最佳化這個問題呢?
Limit 是一種常用的分頁查詢語句,它可以指定返回記錄行的偏移量和最大數目。例如,下面的語句表示從 test 表中查詢 val 等於4的記錄,並返回第300001到第300005條記錄:
select * from testwhere val=4 limit 300000,5;
這樣的語句看起來很簡單,但是在實際使用中,可能會出現效能問題。為什麽呢?我們需要從 Mysql 的索引結構和查詢過程來分析。
Mysql 的索引結構
Mysql 支持多種型別的索引,其中最常用的是 B+ 樹索引。B+ 樹索引是一種平衡多路尋找樹,它有以下特點:
樹中的每個節點最多包含 m 個子節點,m 被稱為 B+ 樹的階。
樹中的每個節點最少包含 m/2(向上取整)個子節點,除了根節點和葉子節點。
樹中的所有葉子節點都位於同一層,並且透過指標相連。
樹中的所有非葉子節點只儲存鍵值(索引列)和指向子節點的指標。
樹中的所有葉子節點儲存鍵值(索引列)和指向數據記錄(聚簇索引)或者數據記錄地址(非聚簇索引)的指標。
下圖是一個 B+ 樹索引的範例:
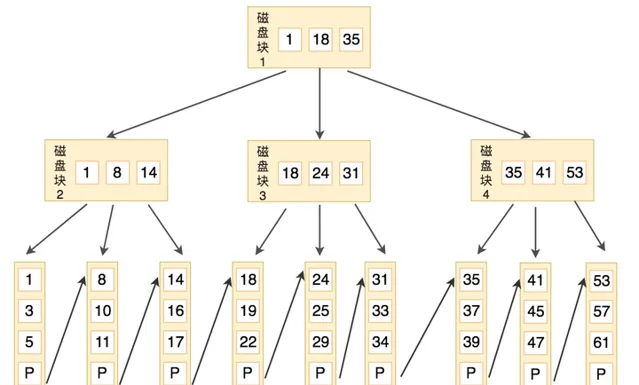
在 Mysql 中,有兩種常見的 B+ 樹索引:聚簇索引和非聚簇索引。
聚簇索引是一種特殊的 B+ 樹索引,它將數據記錄和索引放在一起儲存,也就是說,葉子節點就是數據記錄。在 Mysql 中,每張表只能有一個聚簇索引,通常是主鍵或者唯一非空鍵。如果沒有定義這樣的鍵,Mysql 會自動生成一個隱藏的聚簇索引。
非聚簇索引是一種普通的 B+ 樹索引,它將數據記錄和索引分開儲存,也就是說,葉子節點只儲存鍵值和指向數據記錄地址的指標。在 Mysql 中,每張表可以有多個非聚簇索引,通常是普通鍵或者唯一鍵。
下圖是一個聚簇索引和非聚簇索引的對比:
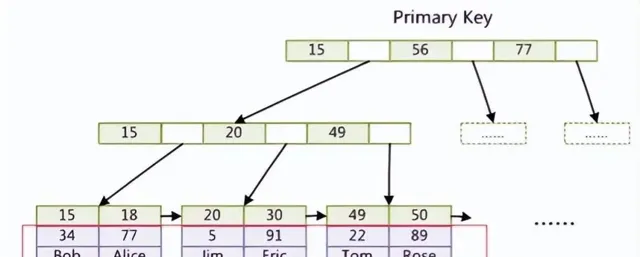
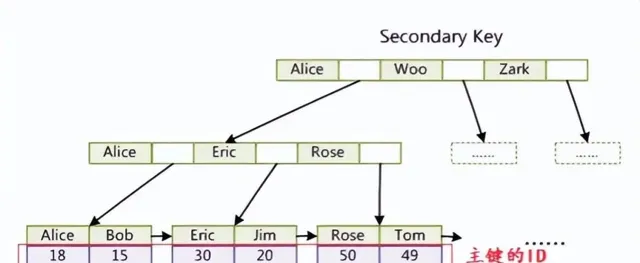
Mysql 的查詢過程
當我們執行一個 SQL 查詢語句時,Mysql 會根據最佳化器的選擇,使用不同的執行計劃來執行。其中,最常見的執行計劃有以下幾種:
全表掃描: 顧名思義,就是掃描整張表的所有數據記錄,逐條檢查是否滿足條件。這種執行計劃通常在沒有合適的索引或者條件過於復雜時使用。
索引掃描: 也稱為範圍掃描,就是根據條件在索引上進行尋找,並返回滿足條件的記錄。這種執行計劃通常在有合適的索引且條件較為簡單時使用。
索引覆蓋掃描: 也稱為索引只掃描,就是根據條件在索引上進行尋找,並返回滿足條件的記錄,但是不需要再存取數據記錄,因為查詢所需的所有欄位都在索引中。這種執行計劃通常在有合適的索引且查詢欄位較少時使用。
回表查詢: 也稱為索引尋找,就是根據條件在索引上進行尋找,並返回滿足條件的記錄,然後再根據索引指標去存取數據記錄,獲取查詢所需的其他欄位。這種執行計劃通常在有合適的索引但查詢欄位較多時使用。
下圖是一個回表查詢的範例:
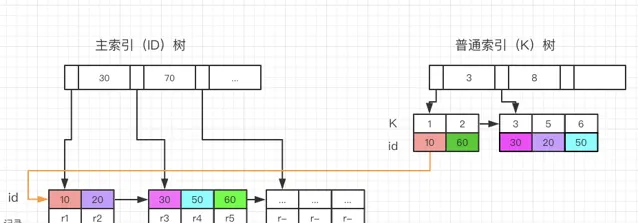
Mysql 的 Limit 效能問題
回到我們最開始的問題,Mysql 的 Limit 會影響效能嗎?為什麽?
答案是:會影響效能,因為 Limit 會導致 Mysql 掃描過多的數據記錄或者索引記錄,而且大部份掃描到的記錄都是無用的。
我們以一個非聚簇索引為例,來分析一下 Limit 的影響。假設我們有一張表 test ,它有兩個欄位 id 和 val ,其中 id 是主鍵,val 是非唯一非聚簇索引。表中有 500 萬條數據,val 的值從 1 到 10 隨機分布。我們執行以下語句:
select * from testwhere val=4 limit 300000,5;
這條語句的意思是查詢 val 等於 4 的記錄,並返回第 300001 到第 300005 條記錄。Mysql 會怎麽執行呢?
首先,Mysql 會選擇 val 索引作為執行計劃,因為它可以縮小查詢範圍。然後,Mysql 會從 val 索引的根節點開始尋找,沿著 B+ 樹向下搜尋,直到找到第一個 val 等於 4 的葉子節點。接著,Mysql 會沿著葉子節點的指標向右移動,掃描所有 val 等於 4 的葉子節點,並記錄它們對應的 id 值和數據記錄地址。
由於我們要返回第 300001 到第 300005 條記錄,所以 Mysql 必須掃描至少 300005 個葉子節點,才能確定哪些是我們需要的。這就導致了大量的隨機 I/O 操作,在磁盤上讀取索引頁。
接下來,Mysql 還要根據葉子節點指向的數據記錄地址,去存取數據頁,獲取查詢所需的所有欄位。由於我們要返回所有欄位(
select *
),所以 Mysql 必須存取至少 300005 次數據頁,才能獲取到完整的數據記錄。這又導致了大量的隨機 I/O 操作,在磁盤上讀取數據頁。
最後,Mysql 還要對掃描到的數據記錄進行排序和過濾,拋棄前面 300000 條無用的記錄,只保留後面 5 條有用的記錄。這就導致了大量的 CPU 和記憶體消耗,在記憶體中進行排序和過濾。
綜上所述,Mysql 在執行這條語句時,需要做以下操作:
掃描至少 300005 個索引頁
存取至少 300005 次數據頁
排序和過濾至少 300005 條數據記錄
這些操作都是非常耗時和耗資源和時間的浪費。為了返回 5 條有用的記錄,Mysql 不得不掃描和存取大量的無用的記錄。這就是 Limit 會影響效能的原因。
那麽,有沒有辦法最佳化這個問題呢?
答案是:有,但是需要根據具體的情況來選擇合適的方法。下面,我們介紹幾種常見的最佳化方法:
使用索引覆蓋掃描。
如果我們只需要查詢部份欄位,而不是所有欄位,我們可以嘗試使用索引覆蓋掃描,也就是讓查詢所需的所有欄位都在索引中,這樣就不需要再存取數據頁,減少了隨機 I/O 操作。
例如,如果我們只需要查詢 id 和 val 欄位,我們可以執行以下語句:
select id,val from testwhere val=4 limit 300000,5;
這樣,Mysql 只需要掃描索引頁,而不需要存取數據頁,提高了查詢效率。
使用子查詢。
如果我們不能使用索引覆蓋掃描,或者查詢欄位較多,我們可以嘗試使用子查詢,也就是先用一個子查詢找出我們需要的記錄的 id 值,然後再用一個主查詢根據 id 值獲取其他欄位。
例如,我們可以執行以下語句:
select * from testwhere id in (select id from testwhere val=4 limit 300000,5);
這樣,Mysql 先執行子查詢,在 val 索引上進行範圍掃描,並返回 5 個 id 值。然後,Mysql 再執行主查詢,在 id 索引上進行點尋找,並返回所有欄位。這樣,Mysql 只需要掃描 5 個數據頁,而不是 300005 個數據頁,提高了查詢效率。
使用分區表。
如果我們的表非常大,或者數據分布不均勻,我們可以嘗試使用分區表,也就是將一張大表分成多個小表,並按照某個欄位或者範圍進行劃分。這樣,Mysql 可以根據條件只存取部份分區表,而不是整張表,減少了掃描和存取的數據量。
例如,如果我們按照 val 欄位將 test 表分成 10 個分區表(test_1 到 test_10),每個分區表只儲存 val 等於某個值的記錄,我們可以執行以下語句:
select * from test_4 limit 300000,5;
這樣,Mysql 只需要存取 test_4 這個分區表,而不需要存取其他分區表,提高了查詢效率。
👉 歡迎 ,你將獲得: 專屬的計畫實戰 / Java 學習路線 / 一對一提問 / 學習打卡 / 每月贈書
新計畫: 仿小紅書 (微服務架構)正在更新中... , 全棧前後端分離部落格計畫 2.0 版本完結啦, 演示連結 : http://116.62.199.48/ 。全程手摸手,後端 + 前端全棧開發,從 0 到 1 講解每個功能點開發步驟,1v1 答疑,直到計畫上線。 目前已更新了261小節,累計41w+字,講解圖:1806張,還在持續爆肝中.. 後續還會上新更多計畫,目標是將Java領域典型的計畫都整一波,如秒殺系統, 線上商城, IM即時通訊,Spring Cloud Alibaba 等等,

1.
2.
3.
4.
最近面試BAT,整理一份面試資料【Java面試BATJ通關手冊】,覆蓋了Java核心技術、JVM、Java並行、SSM、微服務、資料庫、數據結構等等。
獲取方式:點「在看」,關註公眾號並回復 Java 領取,更多內容陸續奉上。
PS:因公眾號平台更改了推播規則,如果不想錯過內容,記得讀完點一下「在看」,加個「星標」,這樣每次新文章推播才會第一時間出現在你的訂閱列表裏。
點「在看」支持小哈呀,謝謝啦











