點選關註公眾號,Java幹貨 及時送達 👇

在排查線上異常的過程中,查詢日誌總是必不可缺的一部份。現今大多采用的微服務架構,日誌被分散在不同的機器上,使得日誌的查詢變得異常困難。
工欲善其事,必先利其器。如果此時有一個統一的即時日誌分析平台,那可謂是雪中送碳,必定能夠提高我們排查線上問題的效率。本文帶您了解一下開源的即時日誌分析平台 ELK 的搭建及使用。
ELK 簡介
ELK 是一個開源的即時日誌分析平台,它主要由 Elasticsearch、Logstash 和 Kiabana 三部份組成。
Logstash
Logstash 主要用於收集伺服器日誌,它是一個開源數據收集引擎,具有即時管道功能。Logstash 可以動態地將來自不同資料來源的數據統一起來,並將數據標準化到您所選擇的目的地。
Logstash 收集數據的過程主要分為以下三個部份:
輸入:數據(包含但不限於日誌)往往都是以不同的形式、格式儲存在不同的系統中,而 Logstash 支持從多種資料來源中收集數據(File、Syslog、MySQL、訊息中介軟體等等)。
過濾器:即時解析和轉換數據,辨識已命名的欄位以構建結構,並將它們轉換成通用格式。
輸出:Elasticsearch 並非儲存的唯一選擇,Logstash 提供很多輸出選擇。
Elasticsearch
Elasticsearch (ES)是一個分布式的 Restful 風格的搜尋和數據分析引擎,它具有以下特點:
查詢:允許執行和合並多種型別的搜尋 — 結構化、非結構化、地理位置、度量指標 — 搜尋方式隨心而變。
分析:Elasticsearch 聚合讓您能夠從大處著眼,探索數據的趨勢和模式。
速度:很快,可以做到億萬級的數據,毫秒級返回。
可延伸性:可以在膝上型電腦上執行,也可以在承載了 PB 級數據的成百上千台伺服器上執行。
彈性:執行在一個分布式的環境中,從設計之初就考慮到了這一點。
靈活性:具備多個案例場景。支持數位、文本、地理位置、結構化、非結構化,所有的數據型別都歡迎。
Kibana
Kibana 可以使海量數據通俗易懂。它很簡單,基於瀏覽器的界面便於您快速建立和分享動態數據儀表板來追蹤 Elasticsearch 的即時數據變化。其搭建過程也十分簡單,您可以分分鐘完成 Kibana 的安裝並開始探索 Elasticsearch 的索引數據 — 沒有程式碼、不需要額外的基礎設施。
對於以上三個元件在 【ELK 協定棧介紹及體系結構】 一文中有具體介紹,這裏不再贅述。
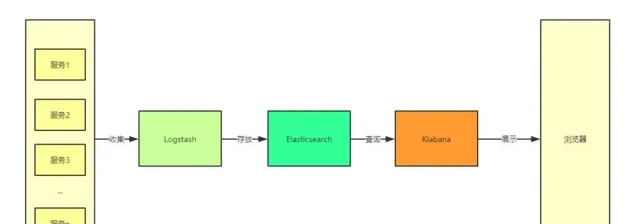
在 ELK 中,三大元件的大概工作流程如下圖所示,由 Logstash 從各個服務中采集日誌並存放至 Elasticsearch 中,然後再由 Kiabana 從 Elasticsearch 中查詢日誌並展示給終端使用者。
圖 1. ELK 的大致工作流程
ELK 實作方案
通常情況下我們的服務都部署在不同的伺服器上,那麽如何從多台伺服器上收集日誌資訊就是一個關鍵點了。本篇文章中提供的解決方案如下圖所示:
圖 2. 本文提供的 ELK 實作方案
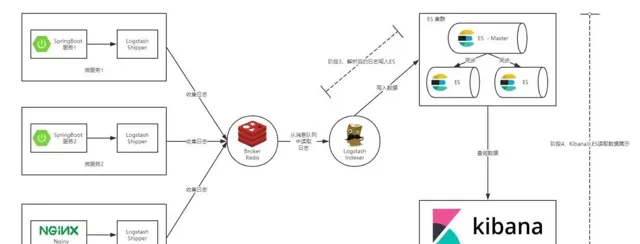
如上圖所示,整個 ELK 的執行流程如下:
在微服務(產生日誌的服務)上部署一個 Logstash,作為 Shipper 角色,主要負責對所在機器上的服務產生的日誌檔進行數據采集,並將訊息推播到 Redis 訊息佇列。
另用一台伺服器部署一個 Indexer 角色的 Logstash,主要負責從 Redis 訊息佇列中讀取數據,並在 Logstash 管道中經過 Filter 的解析和處理後輸出到 Elasticsearch 集群中儲存。
Elasticsearch 主副節點之間數據同步。
單獨一台伺服器部署 Kibana 讀取 Elasticsearch 中的日誌數據並展示在 Web 頁面。
透過這張圖,相信您已經大致清楚了我們將要搭建的 ELK 平台的工作流程,以及所需元件。下面就讓我們一起開始搭建起來吧。
ELK 平台搭建
本節主要介紹搭建 ELK 日誌平台,包括安裝 Indexer 角色的 Logstash,Elasticsearch 以及 Kibana 三個元件。完成本小節,您需要做如下準備:
一台 Ubuntu 機器或虛擬機器,作為入門教程,此處省略了 Elasticsearch 集群的搭建,且將 Logstash(Indexer)、Elasticsearch 以及 Kibana 安裝在同一機器上。
在 Ubuntu 上安裝 JDK,註意 Logstash 要求 JDK 在 1.7 版本以上。
Logstash、Elasticsearch、Kibana 安裝包,您可以在 此頁面 下載。
安裝 Logstash
解壓壓縮包:
tar -xzvf logstash-7.3.0.tar.gz
顯示更多簡單用例測試,進入到解壓目錄,並啟動一個將控制台輸入輸出到控制台的管道。
cd logstash-7.3.0
elk@elk:~/elk/logstash-7.3.0$ bin/logstash -e 'input { stdin {} } output { { stdout {} } }'
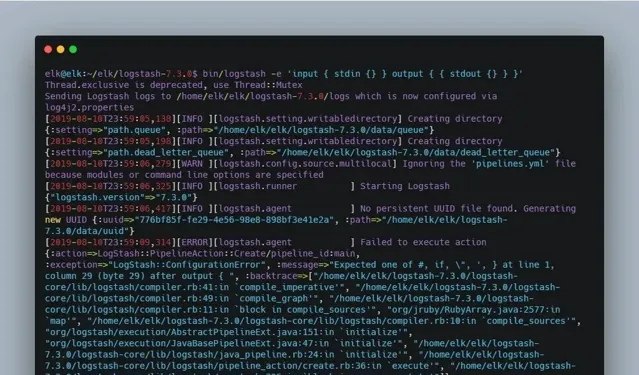
顯示更多看到如下日誌就意味著 Logstash 啟動成功。
圖 3. Logstash 啟動成功日誌
在控制台輸入 Hello Logstash ,看到如下效果代表 Logstash 安裝成功。
清單 1. 驗證 Logstash 是否啟動成功Hello Logstash
{
"@timestamp" => 2019-08-10T16:11:10.040Z,
"host" => "elk",
"@version" => "1",
"message" => "Hello Logstash"
}
安裝 Elasticsearch
解壓安裝包:
tar -xzvf elasticsearch-7.3.0-linux-x86_64.tar.gz
啟動 Elasticsearch:
cd elasticsearch-7.3.0/
bin/elasticsearch
在啟動 Elasticsearch 的過程中我遇到了兩個問題在這裏列舉一下,方便大家排查。
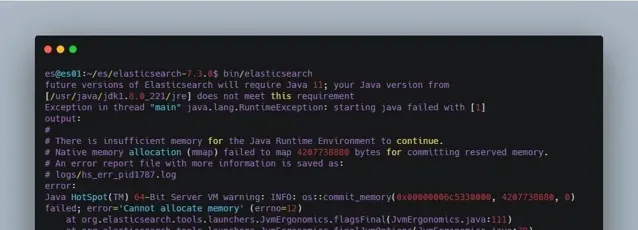
問題一 :記憶體過小,如果您的機器記憶體小於 Elasticsearch 設定的值,就會報下圖所示的錯誤。解決方案是,修改 elasticsearch-7.3.0/config/jvm.options 檔中的如下配置為適合自己機器的記憶體大小,若修改後還是報這個錯誤,可重新連線伺服器再試一次。
圖 4. 記憶體過小導致 Elasticsearch 啟動報錯
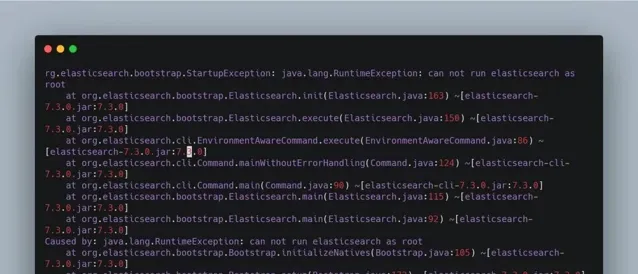
問題二 ,如果您是以 root 使用者啟動的話,就會報下圖所示的錯誤。解決方案自然就是添加一個新使用者啟動 Elasticsearch,至於添加新使用者的方法網上有很多,這裏就不再贅述。
圖 5. Root 使用者啟動 Elasticsearch 報錯
啟動成功後,另起一個會話視窗執行 curl http://localhost:9200 命令,如果出現如下結果,則代表 Elasticsearch 安裝成功。
清單 2. 檢查 Elasticsearch 是否啟動成功
elk@elk:~$ curl http://localhost:9200
{
"name" : "elk",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "hqp4Aad0T2Gcd4QyiHASmA",
"version" : {
"number" : "7.3.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "de777fa",
"build_date" : "2019-07-24T18:30:11.767338Z",
"build_snapshot" : false,
"lucene_version" : "8.1.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
安裝 Kibana
解壓安裝包:
tar -xzvf kibana-7.3.0-linux-x86_64.tar.gz
修改配置檔 config/kibana.yml ,主要指定 Elasticsearch 的資訊。
清單 3. Kibana 配置資訊#Elasticsearch主機地址
elasticsearch.hosts: "http://ip:9200"
# 允許遠端存取
server.host: "0.0.0.0"
# Elasticsearch使用者名稱 這裏其實就是我在伺服器啟動Elasticsearch的使用者名稱
elasticsearch.username: "es"
# Elasticsearch鑒權密碼 這裏其實就是我在伺服器啟動Elasticsearch的密碼
elasticsearch.password: "es"
啟動 Kibana:
cd kibana-7.3.0-linux-x86_64/bin
./kibana
在瀏覽器中存取 http://ip:5601 ,若出現以下界面,則表示 Kibana 安裝成功。
圖 6. Kibana 啟動成功界面

ELK 日誌平台安裝完成後,下面我們就將透過具體的例子來看下如何使用 ELK,下文將分別介紹如何將 和 Nginx 日誌交由 ELK 分析。
在 Spring Boot 中使用 ELK
首先我們需要建立一個 Spring Boot 的計畫,之前我寫過一篇文章介紹 如何使用 AOP 來統一處理 Spring Boot 的 Web 日誌 ,本文的 Spring Boot 計畫就建立在這篇文章的基礎之上。
修改並部署 Spring Boot 計畫
在計畫 resources 目錄下建立 spring-logback.xml 配置檔。
清單 4. Spring Boot 計畫 Logback 的配置
<?xml version="1.0" encoding="UTF-8"?>
<configuration debug="false">
<contextName>Logback For demo Mobile</contextName>
<property name="LOG_HOME" value="/log" />
<springProperty scope="context" name="appName"source="spring.application.name"
defaultValue="localhost" />
...
<appender name="ROLLING_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
...
<encoder class="ch.qos.logback. classic.encoder.PatternLayoutEncoder">
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{25} ${appName} -%msg%n</pattern>
</encoder>
...
</appender>
...
</configuration>
以上內容省略了很多內容,您可以在源碼中獲取。在上面的配置中我們定義了一個名為 ROLLING_FILE 的 Appender 往日誌檔中輸出指定格式的日誌。而上面的 pattern 標簽正是具體日誌格式的配置,透過上面的配置,我們指定輸出了時間、執行緒、日誌級別、logger(通常為日誌打印所在類的全路徑)以及服務名稱等資訊。
將計畫打包,並部署到一台 Ubuntu 伺服器上。
清單 5. 打包並部署 Spring Boot 計畫
# 打包命令
mvn package -Dmaven.test.skip=true
# 部署命令
java -jar sb-elk-start-0.0.1-SNAPSHOT.jar
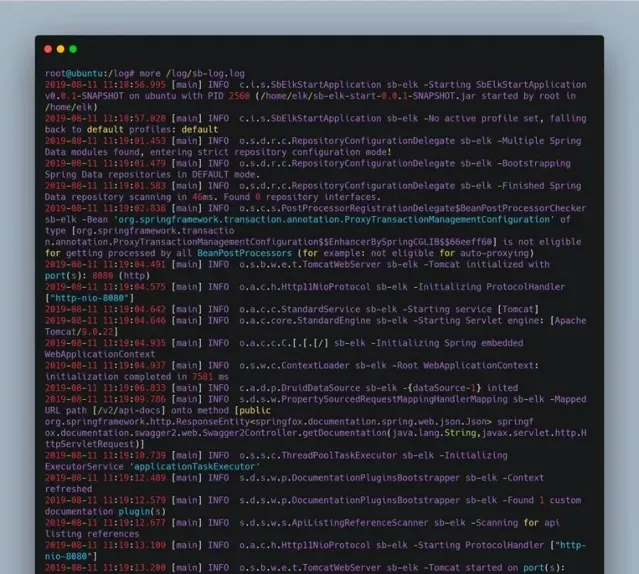
檢視日誌檔, logback 配置檔中我將日誌存放在 /log/sb-log.log 檔中,執行 more /log/sb-log.log 命令,出現以下結果表示部署成功。
圖 7. Spring Boot 日誌檔
配置 Shipper 角色 Logstash
Spring Boot 計畫部署成功之後,我們還需要在當前部署的機器上安裝並配置 Shipper 角色的 Logstash。Logstash 的安裝過程在 ELK 平台搭建小節中已有提到,這裏不再贅述。
安裝完成後,我們需要編寫 Logstash 的配置檔,以支持從日誌檔中收集日誌並輸出到 Redis 訊息管道中,Shipper 的配置如下所示。
清單 6. Shipper 角色的 Logstash 的配置
input {
file {
path => [
# 這裏填寫需要監控的檔
"/log/sb-log.log"
]
}
}
output {
# 輸出到redis
redis {
host => "10.140.45.190"# redis主機地址
port => 6379 # redis埠號
db => 8 # redis資料庫編號
data_type => "channel"# 使用釋出/訂閱模式
key => "logstash_list_0"# 釋出通道名稱
}
}
其實 Logstash 的配置是與前面提到的 Logstash 管道中的三個部份(輸入、過濾器、輸出)一一對應的,只不過這裏我們不需要過濾器所以就沒有寫出來。上面配置中 Input 使用的資料來源是檔型別的,只需要配置上需要收集的本機日誌檔路徑即可。Output 描述數據如何輸出,這裏配置的是輸出到 Redis。
Redis 的配置 data_type 可選值有 channel 和 list 兩個。channel 是 Redis 的釋出/訂閱通訊模式,而 list 是 Redis 的佇列數據結構,兩者都可以用來實作系統間有序的訊息異步通訊。
channel 相比 list 的好處是,解除了釋出者和訂閱者之間的耦合。舉個例子,一個 Indexer 在持續讀取 Redis 中的記錄,現在想加入第二個 Indexer,如果使用 list ,就會出現上一條記錄被第一個 Indexer 取走,而下一條記錄被第二個 Indexer 取走的情況,兩個 Indexer 之間產生了競爭,導致任何一方都沒有讀到完整的日誌。
channel 就可以避免這種情況。這裏 Shipper 角色的配置檔和下面將要提到的 Indexer 角色的配置檔中都使用了 channel 。
配置 Indexer 角色 Logstash
配置好 Shipper 角色的 Logstash 後,我們還需要配置 Indexer 角色 Logstash 以支持從 Redis 接收日誌數據,並透過過濾器解析後儲存到 Elasticsearch 中,其配置內容如下所示。
清單 7. Indexer 角色的 Logstash 的配置
input {
redis {
host => "192.168.142.131"# redis主機地址
port => 6379 # redis埠號
db => 8 # redis資料庫編號
data_type => "channel"# 使用釋出/訂閱模式
key => "sb-logback"# 釋出通道名稱
}
}
filter {
#定義數據的格式
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:time} \[%{NOTSPACE:threadName}\] %{LOGLEVEL:level} %{DATA:logger} %{NOTSPACE:applicationName} -(?:.*=%{NUMBER:timetaken}ms|)"}
}
}
output {
stdout {}
elasticsearch {
hosts => "localhost:9200"
index => "logback"
}
}
與 Shipper 不同的是,Indexer 的管道中我們定義了過濾器,也正是在這裏將日誌解析成結構化的數據。下面是我截取的一條 logback 的日誌內容:
清單 8. Spring Boot 計畫輸出的一條日誌
2019-08-11 18:01:31.602 [http-nio-8080-exec-2] INFO c.i.s.aop.WebLogAspect sb-elk -介面日誌
POST請求測試介面結束呼叫:耗時=11ms,result=BaseResponse{code=10000, message='操作成功'}
在 Filter 中我們使用 Grok 外掛程式從上面這條日誌中解析出了時間、執行緒名稱、Logger、服務名稱以及介面耗時幾個欄位。Grok 又是如何工作的呢?
message 欄位是 Logstash 存放收集到的數據的欄位, match = {"message" => ...} 代表是對日誌內容做處理。
Grok 實際上也是透過正規表式來解析數據的,上面出現的 TIMESTAMP_ISO8601 、 NOTSPACE 等都是 Grok 內建的 patterns。
我們編寫的解析字串可以使用 Grok Debugger 來測試是否正確,這樣避免了重復在真實環境中校驗解析規則的正確性。
檢視效果
經過上面的步驟,我們已經完成了整個 ELK 平台的搭建以及 Spring Boot 計畫的接入。下面我們按照以下步驟執行一些操作來看下效果。
啟動 Elasticsearch,啟動命令在 ELK 平台搭建 小節中有提到,這裏不贅述(Kibana 啟動同)。啟動 Indexer 角色的 Logstash。
# 進入到 Logstash 的解壓目錄,然後執行下面的命令
bin/logstash -f indexer-logstash.conf
啟動 Kibana。
啟動 Shipper 角色的 Logstash。
# 進入到 Logstash 的解壓目錄,然後執行下面的命令
bin/logstash -f shipper-logstash.conf
呼叫 Spring Boot 介面,此時應該已經有數據寫入到 ES 中了。
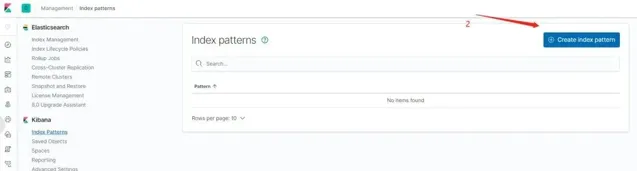
在瀏覽器中存取 http://ip:5601 ,開啟 Kibana 的 Web 界面,並且如下圖所示添加 logback 索引。
圖 8. 在 Kibana 中添加 Elasticsearch 索引
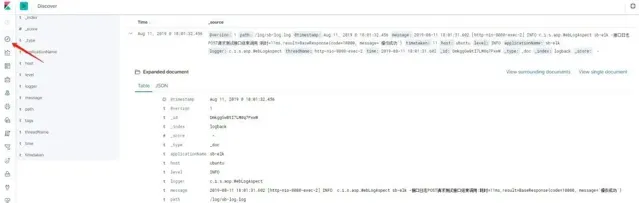
進入 Discover 界面,選擇 logback 索引,就可以看到日誌數據了,如下圖所示。
圖 9. ELK 日誌檢視
在 Nginx 中使用 ELK
相信透過上面的步驟您已經成功的搭建起了自己的 ELK 即時日誌平台,並且接入了 Logback 型別的日誌。但是實際場景下,幾乎不可能只有一種型別的日誌,下面我們就再在上面步驟的基礎之上接入 Nginx 的日誌。
當然這一步的前提是我們需要在伺服器上安裝 Nginx,具體的安裝過程網上有很多介紹,這裏不再贅述。檢視 Nginx 的日誌如下(Nginx 的存取日誌預設在 /var/log/nginx/access.log 檔中)。
清單 9. Nginx 的存取日誌
192.168.142.1 - - [17/Aug/2019:21:31:43 +0800] "GET /weblog/get-test?name=elk HTTP/1.1"
200 3 "http://192.168.142.131/swagger-ui.html""Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"
同樣,我們需要為此日誌編寫一個 Grok 解析規則,如下所示:
清單 10. 針對 Nginx 存取日誌的 Grok 解析規則
%{IPV4:ip} \- \- \[%{HTTPDATE:time}\] "%{NOTSPACE:method} %{DATA:requestUrl}
HTTP/%{NUMBER:httpVersion}" %{NUMBER:httpStatus} %{NUMBER:bytes}
"%{DATA:referer}""%{DATA:agent}"
完成上面這些之後的關鍵點是 Indexer 型別的 Logstash 需要支持兩種型別的輸入、過濾器以及輸出,如何支持呢?首先需要給輸入指定型別,然後再根據不同的輸入型別走不同的過濾器和輸出,如下所示。
清單 11. 支持兩種日誌輸入的 Indexer 角色的 Logstash 配置
input {
redis {
type => "logback"
...
}
redis {
type => "nginx"
...
}
}
filter {
if [type] == "logback" {
...
}
if [type] == "nginx" {
...
}
}
output {
if [type] == "logback" {
...
}
if [type] == "nginx" {
...
}
}
我的 Nginx 與 Spring Boot 計畫部署在同一台機器上,所以還需修改 Shipper 型別的 Logstash 的配置以支持兩種型別的日誌輸入和輸出,其配置檔的內容可 點選這裏獲取。
以上配置完成後,我們按照 檢視效果 章節中的步驟,啟動 ELK 平台、Shipper 角色的 Logstash、Nginx 以及 Spring Boot 計畫,然後在 Kibana 上添加 Nignx 索引後就可同時檢視 Spring Boot 和 Nginx 的日誌了,如下圖所示。
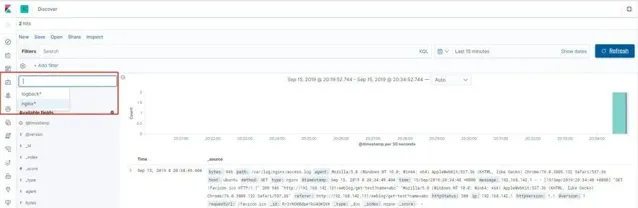
圖 10. ELK 檢視 Nginx 日誌
ELK 啟動
在上面的步驟中,ELK 的啟動過程是我們一個一個的去執行三大元件的啟動命令的。而且還是在前台啟動的,意味著如果我們關閉會話視窗,該元件就會停止導致整個 ELK 平台無法使用,這在實際工作過程中是不現實的,我們剩下的問題就在於如何使 ELK 在背景執行。
根據 【Logstash 最佳實踐】 一書的推薦,我們將使用 Supervisor 來管理 ELK 的啟停。首先我們需要安裝 Supervisor,在 Ubuntu 上執行 apt-get install supervisor 即可。安裝成功後,我們還需要在 Supervisor 的配置檔中配置 ELK 三大元件(其配置檔預設為 /etc/supervisor/supervisord.conf 檔)。
清單 12. ELK 後台啟動
[program:elasticsearch]
environment=JAVA_HOME="/usr/java/jdk1.8.0_221/"
directory=/home/elk/elk/elasticsearch
user=elk
command=/home/elk/elk/elasticsearch/bin/elasticsearch
[program:logstash]
environment=JAVA_HOME="/usr/java/jdk1.8.0_221/"
directory=/home/elk/elk/logstash
user=elk
command=/home/elk/elk/logstash/bin/logstash -f /home/elk/elk/logstash/indexer-logstash.conf
[program:kibana]
environment=LS_HEAP_SIZE=5000m
directory=/home/elk/elk/kibana
user=elk
command=/home/elk/elk/kibana/bin/kibana
按照以上內容配置完成後,執行 sudo supervisorctl reload 即可完成整個 ELK 的啟動,而且其預設是開機自啟。當然,我們也可以使用 sudo supervisorctl start/stop [program_name] 來管理單獨的套用。
結束語
在本教程中,我們主要了解了什麽是 ELK,然後透過實際操作和大家一起搭建了一個 ELK 日誌分析平台,並且接入了 Logback 和 Nginx 兩種日誌。
來源:https://blog.csdn.net/JAVABBQ
W E/article/details/118825321
END
看完本文有收獲?請轉發分享給更多人
關註「Java編程鴨」,提升Java技能
關註Java編程鴨微信公眾號,後台回復:碼農大禮包可以獲取最新整理的技術資料一份。涵蓋Java 框架學習、架構師學習等!
文章有幫助的話,在看,轉發吧。
謝謝支持喲 (*^__^*)











