
連結:https://blog.51cto.com/u_11555417/5680563
老版本的kubernetes集群,容器執行時使用的是docker,經常會出現集群執行很久後節點的硬碟快跑滿了,大檔主要集中在:/var/lib/dokcer/ovlery2,該目錄下檔有塊70G,/var/log/或者/var/log/journal下也有大日誌檔占用空間。此時需要及時清理,不然會導致集群異常。
磁盤爆滿
容器執行時使用的目錄所在磁盤爆滿
如果容器執行時使用的目錄所在空間爆滿,極有可能導致容器執行時無響應,例如docker相關命令會hang住,kubelet 日誌也將看到 PLEG unhealthy,而 CRI 呼叫 timeout 也將導致容器無法建立或銷毀,外在現象通常表現為 Pod 一直 ContainerCreating 或一直 Terminating。
docker 預設使用的目錄
/var/run/docker:用於儲存容器執行狀態,透過 dockerd 的--exec-root 參數指定。
/var/lib/docker:用於持久化容器相關的數據。例如,容器映像、容器可寫層數據、容器標準日誌輸出及透過 docker 建立的 volume 等。
故障現象
Pod 在啟動過程中,可能會出現以下類似事件
#pod啟動過程事件Warning FailedCreatePodSandBox 53m kubelet, 172.22.0.44 Failed create pod sandbox: rpc error: code = DeadlineExceeded desc = context deadline exceededWarning FailedCreatePodSandBox 2m (x4307 over 16h) kubelet, 10.179.80.31 (combined from similar events): Failed create pod sandbox: rpc error: code = Unknown desc = failed to create a sandbox for pod "apigateway-6dc48bf8b6-l8xrw": Error response from daemon: mkdir /var/lib/docker/aufs/mnt/1f09d6c1c9f24e8daaea5bf33a4230de7dbc758e3b22785e8ee21e3e3d921214-init: no space left on deviceWarning Failed 5m1s (x3397 over 17h) kubelet, ip-10-0-151-35.us-west-2.compute.internal (combined from similar events): Error: container create failed: container_linux.go:336: starting container process caused "process_linux.go:399: container init caused \"rootfs_linux.go:58: mounting \\\"/sys\\\" to rootfs \\\"/var/lib/dockerd/storage/overlay/051e985771cc69f3f699895a1dada9ef6483e912b46a99e004af7bb4852183eb/merged\\\" at \\\"/var/lib/dockerd/storage/overlay/051e985771cc69f3f699895a1dada9ef6483e912b46a99e004af7bb4852183eb/merged/sys\\\" caused \\\"no space left on device\\\"\""#pod刪除過程事件Normal Killing 39s (x735 over 15h) kubelet, 10.179.80.31 Killing container with id docker://apigateway:Need to kill Pod
kubelet使用的目錄爆滿
預設的kubelet的目錄為/var/lib/kubelet,透過 kubelet 的 --root-dir 參數指定,用於儲存外掛程式資訊、Pod 相關的狀態以及掛載的 volume
故障現象
Kubelet 使用的目錄所在磁盤空間爆滿(通常是系統槽),新建 Pod 時無法成功進行 mkdir,導致 Sandbox 也無法建立成功,Pod 通常會出現以下類似事件:
Warning UnexpectedAdmissionError 44m kubelet, 172.22.0.44 Update plugin resources failed due to failed to write checkpoint file "kubelet_internal_checkpoint": write /var/lib/kubelet/device-plugins/.728425055: no space left on device, which is unexpected.
解決辦法
當容器執行時為 docker 時發生磁盤爆滿問題,dockerd 也會因此無法正常響應,在停止時會卡住,從而導致無法直接重新開機 dockerd 來釋放空間。需要先手動清理部份檔騰出空間以確保 dockerd 能夠停止並重新開機。恢復步驟如下:
手動刪除 docker 的部份 log 檔或可寫層檔。通常刪除 log 檔,範例如下:
$ cd /var/lib/docker/containers$ du -sh * # 找到比較大的目錄$ cd dda02c9a7491fa797ab730c1568ba06cba74cecd4e4a82e9d90d00fa11de743c$ cat /dev/null > dda02c9a7491fa797ab730c1568ba06cba74cecd4e4a82e9d90d00fa11de743c-json.log.9 # 刪除log檔
說明:
刪除檔時,建議使用cat /dev/null > 方式進行刪除,不建議使用rm。使用rm 方式刪除的檔,不能夠被 docker 行程釋放掉,該檔所占用的空間也就不會被釋放。
log 的字尾數位越大表示時間越久遠,建議優先刪除舊日誌。
2 執行以下命令,將該 Node 標記為不可排程,並將其已有的 Pod 驅逐到其它節點。
kubectl drain <node-name>
該步驟可以確保 dockerd 重新開機時將原節點上 Pod 對應的容器刪掉,同時確保容器相關的日誌(標準輸出)與容器內產生的數據檔(未掛載 volume 及可寫層)也會被清理。
3 重新開機docker
systemctl restart dockerd# or systemctl restart docker
4等待 dockerd 重新開機恢復,Pod 排程到其它節點後,排查磁盤爆滿原因並進行數據清理和規避操作。
5執行以下命令,取消節點不可排程標記。
清理docker映像
在日常運維工作中,為了規避磁盤爆滿的情況,需要及時清理docker映像來時放磁盤空間。
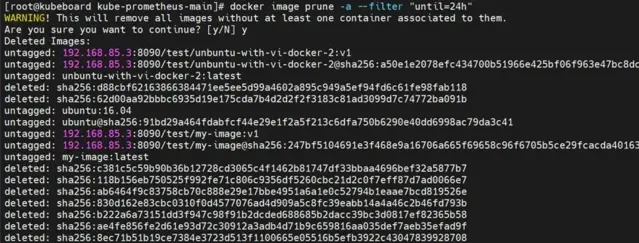
以下是docker原生命令來清理映像
journalctl --vacuum-size=20M #設定journal 日誌最大為20M不保留不必要日誌。docker image prune -a --filter "until=24h" # 清除超過建立時間超過24小時的映像docker container prune --filter "until=24h" #清除掉所有停掉的容器,但24內建立的除外docker volume prune --filter "label!=keep" #除lable=keep外的volume外都清理掉(沒有參照的volume)docker system prune #清理everything:images ,containers,networks一次性清理操作可以透過docker system prune來搞定
k8s垃圾回收機制
Kubelet 垃圾回收(kubelet-garbage-collection)負責自動清理節點上的無用映像和容器。
映像回收
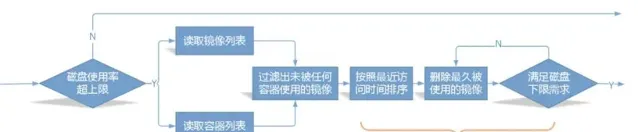
Kubernetes 對節點上的所有映像提供生命周期管理服務,這裏的所有映像是真正意義上的所有映像,不僅僅是透過 Kubelet 拉取的映像。當磁盤使用率超過設定上限 HighThresholdPercent 時,Kubelet 就會按照 LRU 清除策略逐個清理掉那些沒有被任何 Pod 容器(包括已經死亡的容器)所使用的映像,直到磁盤使用率降到設定下限 LowThresholdPercent 或沒有空閑映像可以清理。此外,在進行映像清理時,會考慮映像的生存年齡,對於年齡沒有達到最短生存年齡 MinAge 要求的映像,暫不予以清理。
影響垃圾回收的關鍵參數
--image-gc-high-threshold:磁盤使用率上限,有效範圍 [0-100],預設 85--image-gc-low-threshold:磁盤使用率下限,有效範圍 [0-100],預設 80--minimum-image-ttl-duration:映像最短應該生存的年齡,預設 2 分鐘
配置舉例
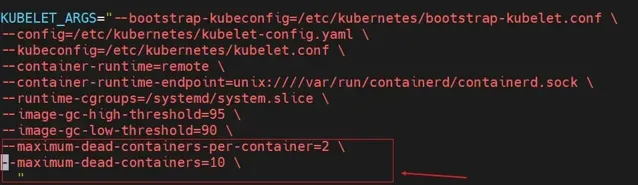
k8s版本1.24,主要是更改node節點的kubelet參數
vim /etc/kubernetes kubelet.env

增加啟動參數,然後重新開機kubelet
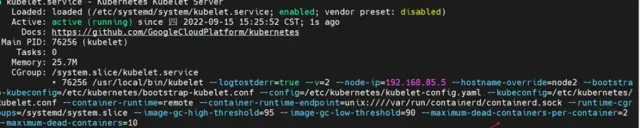
systemctl restart kubeletsystemctl status kubelet -fl
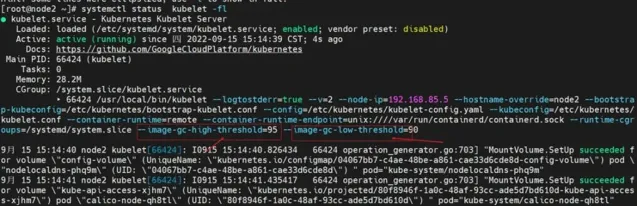
確認參數配置上去
容器回收
容器在停止執行(比如出錯結束或者正常結束)後會殘留一系列的垃圾檔,一方面會占據磁盤空間,另一方面也會影響系統執行速度。此時,就需要 Kubelet 容器回收了。要特別註意的是,Kubelet 回收的容器是指那些由其管理的的容器(也就是 Pod 容器),使用者手動執行的容器不會被 Kubelet 進行垃圾回收。
容器回收主要針對三個目標資源:普通容器、sandbox 容器以及容器日誌目錄。
MaxPerPodContainer 與 MaxContainers 的設定,按照 LRU 策略,從 Pod 的死亡容器列表刪除一定數量的容器,直到滿足配置需求;對於 sandbox 容器,按照每個 Pod 保留一個的原則清理多余的死亡 sandbox;對於日誌目錄,只要沒有 Pod 與之關聯了就將其刪除。Kubelet 的容器垃圾回收只針對 Pod 容器,非 Kubelet Pod 容器(比如透過 docker run 啟動的容器)不會被主動清理。
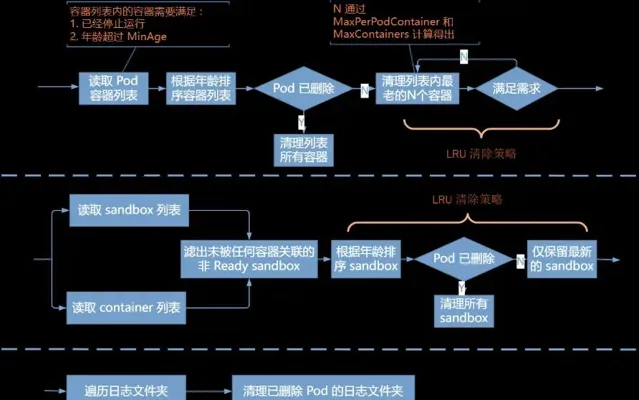
影響容器垃圾回收的相關控制參數主要有三個:
--minimum-container-ttl-duration:從容器停止執行時起經過設定時間後,該容器標記為已過期將來可以被回收(只是標記,不是回收),預設值為1m0s # 1.22.5 不支持--maximum-dead-containers-per-container:每個 pod 上可以留下執行結束之後的容器的個數,預設值為 2--maximum-dead-containers:節點可保留的死亡容器的最大數量,預設值是 -1,這意味著節點沒有限制死亡容器數量
關於kubelet的詳細參數設定,請檢視官方文件。
kubelet | Kubernetes











