點選上方↑↑↑「OpenCV學堂」關註我
來源:公眾號 新智元授權
【導讀】 新的一年,PyTorch也迎來了重大更新,PyTorch 2.2整合了FlashAttention-2和AOTInductor等新特性,計算效能翻倍。
新的一年,PyTorch也迎來了重大更新!
繼去年十月份的PyTorch大會釋出了2.1版本之後,全世界各地的521位開發者貢獻了3628個送出,由此形成了最新的PyTorch 2.2版本。

新的版本整合了FlashAttention-2,使得scaled_dot_product_attention (SDPA)相較於之前的版本有了約2倍的效能提升。
PyTorch 2.2還引入了一個新的TorchInductor提前擴充套件,稱為 AOTInductor,旨在為非python伺服器端編譯和部署PyTorch程式。
PyTorch中的torch.distributed支持了一個叫做device_mesh的新抽象,用於初始化和表示ProcessGroups。

另外,PyTorch 2.2提供了一個標準化的、可配置的日誌記錄機制,——TORCH_LOGS。
PyTorch 2.2還對torch.compile做了許多改進,包括改進了對編譯最佳化器的支持,以及TorchInductor融合和布局最佳化。
最後值得註意的是,PyTorch將放棄對macOS x86的支持,PyTorch 2.2.x是支持macOS x64的最後一個版本。
PyTorch 2.2新特性
首先請註意,如果從原始碼構建PyTorch 2.2,需要GCC 9.4或更高版本,PyTorch 程式碼庫已從C++ 14遷移到C++ 17。

FlashAttention-2
FlashAttention-2透過最佳化GPU上不同執行緒塊和warps之間的工作分區,來解決占用率低或不必要的共享記憶體讀寫。
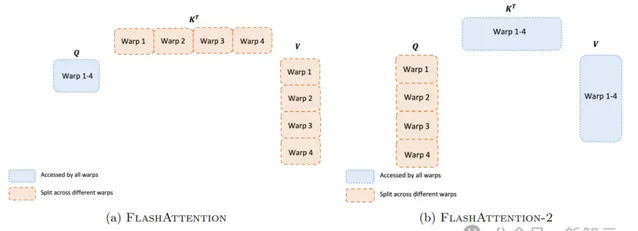
FlashAttention-2調整了演算法以減少非matmul的計算量,同時提升了Attention計算的並列性(即使是單個頭,也可以跨不同的執行緒塊,以增加占用率),在每個執行緒塊中,最佳化warps之間的工作分配,以減少透過共享記憶體的通訊。
PyTorch 2.2將FlashAttention內核更新到了v2版本,不過需要註意的是,之前的Flash Attention內核具有Windows實作,Windows使用者可以強制使用sdp_kernel,僅啟用Flash Attention的上下文管理器。
而在2.2中,如果必須使用 sdp_kernel 上下文管理器,請使用memory efficient或math內核(在Windows上)。
在FlashAttention-2的加持之下,torch.nn.functional.scaled_dot_product_attention的速度提升了大約2倍,在A100 GPU上達到了理論計算峰值的50%-73%。
AOTInductor
AOTInductor是TorchInductor的擴充套件,用於處理匯出的PyTorch模型,對其進行最佳化,並生成共享庫以及其他相關工件。
這些編譯的工件可以部署在非Python環境中,經常用於伺服器端的推理。
下面的範例演示了如何呼叫 aot_compile 將模型轉換為共享庫。
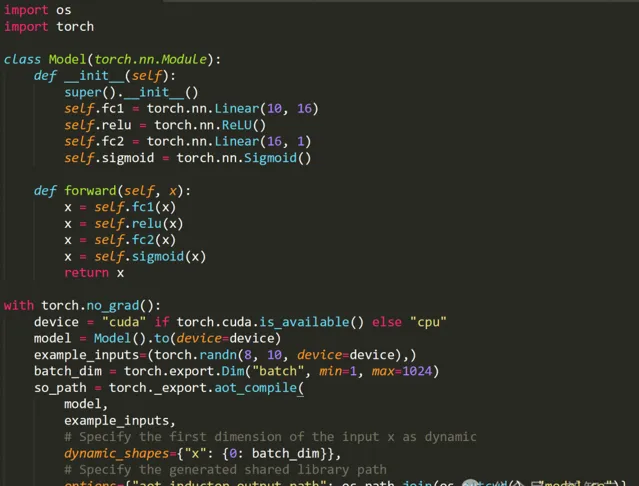
AOTInductor支持與Inductor相同的後端,包括CUDA、ROCm和CPU。
TORCH_LOGS
PyTorch 2.2提供了一個標準化的、可配置的日誌記錄機制,可用於分析各種子系統的狀態,例如編譯和分布式操作
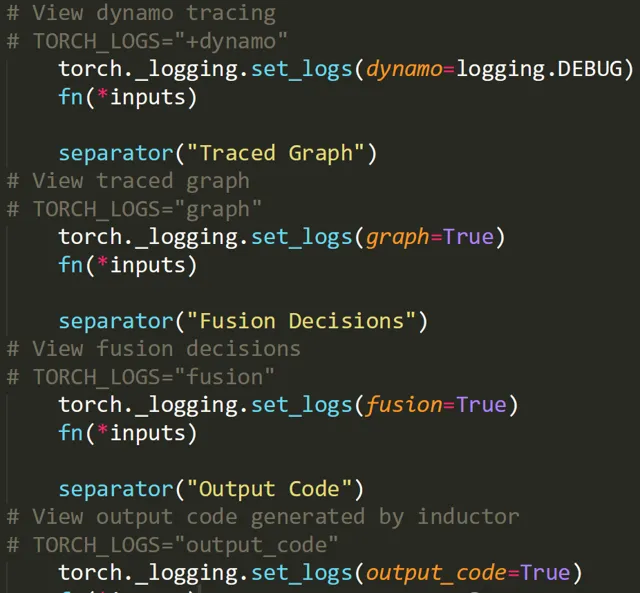
可以透過TORCH_LOGS環境變量啟用日誌。比如透過在命令列中修改環境變量:
將TorchDynamo的日誌級別設定為logging.ERROR,將TorchInductor的日誌級別設定為logging.DEBUG。
當然也可以在程式碼中以API的形式使用:
torch.distributed.device_mesh
PyTorch 2.2引入了一個新的抽象,用於表示分布式並列中涉及的 ProcessGroups,稱為torch.distributed.device_mesh。
為分布式訓練設定分布式通訊器(NCCL)是一件麻煩的事情。使用者需要編寫不同並列度的工作負載,並為每個並列度手動設定和管理NCCL通訊器(ProcessGroup )。
這個過程可能很復雜,容易出錯。而DeviceMesh 可以簡化此過程,使其更易於管理。
DeviceMesh 是管理 ProcessGroup 的更高級別的抽象。它允許使用者毫不費力地建立節點間和節點內行程組,而不必擔心如何為不同的子行程組正確設定等級。
例如,陣列的其中一個維度可以表示FSDP中的數據並列(data parallelism),而另一個維度可以表示FSDP中的張量並列(tensor parallelism)。
使用者還可以透過 DeviceMesh 輕松管理底層process_groups,以實作多維並列。
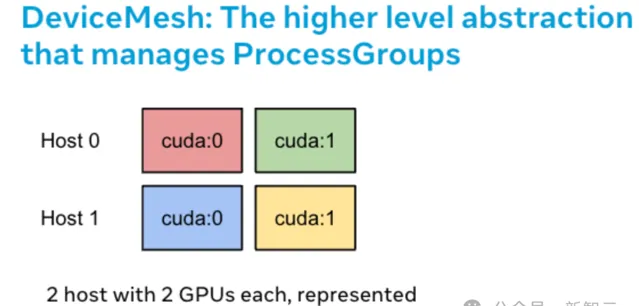
DeviceMesh在處理多維並列性(如3D並列)時很有用。如上圖所示,當你的並列解決方案需要跨主機和每個主機內部進行通訊時,可以建立一個2D網格,用於連線每個主機中的裝置,並以同構設定將每個裝置與其他主機上的對應裝置連線起來。
借助 init_device_mesh() ,我們可以在短短兩行內完成上面這個2D設定:
而如果不使用DeviceMesh,我們大概需要自己寫下面這一堆程式碼:
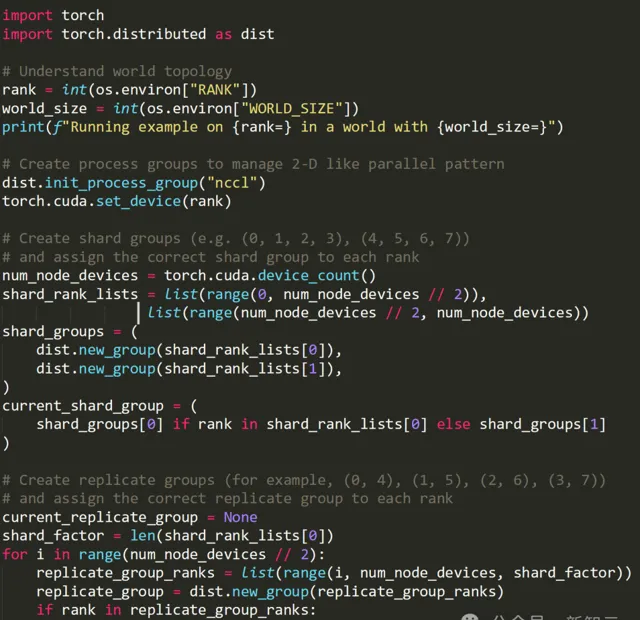
當然,如果需要,我們仍然可以存取底層 ProcessGroup:
最佳化器的改進
大概有以下幾點:
編譯最佳化器在所有基準測試中都提高了效能:HuggingFace +18%、TorchBench +19%、TIMM +8% E2E;
編譯的最佳化器增加對cudagraphs的支持;
對測試套件中所有模型進行平均,每個測試套件的基準測試平均編譯時間增加約40秒;正在進行的最佳化可能會將其降低到30秒以下。
用於多張量最佳化器編譯的inductor中缺少的主要功能是foreach算子的高效編碼生成。
在排程器內部,將所有在下放過程中註冊的緩沖區列表凝聚到ForeachKernelSchedulerNodes中(FusedSchedulerNode的子類別)。
為了檢查融合是否合法,每個內部 SchedulerNode 執行的寫操作必須與消費SchedulerNode在同一列表索引處的讀操作相匹配。
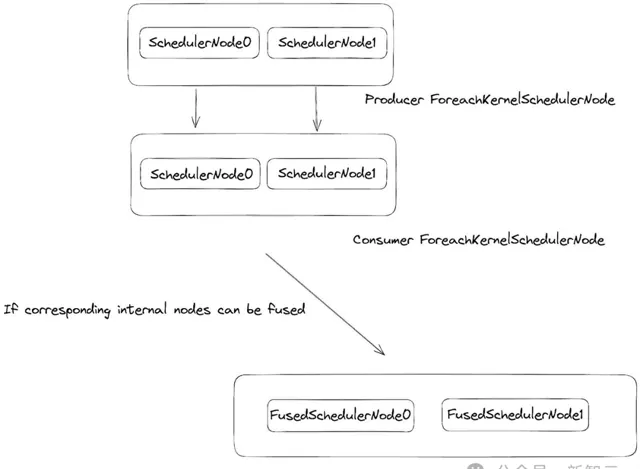
此外,正常的垂直融合規則必須允許在消費者和生產者SchedulerNode列表的每個索引處進行融合。
如果滿足了這些條件,ForeachKernelSchedulerNode將垂直融合成一個 ForeachKernelSchedulerNode,其中每個列表上的相應點操作都將被融合。
透過實作這種融合,可以將一系列 foreach 運算融合到單個內核中,從而實作多張量最佳化器的完全融合。
效能改進
TorchInductor中添加了許多效能最佳化,包括對torch.concat的水平融合支持、改進的摺積布局最佳化、以及改進scaled_dot_product_attention模式匹配。

PyTorch 2.2還包括aarch64的許多效能增強,包括對mkldnn權重預打包的支持、改進的ideep基元緩存,以及透過對OneDNN的固定格式內核改進,來提高推理速度。
參考資料:
https://pytorch.org/blog/pytorch2-2/












