Tomcat 架構原理解析到架構設計借鑒
Tomcat 發展這麽多年,已經比較成熟穩定。在如今『追新求快』的時代,Tomcat 作為 Java Web 開發必備的工具似乎變成了『熟悉的陌生人』,難道說如今就沒有必要深入學習它了麽?學習它我們又有什麽收獲呢?
靜下心來,細細品味經典的開源作品 。提升我們的「內功」,具體來說就是學習大牛們如何設計、架構一個中介軟體系統,並且讓這些經驗為我所用。
美好的事物往往是整潔而優雅的。但這並不等於簡單,而是要將復雜的系統分解成一個個小模組,並且各個模組的職責劃分也要清晰合理。
與此相反的是淩亂無序,比如你看到城中村一堆互相纏結在一起的電線,可能會感到不適。維護的程式碼一個類幾千行、一個方法好幾百行。方法之間相互耦合糅雜在一起,你可能會說 what the f*k!

學習目的
掌握 Tomcat 架構設計與原理提高內功
宏觀上看
Tomcat 作為一個 「
Http
伺服器 +
Servlet
容器」,對我們遮蔽了套用層協定和網路通訊細節,給我們的是標準的
Request
和
Response
物件;對於具體的業務邏輯則作為變化點,交給我們來實作。我們使用了
SpringMVC
之類的框架,可是卻從來不需要考慮
TCP
連線、
Http
協定的數據處理與響應。就是因為 Tomcat 已經為我們做好了這些,我們只需要關註每個請求的具體業務邏輯。
微觀上看
Tomcat
內部也隔離了變化點與不變點,使用了元件化設計,目的就是為了實作「俄羅斯套娃式」的高度客製化(組合模式),而每個元件的生命周期管理又有一些共性的東西,則被提取出來成為介面和抽象類,讓具體子類別實作變化點,也就是樣版方法設計模式。
當今流行的微服務也是這個思路,按照功能將單體套用拆成「微服務」,拆分過程要將共性提取出來,而這些共性就會成為核心的基礎服務或者通用庫。「中台」思想亦是如此。
設計模式往往就是封裝變化的一把利器,合理的運用設計模式能讓我們的程式碼與系統設計變得優雅且整潔。
這就是學習優秀開源軟體能獲得的「內功」,從不會過時,其中的設計思想與哲學才是根本之道。從中借鑒設計經驗,合理運用設計模式封裝變與不變,更能從它們的源碼中汲取經驗,提升自己的系統設計能力。
宏觀理解一個請求如何與 Spring 聯系起來
在工作過程中,我們對 Java 語法已經很熟悉了,甚至「背」過一些設計模式,用過很多 Web 框架,但是很少有機會將他們用到實際計畫中,讓自己獨立設計一個系統似乎也是根據需求一個個 Service 實作而已。腦子裏似乎沒有一張 Java Web 開發全景圖,比如我並不知道瀏覽器的請求是怎麽跟 Spring 中的程式碼聯系起來的。
為了突破這個瓶頸,為何不站在巨人的肩膀上學習優秀的開源系統,看大牛們是如何思考這些問題。
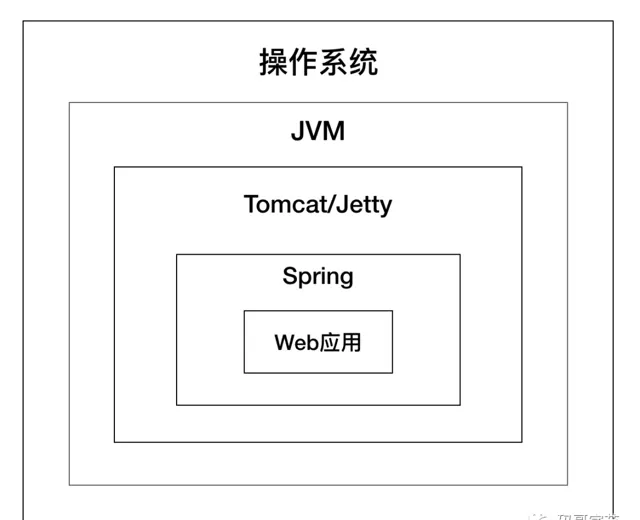
學習 Tomcat 的原理,我發現
Servlet
技術是 Web 開發的原點,幾乎所有的 Java Web 框架(比如 Spring)都是基於
Servlet
的封裝,Spring 套用本身就是一個
Servlet
(
DispatchSevlet
),而 Tomcat 和 Jetty 這樣的 Web 容器,負責載入和執行
Servlet
。如圖所示:
提升自己的系統設計能力
學習 Tomcat ,我還發現用到不少 Java 高級技術,比如 Java 多執行緒並行編程、Socket 網路編程以及反射等。之前也只是了解這些技術,為了面試也背過一些題。但是總感覺「知道」與會用之間存在一道溝壑,透過對 Tomcat 源碼學習,我學會了什麽場景去使用這些技術。
還有就是系統設計能力,比如面向介面編程、元件化組合模式、骨架抽象類、一鍵式啟停、物件池技術以及各種設計模式,比如樣版方法、觀察者模式、責任鏈模式等,之後我也開始模仿它們並把這些設計思想運用到實際的工作中。
整體架構設計
今天咱們就來一步一步分析 Tomcat 的設計思路,一方面我們可以學到 Tomcat 的總體架構,學會從宏觀上怎麽去設計一個復雜系統,怎麽設計頂層模組,以及模組之間的關系;另一方面也為我們深入學習 Tomcat 的工作原理打下基礎。
Tomcat 啟動流程:
startup.sh -> catalina.sh start ->java -jar org.apache.catalina.startup.Bootstrap.main()
Tomcat 實作的 2 個核心功能:
處理
Socket
連線,負責網路字節流與
Request
和
Response
物件的轉化。
載入並管理
Servlet
,以及處理具體的
Request
請求。
所以 Tomcat 設計了兩個核心元件連結器(Connector)和容器(Container)。連結器負責對外交流,容器負責內部 處理
Tomcat
為了實作支持多種
I/O
模型和套用層協定,一個容器可能對接多個連結器,就好比一個房間有多個門。
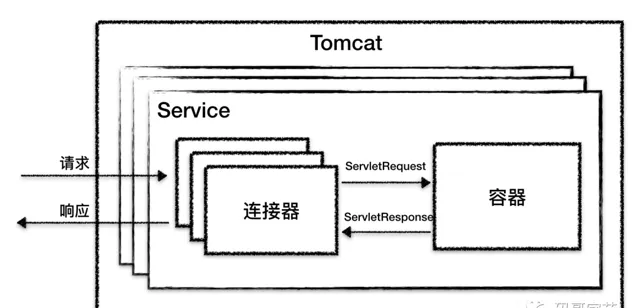
Server 對應的就是一個 Tomcat 例項。
Service 預設只有一個,也就是一個 Tomcat 例項預設一個 Service。
Connector:一個 Service 可能多個 連結器,接受不同連線協定。
Container: 多個連結器對應一個容器,頂層容器其實就是 Engine。
每個元件都有對應的生命周期,需要啟動,同時還要啟動自己內部的子元件,比如一個 Tomcat 例項包含一個 Service,一個 Service 包含多個連結器和一個容器。而一個容器包含多個 Host, Host 內部可能有多個 Contex t 容器,而一個 Context 也會包含多個 Servlet,所以 Tomcat 利用組合模式管理元件每個元件,對待過個也想對待單個組一樣對待 。整體上每個元件設計就像是「俄羅斯套娃」一樣。
連結器
在開始講連結器前,我先鋪墊一下
Tomcat
支持的多種
I/O
模型和套用層協定。
Tomcat
支持的
I/O
模型有:
NIO
:非阻塞
I/O
,采用
Java NIO
類別庫實作。
NIO2
:異步
I/O
,采用
JDK 7
最新的
NIO2
類別庫實作。
APR
:采用
Apache
可移植執行庫實作,是
C/C++
編寫的本地庫。
Tomcat 支持的套用層協定有:
HTTP/1.1
:這是大部份 Web 套用采用的存取協定。
AJP
:用於和 Web 伺服器整合(如 Apache)。
HTTP/2
:HTTP 2.0 大振幅的提升了 Web 效能。
所以一個容器可能對接多個連結器。連結器對
Servlet
容器遮蔽了網路協定與
I/O
模型的區別,無論是
Http
還是
AJP
,在容器中獲取到的都是一個標準的
ServletRequest
物件。
細化連結器的功能需求就是:
監聽網路埠。
接受網路連線請求。
讀取請求網路字節流。
根據具體套用層協定(
HTTP/AJP
)解析字節流,生成統一的
Tomcat Request
物件。
將
Tomcat Request
物件轉成標準的
ServletRequest
。
呼叫
Servlet
容器,得到
ServletResponse
。
將
ServletResponse
轉成
Tomcat Response
物件。
將
Tomcat Response
轉成網路字節流。
將響應字節流寫回給瀏覽器。
需求列清楚後,我們要考慮的下一個問題是,連結器應該有哪些子模組?優秀的模組化設計應該考慮 高內聚、低耦合 。
高內聚 是指相關度比較高的功能要盡可能集中,不要分散。
低耦合 是指兩個相關的模組要盡可能減少依賴的部份和降低依賴的程度,不要讓兩個模組產生強依賴。
我們發現連結器需要完成 3 個 高內聚 的功能:
網路通訊。
套用層協定解析。
Tomcat Request/Response
與
ServletRequest/ServletResponse
的轉化。
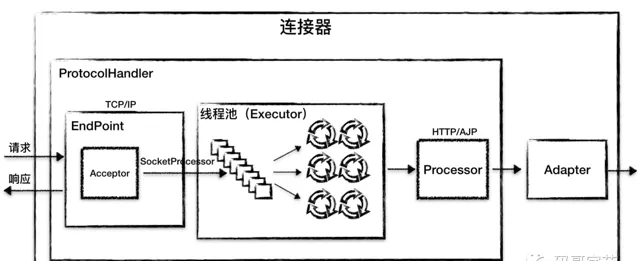
因此 Tomcat 的設計者設計了 3 個元件來實作這 3 個功能,分別是
EndPoint、Processor 和 Adapter
。
網路通訊的 I/O 模型是變化的, 套用層協定也是變化的,但是整體的處理邏輯是不變的,
EndPoint
負責提供字節流給
Processor
,
Processor
負責提供
Tomcat Request
物件給
Adapter
,
Adapter
負責提供
ServletRequest
物件給容器。
封裝變與不變
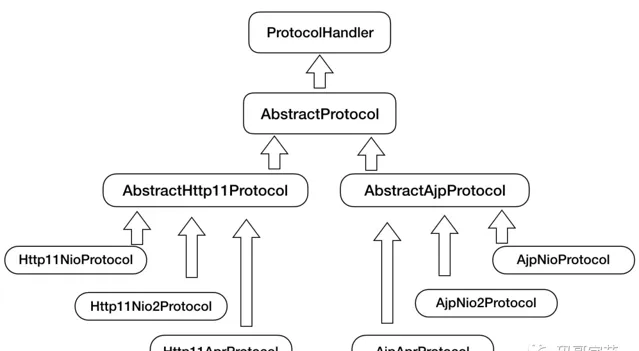
因此 Tomcat 設計了一系列抽象基礎類別來
封裝這些穩定的部份
,抽象基礎類別
AbstractProtocol
實作了
ProtocolHandler
介面。每一種套用層協定有自己的抽象基礎類別,比如
AbstractAjpProtocol
和
AbstractHttp11Protocol
,具體協定的實作類擴充套件了協定層抽象基礎類別。
這就是樣版方法設計模式的運用。
總結下來,連結器的三個核心元件
Endpoint
、
Processor
和
Adapter
來分別做三件事情,其中
Endpoint
和
Processor
放在一起抽象成了
ProtocolHandler
元件,它們的關系如下圖所示。
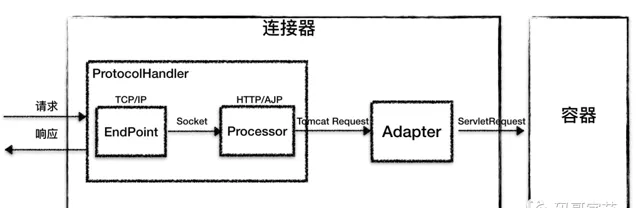
ProtocolHandler 元件
主要處理 網路連線 和 套用層協定 ,包含了兩個重要部件 EndPoint 和 Processor,兩個元件組合形成 ProtocoHandler,下面我來詳細介紹它們的工作原理。
EndPoint
EndPoint
是通訊端點,即通訊監聽的介面,是具體的 Socket 接收和發送處理器,是對傳輸層的抽象,因此
EndPoint
是用來實作
TCP/IP
協定數據讀寫的,本質呼叫作業系統的 socket 介面。
EndPoint
是一個介面,對應的抽象實作類是
AbstractEndpoint
,而
AbstractEndpoint
的具體子類別,比如在
NioEndpoint
和
Nio2Endpoint
中,有兩個重要的子元件:
Acceptor
和
SocketProcessor
。
其中 Acceptor 用於監聽 Socket 連線請求。
SocketProcessor
用於處理
Acceptor
接收到的
Socket
請求,它實作
Runnable
介面,在
Run
方法裏呼叫套用層協定處理元件
Processor
進行處理。為了提高處理能力,
SocketProcessor
被送出到執行緒池來執行。
我們知道,對於 Java 的多路復用器的使用,無非是兩步:
建立一個 Seletor,在它身上註冊各種感興趣的事件,然後呼叫 select 方法,等待感興趣的事情發生。
感興趣的事情發生了,比如可以讀了,這時便建立一個新的執行緒從 Channel 中讀數據。
在 Tomcat 中
NioEndpoint
則是
AbstractEndpoint
的具體實作,裏面元件雖然很多,但是處理邏輯還是前面兩步。它一共包含
LimitLatch
、
Acceptor
、
Poller
、
SocketProcessor
和
Executor
共 5 個元件,分別分工合作實作整個 TCP/IP 協定的處理。
LimitLatch 是連線控制器,它負責控制最大連線數,NIO 模式下預設是 10000,達到這個閾值後,連線請求被拒絕。
Acceptor
跑在一個單獨的執行緒裏,它在一個死迴圈裏呼叫
accept
方法來接收新連線,一旦有新的連線請求到來,
accept
方法返回一個
Channel
物件,接著把
Channel
物件交給 Poller 去處理。
Poller
的本質是一個
Selector
,也跑在單獨執行緒裏。
Poller
在內部維護一個
Channel
陣列,它在一個死迴圈裏不斷檢測
Channel
的數據就緒狀態,一旦有
Channel
可讀,就生成一個
SocketProcessor
任務物件扔給
Executor
去處理。
SocketProcessor 實作了 Runnable 介面,其中 run 方法中的
getHandler().process(socketWrapper, SocketEvent.CONNECT_FAIL);
程式碼則是獲取 handler 並執行處理 socketWrapper,最後透過 socket 獲取合適套用層協定處理器,也就是呼叫 Http11Processor 元件來處理請求。Http11Processor 讀取 Channel 的數據來生成 ServletRequest 物件,Http11Processor 並不是直接讀取 Channel 的。這是因為 Tomcat 支持同步非阻塞 I/O 模型和異步 I/O 模型,在 Java API 中,相應的 Channel 類也是不一樣的,比如有 AsynchronousSocketChannel 和 SocketChannel,為了對 Http11Processor 遮蔽這些差異,Tomcat 設計了一個包裝類叫作 SocketWrapper,Http11Processor 只呼叫 SocketWrapper 的方法去讀寫數據。
Executor
就是執行緒池,負責執行
SocketProcessor
任務類,
SocketProcessor
的
run
方法會呼叫
Http11Processor
來讀取和解析請求數據。我們知道,
Http11Processor
是套用層協定的封裝,它會呼叫容器獲得響應,再把響應透過
Channel
寫出。
工作流程如下所示:
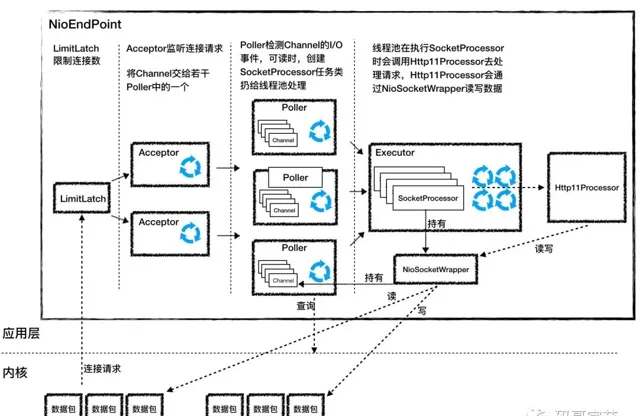
Processor
Processor 用來實作 HTTP 協定,Processor 接收來自 EndPoint 的 Socket,讀取字節流解析成 Tomcat Request 和 Response 物件,並透過 Adapter 將其送出到容器處理,Processor 是對套用層協定的抽象。
從圖中我們看到,EndPoint 接收到 Socket 連線後,生成一個 SocketProcessor 任務送出到執行緒池去處理,SocketProcessor 的 Run 方法會呼叫 HttpProcessor 元件去解析套用層協定,Processor 透過解析生成 Request 物件後,會呼叫 Adapter 的 Service 方法,方法內部透過 以下程式碼將請求傳遞到容器中。
// Calling the container
connector.getService().getContainer().getPipeline().getFirst().invoke(request, response);
Adapter 元件
由於協定的不同,Tomcat 定義了自己的
Request
類來存放請求資訊,這裏其實體現了物件導向的思維。但是這個 Request 不是標準的
ServletRequest
,所以不能直接使用 Tomcat 定義 Request 作為參數直接容器。
Tomcat 設計者的解決方案是引入
CoyoteAdapter
,這是介面卡模式的經典運用,連結器呼叫
CoyoteAdapter
的
Sevice
方法,傳入的是
Tomcat Request
物件,
CoyoteAdapter
負責將
Tomcat Request
轉成
ServletRequest
,再呼叫容器的
Service
方法。
容器
連結器負責外部交流,容器負責內部處理。具體來說就是,連結器處理 Socket 通訊和套用層協定的解析,得到
Servlet
請求;而容器則負責處理
Servlet
請求。
容器:顧名思義就是拿來裝東西的, 所以 Tomcat 容器就是拿來裝載
Servlet
。
Tomcat 設計了 4 種容器,分別是
Engine
、
Host
、
Context
和
Wrapper
。
Server
代表 Tomcat 例項。
要註意的是這 4 種容器不是平行關系,屬於父子關系,如下圖所示:
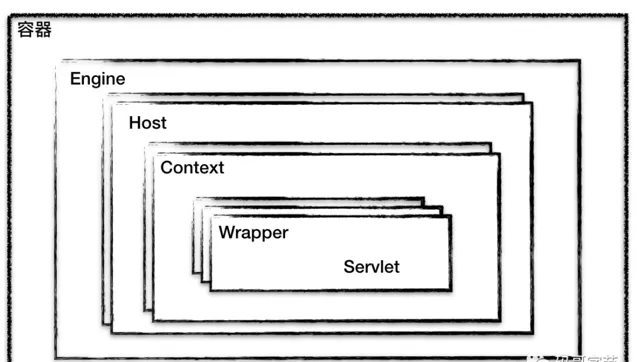
你可能會問,為啥要設計這麽多層次的容器,這不是增加復雜度麽?其實這背後的考慮是, Tomcat 透過一種分層的架構,使得 Servlet 容器具有很好的靈活性。因為這裏正好符合一個 Host 多個 Context, 一個 Context 也包含多個 Servlet,而每個元件都需要統一生命周期管理,所以組合模式設計這些容器
Wrapper
表示一個
Servlet
,
Context
表示一個 Web 應用程式,而一個 Web 程式可能有多個
Servlet
;
Host
表示一個虛擬主機,或者說一個站點,一個 Tomcat 可以配置多個站點(Host);一個站點( Host) 可以部署多個 Web 套用;
Engine
代表 引擎,用於管理多個站點(Host),一個 Service 只能有 一個
Engine
。
可透過 Tomcat 配置檔加深對其層次關系理解。
<Serverport="8005"shutdown="SHUTDOWN"> // 頂層元件,可包含多個 Service,代表一個 Tomcat 例項
<Servicename="Catalina"> // 頂層元件,包含一個 Engine ,多個連結器
<Connectorport="8080"protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />
<!-- Define an AJP 1.3 Connector on port 8009 -->
<Connectorport="8009"protocol="AJP/1.3"redirectPort="8443" /> // 連結器
// 容器元件:一個 Engine 處理 Service 所有請求,包含多個 Host
<Enginename="Catalina"defaultHost="localhost">
// 容器元件:處理指定Host下的客戶端請求, 可包含多個 Context
<Hostname="localhost"appBase="webapps"
unpackWARs="true"autoDeploy="true">
// 容器元件:處理特定 Context Web套用的所有客戶端請求
<Context></Context>
</Host>
</Engine>
</Service>
</Server>
如何管理這些容器?我們發現容器之間具有父子關系,形成一個樹形結構,是不是想到了設計模式中的 組合模式 。
Tomcat 就是用組合模式來管理這些容器的。具體實作方法是,
所有容器元件都實作了
Container
介面,因此組合模式可以使得使用者對單容器物件和組合容器物件的使用具有一致性
。這裏單容器物件指的是最底層的
Wrapper
,組合容器物件指的是上面的
Context
、
Host
或者
Engine
。
Container
介面定義如下:
publicinterfaceContainerextendsLifecycle{
publicvoidsetName(String name);
public Container getParent();
publicvoidsetParent(Container container);
publicvoidaddChild(Container child);
publicvoidremoveChild(Container child);
public Container findChild(String name);
}
我們看到了
getParent
、
SetParent
、
addChild
和
removeChild
等方法,這裏正好驗證了我們說的組合模式。我們還看到
Container
介面拓展了
Lifecycle
,Tomcat 就是透過
Lifecycle
統一管理所有容器的元件的生命周期。透過組合模式管理所有容器,拓展
Lifecycle
實作對每個元件的生命周期管理 ,
Lifecycle
主要包含的方法
init()、start()、stop() 和 destroy()
。
請求定位 Servlet 的過程
一個請求是如何定位到讓哪個
Wrapper
的
Servlet
處理的?答案是,Tomcat 是用 Mapper 元件來完成這個任務的。
Mapper
元件的功能就是將使用者請求的
URL
定位到一個
Servlet
,它的工作原理是:
Mapper
元件裏保存了 Web 套用的配置資訊,其實就是
容器元件與存取路徑的對映關系
,比如
Host
容器裏配置的網域名稱、
Context
容器裏的
Web
套用路徑,以及
Wrapper
容器裏
Servlet
對映的路徑,你可以想象這些配置資訊就是一個多層次的
Map
。
當一個請求到來時,
Mapper
元件透過解析請求 URL 裏的網域名稱和路徑,再到自己保存的 Map 裏去尋找,就能定位到一個
Servlet
。請你註意,一個請求 URL 最後只會定位到一個
Wrapper
容器,也就是一個
Servlet
。
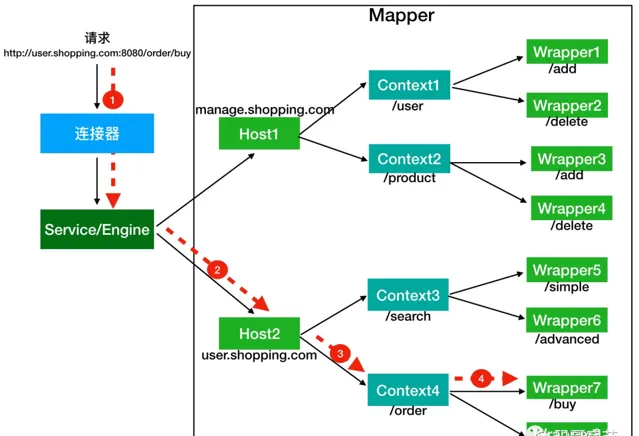
假如有使用者存取一個 URL,比如圖中的
http://user.shopping.com:8080/order/buy
,Tomcat 如何將這個 URL 定位到一個 Servlet 呢?
首先根據協定和埠號確定 Service 和 Engine 。Tomcat 預設的 HTTP 連結器監聽 8080 埠、預設的 AJP 連結器監聽 8009 埠。上面例子中的 URL 存取的是 8080 埠,因此這個請求會被 HTTP 連結器接收,而一個連結器是屬於一個 Service 元件的,這樣 Service 元件就確定了。我們還知道一個 Service 元件裏除了有多個連結器,還有一個容器元件,具體來說就是一個 Engine 容器,因此 Service 確定了也就意味著 Engine 也確定了。
根據網域名稱選定 Host。 Service 和 Engine 確定後,Mapper 元件透過 URL 中的網域名稱去尋找相應的 Host 容器,比如例子中的 URL 存取的網域名稱是
user.shopping.com,因此 Mapper 會找到 Host2 這個容器。根據 URL 路徑找到 Context 元件。 Host 確定以後,Mapper 根據 URL 的路徑來匹配相應的 Web 套用的路徑,比如例子中存取的是 /order,因此找到了 Context4 這個 Context 容器。
根據 URL 路徑找到 Wrapper(Servlet)。 Context 確定後,Mapper 再根據 web.xml 中配置的 Servlet 對映路徑來找到具體的 Wrapper 和 Servlet。
連結器中的 Adapter 會呼叫容器的 Service 方法來執行 Servlet,最先拿到請求的是 Engine 容器,Engine 容器對請求做一些處理後,會把請求傳給自己子容器 Host 繼續處理,依次類推,最後這個請求會傳給 Wrapper 容器,Wrapper 會呼叫最終的 Servlet 來處理。那麽這個呼叫過程具體是怎麽實作的呢?答案是使用 Pipeline-Valve 管道。
Pipeline-Valve
是責任鏈模式,責任鏈模式是指在一個請求處理的過程中有很多處理者依次對請求進行處理,每個處理者負責做自己相應的處理,處理完之後將再呼叫下一個處理者繼續處理,Valve 表示一個處理點(也就是一個處理閥門),因此
invoke
方法就是來處理請求的。
publicinterfaceValve{
public Valve getNext();
publicvoidsetNext(Valve valve);
publicvoidinvoke(Request request, Response response)
}
繼續看 Pipeline 介面
publicinterfacePipeline{
publicvoidaddValve(Valve valve);
public Valve getBasic();
publicvoidsetBasic(Valve valve);
public Valve getFirst();
}
Pipeline
中有
addValve
方法。Pipeline 中維護了
Valve
連結串列,
Valve
可以插入到
Pipeline
中,對請求做某些處理。我們還發現 Pipeline 中沒有 invoke 方法,因為整個呼叫鏈的觸發是 Valve 來完成的,
Valve
完成自己的處理後,呼叫
getNext.invoke()
來觸發下一個 Valve 呼叫。
其實每個容器都有一個 Pipeline 物件,只要觸發了這個 Pipeline 的第一個 Valve,這個容器裏
Pipeline
中的 Valve 就都會被呼叫到。但是,不同容器的 Pipeline 是怎麽鏈式觸發的呢,比如 Engine 中 Pipeline 需要呼叫下層容器 Host 中的 Pipeline。
這是因為
Pipeline
中還有個
getBasic
方法。這個
BasicValve
處於
Valve
連結串列的末端,它是
Pipeline
中必不可少的一個
Valve
,負責呼叫下層容器的 Pipeline 裏的第一個 Valve。
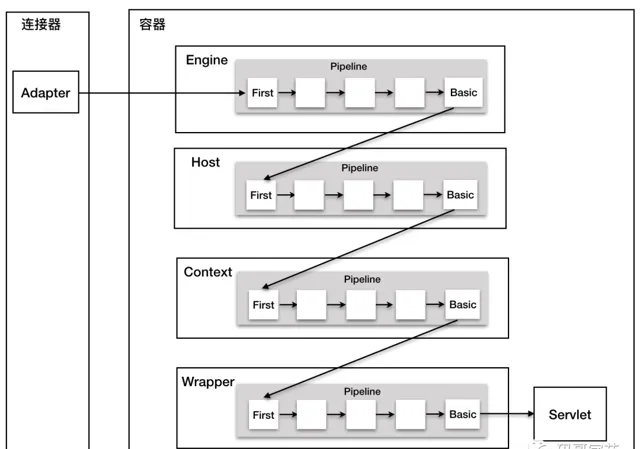
整個過程分是透過連結器中的
CoyoteAdapter
觸發,它會呼叫 Engine 的第一個 Valve:
@Override
publicvoidservice(org.apache.coyote.Request req, org.apache.coyote.Response res){
// 省略其他程式碼
// Calling the container
connector.getService().getContainer().getPipeline().getFirst().invoke(
request, response);
...
}
Wrapper 容器的最後一個 Valve 會建立一個 Filter 鏈,並呼叫
doFilter()
方法,最終會調到
Servlet
的
service
方法。
前面我們不是講到了
Filter
,似乎也有相似的功能,那
Valve
和
Filter
有什麽區別嗎?它們的區別是:
Valve
是
Tomcat
的私有機制,與 Tomcat 的基礎架構
API
是緊耦合的。
Servlet API
是公有的標準,所有的 Web 容器包括 Jetty 都支持 Filter 機制。
另一個重要的區別是
Valve
工作在 Web 容器級別,攔截所有套用的請求;而
Servlet Filter
工作在套用級別,只能攔截某個
Web
套用的所有請求。如果想做整個
Web
容器的攔截器,必須透過
Valve
來實作。
Lifecycle 生命周期
前面我們看到
Container
容器 繼承了
Lifecycle
生命周期。如果想讓一個系統能夠對外提供服務,我們需要建立、組裝並啟動這些元件;在服務停止的時候,我們還需要釋放資源,銷毀這些元件,因此這是一個動態的過程。也就是說,Tomcat 需要動態地管理這些元件的生命周期。
如何統一管理元件的建立、初始化、啟動、停止和銷毀?如何做到程式碼邏輯清晰?如何方便地添加或者刪除元件?如何做到元件啟動和停止不遺漏、不重復?
一鍵式啟停:LifeCycle 介面
設計就是要找到系統的變化點和不變點。這裏的不變點就是每個元件都要經歷建立、初始化、啟動這幾個過程,這些狀態以及狀態的轉化是不變的。而變化點是每個具體元件的初始化方法,也就是啟動方法是不一樣的。
因此,Tomcat 把不變點抽象出來成為一個介面,這個介面跟生命周期有關,叫作 LifeCycle。LifeCycle 介面裏定義這麽幾個方法:
init()、start()、stop() 和 destroy()
,每個具體的元件(也就是容器)去實作這些方法。
在父元件的
init()
方法裏需要建立子元件並呼叫子元件的
init()
方法。同樣,在父元件的
start()
方法裏也需要呼叫子元件的
start()
方法,因此呼叫者可以無差別的呼叫各元件的
init()
方法和
start()
方法,這就是
組合模式
的使用,並且只要呼叫最頂層元件,也就是 Server 元件的
init()
和
start()
方法,整個 Tomcat 就被啟動起來了。所以 Tomcat 采取組合模式管理容器,容器繼承 LifeCycle 介面,這樣就可以向針對單個物件一樣一鍵管理各個容器的生命周期,整個 Tomcat 就啟動起來。
可延伸性:LifeCycle 事件
我們再來考慮另一個問題,那就是系統的可延伸性。因為各個元件
init()
和
start()
方法的具體實作是復雜多變的,比如在 Host 容器的啟動方法裏需要掃描 webapps 目錄下的 Web 套用,建立相應的 Context 容器,如果將來需要增加新的邏輯,直接修改
start()
方法?這樣會違反開閉原則,那如何解決這個問題呢?開閉原則說的是為了擴充套件系統的功能,你不能直接修改系統中已有的類,但是你可以定義新的類。
元件的
init()
和
start()
呼叫是由它的父元件的狀態變化觸發的,上層元件的初始化會觸發子元件的初始化,上層元件的啟動會觸發子元件的啟動,因此我們把元件的生命周期定義成一個個狀態,把狀態的轉變看作是一個事件。而事件是有監聽器的,在監聽器裏可以實作一些邏輯,並且監聽器也可以方便的添加和刪除
,這就是典型的
觀察者模式
。
以下就是
Lyfecycle
介面的定義:
Lyfecycle
重用性:LifeCycleBase 抽象基礎類別
再次看到抽象樣版設計模式。
有了介面,我們就要用類去實作介面。一般來說實作類不止一個,不同的類在實作介面時往往會有一些相同的邏輯,如果讓各個子類別都去實作一遍,就會有重復程式碼。那子類別如何重用這部份邏輯呢?其實就是定義一個基礎類別來實作共同的邏輯,然後讓各個子類別去繼承它,就達到了重用的目的。
Tomcat 定義一個基礎類別 LifeCycleBase 來實作 LifeCycle 介面,把一些公共的邏輯放到基礎類別中去,比如生命狀態的轉變與維護、生命事件的觸發以及監聽器的添加和刪除等,而子類別就負責實作自己的初始化、啟動和停止等方法。
publicabstract classLifecycleBaseimplementsLifecycle{
// 持有所有的觀察者
privatefinal List<LifecycleListener> lifecycleListeners = new CopyOnWriteArrayList<>();
/**
* 釋出事件
*
* @param type Event type
* @param data Data associated with event.
*/
protectedvoidfireLifecycleEvent(String type, Object data){
LifecycleEvent event = new LifecycleEvent(this, type, data);
for (LifecycleListener listener : lifecycleListeners) {
listener.lifecycleEvent(event);
}
}
// 樣版方法定義整個啟動流程,啟動所有容器
@Override
publicfinalsynchronizedvoidinit()throws LifecycleException {
//1. 狀態檢查
if (!state.equals(LifecycleState.NEW)) {
invalidTransition(Lifecycle.BEFORE_INIT_EVENT);
}
try {
//2. 觸發 INITIALIZING 事件的監聽器
setStateInternal(LifecycleState.INITIALIZING, null, false);
// 3. 呼叫具體子類別的初始化方法
initInternal();
// 4. 觸發 INITIALIZED 事件的監聽器
setStateInternal(LifecycleState.INITIALIZED, null, false);
} catch (Throwable t) {
ExceptionUtils.handleThrowable(t);
setStateInternal(LifecycleState.FAILED, null, false);
thrownew LifecycleException(
sm.getString("lifecycleBase.initFail",toString()), t);
}
}
}
Tomcat 為了實作一鍵式啟停以及優雅的生命周期管理,並考慮到了可延伸性和可重用性,將物件導向思想和設計模式發揮到了極致,
Containaer
介面維護了容器的父子關系,
Lifecycle
組合模式實作元件的生命周期維護,生命周期每個元件有變與不變的點,運用樣版方法模式。分別運用了
組合模式、觀察者模式、骨架抽象類和樣版方法
。
如果你需要維護一堆具有父子關系的實體,可以考慮使用組合模式。
觀察者模式聽起來 「高大上」,其實就是當一個事件發生後,需要執行一連串更新操作。實作了低耦合、非侵入式的通知與更新機制。
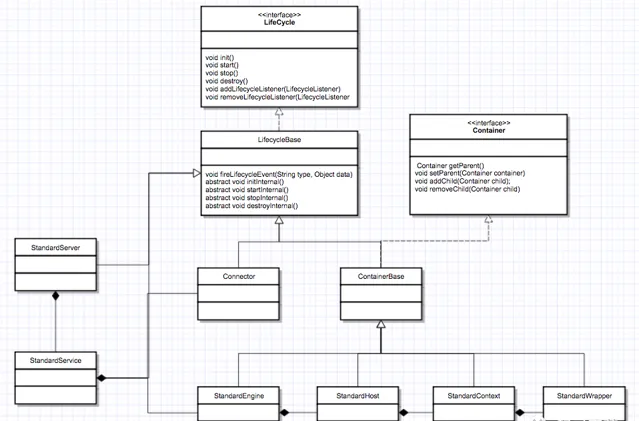
Container
繼承了 LifeCycle,StandardEngine、StandardHost、StandardContext 和 StandardWrapper 是相應容器元件的具體實作類,因為它們都是容器,所以繼承了 ContainerBase 抽象基礎類別,而 ContainerBase 實作了 Container 介面,也繼承了 LifeCycleBase 類,它們的生命周期管理介面和功能介面是分開的,這也符合設計中
介面分離的原則
。
Tomcat 為何打破雙親委派機制
雙親委派
我們知道
JVM
的類載入器載入 class 的時候基於雙親委派機制,也就是會將載入交給自己的父載入器載入,如果 父載入器為空則尋找
Bootstrap
是否載入過,當無法載入的時候才讓自己載入。JDK 提供一個抽象類
classLoader
,這個抽象類中定義了三個關鍵方法。對外使用
load class(String name) 用於子類別重寫打破雙親委派:load class(String name, boolean resolve)
public class<?> load class(String name) throws classNotFoundException {
return load class(name, false);
}
protected class<?> load class(String name, boolean resolve)
throws classNotFoundException
{
synchronized (get classLoadingLock(name)) {
// 尋找該 class 是否已經被載入過
class<?> c = findLoaded class(name);
// 如果沒有載入過
if (c == null) {
// 委托給父載入器去載入,遞迴呼叫
if (parent != null) {
c = parent.load class(name, false);
} else {
// 如果父載入器為空,尋找 Bootstrap 是否載入過
c = findBootstrap classOrNull(name);
}
// 若果依然載入不到,則呼叫自己的 find class 去載入
if (c == null) {
c = find class(name);
}
}
if (resolve) {
resolve class(c);
}
return c;
}
}
protected class<?> find class(String name){
//1. 根據傳入的類名 name,到在特定目錄下去尋找類檔,把. class 檔讀入記憶體
...
//2. 呼叫 define class 將字節陣列轉成 class 物件
return define class(buf, off, len);
}
// 將字節碼陣列解析成一個 class 物件,用 native 方法實作
protectedfinal class<?> define class(byte[] b, int off, int len){
...
}
JDK 中有 3 個類載入器,另外你也可以自訂類載入器,它們的關系如下圖所示。
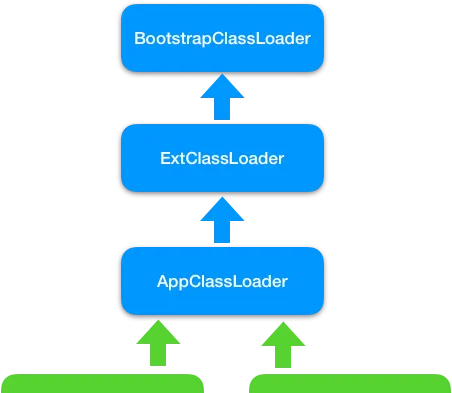
Bootstrap classLoader
是啟動類載入器,由 C 語言實作,用來載入
JVM
啟動時所需要的核心類,比如
rt.jar
、
resources.jar
等。
Ext classLoader
是擴充套件類載入器,用來載入
\jre\lib\ext
目錄下 JAR 包。
App classLoader
是系統類載入器,用來載入
classpath
下的類,應用程式預設用它來載入類。
自訂類載入器,用來載入自訂路徑下的類。
這些類載入器的工作原理是一樣的,區別是它們的載入路徑不同,也就是說
find class
這個方法尋找的路徑不同。雙親委托機制是為了保證一個 Java 類在 JVM 中是唯一的,假如你不小心寫了一個與 JRE 核心類同名的類,比如
Object
類,雙親委托機制能保證載入的是
JRE
裏的那個
Object
類,而不是你寫的
Object
類。這是因為
App classLoader
在載入你的 Object 類時,會委托給
Ext classLoader
去載入,而
Ext classLoader
又會委托給
Bootstrap classLoader
,
Bootstrap classLoader
發現自己已經載入過了
Object
類,會直接返回,不會去載入你寫的
Object
類。我們最多只能 獲取到
Ext classLoader
這裏註意下。
Tomcat 熱載入
Tomcat 本質是透過一個後台執行緒做周期性的任務,定期檢測類檔的變化,如果有變化就重新載入類。我們來看
ContainerBackgroundProcessor
具體是如何實作的。
protected classContainerBackgroundProcessorimplementsRunnable{
@Override
publicvoidrun(){
// 請註意這裏傳入的參數是 " 宿主類 " 的例項
processChildren(ContainerBase.this);
}
protectedvoidprocessChildren(Container container){
try {
//1. 呼叫當前容器的 backgroundProcess 方法。
container.backgroundProcess();
//2. 遍歷所有的子容器,遞迴呼叫 processChildren,
// 這樣當前容器的子孫都會被處理
Container[] children = container.findChildren();
for (int i = 0; i < children.length; i++) {
// 這裏請你註意,容器基礎類別有個變量叫做 backgroundProcessorDelay,如果大於 0,表明子容器有自己的後台執行緒,無需父容器來呼叫它的 processChildren 方法。
if (children[i].getBackgroundProcessorDelay() <= 0) {
processChildren(children[i]);
}
}
} catch (Throwable t) { ... }
Tomcat 的熱載入就是在 Context 容器實作,主要是呼叫了 Context 容器的 reload 方法。拋開細節從宏觀上看主要完成以下任務:
停止和銷毀 Context 容器及其所有子容器,子容器其實就是 Wrapper,也就是說 Wrapper 裏面 Servlet 例項也被銷毀了。
停止和銷毀 Context 容器關聯的 Listener 和 Filter。
停止和銷毀 Context 下的 Pipeline 和各種 Valve。
停止和銷毀 Context 的類載入器,以及類載入器載入的類檔資源。
啟動 Context 容器,在這個過程中會重新建立前面四步被銷毀的資源。
在這個過程中,類載入器發揮著關鍵作用。一個 Context 容器對應一個類載入器,類載入器在銷毀的過程中會把它載入的所有類也全部銷毀。Context 容器在啟動過程中,會建立一個新的類載入器來載入新的類檔。
Tomcat 的類載入器
Tomcat 的自訂類載入器
WebApp classLoader
打破了雙親委托機制,它
首先自己嘗試去載入某個類,如果找不到再代理給父類載入器
,其目的是優先載入 Web 套用自己定義的類。具體實作就是重寫
classLoader
的兩個方法:
find class
和
load class
。
find class 方法
org.apache.catalina.loader.Webapp classLoaderBase#find class
;為了方便理解和閱讀,我去掉了一些細節:
public class<?> find class(String name) throws classNotFoundException {
...
class<?> clazz = null;
try {
//1. 先在 Web 套用目錄下尋找類
clazz = find classInternal(name);
} catch (RuntimeException e) {
throw e;
}
if (clazz == null) {
try {
//2. 如果在本地目錄沒有找到,交給父載入器去尋找
clazz = super.find class(name);
} catch (RuntimeException e) {
throw e;
}
//3. 如果父類也沒找到,丟擲 classNotFoundException
if (clazz == null) {
thrownew classNotFoundException(name);
}
return clazz;
}
先在 Web 套用本地目錄下尋找要載入的類。
如果沒有找到,交給父載入器去尋找,它的父載入器就是上面提到的系統類載入器
App classLoader。如何父載入器也沒找到這個類,丟擲
classNotFound異常。
load class 方法
再來看 Tomcat 類載入器的
load class
方法的實作,同樣我也去掉了一些細節:
public class<?> load class(String name, boolean resolve) throws classNotFoundException {
synchronized (get classLoadingLock(name)) {
class<?> clazz = null;
//1. 先在本地 cache 尋找該類是否已經載入過
clazz = findLoaded class0(name);
if (clazz != null) {
if (resolve)
resolve class(clazz);
return clazz;
}
//2. 從系統類載入器的 cache 中尋找是否載入過
clazz = findLoaded class(name);
if (clazz != null) {
if (resolve)
resolve class(clazz);
return clazz;
}
// 3. 嘗試用 Ext classLoader 類載入器類載入,為什麽?
classLoader javaseLoader = getJavase classLoader();
try {
clazz = javaseLoader.load class(name);
if (clazz != null) {
if (resolve)
resolve class(clazz);
return clazz;
}
} catch ( classNotFoundException e) {
// Ignore
}
// 4. 嘗試在本地目錄搜尋 class 並載入
try {
clazz = find class(name);
if (clazz != null) {
if (resolve)
resolve class(clazz);
return clazz;
}
} catch ( classNotFoundException e) {
// Ignore
}
// 5. 嘗試用系統類載入器 (也就是 App classLoader) 來載入
try {
clazz = class.forName(name, false, parent);
if (clazz != null) {
if (resolve)
resolve class(clazz);
return clazz;
}
} catch ( classNotFoundException e) {
// Ignore
}
}
//6. 上述過程都載入失敗,丟擲異常
thrownew classNotFoundException(name);
}
主要有六個步驟:
先在本地 Cache 尋找該類是否已經載入過,也就是說 Tomcat 的類載入器是否已經載入過這個類。
如果 Tomcat 類載入器沒有載入過這個類,再看看系統類載入器是否載入過。
如果都沒有,就讓 Ext classLoader 去載入,這一步比較關鍵,目的 防止 Web 套用自己的類覆蓋 JRE 的核心類 。因為 Tomcat 需要打破雙親委托機制,假如 Web 套用裏自訂了一個叫 Object 的類,如果先載入這個 Object 類,就會覆蓋 JRE 裏面的那個 Object 類,這就是為什麽 Tomcat 的類載入器會優先嘗試用
Ext classLoader去載入,因為Ext classLoader會委托給Bootstrap classLoader去載入,Bootstrap classLoader發現自己已經載入了 Object 類,直接返回給 Tomcat 的類載入器,這樣 Tomcat 的類載入器就不會去載入 Web 套用下的 Object 類了,也就避免了覆蓋 JRE 核心類的問題。如果
Ext classLoader載入器載入失敗,也就是說JRE核心類中沒有這類,那麽就在本地 Web 套用目錄下尋找並載入。如果本地目錄下沒有這個類,說明不是 Web 套用自己定義的類,那麽由系統類載入器去載入。這裏請你註意,Web 套用是透過
class.forName呼叫交給系統類載入器的,因為class.forName的預設載入器就是系統類載入器。如果上述載入過程全部失敗,丟擲
classNotFound異常。
Tomcat 類載入器層次
Tomcat 作為
Servlet
容器,它負責載入我們的
Servlet
類,此外它還負責載入
Servlet
所依賴的 JAR 包。並且
Tomcat
本身也是也是一個 Java 程式,因此它需要載入自己的類和依賴的 JAR 包。首先讓我們思考這一下這幾個問題:
假如我們在 Tomcat 中執行了兩個 Web 應用程式,兩個 Web 套用中有同名的
Servlet,但是功能不同,Tomcat 需要同時載入和管理這兩個同名的Servlet類,保證它們不會沖突,因此 Web 套用之間的類需要隔離。假如兩個 Web 套用都依賴同一個第三方的 JAR 包,比如
Spring,那Spring的 JAR 包被載入到記憶體後,Tomcat要保證這兩個 Web 套用能夠共享,也就是說Spring的 JAR 包只被載入一次,否則隨著依賴的第三方 JAR 包增多,JVM的記憶體會膨脹。跟 JVM 一樣,我們需要隔離 Tomcat 本身的類和 Web 套用的類。
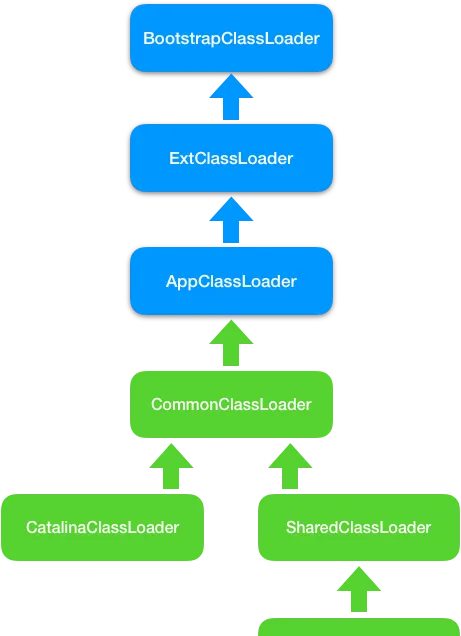
1. WebApp classLoader
Tomcat 的解決方案是自訂一個類載入器
WebApp classLoader
, 並且給每個 Web 套用建立一個類載入器例項。我們知道,Context 容器元件對應一個 Web 套用,因此,每個
Context
容器負責建立和維護一個
WebApp classLoader
載入器例項。這背後的原理是,
不同的載入器例項載入的類被認為是不同的類
,即使它們的類名相同。這就相當於在 Java 虛擬機器內部建立了一個個相互隔離的 Java 類空間,每一個 Web 套用都有自己的類空間,Web 套用之間透過各自的類載入器互相隔離。
2.Shared classLoader
本質需求是兩個 Web 套用之間怎麽共享庫類,並且不能重復載入相同的類。在雙親委托機制裏,各個子載入器都可以透過父載入器去載入類,那麽把需要共享的類放到父載入器的載入路徑下不就行了嗎。
因此 Tomcat 的設計者又加了一個類載入器
Shared classLoader
,作為
WebApp classLoader
的父載入器,專門來載入 Web 套用之間共享的類。如果
WebApp classLoader
自己沒有載入到某個類,就會委托父載入器
Shared classLoader
去載入這個類,
Shared classLoader
會在指定目錄下載入共享類,之後返回給
WebApp classLoader
,這樣共享的問題就解決了。
3. Catalina classloader
如何隔離 Tomcat 本身的類和 Web 套用的類?
要共享可以透過父子關系,要隔離那就需要兄弟關系了。兄弟關系就是指兩個類載入器是平行的,它們可能擁有同一個父載入器,基於此 Tomcat 又設計一個類載入器
Catalina classloader
,專門來載入 Tomcat 自身的類。
這樣設計有個問題,那 Tomcat 和各 Web 套用之間需要共享一些類時該怎麽辦呢?
老辦法,還是再增加一個
Common classLoader
,作為
Catalina classloader
和
Shared classLoader
的父載入器。
Common classLoader
能載入的類都可以被
Catalina classLoader
和
Shared classLoader
使用
整體架構設計解析收獲總結
透過前面對 Tomcat 整體架構的學習,知道了 Tomcat 有哪些核心元件,元件之間的關系。以及 Tomcat 是怎麽處理一個 HTTP 請求的。下面我們透過一張簡化的類圖來回顧一下,從圖上你可以看到各種元件的層次關系,圖中的虛線表示一個請求在 Tomcat 中流轉的過程。
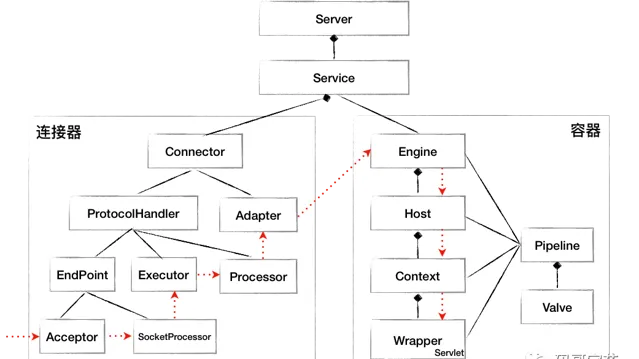
連結器
Tomcat 的整體架構包含了兩個核心元件連結器和容器。連結器負責對外交流,容器負責內部處理。連結器用
ProtocolHandler
介面來封裝通訊協定和
I/O
模型的差異,
ProtocolHandler
內部又分為
EndPoint
和
Processor
模組,
EndPoint
負責底層
Socket
通訊,
Proccesor
負責套用層協定解析。連結器透過介面卡
Adapter
呼叫容器。
對 Tomcat 整體架構的學習,我們可以得到一些設計復雜系統的基本思路。 首先要分析需求,根據高內聚低耦合的原則確定子模組,然後找出子模組中的變化點和不變點,用介面和抽象基礎類別去封裝不變點,在抽象基礎類別中定義樣版方法,讓子類別自行實作抽象方法,也就是具體子類別去實作變化點。
容器
運用了 組合模式 管理容器、透過 觀察者模式 釋出啟動事件達到解耦、開閉原則。骨架抽象類和樣版方法抽象變與不變,變化的交給子類別實作,從而實作程式碼復用,以及靈活的拓展 。使用責任鏈的方式處理請求,比如記錄日誌等。
類載入器
Tomcat 的自訂類載入器
WebApp classLoader
為了隔離 Web 套用打破了雙親委托機制,它
首先自己嘗試去載入某個類,如果找不到再代理給父類載入器
,其目的是優先載入 Web 套用自己定義的類。
防止 Web 套用自己的類覆蓋 JRE 的核心類
,使用
Ext classLoader
去載入,這樣即打破了雙親委派,又能安全載入。
如何閱讀源碼持續學習
學習是一個反人類的過程,是比較痛苦的 。尤其學習我們常用的優秀技術框架本身比較龐大,設計比較復雜,在學習初期很容易遇到 「挫折感」,debug 跳來跳去陷入恐怖細節之中無法自拔,往往就會放棄。
找到適合自己的學習方法非常重要,同樣關鍵的是要保持學習的興趣和動力,並且得到學習反饋效果 。
學習優秀源碼,我們收獲的就是架構設計能力,遇到復雜需求我們學習到可以利用合理模式與元件抽象設計了可拓展性強的程式碼能力。
如何閱讀
比如我最初在學習 Spring 框架的時候,一開始就鉆進某個模組啃起來。然而由於 Spring 太龐大,模組之間也有聯系,根本不明白為啥要這麽寫,只覺得為啥設計這麽 「繞」。
錯誤方式
陷入細節,不看全域: 我還沒弄清楚森林長啥樣,就盯著葉子看 ,看不到全貌和整體設計思路。所以閱讀源碼學習的時候不要一開始就進入細節,而是宏觀看待整體架構設計思想,模組之間的關系。
還沒學會用就研究如何設計:首先基本上框架都運用了設計模式,我們最起碼也要了解常用的設計模式,即使是「背」,也得了然於胸。在學習一門技術,我推薦先看官方文件,看看有哪些模組、整體設計思想。然後下載範例跑一遍,最後才是看源碼。
看源碼深究細節:到了看具體某個模組源碼的時候也要下意識的不要去深入細節,重要的是學習設計思路,而不是具體一個方法實作邏輯。除非自己要基於源碼做二次開發。
正確方式
定焦原則:抓主線(抓住一個核心流程去分析,不要漫無目的的到處閱讀)。
宏觀思維:從全域的視角去看待,上帝視角理出主要核心架構設計,先森林後樹葉。切勿不要試圖去搞明白每一行程式碼。
斷點:合理運用呼叫棧(觀察呼叫過程上下文)。
帶著目標去學
比如某些知識點是面試的熱點,那學習目標就是徹底理解和掌握它,當被問到相關問題時,你的回答能夠使得面試官對你刮目相看,有時候往往憑著某一個亮點就能影響最後的錄用結果。
又或者接到一個稍微復雜的需求, 學習從優秀源碼中借鑒設計思路與最佳化技巧。
最後就是動手實踐 ,將所學運用在工作計畫中。只有動手實踐才會讓我們對技術有最直觀的感受。有時候我們聽別人講經驗和理論,感覺似乎懂了,但是過一段時間便又忘記了。
實際場景運用
簡單的分析了 Tomcat 整體架構設計,從 【連結器】 到 【容器】,並且分別細說了一些元件的設計思想以及設計模式。接下來就是如何學以致用,借鑒優雅的設計運用到實際工作開發中。 學習,從模仿開始。
責任鏈模式
在工作中,有這麽一個需求,使用者可以輸入一些資訊並可以選擇查驗該企業的 【工商資訊】、【司法資訊】、【中登情況】等如下如所示的一個或者多個模組,而且模組之間還有一些公共的東西是要各個模組復用。
這裏就像一個請求,會被多個模組去處理。所以每個查詢模組我們可以抽象為 處理閥門 ,使用一個 List 將這些 閥門保存起來,這樣新增模組我們只需要新增一個 閥門 即可,實作了 開閉原則 , 同時將一堆查驗的程式碼解耦到不同的具體閥門中 ,使用抽象類提取 「 不變的 」功能。
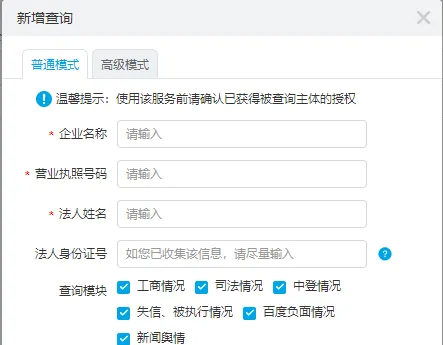
具體範例程式碼如下所示:
首先抽象我們的處理閥門,
NetCheckDTO
是請求資訊
/**
* 責任鏈模式:處理每個模組閥門
*/
publicinterfaceValve{
/**
* 呼叫
* @param netCheckDTO
*/
voidinvoke(NetCheckDTO netCheckDTO);
}
定義抽象基礎類別,復用程式碼。
publicabstract classAbstractCheckValveimplementsValve{
publicfinal AnalysisReportLogDO getLatestHistoryData(NetCheckDTO netCheckDTO, NetCheckDataTypeEnum checkDataTypeEnum){
// 獲取歷史記錄,省略程式碼邏輯
}
// 獲取查驗資料來源配置
publicfinal String getModuleSource(String querySource, ModuleEnum moduleEnum){
// 省略程式碼邏輯
}
}
定義具體每個模組處理的業務邏輯,比如 【百度負面新聞】對應的處理
@Slf4j
@Service
public classBaiduNegativeValveextendsAbstractCheckValve{
@Override
publicvoidinvoke(NetCheckDTO netCheckDTO){
}
}
最後就是管理使用者選擇要查驗的模組,我們透過 List 保存。用於觸發所需要的查驗模組
@Slf4j
@Service
public classNetCheckService{
// 註入所有的閥門
@Autowired
private Map<String, Valve> valveMap;
/**
* 發送查驗請求
*
* @param netCheckDTO
*/
@Async("asyncExecutor")
publicvoidsendCheckRequest(NetCheckDTO netCheckDTO){
// 用於保存客戶選擇處理的模組閥門
List<Valve> valves = new ArrayList<>();
CheckModuleConfigDTO checkModuleConfig = netCheckDTO.getCheckModuleConfig();
// 將使用者選擇查驗的模組添加到 閥門鏈條中
if (checkModuleConfig.getBaiduNegative()) {
valves.add(valveMap.get("baiduNegativeValve"));
}
// 省略部份程式碼.......
if (CollectionUtils.isEmpty(valves)) {
log.info("網查查驗模組為空,沒有需要查驗的任務");
return;
}
// 觸發處理
valves.forEach(valve -> valve.invoke(netCheckDTO));
}
}
樣版方法模式
需求是這樣的,可根據客戶錄入的財報 excel 數據或者企業名稱執行財報分析。
對於非上市的則解析 excel -> 校驗數據是否合法->執行計算。
上市企業:判斷名稱是否存在 ,不存在則發送信件並中止計算-> 從資料庫拉取財報數據,初始化查驗日誌、生成一條報告記錄,觸發計算-> 根據失敗與成功修改任務狀態 。
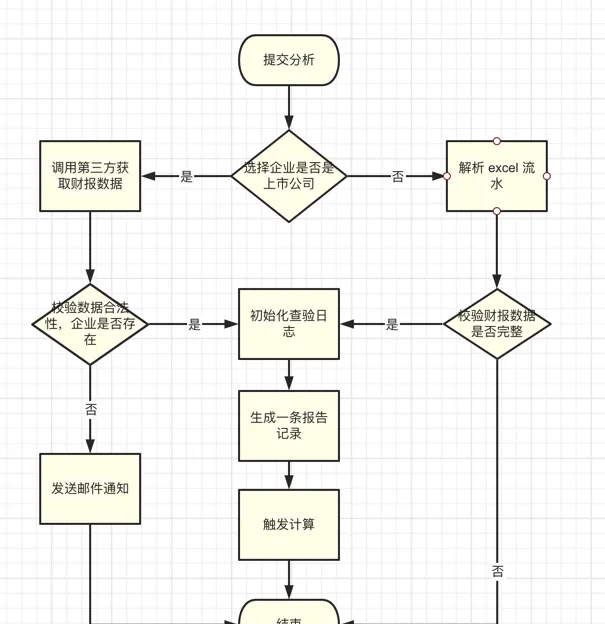
重要的 」變「 與 」不變「,
不變 的是整個流程是 初始化查驗日誌、初始化一條報告 、 前期校驗數據 (若是上市公司校驗不透過還需要構建信件數據並行送)、從不同來源拉取財報數據並且適配通用數據、然後觸發計算,任務異常與成功都需要修改狀態。
變化 的是上市與非上市校驗規則不一樣,獲取財報數據方式不一樣,兩種方式的財報數據需要適配
整個演算法流程是固定的樣版,但是需要將 演算法內部變化的部份 具體實作延遲到不同子類別實作,這正是樣版方法模式的最佳場景。
publicabstract classAbstractAnalysisTemplate{
/**
* 送出財報分析樣版方法,定義骨架流程
* @param reportAnalysisRequest
* @return
*/
publicfinal FinancialAnalysisResultDTO doProcess(FinancialReportAnalysisRequest reportAnalysisRequest){
FinancialAnalysisResultDTO analysisDTO = new FinancialAnalysisResultDTO();
// 抽象方法:送出查驗的合法校驗
boolean prepareValidate = prepareValidate(reportAnalysisRequest, analysisDTO);
log.info("prepareValidate 校驗結果 = {} ", prepareValidate);
if (!prepareValidate) {
// 抽象方法:構建通知信件所需要的數據
buildEmailData(analysisDTO);
log.info("構建信件資訊,data = {}", JSON.toJSONString(analysisDTO));
return analysisDTO;
}
String reportNo = FINANCIAL_REPORT_NO_PREFIX + reportAnalysisRequest.getUserId() + SerialNumGenerator.getFixLenthSerialNumber();
// 生成分析日誌
initFinancialAnalysisLog(reportAnalysisRequest, reportNo);
// 生成分析記錄
initAnalysisReport(reportAnalysisRequest, reportNo);
try {
// 抽象方法:拉取財報數據,不同子類別實作
FinancialDataDTO financialData = pullFinancialData(reportAnalysisRequest);
log.info("拉取財報數據完成, 準備執行計算");
// 測算指標
financialCalcContext.calc(reportAnalysisRequest, financialData, reportNo);
// 設定分析日誌為成功
successCalc(reportNo);
} catch (Exception e) {
log.error("財報計算子任務出現異常", e);
// 設定分析日誌失敗
failCalc(reportNo);
throw e;
}
return analysisDTO;
}
}
最後新建兩個子類別繼承該樣版,並實作抽象方法。這樣就將上市與非上市兩種型別的處理邏輯解耦,同時又復用了程式碼。
策略模式
需求是這樣,要做一個萬能辨識銀行流水的 excel 介面,假設標準流水包含【交易時間、收入、支出、交易余額、付款人帳號、付款人名字、收款人名稱、收款人帳號】等欄位。現在我們解析出來每個必要欄位所在 excel 表頭的下標。但是流水有多種情況:
一種就是包含所有標準欄位。
收入、支出下標是同一列,透過正負來區分收入與支出。
收入與支出是同一列,有一個交易型別的欄位來區分。
特殊銀行的特殊處理。
也就是我們要
根據解析對應的下標找到對應的處理邏輯演算法
,我們可能在一個方法裏面寫超多
if else
的程式碼,整個流水處理都偶合在一起,假如未來再來一種新的流水型別,還要繼續改老程式碼。最後可能出現 「又臭又長,難以維護」 的程式碼復雜度。
這個時候我們可以用到 策略模式 , 將不同樣版的流水使用不同的處理器處理,根據樣版找到對應的策略演算法去處理 。即使未來再加一種型別,我們只要新加一種處理器即可,高內聚低耦合,且可拓展。

定義處理器介面,不同處理器去實作處理邏輯。將所有的處理器註入到
BankFlowDataHandler
的
data_processor_map
中,根據不同的場景取出對已經的處理器處理流水。
publicinterfaceDataProcessor{
/**
* 處理流水數據
* @param bankFlowTemplateDO 流水下標數據
* @param row
* @return
*/
BankTransactionFlowDO doProcess(BankFlowTemplateDO bankFlowTemplateDO, List<String> row);
/**
* 是否支持處理該樣版,不同型別的流水策略根據樣版數據判斷是否支持解析
* @return
*/
booleanisSupport(BankFlowTemplateDO bankFlowTemplateDO);
}
// 處理器的上下文
@Service
@Slf4j
public classBankFlowDataContext{
// 將所有處理器註入到 map 中
@Autowired
private List<DataProcessor> processors;
// 找對對應的處理器處理流水
publicvoidprocess(){
DataProcessor processor = getProcessor(bankFlowTemplateDO);
for(DataProcessor processor :processors) {
if (processor.isSupport(bankFlowTemplateDO)) {
// row 就是一行流水數據
processor.doProcess(bankFlowTemplateDO, row);
break;
}
}
}
}
定義預設處理器,處理正常樣版,新增樣版只要新增處理器實作
DataProcessor
即可。
/**
* 預設處理器:正對規範流水樣版
*
*/
@Component("defaultDataProcessor")
@Slf4j
public classDefaultDataProcessorimplementsDataProcessor{
@Override
public BankTransactionFlowDO doProcess(BankFlowTemplateDO bankFlowTemplateDO){
// 省略處理邏輯細節
return bankTransactionFlowDO;
}
@Override
public String strategy(BankFlowTemplateDO bankFlowTemplateDO){
// 省略判斷是否支持解析該流水
boolean isDefault = true;
return isDefault;
}
}
透過策略模式,我們將不同處理邏輯分配到不同的處理類中,這樣完全解耦,便於拓展。
使用內嵌 Tomcat 方式偵錯原始碼:GitHub: https://github.com/UniqueDong/tomcat-embedded
如喜歡本文,請點選右上角,把文章分享到朋友圈
如有想了解學習的技術點,請留言給若飛安排分享
因公眾號更改推播規則,請點「在看」並加「星標」 第一時間獲取精彩技術分享
·END·
相關閱讀:
作者:碼哥字節
來源:碼哥字節
版權申明:內容來源網路,僅供學習研究,版權歸原創者所有。如有侵權煩請告知,我們會立即刪除並表示歉意。謝謝!
架構師
我們都是架構師!

關註 架構師(JiaGouX),添加「星標」
獲取每天技術幹貨,一起成為牛逼架構師
技術群請 加若飛: 1321113940 進架構師群
投稿、合作、版權等信箱: [email protected]











