來源:近探,侵刪
電商數據采集的方法有哪些呢? 我給大家分享一下我使用爬蟲的個人經驗,我們在采集類似電商數據網站的時候會遇到什麽技術問題,然後再根據這些問題給大家分享采集方案。
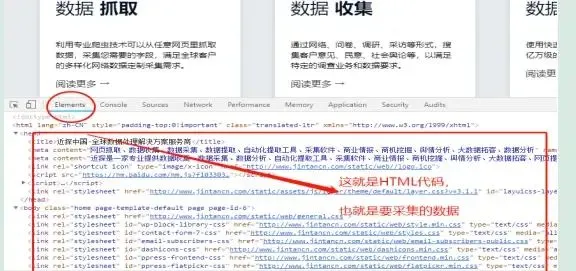
我們平時說的采集網站數據、數據抓取等,其實不是真正的采集數據,在我們的職業裏這個最多算是正規表式,網頁原始碼解析而已,談不上爬蟲采集技術難度,因為這種抓取主要是采集瀏覽器開啟可以看到的數據,這個數據叫做html頁面數據。
比如您開啟:www.baidu.com這個網址,然後鍵盤按F12 ,可以直接看到這個網址的所有數據和原始碼,這個網站主要是提供一些爬蟲技術服務和客製,裏面有些免費新工商數據,如果需要采集它數據,你可以寫個正則匹配規則html標簽,進行截取我們需要的欄位資訊即可。
下面給大家總結一下采集類似這種工商、天眼、商標、專利、亞馬遜、淘寶、app等普遍網站常用的幾個方法,掌握這些存取幾乎解決了90%的數據采集問題了。
「方法一:用python的request方法」
用python的request方法,直接原生態程式碼,python感覺是為了爬蟲和大數據而生的,我平時做的網路分布式爬蟲、影像辨識、AI模型都是用python,因為python有很多現存的庫直接可以呼叫,比如您需要做個簡單爬蟲,比如我想采集百度 幾行程式碼就可以搞定了,核心程式碼如下:
import requests #參照reques庫
response=request.get(‘https://www.tianyancha.com/’)#用get模擬請求
print(response.text) #已經采集出來了,也許您會覺好神奇!
「方法二、用selenium模擬瀏覽器」
selenium是一個專門采集反爬很厲害的網站經常使用的工具,它主要是可以模擬瀏覽器去開啟存取您需要采集的目標網站了,比如您需要采集天眼查或者企查查或者是淘寶、58、京東等各種商業的網站,那麽這種網站伺服端做了反爬技術了,如果您還是用python的request.get方法就容易被辨識,被封IP。
這個時候如果您對數據采集速度要求不太高,比如您一天只是采集幾萬條數據而已,那麽這個工具是非常適合的。我當時在處理商標網時候也是用selenum,後面改用JS逆向了,如果您需要采集幾百萬幾千萬怎麽辦呢?下面的方法就可以用上了。
「方法三、用scrapy進行分布式高速采集」
Scrapy是適用於Python的一個快速、高層次的螢幕抓取和web抓取框架,用於抓取web站點並從頁面中提取結構化的數據。scrapy 特點是異步高效分布式爬蟲架構,可以開多行程 多執行緒池進行批次分布式采集。
比如您想采集1000萬的數據,您就可以多設定幾個結點和執行緒。
Scrapy也有缺點的,它基於 twisted 框架,執行中的 exception 是不會幹掉 reactor(反應器),並且異步框架出錯後 是不會停掉其他任務的,數據出錯後難以察覺。我2019年在做企業知識圖譜建立的時候就是用這個框架,因為要完成1.8億的全量工商企業數據采集和建立關系,維度比天眼還要多,主要是時候更新要求比天眼快。
「方法四:用Crawley」
Crawley也是python開發出的爬蟲框架,該框架致力於改變人們從互聯網中提取數據的方式。它是基於Eventlet構建的高速網路爬蟲框架、可以將爬取的數據匯入為Json、XML格式。支持非關聯式資料庫、支持使用Cookie登入或存取那些只有登入才可以存取的網頁。
「方法五:用PySpider」
相對於Scrapy框架而言,PySpider框架是一支新秀。它采用Python語言編寫,分布式架構,支持多種資料庫後端,強大的WebUI支持指令碼編輯器、任務監視器、計畫管理器以及結果檢視器。
PySpider的特點是ython指令碼控制,可以用任何你喜歡的html解析包,Web界面編寫偵錯指令碼、起停指令碼、監控執行狀態、檢視活動歷史,並且支持RabbitMQ、Beanstalk、Redis和Kombu作為訊息佇列。用它做個兩個外貿網站采集的計畫,感覺還不錯。
「方法六:用Aiohttp」
Aiohttp 是純粹的異步框架,同時支持 HTTP 客戶端和 HTTP 伺服端,可以快速實作異步爬蟲。坑比其他框架少。
並且 aiohttp 解決了requests 的一個痛點,aiohttp 可以輕松實作自動轉碼,對於中文編碼就很方便了。
這個做異步爬蟲很不錯,我當時對幾個淘寶網站異步檢測商城裏面的商品和價格變化後處理時用過一段時間。
「方法七:asks」
Python 內建一個異步的標準庫 asyncio,但是這個庫很多人覺得不好用,甚至是 Flask 庫的作者公開抱怨自己花了好長時間才理解這玩意,於是就有好事者撇開它造了兩個庫叫做 curio 和 trio,而這裏的 ask 則是封裝了 curio 和 trio 的一個 http 請求庫。
「方法八:vibora」
號稱是現在最快的異步請求框架,跑分是最快的。寫爬蟲、寫伺服器響應都可以用,用過1個月後 就很少用了。
「方法九:Pyppeteer」
Pyppeteer 是異步無頭瀏覽器(Headless Chrome),從跑分來看比 Selenium + webdriver 快,使用方式是最接近於瀏覽器的自身的設計介面的。
它本身是來自 Google 維護的 puppeteer。我經常使用它來提高selenium采集的一些反爬比較厲害的網站 比如裁判文書網,這種網站反爬辨識很厲害。
「方法十:Fiddle++node JS逆向+request (采集APP必用)」
Fiddler是一個蠻好用的抓包工具,可以將網路傳輸發送與接受的封包進行截獲、重發、編輯、轉存等操作。
我們在采集某個app時候,一般是先用Fiddler抓包 找到這個app請求這個數據時候調取的是後台的那個介面地址,找到這個地址和請求的參數然後再模擬request。今年在處理快手、抖音的粉絲、評價、商品店鋪銷量時候就用到了Fiddle。
某些APP 和網站的參數是透過js加密的,比如商標網、裁判文書網、抖音快手等這些。
您如果需要請求它的源api地址就地逆向解析破解這些加密參數,可以使用node解析混淆函式。因為平時需要經常采集一些app,所以和Fiddler打交道的比較多。
前面主要是對網站和APP 數據采集和解析的一些方法,其實對這種網站爬蟲技術說無非就解決三個問題:首先是封IP問題,您可以自建代理IP池解決這個問題的,第二個問題就是驗證碼問題,這個問題可以透過python的影像辨識技術來解決或者是您直接調取第三方的打碼平台解決。第三問題就是需要會員帳號登入後才看到的數據,這個很簡單直接用cookie池解決。
其實你也可以不用寫什麽程式碼就能實作數據采集,比如說低程式碼數據收集平台——亮數據Bright Data。
它提供數據采集瀏覽器、網路解鎖器、數據采集托管IDE三種方式,能透過簡單的幾十行Python程式碼實作復雜網路數據的采集,對於反爬、驗證碼、動態網頁等進行自動化處理,完全不需要你操心。

官網地址(點選原文連結也可檢視):
https://get.brightdata.com/weijun
有數據抓取需求的可以試試,非常簡單,能節省大量時間和精力!!!
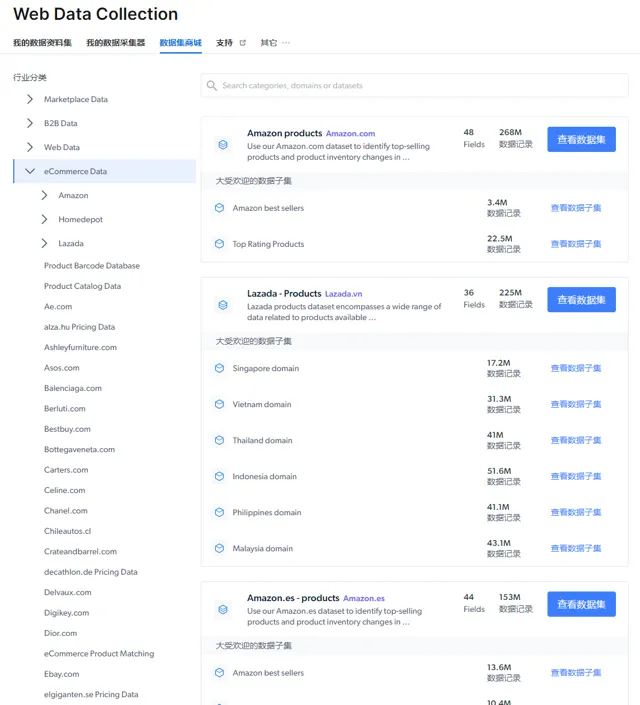
亮數據也提供了現成的數據集,包括電商、社媒、金融、新聞、視訊等等
這些現成的數據集,對於有數據分析需求的人來說非常有節省時間,可以做市場分析、訓練模型等等。
對網路數據采集感興趣的,加入我們的數據采集技術交流群,限200人,滿了就進不了。












