微軟亞洲研究院昨天發了一個貼文,論文看了,但又沒有完全看懂(流下了缺乏知識的淚水),感覺是個特別牛逼的東西,這是一種新的1-bit大語言模型(LLM)BitNet b1.58,到底牛逼在哪兒呢?我們一起探討吧,看下回能不能在亞研院請個同事來給大家再解釋一下。
與傳統的FP16 LLM相比,BitNet b1.58在速度、記憶體使用、能耗等方面具有顯著優勢,同時在語言模型困惑度和下遊任務效能方面能夠與之媲美。
等一下,FP16 LLM是啥來著,FP16也叫做 float16,全稱是Half-precision floating-point(半精度浮點數),具體是啥…反正我們就說FP16大模型一開始就是想讓大模型瘦身,能用在更小的裝置上,比如你在輝達4090顯卡的電腦上跑個30億參數的大模型是不是好慢?FP16 LLM可以讓Flash的速度快上個幾倍。
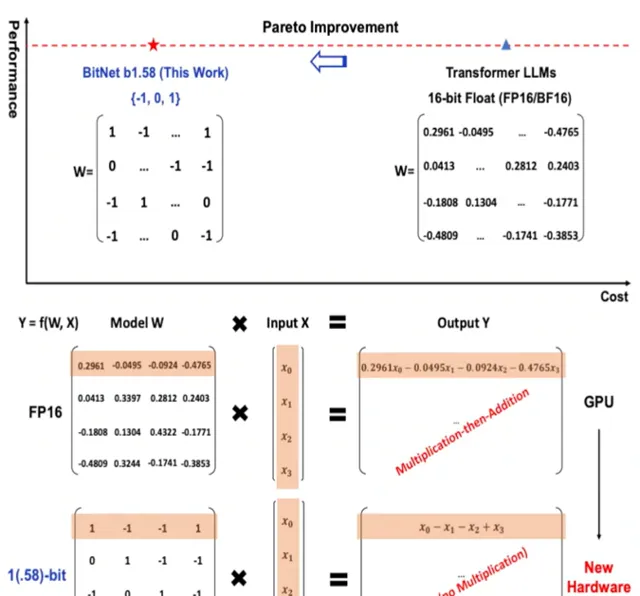
但是,BitNet b1.58一上來就整了個開創性的開局,將FP16這種慢吞吞瘦身而且有極限的辦法拋棄了,它將每個參數列示為三進制(-1, 0, 1),而不是傳統的二進制(0, 1)。然後你的大模型就突然:
1.速度kuchakucha地變快:BitNet b1.58的推理速度比FP16 LLM快2-4倍,這主要得益於它在矩陣乘法操作中只需要整數加法,而不需要浮點數乘法或加法。
2.記憶體使用更少:BitNet b1.58的參數只需要1.58位元來表示,因此與FP16 LLM相比,其記憶體占用減少了3-4倍。
3.能耗更低:BitNet b1.58的能耗比FP16 LLM低70倍以上,這使得它更加適合在行動裝置和物聯網等資源受限的裝置上部署。
你等一等,三進制,三進制,這...是那個前蘇聯搞出來的三進制麽?是的,就是那個1958年前蘇聯電腦用的三進制,你別說,因為二進制現在看起來邊際收益越來越窄的情況下,什麽量子訊號傳輸、半導體、光子電腦都開始三進制的研究和使用了。那在這個場景下為啥從二進制變成三進制有好處呢?
1. 大幅降低了模型的儲存和計算成本
傳統的二進制 LLM 使用 0 和 1 兩種狀態來表示每個參數,因此每個參數需要 1 位儲存空間。而三進制 LLM 使用 -1、0 和 1 三種狀態來表示每個參數,因此每個參數只需要 1.58 位儲存空間。
此外,三進制 LLM 在矩陣乘法操作中只需要整數加法,而不需要浮點數乘法或加法。這使得三進制 LLM 的計算速度比二進制 LLM 快得多。
2. 提高了模型的效能
三進制 LLM 可以表示更豐富的參數值,這使得它能夠更好地擬合訓練數據,從而提高模型的效能。
3. 開辟了新的研究方向
三進制 LLM 的出現為大語言模型的未來發展開辟了新的研究方向。例如,研究人員可以探索如何使用三進制 LLM 來訓練更加復雜和強大的模型。
你再稍等等,三進制LLM每個參數需要 1.58 位儲存空間那不是比二進制需要的儲存空間更大麽,這是怎麽就是好處了?
說得沒錯,在論文中提到的三進制 LLM ,每個參數需要 1.58 位儲存空間,確實比二進制 LLM 需要的 1 位儲存空間要大。
但這並不意味著這是一個壞處。實際上,三進制 LLM 在儲存空間方面仍然具有優勢,主要體現在以下幾個方面:
1. 儲存空間的節省並非線性關系
雖然每個參數需要 1.58 位儲存空間,但由於三進制 LLM 可以表示更豐富的參數值,因此它可以更好地擬合訓練數據,從而提高模型的效能。在很多情況下,三進制 LLM 可以使用更少的參數來達到與二進制 LLM 相同的效能。
2. 計算速度的提升
三進制 LLM 在矩陣乘法操作中只需要整數加法,而不需要浮點數乘法或加法。這使得三進制 LLM 的計算速度比二進制 LLM 快得多。
3. 能耗的降低
由於計算速度的提升,三進制 LLM 的能耗也比二進制 LLM 低得多。
所以 BitNet b1.58 的出現,為大語言模型的未來發展開辟了新的道路。它有可能使大語言模型更加普及,並套用於更廣泛的領域。
以下是一些具體的套用場景:
行動裝置 :BitNet b1.58可以使手機、平板電腦或者車總可以吧等行動裝置上執行更加復雜的大語言模型,從而提供更加豐富的使用者體驗。
物聯網 :BitNet b1.58可以使智慧家居、可穿戴裝置等物聯網裝置具備更強大的語言理解能力,從而實作更加智慧化的互動。
雲端運算 :BitNet b1.58可以幫助雲服務提供商降低大語言模型的部署和營運成本,從而為使用者提供更加經濟實惠的服務。

當然, BitNet b1.58 也還存在一些需要改進的地方,比如:
1. 模型容量 :目前BitNet b1.58的最大模型容量為70B參數,而FP16 LLM已經可以達到1.5T參數。
2. 訓練難度 :BitNet b1.58的訓練過程比FP16 LLM更加復雜,需要更多的計算資源和時間。
BitNet b1.58
是一項具有突破性的研究成果,它為大語言模型的未來發展開辟了新的方向。要知道,這貨被提出到突飛猛進一共也才用了五個月不到,照此勢頭發展下去,大模型在端裝置上跑起來看起來就不遠了啊。
想知道智用人工智慧套用研究院還在做啥麽?下面這個二維碼備上。












