【導讀】 隨著大模型能力叠代迅猛,AI 賦能軟體研發工具層出不窮,軟體開發在大模型時代將面臨哪些機會和挑戰?當 AI 能夠寫程式碼、改 Bug 之時,專業程式設計師的核心競爭力在哪裏?在 上, CSDN 高級副總裁、Boolan 首席技術專家李建忠 發表【 軟體開發智慧化範式思考與探索 】主題演講,深入揭示了其背後的本質與關鍵。
作者 | 李建忠
責編 | Echo Tang
出品丨AI 科技大本營(ID:rgznai100)

自從大模型吹響新一輪技術革命的號角後,整個行業各個層次都面臨大模型帶來的範式轉換。我今年在 4 月份上海舉辦的 上演講時曾提出,大模型為計算產業帶來了計算範式、開發範式、互動範式的三大範式改變。今天是 ,我想和大家來重點談談這一年來對軟體開發智慧化範式改變的思考與探索。
我曾在去年 4 月份的全球軟體研發技術大會上提出【五級「自動軟體開發」參考框架】,借鑒了自動駕駛行業的五級劃分方法,將智慧化軟體開發的水平分為 L1~L5 級。

這一參考框架也在這一年多的研發實踐、和眾多客戶合作、海內外專家研討的過程中,不斷得到完善和豐富。在軟體開發智慧化的實踐和探索中,我也發現業界存在以下幾個比較突出的誤區。
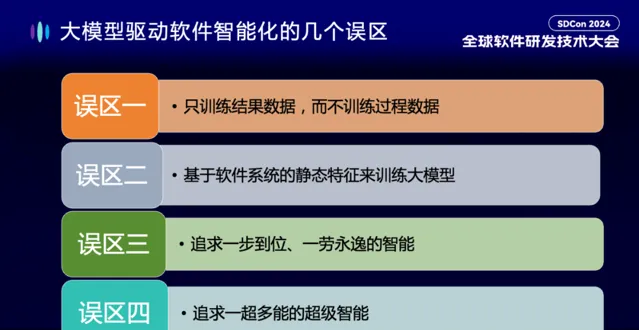
第一個誤區 ,GitHub Copilot 等程式碼大模型工具出來之後,大家會發現它在日常比較簡單的程式碼上確實不錯,但一旦到真實的企業級計畫裏表現可能就沒有期望的那麽好,為什麽?目前的大模型主要都以 GitHub 等開原始碼為主在訓練。這些程式碼我稱之為結果數據,是經過編譯、執行、以及正確性驗證的程式碼。但是它的過程數據基本沒有得到訓練。這既不是人類生物神經網路(ANN)學習的方式,也不是大模型這種數位神經網路(BNN)正確的學習方式。
第二個誤區 ,目前的程式碼大模型,主要基於軟體系統的靜態特征來進行訓練。但是如果我們看 ChatGPT 和 Sora 等在自然語言上和視覺上的訓練,它們的表現顯然效果要好於程式碼領域,為什麽?其實在自然語言領域和視覺領域的訓練,具有相當的動態性,語言的上下文、前因後果、故事線,視訊的時間軸……這些動態資訊蘊含了豐富的知識和邏輯,但軟體開發領域把動態性的特質數據引入模型訓練還是比較少的。
第三個誤區 ,大模型出來之後,可以說透過了圖靈測試,在某些方面也超過了普通人類的水平。這很容易給我們一個希望,去追求一個一步到位一勞永逸的智慧方式。我記得去年 4 月份我們在上海舉辦 SDCon 2023 全球軟體研發技術大會的時候,很多業界朋友都特別期待說我能不能把我的需求一股腦地告訴大模型,大模型就能給我生成真正跑起來的計畫?經過一年多之後,我們越來越發現這是不現實的,我今天想講的是這個期望長期來看也是不現實的,因為 沒有一勞永逸、一步到位的智慧。
第四個誤區 ,Scaling Law 被業界奉為圭臯之後,很多人都在想去追求一個一超多能的超級智慧。希望用一個超級模型,把軟體開發計畫中各種復雜的問題都一股腦地解決,這個也是相當不現實的。正如復雜的人類世界不可能靠一個超人來解決,復雜的軟體領域也不可能靠一個超級模型來解決。
針對以上幾個誤區,我想談一些實踐和探索的觀點和思考。

大模型出來之後,我們一部份人老是覺得上個時代的東西都應該徹底丟掉了,大模型給我們帶來了一個全新的世界。我想強調的是我們在上個時代積累的寶貴經驗和智慧,不是被廢棄了,而是被 AI 壓縮和加速了。因為這些經驗和智慧也是人類知識的一部份。
接下來我們來看看,在大模型時代,有哪些寶貴的經驗和智慧可以幫助我們在軟體領域做得更好?我們說軟體系統有四個復雜的特征,分別是: 復雜性、動態性、協作性、混沌性。

首先來看復雜性。在軟體系統中解決復雜性有兩個常用的手段,第一個是分解,第二個是抽象。

分解是我們在程序導向編程中就有的一個非常有效的手段。包括後來的分層架構、元件化設計、微服務架構等都源自分解思想。但很快,我們發現光有分解是不夠的,必須使用抽象,這就發展出來物件導向、泛型編程、領域驅動設計、概念驅動設計等方法。如果我們看大模型,它在「分解」上做得還是不錯的,但是在「抽象」上就有點差強人意。

就目前的大模型輔助軟體研發的能力來看,它比較擅長什麽?型別實作、函式實作、演算法實作等低抽象任務;但一旦遇到設計模式、架構設計、系統設計等「高抽象任務」,就發現它往往表現得不夠好。在這方面,我們的建議是要向大模型匯入我們在「高抽象任務」方面積累的寶貴的方法論、原則和最佳實踐等。它們未必是程式碼,還包括設計圖、設計文件等。這某種程度上,也是在提升大模型「System 2」的能力。
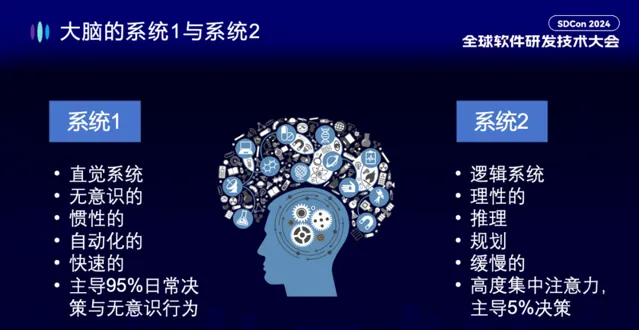
System 1 和 System 2 是諾貝爾經濟學獎得主丹尼爾·卡尼曼在【思考,快與慢】中提出的人類的兩種思考模式。系統一是直覺的、快速的、無意識的,主導我們日常 95%的決策。系統二是基於邏輯的、理性的、規劃的、緩慢的,需要高度集中註意力,主導我們日常 5%的決策。 System 2 的能力對於大模型在軟體開發領域的「抽象能力」至關重要。
第二個部份,我想談談軟體的動態性。所謂動態性本質是我們的軟體系統一直在動態的演化。我們知道軟體開發領域最早一直想追求 Top-down 的瀑布模型,但後來業界越來越發現在很多領域瀑布模型很難 work。究其根本,是軟體開發過程有一個「時間」變量,軟體的需求、所處環境、開發組織等無時無刻不在變化。
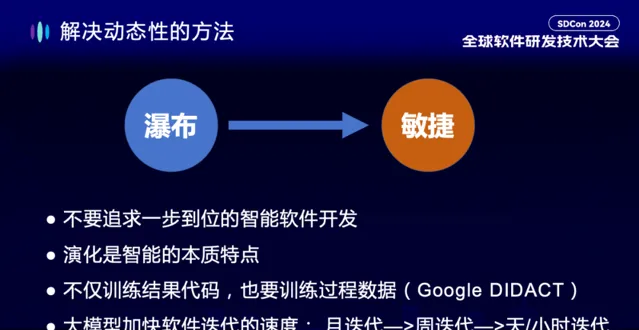
這種「動態性」在大模型時代會改變嗎?我想大機率不會。所以我們也不能追求一步到位的智慧軟體開發。
演化是智慧的本質特點。 智慧從來都不是一步到位的,智慧就是在叠代試錯反復中不斷成長的。我認為在大模型時代,敏捷軟體開發並不會被丟棄,而是 從「組織的敏捷」變為「模型的敏捷」 ,而且會加速敏捷。在敏捷開發之前,軟體開發的周期是以年為單位叠代,比如 Windows 95、Windows 98。在敏捷開發之後,軟體行業進入以月為單位叠代或者以周為單位叠代。在大模型時代,軟體開發將進入以天或者小時為單位進行叠代。
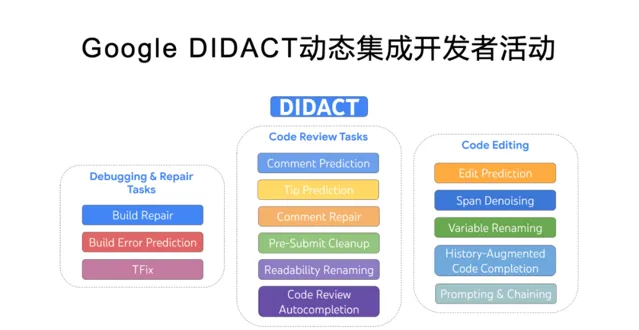
除了提升叠代速度外,我們也需要對更多的軟體開發過程數據進行訓練,來幫助模型更好地理解軟體開發的「動態性」。這裏可以參考一下 Google 最近釋出 DIDACT(Dynamic Integrated Developer ACTivity 動態整合開發者活動)。
參考連結:
https://research.google/blog/large-sequence-models-for-software-development-activities/
從根本上來說,軟體開發並非孤立的過程,而是在人類開發者、程式碼審查者、錯誤報告者、軟體架構師和工具(如編譯器、單元測試、程式碼檢查工具和靜態分析器等)之間進行的對話。DIDACT 使用軟體開發過程作為訓練數據來源,而不僅是最終的完成程式碼。透過讓模型接觸開發者在工作中看到的上下文,結合他們的響應行為,模型可以學習軟體開發的動態性。

Google DIDACT 的研發也發現在學習過程數據之後,模型生成軟體計畫的過程,非常類似人類開發團隊,先編寫比較粗粒度的介面和框架程式碼,然後一點一點把它們細化實作,包括也有反復和試錯的過程。而不是大家最開始想象的那種從上到下一行一行寫的過程,整個計畫一氣呵成。真實的軟體開發不是這樣,人類開發團隊不是這樣,大模型驅動的智慧軟體開發也不會是這樣。
接下來我想談談架構設計領域的協作性。我們知道當軟體系統越來越復雜時,元件與元件之間的協作,服務與服務之間的協作,會變成非常重要的課題。早在 1967 年電腦科學家 Melvin Conway 就提出了著名的「康威定律」。
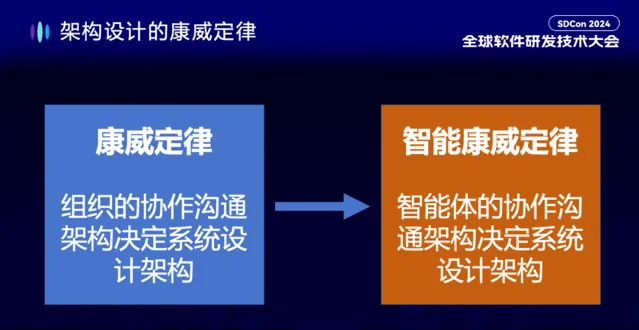
康威定律指出「組織的協作溝通架構,決定了我們的系統設計架構」,這在架構設計領域被奉為第一定律。那麽在大模型時代,軟體內部需不需要協作?顯然是需要的,我們仍然需要許許多多的元件或服務進行協作。只是這時候的元件或服務的構建者,不見得是軟體團隊,而是一個一個智慧體(Agent)。那麽這些智慧體之間當然也需要協作。它們的協作也要遵循康威定律。我稱之為 「智慧康威定律」:智慧體的協作溝通架構,決定系統設計架構。
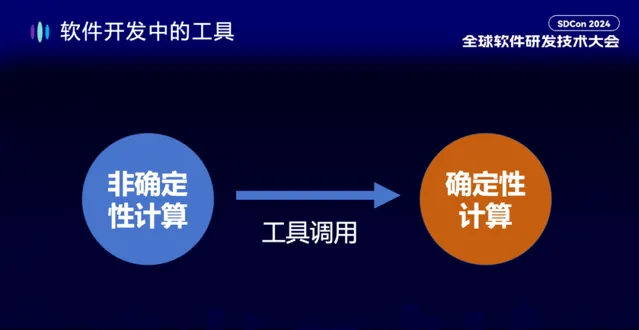
我們再來談一下軟體開發中的工具,來實作在所謂混沌系統中尋求確定性的部份。我們知道現在大模型很多時候做的是一些非確定性的計算(或者叫機率性計算),但這並不意味著我們所有的任務都要用非確定性計算。我們在大模型之前積累了很多確定性計算的工具,它們在大模型時代也不會被丟棄,而是與大模型進行很好的融合。融合方式就是透過 Agent(工具)來實作工具呼叫。
簡單總結一下。針對前面提到的軟體系統的四大特性: 復雜性、動態性、協作性、混沌性 ,在大模型時代智慧軟體開發範式下,我們需要特別關註以下四大核心能力建設:

第一個抽象能力 :怎麽訓練、怎麽提升大模型的抽象能力,也就是 System 2 的能力,是一個很重要的課題。
第二個演化能力 :如何支持大模型在整個軟體開發過程中加速我們的叠代周期,它不僅能快速釋出高品質的軟體,同時對模型能力也是一個快速的提升。
第三個協作能力 :我們需要仔細設計智慧體的協作架構,來支持我們的系統設計架構。
第四個工具能力 :使用工具來解決混沌系統中的確定性問題。
最後我想談一下,提升軟體開發的智慧化水平是一個系統工程,前面講的這四大核心能力,它背後需要很多基礎建設,包括模型方面的建設和數據方面的建設。我列了 10 個主要的方面:

第一:擴充套件定律 。Scaling Law 並沒有停止,仍然在發揮著重要作用,這個是我們對基礎模型方面繼續要期待的。
第二:提高上下文視窗 。上下文視窗是大模型的「記憶體」,它對最大化發揮模型能力有著關鍵影響。這一塊國內外都進展飛速。
第三:長期記憶能力 。大型軟體計畫蘊含的資訊量浩瀚紛繁,大模型的長期記憶也很重要,雖然有 RAG 等外部檢索技術的快速發展,但基礎架構方面的創新也值得期待。
第四:System 2 的提升 。目前的大模型普遍被認為是一個高中生的水平。如何提升大模型系統 2 的能力,關系到大模型是否能夠成為一個深思熟慮的專家級學者,從而來勝任軟體開發這樣具有較高智慧要求的工作。
第五:降低模型幻覺 。降低模型幻覺仍然是業界需要克服的一個問題,雖然我們也不要期望徹底消除幻覺。某種程度上可以說,幻覺也是智慧的一部份,如果沒有幻覺,智慧也將失去創造力。
第六:研發全流程數位化 。如何把研發流程裏盡可能多的開發者活動按時間順序記錄下來,比如:文件、設計圖、程式碼、測試程式碼、運維指令碼、會議記錄、甚至設計決策中的爭論等等各種數據,然後變成數位化的語料,餵給我們的大模型。
第七:多模態數據訓練 。軟體開發領域不只是程式碼和文本,還有很多設計圖比如 UML、表格、甚至視訊等數據。
第八:將模型做「小」 。軟體開發中很多細分任務都不見得需要所謂的「大模型」,而是在高品質垂類數據訓練下的「小模型」,比如 Bug 修復,比如開發者測試,比如 Clean Code。
第九:模型合成數據 。透過模型生成程式碼、設計、註釋等,作為語料供給另外的模型進行訓練,也是在軟體開發中一個非常活躍的發展方向。
第十:多智慧體協同 。針對復雜的軟體工程任務,未來一定是眾多不同角色、不同模型、不同任務的智慧體的群策群力。
最後,軟體開發智慧化範式轉換的大幕才剛剛開啟,中間還有很多曲折等待我們去探索,希望今天的分享能給大家帶來啟發,謝謝大家!
同時和所有開發者朋友們預告,CSDN 聯合高端 IT 教育平台 Boolan 將於 2024 年下半年舉辦 四大主題會議 ,歡迎大家掃碼熱情參與~

*封面圖由 Meta AI 生成











